







目录
一、产生背景
- 2017年,作者 Joseph Redmon 和 Ali Farhadi 在 YOLOv1 的基础上,进行了大量改进,提出了YOLOv2 。重点解决YOLOv1召回率和定位精度方面的不足。
- YOLOv2是一个先进的目标检测算法,比其它的检测器检测速度更快。除此之外,该网络可以适应多种尺寸的图片输入,并且能在检测精度和速度之间进行很好的权衡。
- 相比于YOLOv1是利用全连接层直接预测Bounding Box的坐标,YOLOv2借鉴了Faster R-CNN的思想,引入Anchor机制。利用K-means聚类的方法在训练集中聚类计算出更好的Anchor模板,大大提高了算法的召回率。同时结合图像细粒度特征,将浅层特征与深层特征相连,有助于对小尺寸目标的检测。
二、改进策略
1.Batch Normalization(批量标准化)
- V2版本舍弃Dropout,卷积后全部加入Batch Normalization,简称BN,BN
对数据进行预处理(统一格式、均衡化、去噪等),网络的每一层输入都做了归一化,收敛相对更容易,能够大大提高训练速度,提升训练效果。 - 经过Batch Normalization处理后的网络会提升2%的mAP,从现在的角度看,Batch Normalization已经成为网络必备处理。
2.High Resolution Classifier(高分辨率分类器)
- YOLOv1训练由两个阶段组成。 首先,训练像VGG16这样的分类器网络。 然后用卷积层替换全连接层,并端到端地重新训练以进行目标检测。YOLOv1先使用 224×224 的分辨率来训练分类网络,在训练检测网络的时候再切换到 448×448的分辨率,这意味着YOLOv1的卷积层要重新适应新的分辨率,同时YOLOv1的网络还要学习检测网络。
- 直接切换分辨率,YOLOv1检测模型可能难以快速适应高分辨率。所以YOLOv2 以 224 × 224 的图片开始用于分类器训练,但是然后使用10个epoch再次用 448×448 的图片重新调整分类器。让网络可以调整滤波器来适应高分辨率图像,这使得检测器训练更容易。使用高分辨率的分类网络提升了将近4%的mAP。
3.K-means聚类提取Anchor Boxes
a.引入Anchor Boxes方法
在YOLOv1中,作者设计了端对端的网路,直接对边界框的位置(x, y, w, h)进行预测。这样做虽然简单,但是由于没有类似R-CNN系列的推荐区域,所以网络在前期训练时非常困难,很难收敛。于是,自YOLOv2开始,引入了 Anchor boxes 机制,希望通过提前筛选得到的具有代表性先验框Anchors,使得网络在训练时更容易收敛。
- 在 Faster R-CNN 算法中,是通过预测 bounding box 与 ground truth 的位置偏移值
,间接得到bounding
box的位置。bbox:中心为( x p {x_p} xp, y p {y_p} yp);宽和高为( w p {w_p} wp, h p {h_p} hp), t x {t_x} tx、 t y {t_y} ty为预测出来的偏移量。公式如下:
x = x p + w p ∗ t x y = y p + h p ∗ t y \begin{array}{l} x = {x_p} + {w_p} * {t_x}\\ y = {y_p} + {h_p} * {t_y} \end{array} x=xp+wp∗txy=yp+hp∗ty
当 t x {t_x} tx=1,则会将bbox在x轴向右移动 w p {w_p} wp; t x {t_x} tx=-1,则会将bbox在x轴向左移动 w p {w_p} wp。这样会导致收敛问题,模型不稳定,尤其是刚开始训练的时候。 - YOLOv2的做法是并没有直接使用偏移量,而是选择相对grid cell的偏移量。计算公式为:
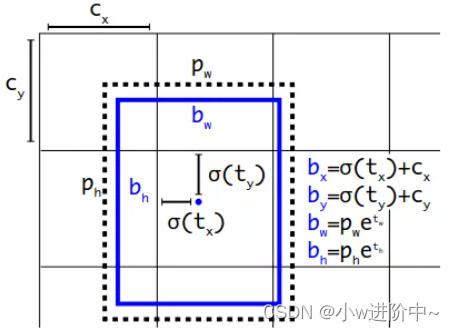
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h \begin{array}{l} {b_x} = \sigma ({t_x}) + {c_x}\\ {b_y} = \sigma ({t_y}) + {c_y}\\ {b_w} = {p_w}{e^{{t_w}}}\\ {b_h} = {p_h}{e^{{t_h}}} \end{array} bx=σ(tx)+cxby=σ(ty)+cybw=pwetwbh=pheth
t x {t_x} tx、 t y {t_y} ty、 t w {t_w} tw、 t h {t_h} th为预测出来的偏移量; p w {p_w} pw、 p h {p_h} ph为预测框的宽高;其中, c x {c_x} cx和 c y {c_y} cy为cell的左上角坐标,当前的cell的左上角坐标为(1,1) ,它们的值都是相对于特征图(这里是13 × 13 13 ,把特征图的长宽记作h,w)大小的,在特征图中的cell长宽均为1。由于sigmoid函数的处理,边界框的中心位置会被约束在当前cell的内部,防止偏移过多。通过公式可以算出预测框相对于整个特征图的位置和大小了。想得到边界框在原图的位置和大小,需要乘以网络下采样的倍数。
示意图如下:
举例:例如预测值(
σ
(
t
x
)
\sigma ({t_x})
σ(tx),
σ
(
t
y
)
\sigma ({t_y})
σ(ty),
t
w
{t_w}
tw,
t
h
{t_h}
th)=(0.2,0.1,0.2,0.32),anchor框为
p
w
{p_w}
pw=3.19275(),
p
h
{p_h}
ph=4.00944
预测框相对于最终输出的特征图(13×13)位置为:
b
x
=
0.2
+
1
=
1.2
b
y
=
0.1
+
1
=
1.1
b
w
=
3.19275
∗
e
0.2
=
3.89963
b
h
=
4.00944
∗
e
0.32
=
5.52151
\begin{array}{l} {b_x} = 0.2 + 1 = 1.2\\ {b_y} = 0.1 + 1 = 1.1\\ {b_w} = 3.19275 * {e^{0.2}} = 3.89963\\ {b_h} = 4.00944 * {e^{0.32}} = 5.52151 \end{array}
bx=0.2+1=1.2by=0.1+1=1.1bw=3.19275∗e0.2=3.89963bh=4.00944∗e0.32=5.52151
预测框相对于原始输入图像(416×416)的位置为:
b
x
=
1.2
∗
32
=
38.4
b
y
=
1.1
∗
32
=
35.2
b
w
=
3.89963
∗
32
=
124.78
b
h
=
5.52151
∗
32
=
176.68
\begin{array}{l} {b_x} = 1.2 * 32 = 38.4\\ {b_y} = 1.1 * 32 = 35.2\\ {b_w} = 3.89963 * 32 = 124.78\\ {b_h} = 5.52151 * 32 = 176.68 \end{array}
bx=1.2∗32=38.4by=1.1∗32=35.2bw=3.89963∗32=124.78bh=5.52151∗32=176.68
b.改进Anchor Boxes方法
对于YOLOv1 的缺点:一张图片被分成7×7的网格,一个网格只能预测一个类,当一个网格中同时出现多个类时,就无法检测出所有类,YOLOv2做出了相应的改进,可以同时预测类别和坐标:
- 将YOLOv1的FC层和最后一个Pooling层去掉,使得最后的卷积层的输出可以有更高的分辨率特征。
- 缩减图片的输入尺寸,用416×416大小的输入代替原来的448×448,使得网络输出的特征图有奇数大小的宽和高,进而使得每个特征图在划分单元格的时候只有一个中心单元格(Center Cell)。YOLOv2通过5个Pooling层进行下采样,得到的输出是13×13的像素特征。所以在YOLOv2设计中要保证最终的特征图为奇数的宽和高。
- YOLOv2使用卷积层降采样(factor=32),使得输入卷积网络的416x416的图片最终得到13x13的卷积特征图(416/32=13)。每个中心预测5种不同大小和比例的先验框。由于都是卷积不需要reshape,很好的保留的空间信息,最终特征图的每个特征点和原图的每个Cell一一对应。
- YOLO v1是由每个Cell来负责预测类别,每个Cell对应的2个Bounding Box负责预测坐标(YOLOv1中最后输出7×7×30的特征,每个Cell对应1×1×30,前10个主要是2个Bounding Box用来预测坐标,后20个表示该Cell在假设包含目标的条件下属于20个类别的概率)。YOLOv2中,不再让类别的预测与每个Cell(空间位置)绑定一起,而是全部放到Anchor Box中。
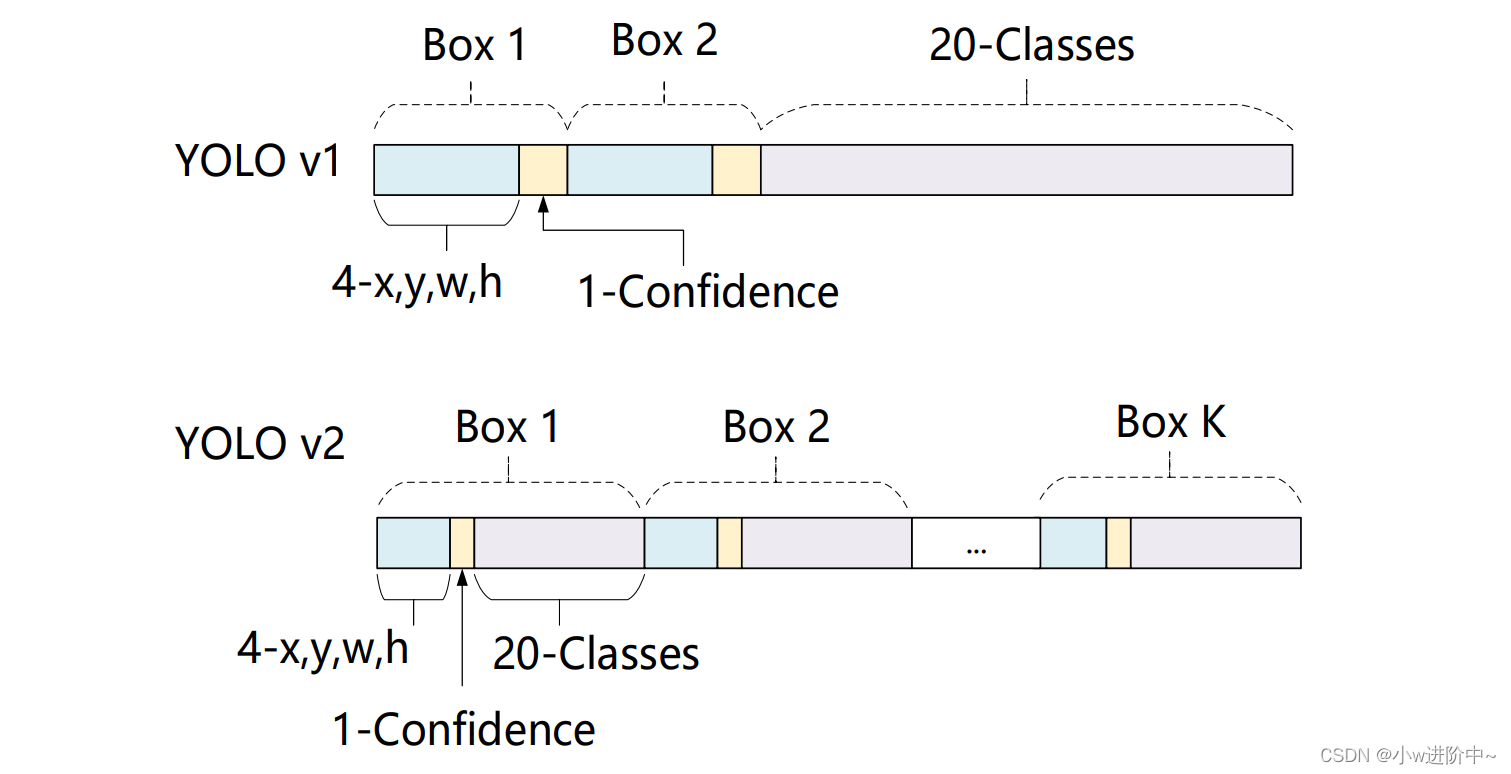
- 由于YOLOv2将类别预测从cell级别转移到边界框级别,在每一个区域预测5个边框,每个边框有25个预测值,因此最后输出的特征图通道数为125。其中,一个边框的25个预测值分别是20个类别预测、4个位置预测及1个置信度预测值。这与YOLOv1有很大区别,YOLOv1是一个区域内的边框共享类别预测,而这里则是相互独立的类别预测值。
- YOLOv1只能预测98个边界框(7 × 7 × 2),而YOLOv2使用anchor boxes之后可以预测上千个边界框 (13 ×
13 × 5 = 845) 。所以使用anchor boxes之后,YOLOv2的召回率大大提升,由原来的81%升至88%。
c.K-means聚类提取Anchor Boxes
- Faster-Rcnn系列选择的先验框长宽比例都是常规的,但不一定完全适合数据集。作者希望可以一开始就选择更好的、更有代表性的先验框维度,那么网络就应该更容易学到准确的预测位置。
- 作者使用了统计学习中的 K-means聚类方法,通过对数据集中的 GT Box 做聚类,找到 GT Box的统计规律。以聚类个数𝑘为锚定框个数,以𝑘个聚类中心Box的宽高维度为宽高的维度。
- 如果按照标准K-means使用欧式距离函数,大框比小框产生更多误差。但是,我们真正想要的是使得预测框与GT框的有高的IOU得分,而与框的大小无关。即聚类分析时选用Bbox与聚类中心Bbox之间的IOU值作为距离指标。因此采用了如下距离度量:
d ( b o x , c e n t r o i d s ) = 1 − I o U ( b o x , c e n t r o i d s ) d(box,centroids) = 1 - IoU(box,centroids) d(box,centroids)=1−IoU(box,centroids)
聚类结果如下图:
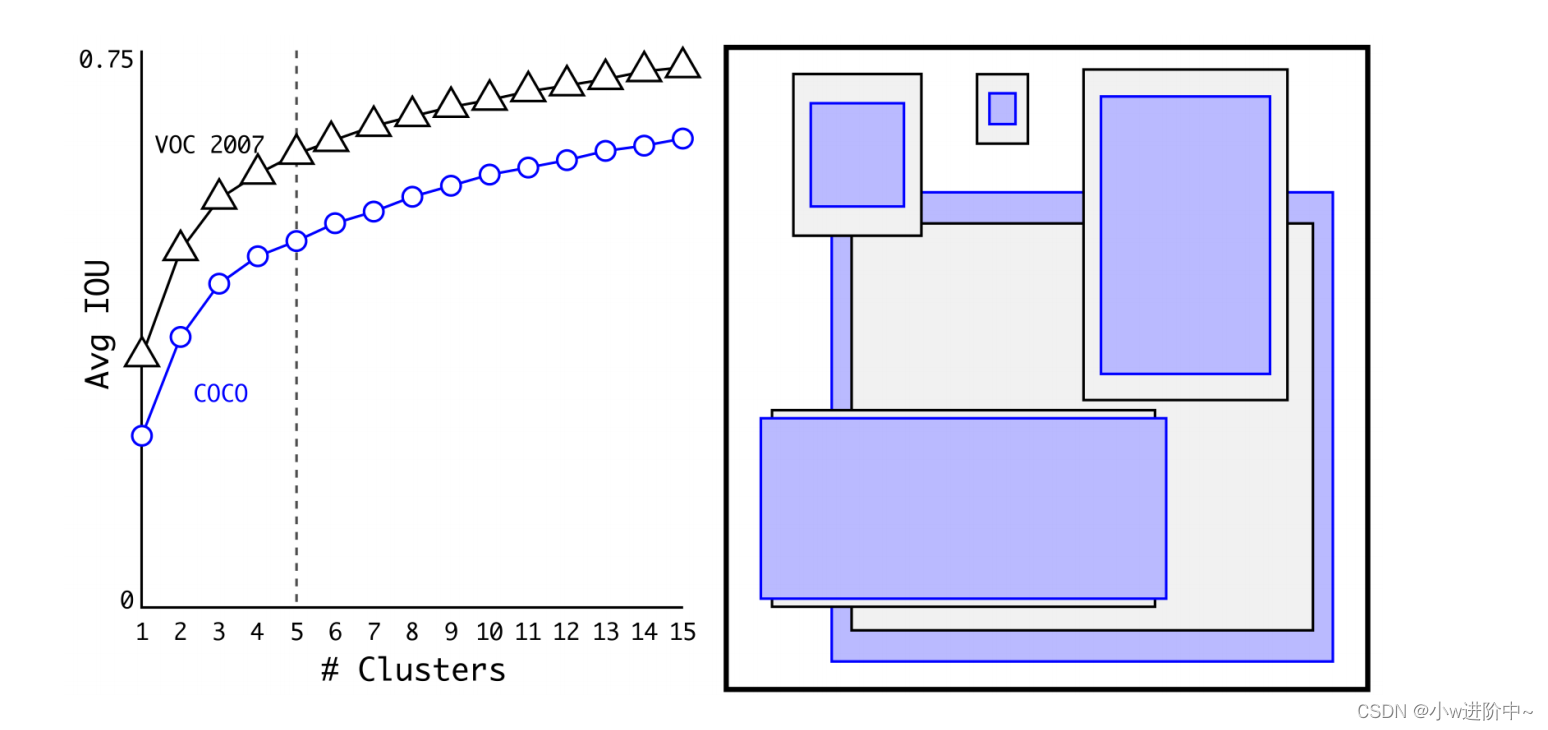
如上左图:随着k的增大,IOU也在增大(高召回率),但是复杂度也在增加。所以平衡复杂度和IOU之后,最终得到k值为5 。
如上右图:5个聚类的中心与手动挑选的框是不同的,扁长的框较少,瘦高的框较多。作者文中的对比实验说明了 K-means 方法的生成的框更具有代表性,使得检测任务更容易学习。
4.Fine-Grained Features(更细粒度特征)
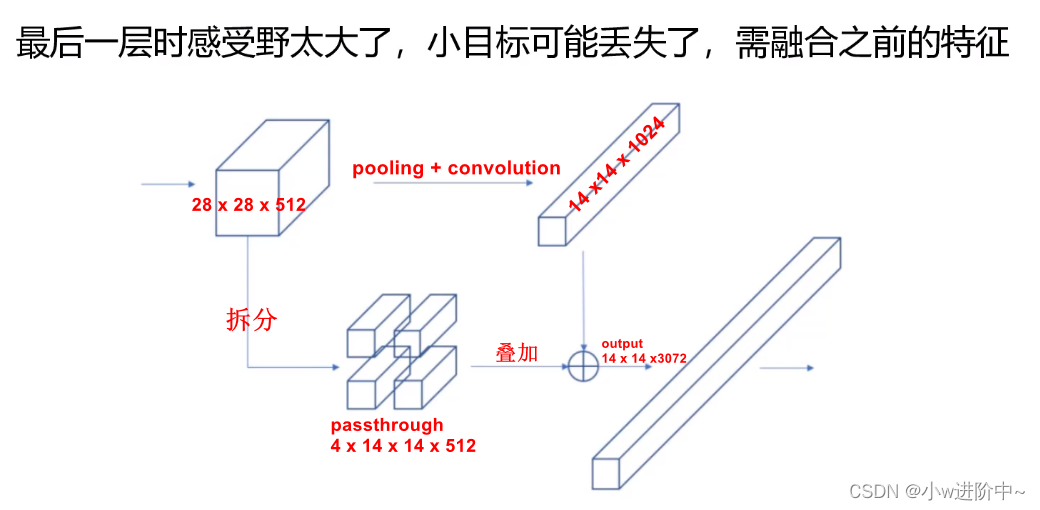
感受野通俗意义上是指就是特征图上的点能看到原始图像多大区域。随着卷积越多,越靠后的感受野越大,因此最后一层时感受野太大了,适合捕捉较大的目标,小目标可能丢失,因此需融合之前的特征,将前一个26×26×512的特征图进行拆分,拆分成4个13×13×512的特征图和下一个13×13×1024的进行拼接,拼接为13×13×(4×512+1024)=13×13×3072。如下图:
5.进行Multi-ScaleTraining(多尺度训练)
- 由于YOLOv2模型移除了全连接层,只有卷积层和池化层,所以YOLOv2的输入不局限于416×416大小的图片。
- 为了增强模型的鲁棒性,YOLOv2采用了多尺度输入训练策略,具体来说就是在训练过程中每间隔一定的迭代(iterations)之后改变模型的输入图片大小。由于YOLOv2为32倍下采样,输入图片大小选择一系列为32倍数的值: {320, 352,…, 608} ,输入图片最小为 320×320 ,此时对应的特征图大小为 10×10 ;而输入图片最大为 608×608,对应的特征图大小为 19×19。
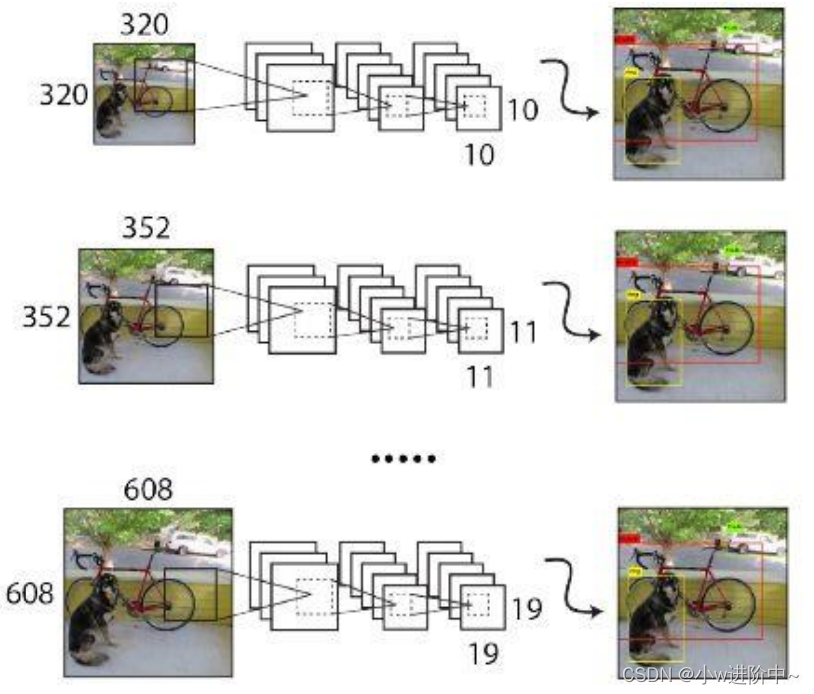
通过多尺度训练出的模型可以预测多个尺度的物体。并且,输入图片的尺度越大则精度越高,尺度越低则速度越快, 因此YOLOv2多尺度训练出的模型可以适应多种不同的场景要求。
6.全新的网络架构DarkNet-19
YOLOv2采用了新的网络架构DarkNet-19,如下图:

- 这个网络包括19个卷积层和5个max pooling层,与VGG相似,使用了很多3×3卷积核,采用 2×2的最大池化层之后,特征图维度降低2倍,而同时将特征图的通道增加两倍,即每一次池化后,下一层的卷积核的通道数 = 池化输出的通道 × 2。
- 在每一层卷积后,都增加了批量标准化(Batch Normalization)进行预处理。采用了降维的思想,把1×1的卷积置于3×3之间,用来压缩特征。在网络最后的输出增加了一个global average pooling层。
- DarkNet的实际输入为 416×416 ,没有全连接层(FC层),5次降采样到 13×13。
主要参考:
https://blog.csdn.net/frighting_ing/article/details/123466282
https://blog.csdn.net/wjinjie/article/details/107509243















 1709
1709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









