







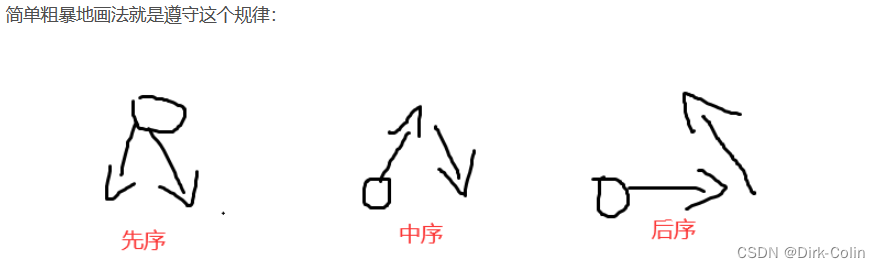
对于前序遍历,首先访问当前节点,然后递归地遍历左子树和右子树。
这就是为什么前序遍历的代码中,首先是 printf("%d ", root->data);。
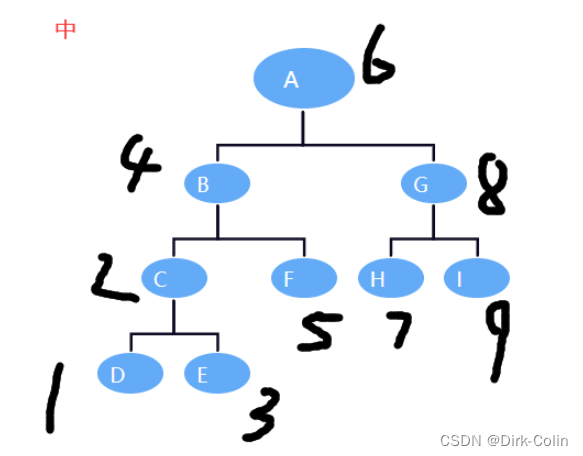
中序遍历:
对于中序遍历,首先递归地遍历左子树,然后访问当前节点,最后递归地遍历右子树。
这就是为什么中序遍历的代码中,左子树递归调用在当前节点访问之前,右子树递归调用在当前节点访问之后。
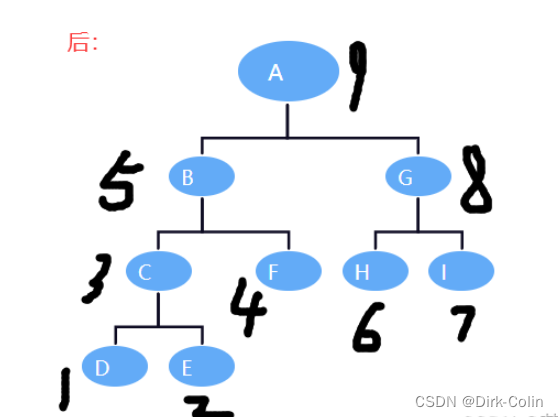
后序遍历:
对于后序遍历,首先递归地遍历左子树和右子树,最后访问当前节点。
这就是为什么后序遍历的代码中,左子树递归调用在当前节点访问之前,右子树递归调用在当前节点访问之前。若已知一棵二叉树先序序列为ABCDEFG,中序序列为CBDAEGF,则其后序序列为()
CDBAGFE
CDBFGEA
CDBGFEA
BCDAGFE第一步:因为先序先遍历的是A,所以A为root,根据中序序列可以知道CBD在左边,EGF在右边,因为中序是先遍历左边,再打印root,再遍历右边。

第二步:因为先序第二个root是B,所以得到下图。


第三步: 现在只需注意GF,因为由中序遍历可知GF都在E的右边,因为前序中先打印的是F,所以得到下图。

第四步:后序遍历 :先遍历左,再遍历右,再打印。为CDBGFEA。

void preOrderTraversal(struct TreeNode* root) {
if (root != NULL) {
printf("%d ", root->data); // 访问当前节点
preOrderTraversal(root->left); // 递归遍历左子树
preOrderTraversal(root->right); // 递归遍历右子树
}
}
// 中序遍历
void inOrderTraversal(struct TreeNode* root) {
if (root != NULL) {
inOrderTraversal(root->left); // 递归遍历左子树
printf("%d ", root->data); // 访问当前节点
inOrderTraversal(root->right); // 递归遍历右子树
}
}
void postOrderTraversal(struct TreeNode* root) {
if (root != NULL) {
postOrderTraversal(root->left); // 递归遍历左子树
postOrderTraversal(root->right); // 递归遍历右子树
printf("%d ", root->data); // 访问当前节点
}
}
二叉树的创建:
// 定义二叉树结构
struct TreeNode {
int data;
struct TreeNode* left;
struct TreeNode* right;
};
// 创建新的二叉树节点
struct TreeNode* createNode(int value) {
struct TreeNode* newNode = (struct TreeNode*)malloc(sizeof(struct TreeNode));
newNode->data = value;
newNode->left = NULL;
newNode->right = NULL;
return newNode;
}测试代码:
int main() {
// 构建一个简单的二叉树
struct TreeNode* root = createNode(1);
root->left = createNode(2);
root->right = createNode(3);
root->left->left = createNode(4);
root->left->right = createNode(5);
// 前序遍历
printf("前序遍历: ");
preOrderTraversal(root);
printf("\n");
// 中序遍历
printf("中序遍历: ");
inOrderTraversal(root);
printf("\n");
// 后序遍历
printf("后序遍历: ");
postOrderTraversal(root);
printf("\n");
return 0;
}哈希表:
在这个示意图中,我将哈希表分为若干个桶(buckets),每个桶对应一个数组元素。每个桶都是一个链表,用于处理哈希冲突。
假设哈希表的大小为 N=15,每个桶是一个链表,链表的节点包含键值对。
Index 0: [ ] -> [ ] -> [ ] -> ...
Index 1: [ ] -> [ ] -> [ ] -> ...
Index 2: [ ] -> [ ] -> [ ] -> ...
... ... ... ... ...
Index 14: [ ] -> [ ] -> [ ] -> ...其中,每个方括号内表示链表的一个节点,包含键值对。例如,Index 0 的链表可能如下:
Index 0: [ ] -> [ ] -> [ ] -> [ ] -> NULL这里,每个 [ ] 表示链表的一个节点,-> 表示链表的指针。最后一个节点的 next 指针指向 NULL,表示链表的结束。
当我们插入键值对时,例如 (key=5, value=42),它会根据哈希函数计算出哈希值,假设哈希值为 2,然后将节点插入到相应的链表头部:
Index 2: [ (5, 42) ] -> [ ] -> [ ] -> [ ] -> NULL这只是一个简单的示意图,实际中每个节点可能会有一个链表,用于解决哈希冲突。
#define N 15
typedef int datatype;
typedef struct node
{
datatype key;
datatype value;
struct node* next;
}ListNode;
typedef struct
{
ListNode data[N];
}hash;Index 0: [ ] -> NULL
Index 1: [ ] -> NULL
Index 2: [ ] -> NULL
... ... ...
Index 14: [ ] -> NULL每个 Index 对应一个数组元素,而每个数组元素是一个 ListNode 结构体的数组。初始时,每个链表为空,表示还没有插入任何键值对。
定义了一个名为 hash 的结构体类型。每个结构体对象实际上代表了一个哈希表,而数组 data 中的每个元素对应哈希表的一个桶。
ListNode data[N];: 这部分定义了一个数组 data,其中每个元素都是一个 ListNode 结构体。这个数组表示哈希表中的所有桶,总共有 N 个桶,每个桶是一个链表。
当插入键值对 (key=5, value=42) 时,首先会 计算键的哈希值。假设通过哈希函数计算得到的哈希值为 hash_value。
然后,使用哈希值对哈希表的大小 N 取模,得到插入的位置,即 index = hash_value % N。
最后,将新节点插入到对应位置的链表的头部。在这里,假设 index 的位置是 2,那么链表的头部将变成:
Index 2: [ (5, 42) ] -> NULL 这表示键值对 (5, 42) 已经成功插入到哈希表中,存储在索引为 2 的链表的头部。如果其他键值对被插入到相同的索引位置,它们将通过链表连接在一起,形成一个链表。
注意:插入节点
int hash_insert(hash* HS, datatype key)
{
ListNode* p, * q;
if (HS == NULL)
{
printf("HS is null\n");
return -1;
}
//创建节点
if ((p = (ListNode*)malloc(sizeof(ListNode))) == NULL)
{
printf("malloc error\n");
return -1;
}
//创建成功的话:
//节点赋值为key
p->key = key;
//节点的哈希值
p->value = key % N;
//节点存储的下一个节点,为NULL
p->next = NULL;
//用一个指针指向这个哈希表,哈希表我这里用数组data[N]表示的
q = &(HS->data[key % N]);
//遍历这个数组,用指针cur去遍历这个链表
while (q->next != NULL && q->next->key > p->key)
{
q = q->next;
}
p->next = q->next;
q->next = p;
return 0;
} 在这个实现中,每个桶(h->data[index])的 next 指针实际上是指向链表的第一个节点。这个节点是存储数据的第一个节点,而头节点(h->data[index])本身不存储数据,仅用于指向链表的第一个节点。
所以,当我们通过 ListNode* current = h->data[index].next; 初始化 current 指针时,实际上是将其指向链表的第一个真正存储数据的节点。
查找节点:
ListNode* hash_search(hash* HS, datatype key)
{
ListNode* p;
if (HS == NULL)
{
printf("HS is null\n");
return NULL;
}
p = &(HS->data[key % N]);
while (p->next && p->next->key != key)
{
p = p->next;
}
if (p->next == NULL)
{
return NULL;
}
else
{
printf("okkkkkkk!\n");
return p->next;
}
}测试代码:
int main(int argc, const char* argv[])
{
hash* HS = NULL;
int data[] = { 23,34,14,38,46,16,68,15,7,31,26 };
int i = 0;
int key = 0;
if ((HS = hash_create()) == NULL)
{
return -1;
}
for (i = 0; i < sizeof(data) / sizeof(data[0]); i++)
{
hash_insert(HS, data[i]);
}
printf("input:");
scanf(" %d", &key);
ListNode* LN = hash_search(HS, key);
if (LN == NULL)
{
printf("not found\n");
}
else
{
printf("founded:%d %d\n", key, LN->key);
}
return 0;
}














 511
511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









