







0.引言
本篇文章主要介绍强化学习中最基本的术语(不包含具体算法),主要提供给刚入门强化学习的朋友们,让大家快速掌握一些基本术语,之后对看强化学习算法内容有着更好地理解。
1.基本术语
1.1.state
中文称为“状态”,举个具体的例子来说:在一个机器人走网格的游戏当中,每一个不同的格子就是不同的状态(如下图1例子中有9个格子所以有9个不同的状态),通常用一串向量来表示:是s1,s2,s3等等,所有状态的集合通常用state space(状态空间)来表示(如9个状态:)。

1.2.action
中文称为“行动”,举个具体的例子来说,在上面那个机器人走网格的例子当中,在每一个格子(状态)内,机器人可以选择五种不同的行动(向前、向后、向左、向右、原地不动)来移动到下一个格子中(状态)。所有的行动的集合可以使用action space来描述:(为什么行动的集合用A(s)?是因为只有基于状态才有行动,所以行动的集合可以看做是基于状态的这么一种函数)
1.3.State transition
中文称为“状态转移”,这是一个由这一状态转移到下一个状态的过程就称为状态转移,下图2举一个具体的例子,该图描述了由state1通过action2到state2的过程,状态转移实际上定义了一个agent与环境之间的一种交互行为。用数学的方法来表示这个过程如下图3表示,使用条件概率表示,也就是说在状态为s1在a1行动的条件下,到达状态s2的概率为1(图中是一种确定性的状态转移。状态转移也有可能为随机态可以用概率描述,比如s1在a1行动下,有50%的概率到状态s2,有50%到s3)。


1.4.Policy
中文名称为“策略”,是一个强化学习中独有的概念,它规定了对于一个状态(state)来说该应该选择哪一个行动(action),如下图4例子所示,图中绿色箭头部分就是Policy,比如右上角第一格为状态是s1,Policy要求它的行动为向右(action2)。在数学描述中使用π来描述Policy,如下图5所示,图中为状态s1的一种确定性的Policy(与状态转移相同的是,Policy也有可能是随机性的)。


1.5.Reward
中文称为“回报”,顾名思义它是指在经过一个行动(action)之后能获得的一个具体数值,通常用r表示。如果reward是一个positive的值的话,说明鼓励做出这种行动(action);反之,如果reward是一个negative的值的话,说明做出这种行动(action)会被惩罚。也就是说我么你可以通过设计不同的reward来影响做出agent做出的行为(action),举一个具体的例子(引用一下图1作为图6):我们可以设置当下一个行动(action)是撞到边界(如s1做出向左的行动)的话,reward设置为-1;如果下一个行动(action)进入的是黄色方块区域(如s5做出向右的行动),reward设置为-1;如果下一个行动(action)到蓝色区域reward设置为1;其余行动reward设置为0。也就是说我们鼓励到蓝色区域(目标区域),对进入黄色区域和撞墙行动会惩罚,可以起到一个引导的作用。
用数学描述来描述reward,如下图7所示,同样的reward也可以属于随机性的。
另外需要强调reward是依赖于当前的状态和行为的,不依赖于下一个状态。

1.6.Trajectory and Return
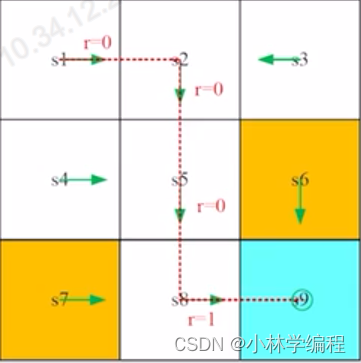
Trajectory这个名词其实就是一个state-action-reward chain的过程,如下图8所示。直观一点儿,用图10来表示这个过程(图9中的红色线部分)。
return这个概念在强化学习中也是十分重要的。return就是把Trajectory路径中的所有获得的reward给加起来得到的数值,图10中从s1-s9的return=0+0+0+1=1,从物理意义上来说如果该路径的return的数值越大,那就说明这条路径是更优的选择,从而评估策略的好坏。

1.7.Discounted return
当图10中的Trajectory的状态到s9时,它的行动(action)就是原地不动,且这个action的reward是1的话,那么这个Trajectory可能无限长的,如下图11所示。

那么它的return也应该是无限大的,就会发散掉,这时我门引入一个变量叫“discount rate”(折扣因子),数学描述使用表示,且
,从而引入“discounted return”,数学公式表达为:
就如上图10的discounted return表示,这样的话就会收敛了:
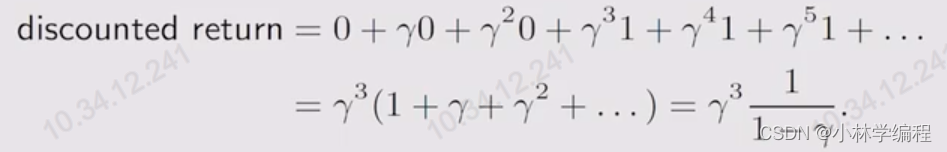
另外,的选择也会影响return中reward的积累,当
取值比较小时,可能会更加重视一些离目标状态比较近一些的reward的积累,也就是更加“近视”;当
取值比较大时,更加注重的是长远的reward,也就是说比较“”远视“”。
1.8.state value
state value的数学表达式如下图12:

其中用来指代state value,是因为它是一个有关于state的这么一个函数,并且它依赖于Policy,对于不同的Policy有不同的state value,物理意义就是它是一个表示state价值的这么一个值,如果state value越大,Policy也就越好(因为更多的rewards可以获得);E[ ]表示求期望,
表示discounted return,也就是说当状态为s时,所获得discounted return的期望值就是state value
那么,return和state value有什么区别呢?
return是针对一条Trajectory的所有reward之和,而state value则是指从状态s出发的所有可能的Trajectory的return的期望值(也就是均值)。
1.9.action value
action value的数学表达式如下图13:

其中来代指action value,因为它是一个关于state-action pair的这么一个函数,并且依赖于Policy,物理意义相当于是state做出不同action之后的价值,也就是说action value越大,那么这个状态做出这种action也就越好。
action value和state value又有什么区别呢?
其实区别对比数学表达式就可以很好的看出来了,本质上都是期望,action value是基于state中一个action之后的期望,而state value是基于state这么一种期望,可以简单的理解为state value是把将每一个action的action value平均之后的值,也就是说state将所有的action value进行求平均结果就是state value。
参考
1.视频P4-P10:第2课-贝尔曼公式(Action value的定义)_哔哩哔哩_bilibili
















 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











