







只为记录学习心得
学习视频来源B站up主 西湖大学空中机器人:
链接:https://www.bilibili.com/video/BV1sd4y167NS/?spm_id_from=333.337.search-card.all.click&vd_source=ad94eb95d81e9e6b1a5d71459ef1a76d
目录
1.return为什么重要?如何计算return?
2.state value的定义
3.贝尔曼公式:推导过程
4.贝尔曼公式:矩阵-向量形式与求解
5.action value
1.return为什么重要?如何计算return?
问题:为什么return重要?
首先强化学习就是在学习最优policy,而return能够反映policy的好坏,即评估policy,因此return很重要

利用grid-world例子,return和图分别对应,严格来说,return3已经不再是return的概念,因为return是针对一条trajectory,而图三从s1开始有从s2和s3两条trajectory,这里实际上求的是期望
可以看出return1>return3>return2,所以图中第一个的policy最好,第二个的policy最差
【这里插一下】什么是期望?期望它就是表示随机变量的一种平均值(另一种理解,期望是加权平均值),以下是我对期望的理解
既然return重要,那么应该如何计算呢?刚才式子只是用定义计算的,实际上有更好的方法。
举例:

这里用v来表示return,计算return时是用discounted return公式,从s1出发的return就是v1,从图可知v1=r1+γr2+γ2r3+γ3r4+γ4r1+···,同理可得v2、v3、v4

上式还能再简洁,如对于v1,将r2开始的γ提出来,v1=r1+γv2(直观理解就是我从s1出发,跳到s2,得到r1后,就不用再继续算了,因为后面得到的return一定是v2),依此类推,得下图

这组式子可以告诉我们从不同state得到的return,是依赖于从其他state出发得到的return,就是说若要知道v1,则需要先计算v2,若要知道v2,则要知道v3,···,而这好像陷入了一种循环的、不可能解决的问题,因为我要求解v,但是我还要事先知道v,这种问题在强化学习中被成为Bootstrapping【就是用下一个state的v来更新当前state的v】
直观上好像无法解决,数学上就能轻松解决,我们可以把式子写成Matrix-vector(矩阵-向量)形式,如下图

图上面的形式就可以简写成写图下的公式,这样,v是未知的,r、γ、P是已知的,利用线性代数就可以轻松解出,下面利用一个例题说明一下过程

回到目录
2.state value的定义
为了知道state value,首先引入几个符号,首先看单步的过程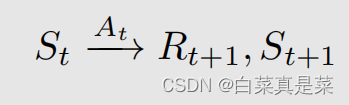
t是指当前时刻,t+1是下一个时刻,St是指t时刻的state,At是指在t时刻的St下,采取的action,Rt+1就是采取At后的奖励【这里写成Rt+1有时也写成Rt,我觉得Rt更符合,但一般写成Rt+1,不用纠结】,St+1就是转移后的state,这些符合都是大写,大写就代表random variable(随机变量),即能对它们求一些列的操作,如期望等,这些情况的取值转换如下图所示
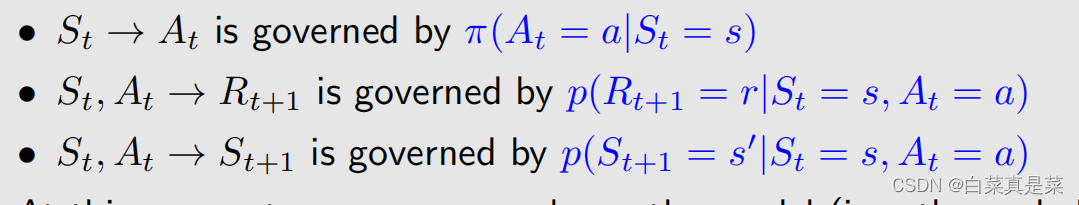
单步的过程可以推到多步的trajectory,这里是多条trajectory,而不是只有一条,是将多条合并一起表示,如下所示
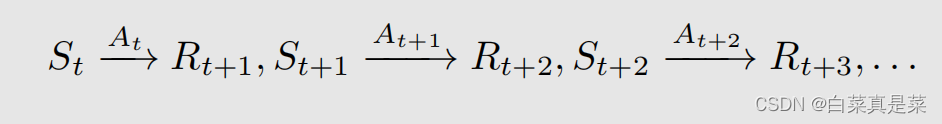
它的discounted return用Gt表示,就是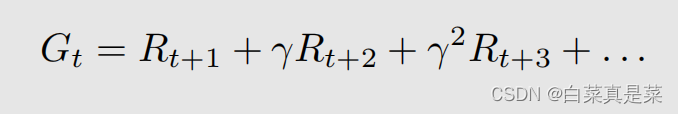
因为这些Rt+1、Rt+2都是随机变量,所以Gt也是随机变量
有了上面,那么来说说什么是state value
state value全称是state value function(状态价值函数),用vπ(s)来表示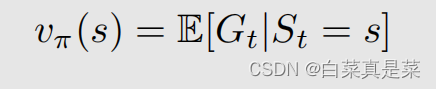
state value就是Gt的期望值,但这是一个条件期望,也就是当前的state应该取一个具体的值s
值得注意:
①这个vπ(s)是关于当前s的函数,所以从不同的s出发,得到的trajectory不同,那得到的discounted return就不同,那求期望也是不同的
②这是一个基于策略(policy)的函数,vπ(s)可以写成v(s,π),π是变量,但为了简单起见就写成vπ(s),不同的策略又会得到不同的轨迹,不同的轨迹就会得到不同的discounted return,进而得到不同的state value
③state value的value是数值,代表着价值,当state value比较大时,就表示这个state是比较有价值的,因为会得到更多的discounted return
那么state value 和return有什么区别?
return是针对单条trajectory求的return,state value是针对多条trajectory求的return再求期望,如果从一个state出发,有多条trajectory,那么state value和return就有区别,如果从一个state出发,一切都是确定的,只有一条trajectory,那么此时state value就等于return
举个例子,下图所示:
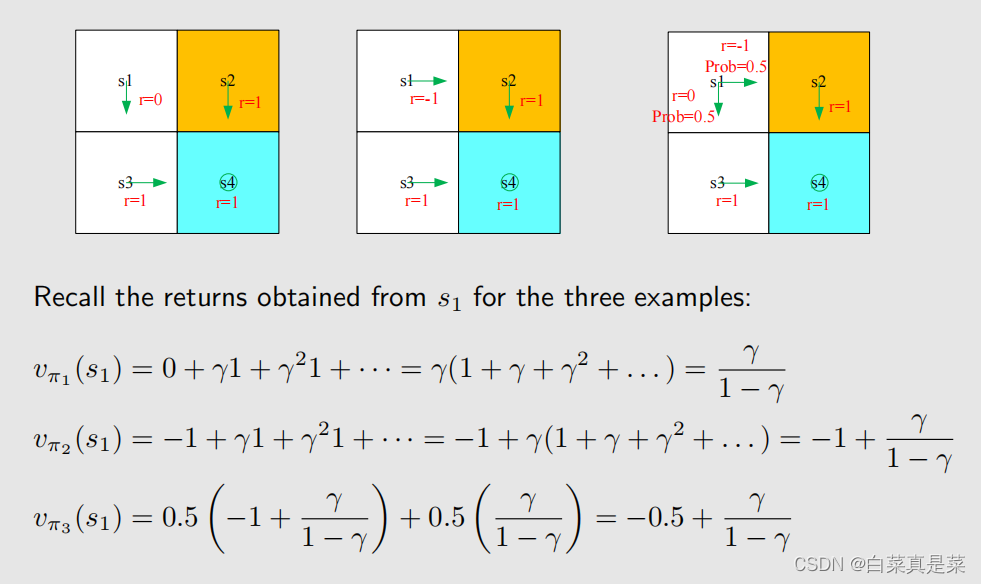
对于第一、第二个图,从s1出发,它们的转换是确定的,只有一条trajectory,此时return就等于vπ(s1),第三个图从s1出发,它们的转换是随机的,因此state value 就不等于return(这里return是有两个的,以往举例时为了方便我们只是将state value当作return来看,但现在得分开),所以vπ3(s1)就等于求discounted return期望
回到目录
3.贝尔曼公式:推导过程
上一块已经说明了state value,state value既然和return挂钩,就说明它很重要,同样能评判policy好坏,那么如何求state value?用Bellman equation(贝尔曼公式)
贝尔曼公式用一句话说明就是它描述了不同状态的state value之间的关系
那么先对贝尔曼公式进行推导
首先给一条trajectory
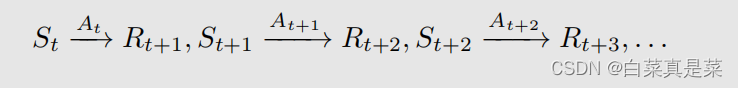
它的discounted return Gt就是
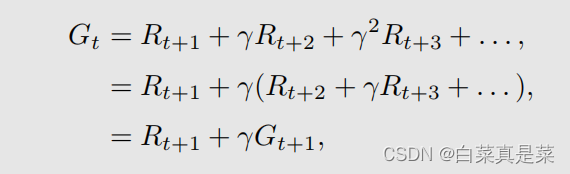
这里只是将其进行提取转换,那么它的state value就是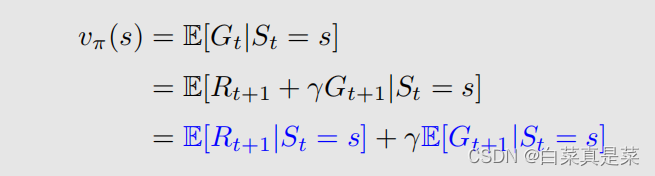
将刚才得到的Gt代换得到,并用到了期望的运算性质 E(X+Y)=E(X)+E(Y)【X、Y都是随机变量】
现在已经将公式拆分成了两部分,分别对这两部分进行求解,首先是+号左边
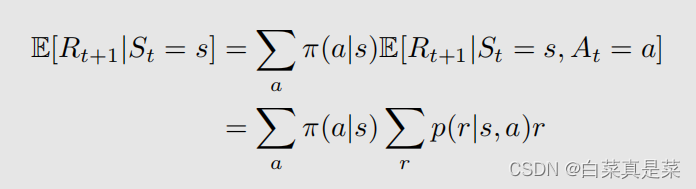
等式左边如何变成右边的呢?
首先要明确reward Rt+1是如何得到的,它是在状态s下,采取动作a后,根据做出的动作得到的奖励,因此奖励是和动作有关的,那么对一个奖励求期望,就是求在所有的动作下,得到动作的概率乘上对应动作的奖励值,因为一个动作可能会有多个奖励值,所以这个奖励值是一个期望,因此,等式左右同等右边,右边部分的在状态s和a下求 Rt+1的期望,这个就是奖励r值乘上其概率而得到的,下图是我个人理解

接下来是另一部分的转换过程
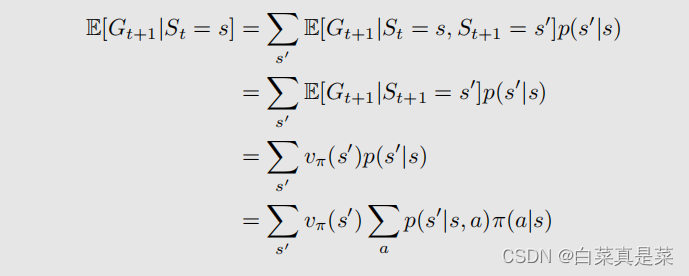
这里我们是求t+1时刻的return Gt+1的期望,但是条件概率St=s,求的是s的下一刻状态s’的return,所以Gt+1的期望就等于跳到所有下一刻状态s’的概率乘上return的期望值的总和,而在下一时刻状态s’的return的期望就是下一时刻状态s’的state value,所以转换成vπ(s’),那么跳转到下一个状态s’的概率的计算就是刚刚举例的图,先选动作π(a|s)后在选择跳的状态p(s’|s,a),然后对下一个状态s‘以及对应动作进行循环即可【其中第一行等式右边St=s能去掉的原因是因为已经知道了St+1,根据MDP的性质无记忆性,当前状态s就可以忽略】

这是这两个的含义
最后vπ(s)就等于下式
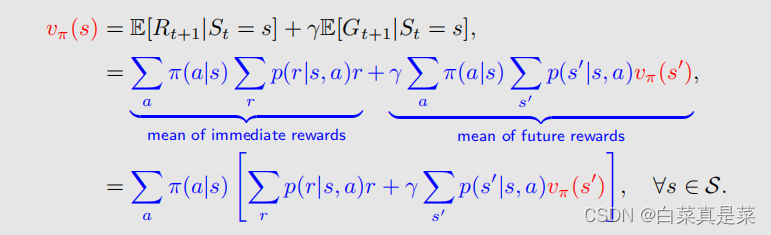
这里只是提取了一个公因子,且式子对所有的s∈S都成立
上式就是贝尔曼公式,它实际上就是描述了不同状态的state value之间的关系,如果有n个状态,我们就可以通过n个式子求解出来,具体怎么求可以看上面1的内容,用到Bootstrapping,但是贝尔曼公式不只是这一个式子
从公式可看到,贝尔曼公式含有π(a|s),是依赖策略policy的,所以计算出state value,就是对policy的评估,还有其中的p{r|s,a)和p{s’|s,a)两个概率,它们就叫dynamic model(或environment model),如果知道这两个model来计算state value就是有模型的强化学习,如果不知道这两个model,同样也能计算出state value,但这时是无模型的强化学习
回到目录
4.贝尔曼公式:矩阵-向量形式与求解
有了贝尔曼公式,接下来要开始计算贝尔曼公式,根据公式,将所有s的公式整理成一个矩阵-向量形式,如何变成这样的形式,首先将原来的贝尔曼公式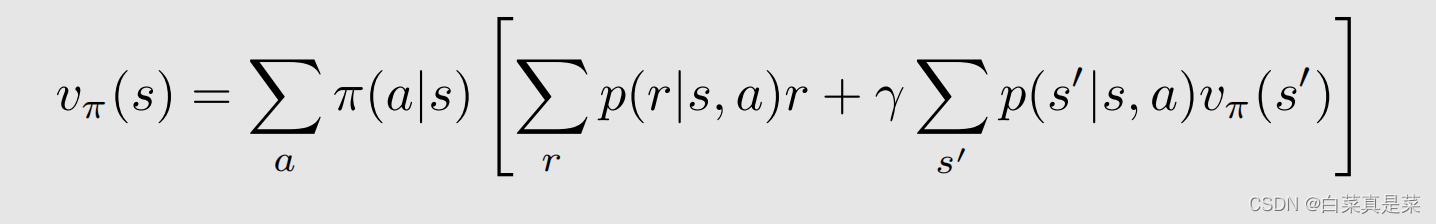
做一个演化,令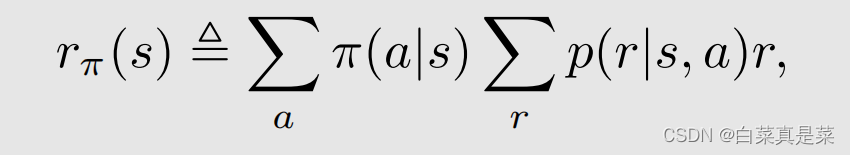
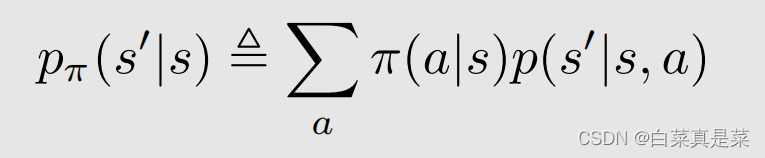
这样就得到一个简化的式子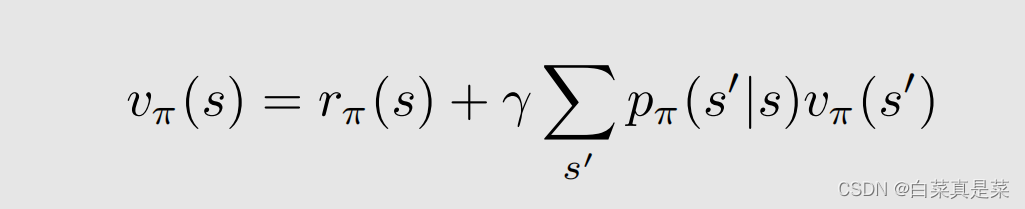
为了要写成矩阵-向量的形式,因此要把所有的状态都写到一起,这时候对不同的状态标上号,用来区分是哪个状态,这样式子就变成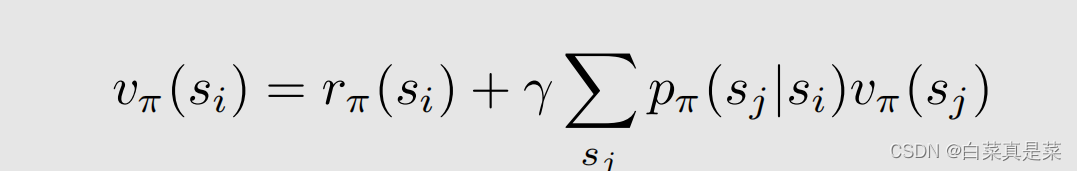
i、j∈(1,2,3,…,n),再简写一下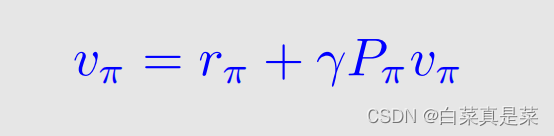
此时上式元素分别表示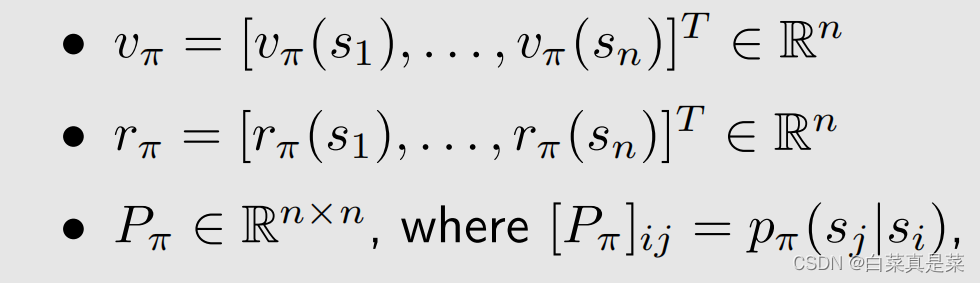
这里Pπ就是状态转移矩阵,[Pπ]ij表示第i行、第j列的元素是从si跳到sj的概率,这里举个例子,当n=4时改表达式的样子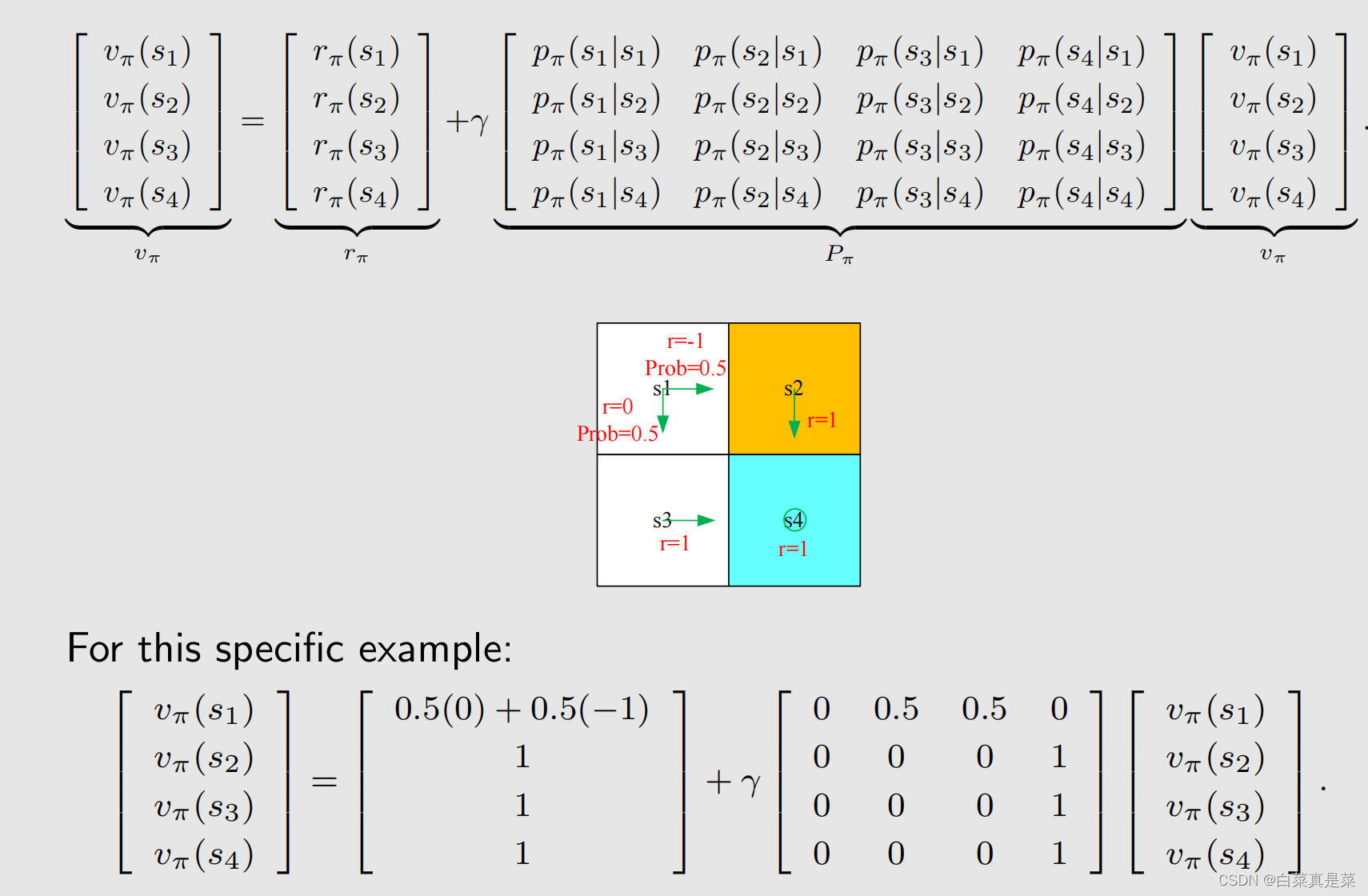
这就是贝尔曼公式的矩阵-向量形式
接下来是求解state value,求解state value也是在做policy evaluation策略评估这样一件事,因为只有评价一个策略好或者不好后,才能进一步去改进策略,最后找到最优策略
那对于刚刚的式子,我们求解的方式是求逆得到的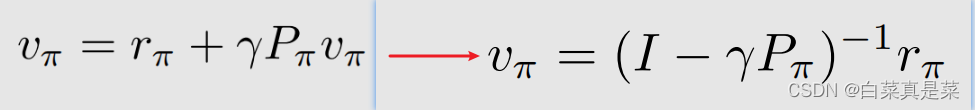
但是实际中并不会用到该求解方式,因为实际状态空间是非常大的,这时候矩阵的维数也会比较大,求逆的计算量也会比较大,因此实际计算中常用一个迭代的方法,即
计算过程如下
为什么当k趋于∞时,vk->vπ,下面是证明

简单翻译就是
下图举个例子,首先定义rboundary=r=forbidden=-1,即当超越边界和进入禁区时奖励是-1,到达目标区时奖励+1。 γ取0.9
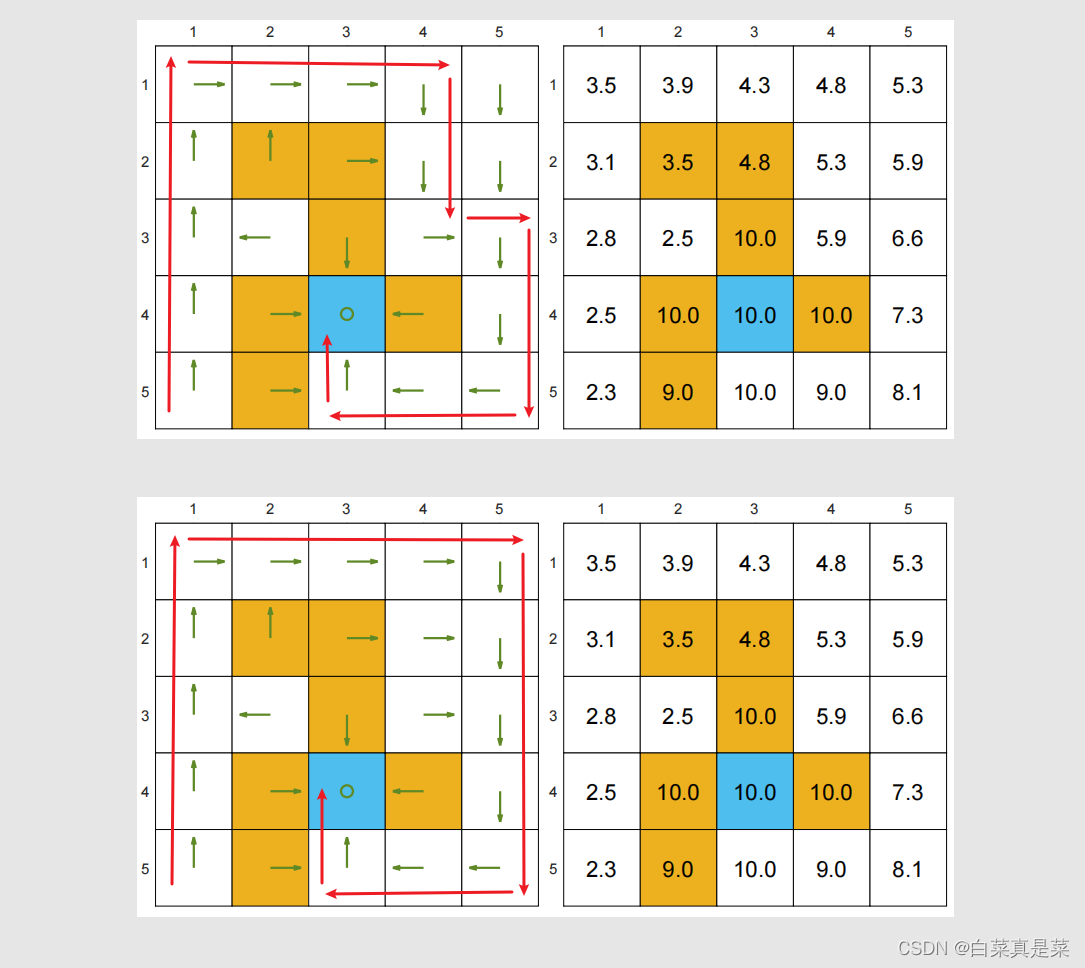
上图展示的是两个比较好的策略,该策略不会进入禁区,也不会超越边界,,数字图表示该点的state value,可以发现,距离蓝色目标区越近的点,它的state value越大,说明越有价值,这两个策略虽然走法不同,但是state value是一样的(不同的策略是能够得到相同的state value的,因为图中走法不同,但是实际上步数一样,得到结果也一样)
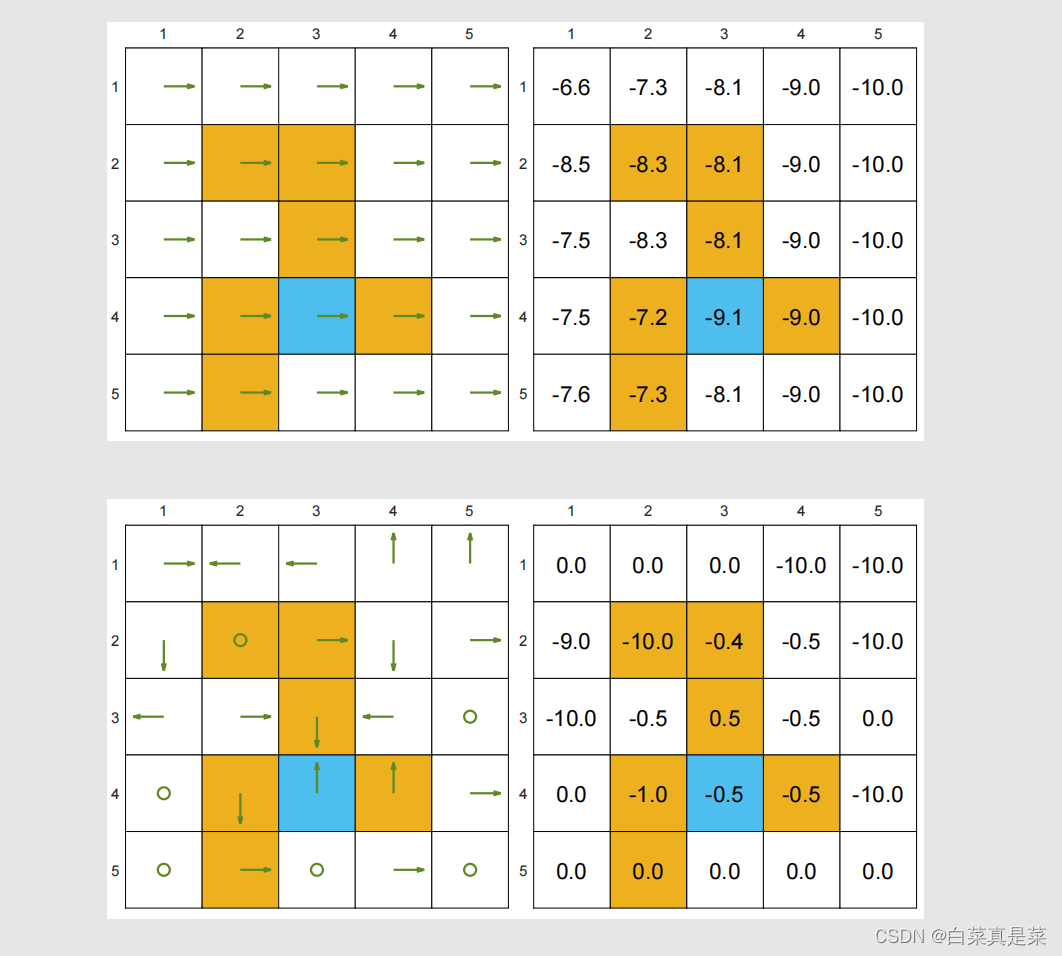
上图是两个比较差的策略,是随机生成的,可以看到,它们的state value都很差,对比上图和上上图,可以明显看到,我们可以计算state value来评价一个策略究竟是好还是不好
回到目录
5.action value
了解了state value,再了解action value,action value同样也很重要,那这两者有什么区别和联系
state value是指agent从一个状态出发所得到的average return
action value是指agent从一个状态出发并且选择了一个动作之后所得到的average return
为什么关注action value,是因为实际上我们一直讨论强化学习中的策略,而策略指的是在一个状态我要选择什么样的action,如何选择action呢?实际上就是根据action value进行选择,action value大意味着选择的action能得到更多的reward
action value定义如下
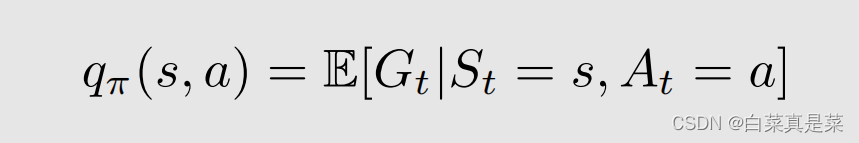
从这个熟悉的式子结合state value的式子,就可以直观的感受到state value和action value两者间的联系
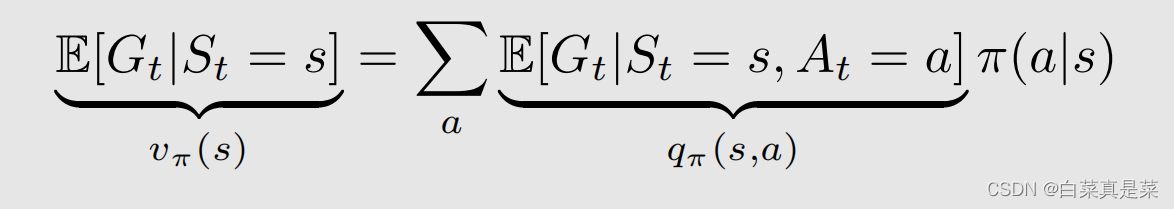
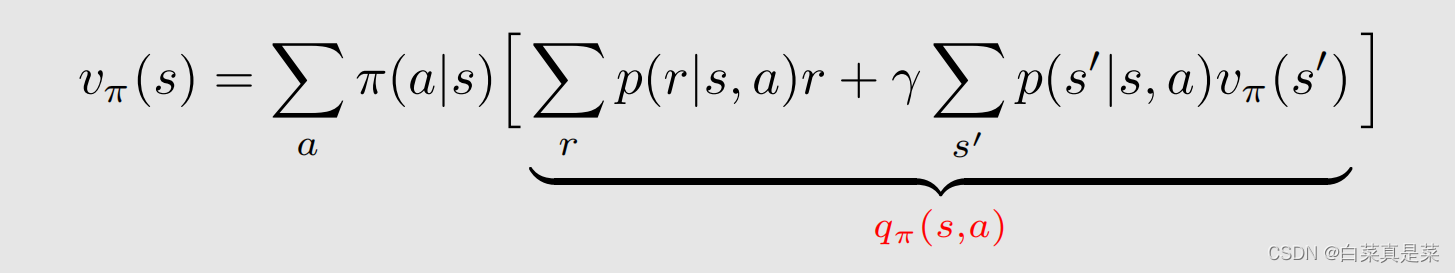
简写一下就是
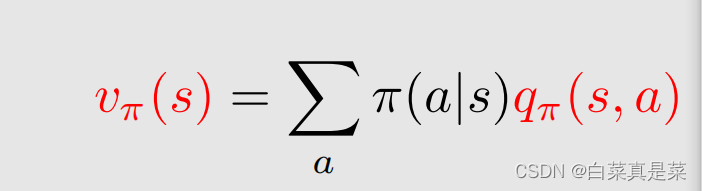
也就能推导出具体的式子
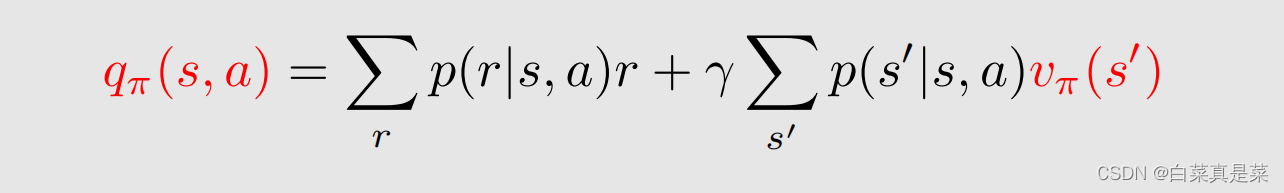
上式和上上式说明了
①对于一个状态所有的action value我都知道了,求期望,实际上就得到了这个状态的state value
②如果知道了所有状态的state value,那么就能求出所有的action value
接下来看一个例子
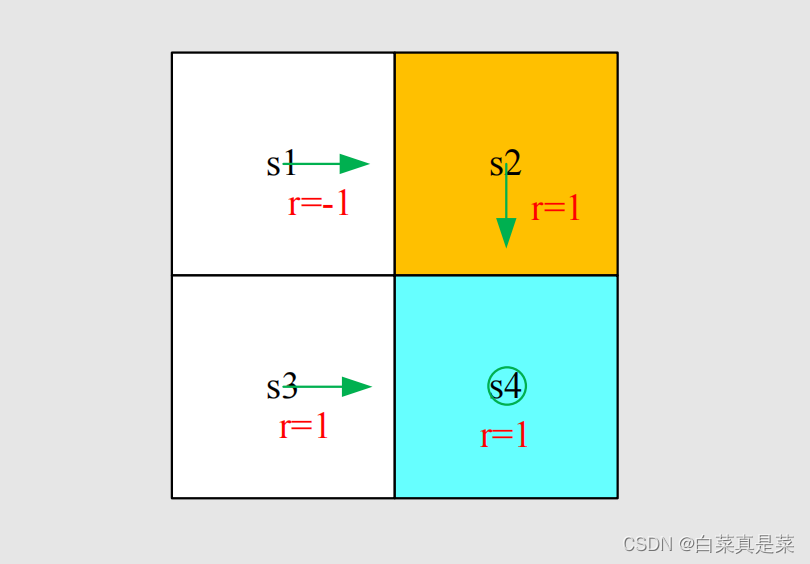
根据图中的信息,可以计算出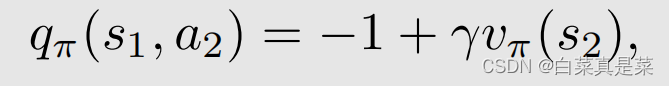
注意一个容易出错的点:图中策略只给了s1采用a2的策略,但是除了a2之外,还有a1、a3、a4、a5这些action,那么它们的action value是什么?有人可能认为是0,因为策略只告诉应该向右走,即应该采用a2,其他的action就不管了,这个实际上是不对的。虽然策略现在告诉我们往右走,但实际上这个策略可能是不好的,未来我们希望在当前状态的其他action好与不好,如果其他的action value很大,也许我们下一个时刻就会选择那个action,这个是一种策略改进的算法。虽然策略只给了a2,但是其他action也是可以计算的,举个例子
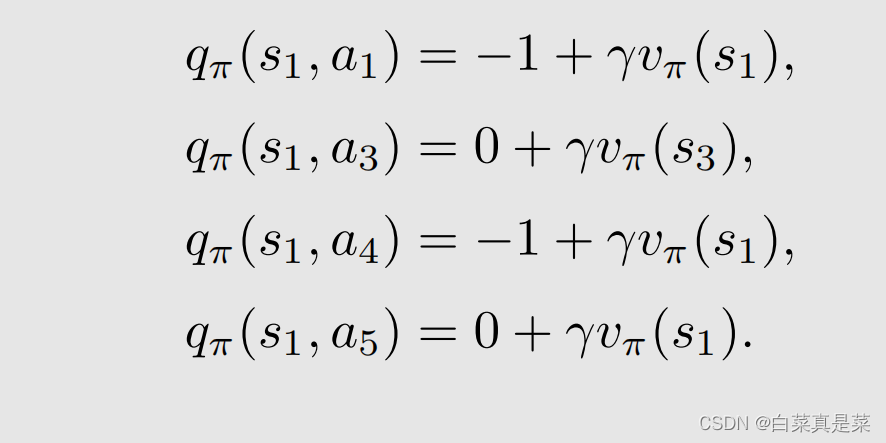
这里的-1是因为撞到边界了
如何计算action value呢?
①可以先求解了一个贝尔曼公式,然后从state value中计算出来action value
②不计算state value,直接计算action value,比如说通过数据的方式,未来会介绍
小结:

欢迎指正!















 1814
1814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









