






HDFS的结构及其作用
1.知识准备
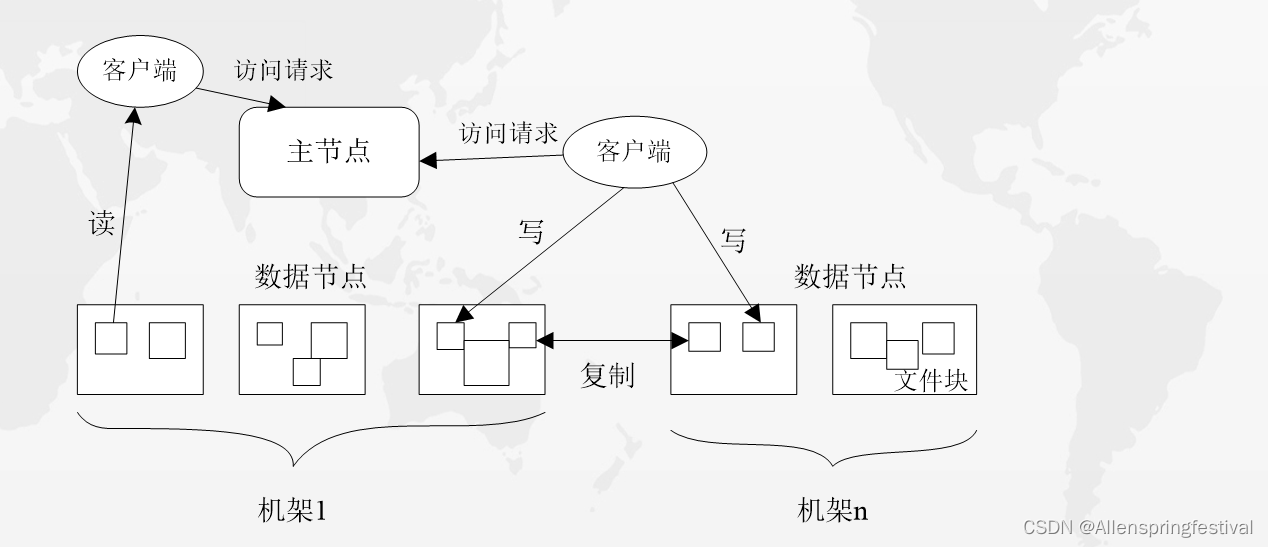
分布式文件系统在物理结构上是由计算机集群中的多个节点构成的,这些节点分为两类,一类叫“主节点”(Master Node)或者也被称为“名称结点”(NameNode),另一类叫“从节点”(Slave Node)或者也被称为“数据节点”(DataNode)。
分布式文件系统结构图:
HDFS要实现以下目标:
1.兼容廉价的硬件设备
2.流数据读写
3.大数据集
4.简单的文件模型
5.强大的跨平台兼容性
HDFS的应用局限性
1.不适合低延迟数据访问
2.无法高效存储大量小文件
3.不支持多用户写入及任意修改文件
2. HDFS的主要组件和功能(结构以及作用)
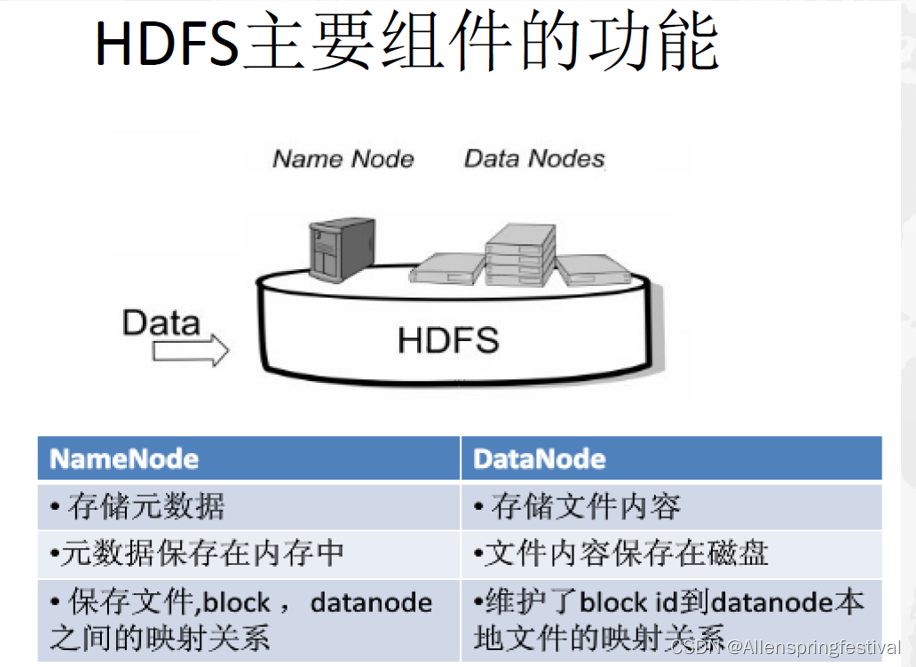
3.名称节点和数据节点
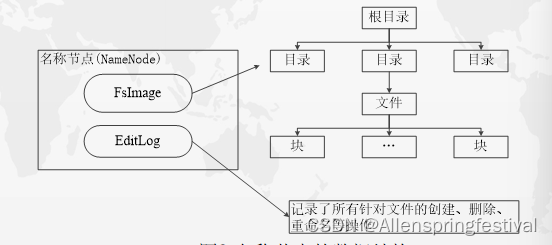
3.1名称节点的数据结构
在HDFS轰namenode负责分布式文件系统的命名空间,保存了两个核心的数据结构,即FslImage和Editlog。
1.Fslmage用于维护文件系统以及文件树中所有的文件和文件夹的元数据
2.Editlog记录了所有针对文件的创建,删除,重命名等操作
名称节点记录了每个文件中各个块所在的数据节点的位置信息。
名称节点的启动
在名称节点启动的时候,它会将Fslmage文件中的内容加载到内存中,之后再执行Editlog文件中的各项操作。使得内存中的元数据与实际的同步,存到内存中的元数据支持客户端的读操作。
一旦在内存中成功建立文件系统元数据的映射,则创建一个新的Fslmage文件和一个空的Editlog文件。
名称节点起来之后,HDFS中的更新操作会重新写到Editlog文件中,因为FslImage文件一般都很大,如果所有的更新操作都往FslImage文件中添加,系统运行将变得非常缓慢。
当如果往EditLog文件里面写就不会这样,应为Editlog要小很多,每次执行写操作之后,且在向客户端发送成功代码之前,edits文件都需要同步更新。
3.2 数据节点
负责数据的存储和读取,会根据客户端或者名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表。
每个数据节点的数据会被保存在各自节点的本地Linux文件系统中。
Hbase简介
Hbase时一个高可靠,高性能,面向列,可伸缩的分布式数据库,是谷歌Bigtable的开源实现,主要用来存储非结构化和半结构化的的松散数据。Hbase的目标是处理非常庞大的列表,可以通过水平扩展的方式,利用廉价的计算机集群处理超过10亿数据和数百万列元素组成的数据表。
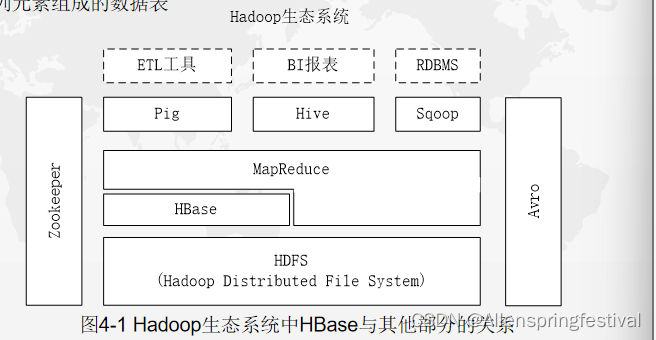
对应关系
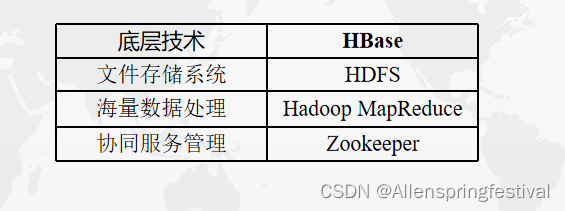
关系数据库已经有了HDFS和Mapreduce,为什么需要Hbase呢?
Hadoop可以很好地解决大规模数据的离线批量处理的问题,但受限于Mapreduce编程框架的高延迟数据处理机制,使得Hadoop无法满足大规模数据实时处理应用的需求。
HDFS面向批量访问模式,不是随机访问模式。
传统的通用关系数据库无法应对在数据规模剧增时导致的系统扩展性和性能问题。
(就算是分库分表也不能很好解决)
传统数据库在数据结构变化时一般需要停机维护
因此,业界出现了一类面向半结构化存储和处理的高可扩展,低写入/查询延迟的系统,例如:键值数据库,文档数据库和列族数据库(例如BIG TABLE和HBASE)
就这样,hbase就成功应用于互联网服务领域和传统行业的众多在线式数据分析系统中。
hbase与传统数据关系数据库的对比分析
(问答题可能会考)
hbase与传统的关系数据库的区别主要体现在以下几个方面:
(1)数据类型:关系数据库采用关系模型,具有丰富的数据类型和存储方式,Hbase则采用更加简单的的数据模型,他把数据存储为未经解释的字符串。
(2)数据操作:关系数据库包含了丰富的操作,其中涉及多表连接。Hbase操作则不存在复杂的表与表之间的关系,只有简单的插入,查询,删除,清空等,因为Hbase在设计上就避免了复杂的表与表之间的关系。
(3)存储模式:关系数据库是基于行模式存储的。Hbase是基于列存储的,每个列族都由几个文件保存,不同列族的文件是分离的。
(4)数据索引:关系数据库通常可以针对不同列构建复杂的多个索引,以提高数据访问性能。Hbase只有一个索引——行键,通过巧妙的设计,Hbase中所有的访问方法,或者通过行键访问,或者通过行键扫描,从而使整个系统不会慢下来。
(5)数据维护:关系数据库更新操作会用最新的当前值去替代原来的旧值,旧值被覆盖后就不会存在。Hbase执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧的版本仍然保留。
(6)可伸缩性:关系数据库很难实现横向扩展,纵向扩展,纵向扩展也有限。HBASE和BIGTABLE就是为了实现灵活的水平扩展而开发的,能够轻易地通过在集群中增加或减少硬件数量来实现性能的伸缩。
Flume 有两大类 HBasesinks: HBaseSink 和 AsyncHBaseSink。















 3393
3393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









