






书接上回~
目录
三、最短路
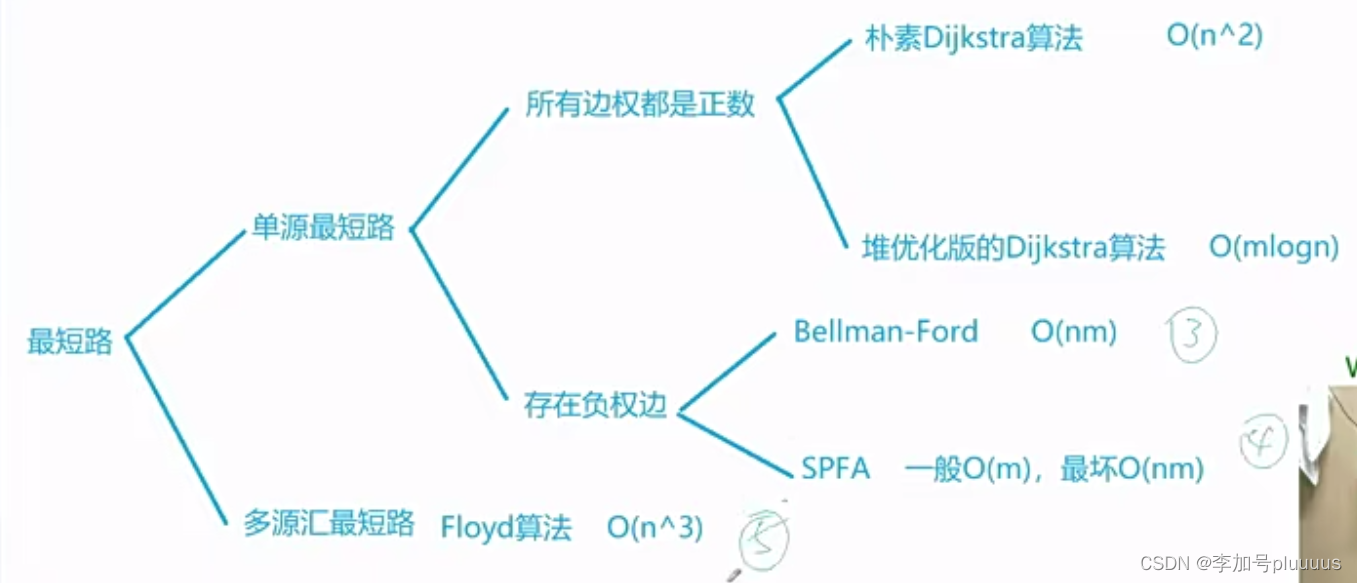
要注意时间复杂度,和题目给出的数据范围,是一种提示。
- 如果n=200,m很大,floyd
- 如果n、m都很大,spfa、堆优化的dijkstra
含义
在网图和非网图中,最短路径的含义是不同的。由于非网图没有边上的权值,所谓最短路径,其实指的就是两个顶点之间经过的边数最少的路(即可以理解为把每一条边的权值看作是1)。
对于网图来说,最短路径,是指两顶点之间经过的边上的权值之和最少的路径,并且我们称路径上的第一个顶点是源点,最后一个顶点是终点。
求带权有向图G的最短路径问题一般可分为两类:一是单源最短路径,即求图中某一个顶点到其它顶点的最短路径,可以通过经典的 Dijkstra(迪杰斯特拉)算法求解;二是求每对顶点间的最短路径,可通过Floyd(弗洛伊德)算法来求解。
单源最短路
3. 1 Dijkstra
Dijkstra算法算法思路是设置一个集合S记录已求得的最短路径的顶点,初始时把源点V0(图中的某个顶点)放入S,集合S每并入一个新顶点 Vi,都要修改源点V0到集合 V-S 中顶点当前的最短路径长度值
假设从顶点 V0 = 0出发,邻接矩阵Edge表示带权无向图,Edge[i][j]表示无向边 (i, j)的权值,若不存在无向边(i, j),则Edge[i][j] == ∞。
Dijkstra算法步骤:
- 初始化:集合S初始化为{0},dist[ ] 的初始值dist[i] = Edge[0][i],path[ ]的初始值path[i] = -1,i = 1,2,...,n-1。
- 从顶点集合 V - S中选出Vj,满足dist[j] = Min{dist[i] | Vi∈ V - S},Vj就是当前求的一条从 V0 出发的最短路径的终点,令S = S∪{j}。
- 修改从V0出发到集合 V - S上任一顶点 Vk 可达的最短路径长度:若 dist[j] + Edge[j][k] < dist[k],则更新 dist[k] = dist[j] + Edge[j][k],并修改path[j] = k(即修改顶点Vk的最短路径的前驱结点 ) 。
- 重复 2~3操作共 n-1 次,直到所有的顶点都包含在 S 中。

举例:
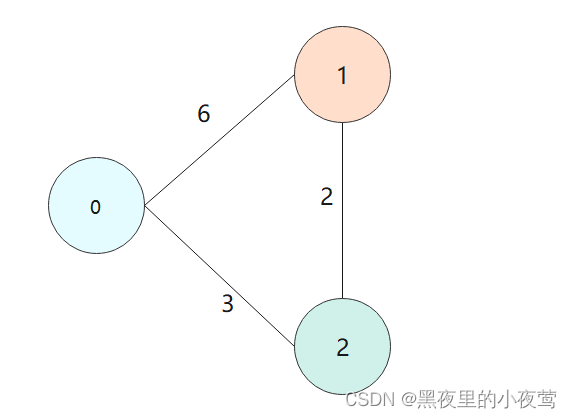
每当一个顶点加入S后,可能需要修改源点V0 到集合 V-S中的可达顶点当前的最短路径长度。下面举一个例子。如下图所示,源点为V0,初始时S = {V0},dist[1] = 6, dist[2] = 3,当 V2 并入集合S后,dist[1] 需要更新为 5(其比6小,即说明两点之间不是直线最短,要根据两点之间路径的权值之和来看)。
(参考:图算法——求最短路径(Dijkstra算法)_黑夜里的小夜莺的博客-CSDN博客)
3.1.1 朴素版
acwing 849. Dijkstra求最短路(一) 朴素版本
给定一个 n 个点 m 条边的有向图,图中可能存在重边和自环,所有边权均为正值。
请你求出 1 号点到 n 号点的最短距离,如果无法从 1 号点走到 n 号点,则输出 −1。
输入格式
第一行包含整数 n 和 m。接下来 m 行每行包含三个整数 x,y,z,表示存在一条从点 x 到点 y 的有向边,边长为 z。
输出格式
输出一个整数,表示 1 号点到 n 号点的最短距离。如果路径不存在,则输出 −1。输入样例:
3 3
1 2 2
2 3 1
1 3 4
输出样例:
3
示例:acwing 849. Dijkstra求最短路(一) 朴素版本__刘小雨的博客-CSDN博客
下面有一个例子示范:
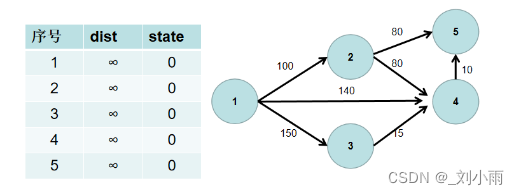
按照上面的步骤操作
1.源点到源点的距离为 0。即dist[1] = 0。
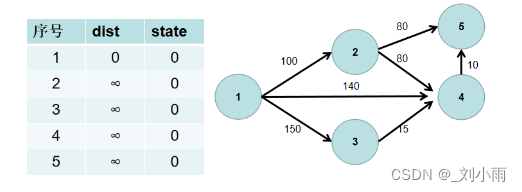
2.遍历 dist 数组,找到一个节点,这个节点是:没有确定最短路径的节点中距离源点最近的点。假设该节点编号为 i。此时就找到了源点到该节点的最短距离,state[i] 置为 1。
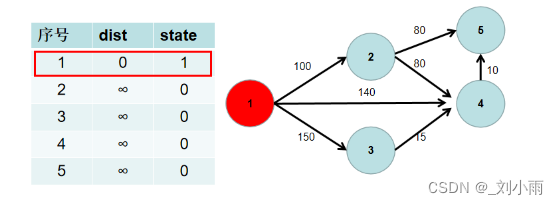
3. 遍历 i 所有可以到达的节点 j,如果 dist[j] > dist[i] + i 到 j 的距离,即 dist[j] > dist[i] + w[i][j](w[i][j] 为 i -> j 的距离) ,则更新 dist[j] = dist[i] + w[i][j]
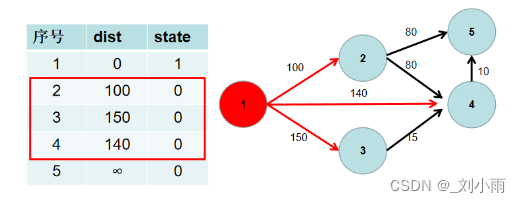
4. 重复 2 3 步骤,直到所有节点的状态都被置为 1。
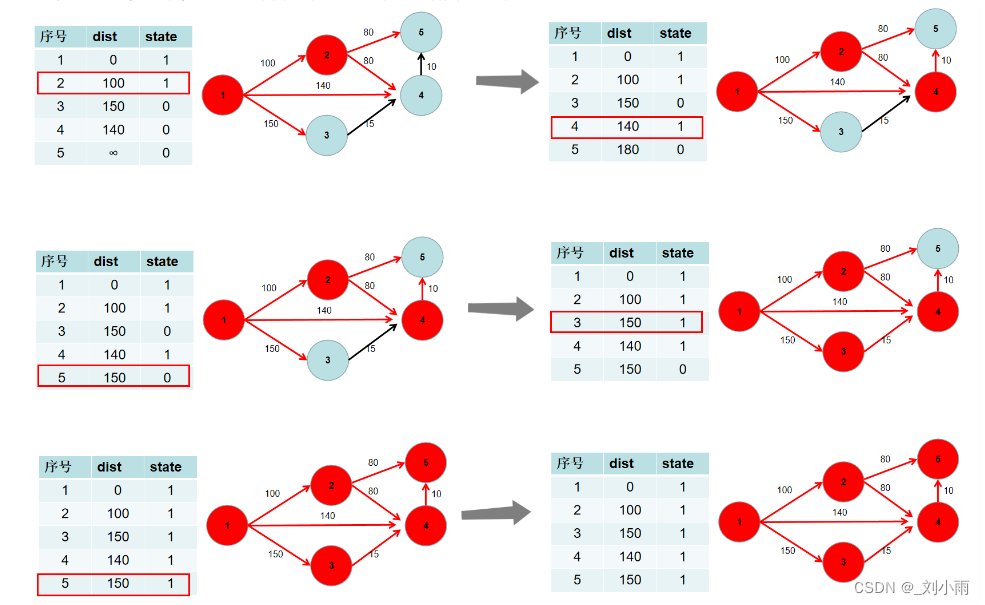
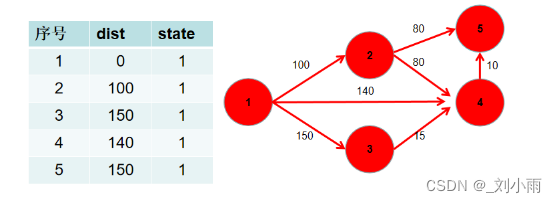
此时 dist 数组中,就保存了源点到其余各个节点的最短距离。
for(int j = 1; j <= n; j ++)
if(!st[j] && (t == -1 || dist[t] > dist[j])) // 寻找还未确定最短路径的点中路径最短的点。第一次循环时用到条件t=-1,之后只用第二个条件:比较
t = j; - ! st[ j ] :还未确定最短路径
- dist[ t ] > dist[ j ] :选择路径最短的点
- i = 0 :最外层的for第一次循环,找到t = 1,标记st[1] = true,节点1的邻接点有2、3、4,更新1节点到这几个点的距离。代码的实际写法其实更新了点1到所有点的距离,对于不可达的点,路径长度为0x3f,无限大,所以逻辑上等同于没有更新。
- i = 1 :for第二次循环,找到t = 2,标记st[2] = true,起点到2节点的最短路径已找到。节点2的临界点有4、5,更新2节点到这几个点的距离。
- 最外层for循环n次,找到n个点,起点到n节点的最短路径都已找到。
代码:
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510;
int g[N][N]; // 邻接矩阵,用于存储图中各个节点之间的连通情况和权值,其中(a,b)=c 表示存在一条从a点指向b点的边
int dist[N]; // 存储每一个点到第一个点的最短距离
bool st[N]; // 标记:每一个节点的最短路径是否已经确定
int n,m; // n:图中点的数量,m:图中边的数量
int Dijkstra(){
memset(dist, 0x3f, sizeof dist); // 初始化,将每个节点到源点的初始距离设为无限大
dist[1] = 0; // 源点到自身的距离为0
for(int i =0; i < n; i ++){ // // 在还未确定最短路的点中,寻找距离最小的点。可以优化
int t = -1; // t用于存储当前访问的节点编号,初值设为-1
// 找个t点:在st数组中所有为false的点中找到dist值最小的点
for(int j = 1; j <= n; j ++)
if(!st[j] && (t == -1 || dist[t] > dist[j])) // 寻找还未确定最短路径的点中路径最短的点。第一次循环时用到条件t=-1,之后只用第二个条件:比较
t = j;
st[t] = true; // 标记起点到t点的最短距离已经确定
// 遍历每个点,更新到达该点的最短路径值
for(int j = 1; j <= n ;j ++) // 只需要遍历t之后的点,1~t不需要访问的,可以优化
if(!st[j]) // 点j没被访问过
dist[j] = min(dist[j], dist[t] + g[t][j]); // 使用已知的最短路径来更新其他节点的最短路径
}
// 如果第n个点的最短路径值仍为无穷大,则说明不存在从源点到这个点的路径
if(dist[n] == 0x3f3f3f3f) return -1;
return dist[n]; // 返回从源点到目标点的最短路径长度
}
int main(){
cin >> n >> m;
memset(g, 0x3f, sizeof g); // 初始化邻接矩阵g,将所有的边的初始权值设为无限大
while (m -- ){
int a, b, c;
cin >> a >> b >> c; // 每条边的两个端点a、b以及该边的权值c
g[a][b] = min(g[a][b], c); // 如果存在重边(即两个节点之间存在多条边),则保留最短的那条边
}
cout << Dijkstra() << endl;
return 0;
}
最外层for循环的作用就是遍历所有节点。每次循环中,我们会找出当前未访问的节点中距离起始点距离最小的节点,然后更新其相邻节点的距离。
3.1.2 堆优化版
acwing 850. Dijkstra求最短路(二)堆优化版本
题目同上,区别在于:
- 这里是稠密图,需要改成邻接表形式存储
- 用堆进行优化,降低时间复杂度
如何判断稠密图还是稀疏图:
- 稠密图: 边数量 = 点数量的平方
- 稀疏图 : 边和点的数量差不多1: 1
用邻接表存的话,无所谓重边,不需要特殊处理
代码:
#include<iostream>
#include<cstring>
#include<algorithm>
#include<queue>
using namespace std;
const int N = 10010;
int h[N], ne[N], e[N], w[N], idx;
int m, n;
int dist[N];
int st[N];
typedef pair<int, int> PII;
void add(int a, int b, int c){
w[idx] = c;
e[idx] = b;
ne[idx] = h[a];
h[a] = idx++;
}
int Dijkstra(){
priority_queue<PII, vector<PII>, greater<PII>> heap; // 小顶堆,用于存储节点和距离的二元组
heap.push({0,1});
// pair排序时是先根据first,再根据second,这里要根据距离排
// 因为用的是邻接表存储,这里存储的是下标)
while(heap.size()){
auto t = heap.top(); // 取堆顶(最小值)
heap.pop();
int ver = t.second; // 当前节点编号
int distance = t.first; // 当前节点到源点的距离
if(st[ver]) continue; // 如果当前节点的最短路径已经确定,则跳过
for(int i = h[ver]; ~i; i = ne[i]){ // 遍历当前节点的所有邻接节点
int j = e[i]; // 邻接节点的编号
if(dist[j] > distance + w[i]){ // 如果通过当前节点能够获得更短的路径,则更新最短路径值
dist[j] = distance + w[i];
heap.push({dist[j], j}); // 并将新路径加入堆中
}
}
}
if(dist[n] == 0x3f3f3f3f) return -1; // 如果终点n的最短路径值仍为无限大,则说明不存在从源点到终点的路径
return dist[n];
}
int main(){
memset(h, -1, sizeof h); //初始化图 因为是求最短路径, 所以每个点初始为无限大
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
cin >> n >> m;
while(m--){
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
}
cout << Dijkstra();
return 0;
}对比朴素做法:省略了一层for循环
里面的优先队列的用法:C++ 语言中 priority_queue 的常见用法详解 - 知乎 (zhihu.com)
priority_queue<PII, vector<PII>, greater<PII>> heap;vector<PII>(也就是第二个参数)是来承载底层数据结构堆(heap)的容器,里面的参数类型要与第一个参数PII要保持一致。如果是int,则此处需要填写vector<int>;
而第三个参数 greater<PII> 则是对第一个参数的比较类,less<int> 表示数字大的优先级越大,而 greater<int> 表示数字小的优先级越大。把最小的元素放在队首。
常用函数:
(1)push():令 x 入队,时间复杂度为 O(logN),其中 N 为当前优先队列中的元素个数。
(2)top():获得队首元素(即堆顶元素),时间复杂度为 O(1) 。
(3)pop():令队首元素(即堆顶元素)出队,时间复杂度为 O(logN),其中 N 为当前优先队列中的元素个数。
(4)empty():检测是否为空,返回 true 则空,返回 false 则非空。时间复杂度为 O(1)。
(5)size():返回优先队列内元素的个数,时间复杂度为 O(1)。
注意:优先队列没有 front() 函数与 back() 函数!只能通过 top() 函数来访问队首元素(也可以称为堆顶元素),也就是优先级最高的元素。因为其实现原理是堆。
代码:
#include<iostream>
#include<cstring>
#include<algorithm>
#include<queue>
using namespace std;
const int N = 10010;
int h[N], ne[N], e[N], w[N], idx;
int m, n;
int dist[N];
int st[N];
typedef pair<int, int> PII;
void add(int a, int b, int c){
w[idx] = c;
e[idx] = b;
ne[idx] = h[a];
h[a] = idx++;
}
int Dijkstra(){
priority_queue<PII, vector<PII>, greater<PII>> heap; // 小顶堆,用于存储节点和距离的二元组
heap.push({0,1});
// pair排序时是先根据first,再根据second,这里显然要根据距离排序
// {}中存储的是:点的距离最小值,点的边下标(因为用的是邻接表存储,这里存储的是下标)
while(heap.size()){
auto t = heap.top(); // 取堆顶(最小值)
heap.pop();
int ver = t.second; // 当前节点编号
int distance = t.first; // 当前节点到源点的距离
if(st[ver]) continue; // 如果当前节点的最短路径已经确定,则跳过
for(int i = h[ver]; ~i; i = ne[i]){ // 遍历当前节点的所有邻接节点
int j = e[i]; // 邻接节点的编号
if(dist[j] > distance + w[i]){ // 如果通过当前节点能够获得更短的路径,则更新最短路径值
dist[j] = distance + w[i];
heap.push({dist[j], j}); // 并将新路径加入堆中
}
}
}
if(dist[n] == 0x3f3f3f3f) return -1; // 如果终点n的最短路径值仍为无限大,则说明不存在从源点到终点的路径
return dist[n];
}
int main(){
memset(h, -1, sizeof h); //初始化图 因为是求最短路径, 所以每个点初始为无限大
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
cin >> n >> m;
while(m--){
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
}
cout << Dijkstra();
return 0;
}3.2 Bellman-Ford
Bellman-Ford算法可以处理 有负权边 的最短路问题、只经过 k 条边的最短路问题。但是求负权边的最短路一般只用spfa算法,因此除了 k 边最短路问题,我们一般都不使用 Bellman-Ford算法。该算法的时间复杂度为 O(nm)。
原理:连续进行松弛,在每次松弛时把每条边都更新一下,若在n-1次松弛后还能更新,则说明图中有负环,因此无法得出结果,否则就完成。
因为一共n个点,则点1到点n的路径最长为 n - 1。假设1号点到n号点是可达的,每一个点同时向指向的方向出发,更新相邻的点的最短距离,通过n-1条路,若图中不存在负环,则1号点一定会到达n号点,若图中存在负环,则在n-1次松弛后一定还会更新。
逐遍的对图中每一个边去迭代计算起始点到其余各点的最短路径,执行N-1遍,最终得到起始点到其余各点的最短路径。(N为连通图结点数)
与迪杰斯特拉算法的区别:
- 迪杰斯特拉算法是借助贪心思想,每次选取一个未处理的最近的结点,去对与他相连接的边进行松弛操作;贝尔曼福特算法是直接对所有边进行N-1遍松弛操作。
- 迪杰斯特拉算法要求边的权值不能是负数;贝尔曼福特算法边的权值可以为负数,并可检测负权回路。
- 每次都是从源点s重新出发进行"松弛"更新操作,而Dijkstra则是从源点出发向外扩逐个处理相邻的节点,不会去重复处理节点,这边也可以看出Dijkstra效率相对更高点。
名词解释:
- 松弛操作:不断更新最短路径和前驱结点的操作。
- 负权回路:绕一圈绕回来发现到自己的距离从0变成了负数,到各结点的距离无限制的降低,停不下来。
伪代码:
// 边的结构体定义
struct
{
int a, b, w;
} e[M];
// 进行k次迭代,表示最多经过k条边可以到达的最短路
for (int i = 0; i < n; i++){
for (int j = 0; j < m; j++)
dist[b] = min(dist[b], backup[a] + w); // 松弛操作
}
每次都循环所有边,格式为(a, b, w)。因此所有边的遍历不一定使用邻接表,可以用傻瓜式的结构体数组存储。完成上述循环之后能够满足对于所有的边都有 dist[b] ≤ dist[a] + w。
为什么Bellman-Ford算法可以用来寻找负环?
这里有一个问题:如果图中存在负权回路,则最短路不一定存在。而 Beillman-Ford算法可以判断出图中是否存在负权回路。因为上述伪代码中的迭代次数是有意义的,比如说我们当前迭代了 k 次,此时获得的 dist 数组是 从源点出发,经过不超过 k 条边,走到每个点的最短距离。如果我们在进行第 n 次迭代的时候,dist 数组又发生了变化,则说明在这个最短路中,存在一条经过 n 条边的最短路,有 n 条边说明有 n+1 个结点,但是我们一共只有 n 个点,因此由于抽屉原理,这 n+1 个点中一定有两个结点完全一样,那么这个路径上一定存在负环。因此,Bellman-Ford算法可以用来寻找负环,但是一般而言,常常使用 spfa判断负环算法。
但是有一类题目只能用Bellman-Ford算法来写,那就是经过最多 k 条边的最短路径问题,这种问题只能使用Bellman-Ford算法。
本质思想:尝试能否利用 源点→a→b 来减少 源点→b 的距离。

迪杰斯特拉算法的局限性:不允许有负权边。如果有负权回路,则最短路不一定存在。而贝尔曼夫限制了最短路径的边数,比如不能超过k条边,则负权回路最多转k次,那么有负权边也可以。
比如求1-5的最短路,从3回到2,距离-1,则越循环路径越小,不存在1-5的最短路。
贝尔曼夫算法可以求负环,但时间复杂度较高,一般不用来求负环。

例题
acwing 853. 有边数限制的最短路
题目
给定一个 n 个点 m 条边的有向图,图中可能存在重边和自环, 边权可能为负数。
请你求出从 1 号点到 n 号点的最多经过 k 条边的最短距离,如果无法从 1 号点走到 n 号点,输出 impossible。
注意:图中可能 存在负权回路 。
输入格式
第一行包含三个整数 n,m,k。接下来 m 行,每行包含三个整数 x,y,z,表示存在一条从点 x 到点 y 的有向边,边长为 z。
点的编号为 1∼n。
输出格式
输出一个整数,表示从 1 号点到 n 号点的最多经过 k 条边的最短距离。如果不存在满足条件的路径,则输出 impossible。
输入样例:
3 3 1
1 2 1
2 3 1
1 3 3
输出样例:
3
backup[j] 表示每次进入第2重循环的dist数组的备份。是为了避免串联情况: 在边数限制为1条的情况下,节点3的距离应该是3,但是由于串联情况,利用本轮更新的节点2——dist[2] = 1 更新了节点3的距离,导致节点3的距离是2。
串联:先更新了2号点,然后我们用2号点更新了3号点距离起点的距离。但是3号点不能被2号点更新,否则不满足题目要求,因为题目要求最多不经过1条边。迭代次数k是有实际意义的,我们迭代1次,那我们求的最短距离就是最多不经过1条边的最短距离。
如果用 dist[b] = min(dist[b], dist[a] + w) 更新:
a b c
1 2 1 d[2] = min( d[2], d[1] + 1) = min( 1, 0 + 1) = 1
2 3 1 d[3] = min( d[3], d[2] + 1) = min( 3, 1 + 1) = 2 用的是本轮更新的节点2
1 3 3 d[3] = min( d[3], d[1] + 3) = min( 3, 0 + 3) = 4

正确做法是用上轮节点2更新的距离——dist[2] = 无穷大,来更新节点3, 再取最小值,所以节点3离起点的距离是3。

怎么保证不发生串联呢?我们保证更新的时候只用上一次循环的结果就行。所以我们先备份一下。备份之后backup数组存的就是上一次循环的结果,我们用上一次循环的结果来更新距离。所以更新距离时要写成:
dist[b] = min(dist[b], backup[a] + w);而不是:
dist[b] = min(dist[b], dist[a] + w);要保证所有迭代过程中都是依赖上一次的 dist 。只用上一次迭代的结果更新当前的距离。如果不做备份,当前 dist 值会被其他的边更新,导致错误。
代码:
#include<iostream>
#include<cstring>
using namespace std;
const int N = 510, M = 10010;
int n, m, k; // 顶点数、边数、松弛次数
int dist[N], backup[N]; // dist:起点到各个顶点的最短路径长度,backup:用于备份dist数组
struct Edge{
int a, b, w; // 边的起点、终点和权重
}edges[M];
int bellman_ford(){
for(int i = 0; i < k; i++){ // k次松弛操作
memcpy(backup, dist, sizeof dist); // 备份dist数组
for(int j = 0; j < m; j++){ // 遍历所有边
int a = edges[j].a;
int b = edges[j].b;
int w = edges[j].w;
dist[b] = min(dist[b], backup[a] + w); // 松弛操作:更新dist数组中的最短路径长度
}
}
if(dist[n] > 0x3f3f3f3f/2) return -1; // 最短路径长度超过了无穷大,则说明存在负环,返回-1
return dist[n];
}
int main(){
memset(dist, 0x3f, sizeof dist); // 初始化dist数组为无穷大
dist[1] = 0; // 起点到自身的最短路径长度为0
cin >> n >> m >> k;
for(int i = 0; i < m; i++){
int a, b, w;
cin >> a >> b >> w;
edges[i] = {a, b, w}; // 将边信息存入edges数组
}
int t = bellman_ford(); // 进行Bellman-Ford算法求解最短路径
if(t == -1) cout << "impossible";
else cout << t;
return 0;
}
注意:
为什么要这样判断?
if(dist[n] > 0x3f3f3f3f/2) return -1; 
因为可能存在: 5号结点 → n号结点的边,边权为 -2 。 5 号点和 n 号点都不可达,dist[5] = dist[n] = 0x3f3f3f3f。但是 dist[n] 可以被 dist[i] 更新为0x3f3f3f3f - 2。如果用:
if(dist[n] == 0x3f3f3f3f) return -1; 那么还是会返回-1,结果出错。
3.3 SPFA
本质是Bellman_ford算法的优化。Bellman-Ford算法比较暴力,它每一次迭代都是遍历所有边来尝试更新,但是每一次迭代的话并不是每一条边都需要更新,即 dist[b]=min(dist[b],dist[a]+w) 并不是每一次都能成功更新,会造成冗余操作。
而SPFA算法就是针对消除冗余来做优化。如果说 dist[b] 在当前迭代下变小了,那么一定是 dist[a] 变小了,因此SPFA利用BFS来做优化,队列里面维护的只有 dist 变小的结点,这样才能有可能成功更新。创建一个队列每一次加入距离被更新的结点。
时间复杂度:平均 O(m),最坏情况 O(nm)。
核心思路:我更新过谁,我就拿谁更新别人。
伪代码:
queue ← 源点
// 队列里面维护的都是变小的结点,因为只有变小的结点才有可能成功的更新
while (queue 不空)
(1) t ← q.front(); q.pop();
(2) 更新一下 t 的所有出边 t → b
如果说dist[b]更新成功且b不在队列中,queue ← b
spfa与bellman_ford区别:
- Bellman_ford算法里最后 return -1 的判断条件写的是 dist[n] > 0x3f3f3f3f / 2。而spfa算法写的是 dist[n] == 0x3f3f3f3f 。其原因在于Bellman_ford算法会遍历所有的边,因此不管是不是和源点连通的边它都会得到更新;但是SPFA算法不一样,它相当于采用了BFS,因此遍历到的结点都是与源点连通的,因此如果 n 和源点不连通,它不会得到更新,还是 0x3f3f3f3f。
- Bellman_ford算法可以存在负权回路,是因为其循环的次数是有限制的因此最终不会发生死循环;但是SPFA算法不可以,由于用了队列来存储,只要发生了更新就会不断的入队,因此假如有负权回路,不要用SPFA,否则会死循环。
- 由于SPFA算法是由Bellman_ford算法优化而来,在最坏的情况下时间复杂度和它一样即时间复杂度为 O(nm),一般情况的时间复杂度为 O(m) ,假如题目时间允许可以直接用SPFA算法去解Dijkstra算法的题目。(题目不卡可以选择这个解两个类型题)
- 求负环一般使用SPFA算法,方法是用一个 cnt 数组记录每个点到源点的边数,一个点被更新一次就+1,一旦有点的边数达到了n,那就说明存在负环。
SPFA算法和Dijkstra算法的区别:
-
数据结构不同:
SPFA算法使用队列作为辅助数据结构,将需要进行松弛操作的顶点入队并出队进行松弛操作。Dijkstra算法使用优先队列(堆)作为辅助数据结构,每次选择当前最短路径长度的顶点进行松弛操作。 -
松弛操作不同:
SPFA算法在每次松弛操作时,只对顶点的邻接边进行松弛,而不需要遍历所有顶点。Dijkstra算法在每次松弛操作时,需要遍历所有顶点,选择当前最短路径.
例题
acwing 851. spfa求最短路
给定一个 n 个点 m 条边的有向图,图中可能存在重边和自环, 边权可能为负数。
请你求出 1 号点到 n 号点的最短距离,如果无法从 1 号点走到 n 号点,则输出 impossible。
数据保证不存在负权回路。
输入格式
第一行包含整数 n 和 m。接下来 m 行每行包含三个整数 x,y,z,表示存在一条从点 x 到点 y 的有向边,边长为 z。
输出格式
输出一个整数,表示 1 号点到 n 号点的最短距离。如果路径不存在,则输出 impossible。输入样例:
3 3
1 2 5
2 3 -3
1 3 4
输出样例:
2
代码:
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
const int N = 100010;
typedef pair<int, int> PII;
int dist[N]; // 起点到各个顶点的最短路径长度
int st[N]; // 当前结点是否在队列中
int h[N], e[N], ne[N], w[N], idx; // 邻接表的头结点、边、下一个节点和权重
int n, m;
void add(int a, int b, int c){
w[idx] = c;
e[idx] = b;
ne[idx] = h[a];
h[a] = idx++;
}
int spfa(){
queue<int> q; // 创建一个队列用于保存需要进行松弛操作的顶点
q.push(1);
st[1] = true;
while(q.size()){
int t = q.front(); // 取出队首顶点t
q.pop();
st[t] = false; // 标记顶点t为未访问
for(int i = h[t]; ~i; i = ne[i]){ // 遍历顶点t的所有邻接边
int j = e[i]; // 邻接点j
if(dist[j] > dist[t] + w[i]){ // 如果之前计算的路径长度 > 起点到顶点j的路径长度
dist[j] = dist[t] + w[i];
if(!st[j]){ // 只有变小了并且不在队中就入队,因为重复的元素入队没有意义
q.push(j);
st[j] = true;
}
}
}
}
if(dist[n] == 0x3f3f3f3f) return -1; // 如果终点n的最短路径长度仍然是无穷大,则说明不存在从起点到终点的路径,返回-1
return dist[n]; // 返回起点到终点的最短路径长度
}
int main(){
memset(h, -1, sizeof h); // 别忘记初始化!否则得不出结果
memset(dist, 0x3f, sizeof dist);
dist[1] = 0; // 起点到自身的最短路径长度为0
cin >> n >> m ;
while(m--){
int a, b, c;
cin >> a >> b >> c;
add(a, b, c); // 添加边的信息到邻接表
}
int t = spfa();
if(t == -1) cout << "impossible" << endl;
else cout << t << endl;
return 0;
}
acwing 852. spfa判断负环
给定一个 n 个点 m 条边的有向图,图中可能存在重边和自环, 边权可能为负数。
请你判断图中是否存在负权回路。
输入格式
第一行包含整数 n 和 m。接下来 m 行每行包含三个整数 x,y,z,表示存在一条从点 x 到点 y 的有向边,边长为 z。
输出格式
如果图中存在负权回路,则输出 Yes,否则输出 No。输入样例:
3 3
1 2 -1
2 3 4
3 1 -4
输出样例:
Yes
通过对SPFA算法的学习,知道了SPFA算法就是Bellman-Ford算法的改进。dist[ i ] 数组就是源点到结点 i 的最短距离。用SPFA算法来判断环,需要额外维护一个数组 cnt 来记录当前这个最短路所走过的边的数量。
在更新 dist[j] = dist[t] + w[i] 时,将 ccnt 同时更新:cnt[j] = cnt[t] + 1,表示从源点到 t 结点最短路所经过的边数 + t 结点到 j 结点的这一条边。当 cnt[j] ≥ n 时,说明从源点到结点 j 经过了 n 条边,也就是经过了 n + 1 个结点。通过容斥原理必定存在至少两个点相同,一定存在负环。
注意:
- 因为求的不是最短路距离,只是判断负环,所以dist 数组不需要初始化。
- 因为求的是图中是否存在负环,但是源点不一定能到达负环所处的位置,因此最初必须将所有的结点入队。
- 因为负环链有可能不大,因此应该使用栈,比队列效率更高。因为不是负环的结点很快就会出栈,但是负环内的结点会频繁的入栈出栈。
代码:
##include<iostream>
#include<cstring>
#include<queue>
using namespace std;
const int N = 100010;
int dist[N], cnt[N]; // cnt:最短路径经过的边数
bool st[N]; // 记录顶点是否在队列中
int h[N], e[N], ne[N], w[N], idx;
int n, m;
void add(int a, int b, int c){
w[idx] = c;
e[idx] = b;
ne[idx] = h[a];
h[a] = idx++;
}
bool spfa(){
queue<int> q; // 队列用于保存需要进行松弛操作的顶点
for(int i = 1; i <= n; i++){ // 所有顶点入队并标记为已访问
q.push(i);
st[i] = true;
}
while(q.size()){
int t = q.front();
q.pop();
st[t] = false; // 标记顶点t未访问
for(int i = h[t]; ~i; i = ne[i]){ // 遍历顶点t的所有邻接边
int j = e[i]; // 邻接顶点j
if(dist[j] > dist[t] + w[i]){ // 如果从起点到顶点j的路径长度比之前计算的路径长度小
dist[j] = dist[t] + w[i]; // 更新最短路径长度
cnt[j] = cnt[t] + 1; // 最短路径经过的边数 + 1
if(cnt[j] >= n) return true; // 如果顶点j被更新次数超过n次,说明存在负环
if(!st[j]){ // 如果顶点j不在队列中
q.push(j); // 将顶点j入队
st[j] = true; // 标记顶点j已访问
}
}
}
}
return false;
}
int main(){
cin >> n >> m;
memset(h, -1, sizeof h); // 初始化邻接表的头结点数组h为-1
// 不用初始化dist[]
while (m--){
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
}
if (spfa()) puts("Yes");
else puts("No");
return 0;
}
注意:
- 不需要初始化dist数组。原理:如果某条最短路径上有n个点(除了自己),那么加上自己之后一共有n+1个点,由抽屉原理一定有两个点相同,所以存在环。
- dist[x]存储1号点到x的最短距离,cnt[x]存储1到x的最短路中经过的点数
邻接表数据结构
h[N] 数组是邻接表的头节点数组,用于存储图中每个节点的邻接链表的头指针。数组的索引表示节点的编号,数组的值表示以该节点为起点的邻接链表的头指针。

通过这个邻接表,我们可以很方便地获取每个节点的邻接节点和对应的权值。例如,节点1的邻接节点是2和3,权值分别是3和5;节点2的邻接节点是3和4,权值分别是2和6;节点3的邻接节点是4,权值是4;节点4没有邻接节点。
这样,当我们在 Dijkstra 算法中遍历节点时,可以通过访问 h[i] 来获取节点 i 的邻接节点和对应的权值,并根据需要更新最短路径值。
ne[N] 数组:存储下一个节点的索引。索引 i :当前节点在邻接表中的位置,数组的值 ne[ i ] 表示下一个节点在邻接表中的位置。通过 ne[N] 数组,可以遍历一个节点的所有邻接节点。
e[N] 数组:存储每条边的终点编号。它的索引 i 表示该边在邻接表中的位置,数组的值 e[ i ] 表示该边的终点节点编号。通过 e[N] 数组,我们可以获取某条边的终点节点。
w[N] 数组:存储每条边的权值。索引 i :该边在邻接表中的位置,数组的值 w[ i ] 表示该边的权值.
idx :记录当前插入到邻接表中的边的位置。在构建邻接表时,每次添加一条边到邻接表中后,idx 的值会递增,用于指示下一个边要插入的位置。

- h[1] = 2,表示以节点1为起点的邻接链表的第一个节点是节点2。
- h[2] = -1,表示以节点2为起点的邻接链表为空。
- ne[0] = 1,表示邻接链表中第一个节点(节点2)的下一个节点是节点3。
- ne[1] = 2,表示邻接链表中第二个节点(节点3)的下一个节点是节点4。
- ne[2] = -1,表示邻接链表中最后一个节点(节点4)没有下一个节点。
- e[0] = 2,表示第一条边的终点节点编号为2。
- e[1] = 3,表示第二条边的终点节点编号为3。
- w[0] = 3,表示第一条边的权值
多源最短路
3.4 Floyd
多源汇最短路问题-具有多个源点(起点)。
时间复杂度是 O(n^3) , n 表示点数。基本思路是动态规划。
d[k, i, j]: i 点,逐一经过 1~k 点,到达 j 点的最短距离。通过 d[k, i, j]=min(d[k-1, i, j], d[k-1, i, k]+d[k-1, k, j]), 第一维度k可以优化掉。
可以有负权边,不能有负权回路。
可以有重边和自环。重边只保留最小边,自环直接删去。
步骤:
- 初始化d, 处理一下自环和重边
- 三重循环
k、i、j,更新d
模板:
初始化:
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= n; j ++ )
if (i == j) d[i][j] = 0;
else d[i][j] = INF;
// 算法结束后,d[a][b]表示a到b的最短距离
void floyd()
{
for (int k = 1; k <= n; k ++ )
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= n; j ++ )
d[i][j] = min(d[i][j], d[i][k] + d[k][j]);
}
模板题
AcWing 854. Floyd求最短路
给定一个 n 个点 m 条边的有向图,图中可能存在重边和自环,边权可能为负数。
再给定 k 个询问,每个询问包含两个整数 x 和 y,表示查询从点 x 到点 y 的最短距离,如果路径不存在,则输出 impossible。数据保证图中不存在负权回路。
输入格式
第一行包含三个整数 n,m,k。接下来 m 行,每行包含三个整数 x,y,z,表示存在一条从点 x 到点 y 的有向边,边长为 z。
接下来 k 行,每行包含两个整数 x,y,表示询问点 x 到点 y 的最短距离。
输出格式
共 k 行,每行输出一个整数,表示询问的结果,若询问两点间不存在路径,则输出 impossible。输入样例:
3 3 2
1 2 1
2 3 2
1 3 1
2 1
1 3
输出样例:
impossible
解题思路:动态规划的思想
节点序号是1到n。假设 f[0][i][j] 是一个 n*n 的矩阵,第 i 行第 j 列代表从 i 到 j 的权值,如果 i 到 j 有边,那么其值就为边 ( i, j ) 的权值。如果没有边,那么其值就为无穷大。
f[k][i][j] (k的取值范围是从1到n):从1到 k 的节点作为中间经过的节点时,从 i 到 j 的最短路径的长度。
比如,f[1][i][j] :1节点作为中间经过的节点时,从 i 到 j 的最短路径的长度。
分析可知,f[1][i][j] 的值无非就是两种情况:i 到 j ,i 到1 到 j:
- f[0][i][j]:i 到 j 的长度 < i 到 1 到 j 的长度
- f[0][i][1] + f[0][1][j]:i 到 1 到 j 的长度 < i 到 j 的长度
说明:
f[k][i][j]可以从两种情况转移而来:
- 从 f[k−1][i][j] 转移而来,表示 i 到 j 的最短路径不经过 k 这个节点
- 从f[k−1][i][k] + f[k−1][k][j] 转移而来,表示 i 到 j 的最短路径经过 k 这个节点
总结:f[k][i][j] = min( f[k−1][i][j] , f[k−1][i][k] + f[k−1][k][j] )。可以发现 f[k] 只可能与 f[k−1] 有关。
代码:
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 210, INF = 1e9;
int n,m,Q;
int d[N][N]; // 任意两个顶点之间的最短路径长度
void floyd(){
for(int k = 1; k <= n; k ++) // 中转点k
for(int i = 1; i <= n; i ++) // 起点i
for(int j = 1; j <= n; j ++) // 终点j
d[i][j] = min(d[i][j], d[i][k]+ d[k][j]); // 更新起点i到终点j的最短路径长度
}
int main(){
cin >> n >> m >> Q;
// 初始化d数组为无穷大
for(int i =1; i <= n; i ++)
for(int j = 1; j <= n; j ++)
if (i == j) d[i][j] = 0; // 自环的最短路径长度为0,对角线上的点(i,i)
else d[i][j] = INF; //除了自环,其他路径长度都是无穷大
while(m --){
int a, b, c;
cin >> a >> b >> c;
d[a][b] = min(d[a][b], c); // 如果存在重边,只保留最小的路径长度
}
floyd(); // 求任意两个顶点之间的最短路径
while(Q --){
int a, b;
cin >> a >> b; // 查询的起点和终点
int t = d[a][b];
if(t > INF / 2) puts("impossible"); // 不存在从起点到终点的路径
else cout << t << endl;
}
return 0;
}
注意:为什么是>=03xf3f3f3f/2?
因为存在负权边 所以0x3f3f3f3f这个值可能会因为负值被更新 但值依然远大于0x3f3f3f3f/2
四、最小生成树

什么是最小生成树问题?
假设地图中有很多城市,现在需要在城市中修建一条公路,使得各个城市可以联通(类似于主线),现在询问最小需要修多少距离的公路。
凡是最小生成树的问题,一般对应的图是无向图。而解决最小生成树问题通常使用的是 Prim 和 Kruskal 算法。
一般而言,对于稠密图的最小生成树问题我们使用Prim算法,时间复杂度是 O(n^2)。对于稀疏图,一般使用Kruskal算法,时间复杂度是 O(mlogm)。
4.1 Prim
通俗解释:在一个无向图,在图中选择若干条边把图的所有节点连起来。要求边长之和最小。在图论中,叫做求最小生成树。
用途:最小生成树在许多领域都有重要的作用,例如:要在 n 个城市之间铺设光缆,使它们都可以通信,铺设光缆的费用很高,且各个城市之间因为距离不同等因素,铺设光缆的费用也不同,如何使铺设光缆的总费用最低?可以知道任意两个城市之间总费用最低的光缆路径。如果图的每一条边的权值都互不相同,那么最小生成树将只有一个,否则可能会有多个最小生成树。
总思路:每次将离连通部分的最近的点和点对应的边加入的连通部分,连通部分逐渐扩大,最后将整个图连通起来,并且边长之和最小。
最小生成树中,正权。负权边都可以出现。
Prim算法与朴素版的Dijkstra算法非常相像,伪代码如下:
首先,初始化距离数组 dist 为正无穷,表示每个点到最小生成树的距离初始都是 ∞
for (int i = 0; i < n; i++)
{
t ← 找到最小生成树之外,距离最小生成树最近的点
用 t 更新其他点到最小生成树的距离
将 t 加入到最小生成树中去
}
注意:用 t 更新其他点到最小生成树的距离是指:如果其他点到最小生成树有多条边,那么只取最短的那一条。如果不存在任何一条边与最小生成树相连,则目前距离仍为正无穷。
区别:
- Dijkstra是更新不在集合中的点 到起点的距离
dist[j]=min(dist[j], dist[t]+g[t][j])- Prim是更新不在集合中的点 到集合S的距离
dist[j] = min(dist[j], g[t][j])
Dijkstra:初始化dist距离为正无穷。先找到当前不在集合当中的、到起点距离最小的点 t ,再用 t 去更新其他点到起点的距离。再把 t 加入 已确定最短路径的点的集合。不在集合当中的意思就是还没有确定最短距离。第一次加入起点,剩下 n - 1 个点,只需要迭代 n - 1 次。
Prim:初始化dist距离为正无穷。n次迭代,找到当前不在集合当中的、到起点距离最小的点 t 。用 t 去更新其他点到集合(最小生成树)的距离。把 t 加入集合(st[ t ] = true)。第一次没有加入任何点,n 个点都需要选择,所以要迭代 n 次。
- 点到集合的距离:能将这个点 连接到集合(最小生成树)内任一点的 所有边中长度最小的那条边。
- 集合:生成树,当前已经在连通块当中的所有点。
4.1.1 朴素版
例题:
acwing 858. Prim算法求最小生成树
给定一个 n 个点 m 条边的无向图,图中可能存在重边和自环,边权可能为负数。
求最小生成树的树边权重之和,如果最小生成树不存在则输出 impossible。
给定一张边带权的无向图 G=(V,E),其中 V 表示图中点的集合,E 表示图中边的集合,n=|V|,m=|E|。
由 V 中的全部 n 个顶点和 E 中 n−1 条边构成的无向连通子图被称为 G 的一棵生成树,其中边的权值之和最小的生成树被称为无向图 G 的最小生成树。
输入格式
第一行包含两个整数 n 和 m。接下来 m 行,每行包含三个整数 u,v,w,表示点 u 和点 v 之间存在一条权值为 w 的边。
输出格式
共一行,若存在最小生成树,则输出一个整数,表示最小生成树的树边权重之和,如果最小生成树不存在则输出 impossible。数据范围
1≤n≤500,
1≤m≤105,
图中涉及边的边权的绝对值均不超过 10000。输入样例:
4 5
1 2 1
1 3 2
1 4 3
2 3 2
3 4 4
输出样例:
6
首先看数据范围:稠密图,点和边的数量相当。用邻接矩阵存储。
有重边:只保留长度最小的边。自环:删掉。
无向图:特殊的有向图,建立边的时候要添加两个方向。add(a,b) , add(b, a)
代码:
#include<iostream>
#include<cstring>
using namespace std;
const int N = 510, INF = 0x3f3f3f3f;
int g[N][N];
int dist[N];
int st[N];
int n, m;
int prim(){
int res = 0; // 最小生成树中所有边的长度之和
for(int i = 0; i < n; i++){ // 遍历n次
int t = -1;
for(int j = 1; j <= n; j++)
if(!st[j] && (t == -1 || dist[t] > dist[j])) // 集合外的、到集合距离最小的点t
t = j;
if(i && dist[t] == INF) return INF; // 不是第一个点、且t点不可达:图不连通,不存在最小生成树
if(i) res += dist[t]; // 只要不是第一个点,这条边加入最小生成树
st[t] = true; // 点t加入集合(已经连通进最小生成树)
for(int j = 1; j <= n; j++)
dist[j] = min(dist[j], g[t][j]); // 点到集合的距离。*与dijkstra的最大区别!
}
return res;
}
int main(){
memset(g, 0x3f, sizeof g);
memset(dist, 0x3f, sizeof dist);
// 不需要dist[1] = 0,因为起点也是要搜索得到
cin >> n >> m;
while(m--){
int a, b, c;
cin >> a >> b >> c;
g[a][b] = g[b][a] = min(g[a][b], c); // 重边只保留最小值
}
int t = prim();
if(t == INF) puts("impossible"); //所有点不连通,不存在最小生成树
else cout << t;
return 0;
}注意:
- 样例中存在特殊数据:负权自环。会更新dist[ j ],把自己的dist变的更小。但最小生成树不能有自环,所以应该先累加res,再for循环更新dist。如果先更新再累加,可能会把自环加进来,导致结果出错。
- 别忘了初始化 g[][]、dist[]!!
- prim里的最外层for循环中,i 不作下标使用,只是计数,表示循环次数。n次
- 每次选出点 t 后,先 if 判断生成树到点 t 是否可达,如果不可达,结束运行。if(i):只要 i 不为0,即不是第一次循环,则执行 if。
- 更新时,是用点 t 去更新 其他所有点 到 集合 的距离。而不是其他所有点到起点的距离。
4.1.2 堆优化版
和堆优化版dijkstra相同,用堆来维护dist数组。总时间复杂度O(mlogn)。
- 每次循环先找最小值 t,O(1),n次循环就是O(n)。
- 用 t 更新其他点到集合距离的时间复杂度:遍历所有边,有m条边,时间复杂度O(m)。更新堆里面元素的时间复杂度是O(logn),合起来是O(mlogn)。
- s[t] = true,O(1),n次循环就是O(n)。
思路麻烦且代码较长,基本不用,遇到稠密图直接用Kruscal。
4.2. Kruscal
解决稀疏图,时间复杂度为O(mlogm) 。m 指的是边数
算法流程:
- 将所有边按权重从小到大排序,这也是该算法时间复杂度瓶颈:O(mlogm);
- 枚举每条边 a→b,权重是 c。共O(m) 次。如果当前 a , b 不在一个集合中,则将该边加入集合中(并查集)。(也就是在a、b之间加一条边)
排序可以用快排,不用手写,直接调用sort()函数就行。时间复杂度固定,主要花销在排序。
分析上面的步骤:在图中的点不连通,然后直接的加入的话,用并查集数据结构应该是最快的,所以操作2是并查集操作另外需要用变量cnt 记录加进集合的边数, 倘若cnt < n -1 则表示不能遍历所有的点( 说明其中的点根本不连通)
对比prim:思路更简单,不需要考虑边界问题,比如循环 n 次、n - 1 次、堆优化之类的。而且不需要用邻接表、邻接矩阵之类复杂数据结构来存,可以用最简单的结构体struct来存储。这里可以发现,枚举边的问题中都可以用struct来存储,就像上边的Bellman-Ford。
中心思想:边从小到大排序,再枚举边,边的两点不连通,就连通集合。
可以参考题目 837 连通块中点的数量
例题
acwing 859. Kruskal算法求最小生成树
给定一个 n 个点 m 条边的无向图,图中可能存在重边和自环,边权可能为负数。
求最小生成树的树边权重之和,如果最小生成树不存在则输出 impossible。
给定一张边带权的无向图 G=(V,E),其中 V 表示图中点的集合,E 表示图中边的集合,n=|V|,m=|E|。
由 V 中的全部 n 个顶点和 E 中 n−1 条边构成的无向连通子图被称为 G 的一棵生成树,其中边的权值之和最小的生成树被称为无向图 G 的最小生成树。
输入格式
第一行包含两个整数 n 和 m。接下来 m 行,每行包含三个整数 u,v,w,表示点 u 和点 v 之间存在一条权值为 w 的边。
输出格式
共一行,若存在最小生成树,则输出一个整数,表示最小生成树的树边权重之和,如果最小生成树不存在则输出 impossible。数据范围
1≤n≤105,
1≤m≤2∗105,
图中涉及边的边权的绝对值均不超过 1000。输入样例:
4 5
1 2 1
1 3 2
1 4 3
2 3 2
3 4 4
输出样例:
6
图示:

代码:
#include<iostream>
#include<algorithm>
using namespace std;
const int N = 100010,M = 2 * N;
int p[N]; // 并查集数组,记录每个节点的父节点
int n, m;
struct Edge{
int a, b, w;
bool operator < (const Edge &W) const{ // 重载小于运算符,按照权重从小到大排序边
return w < W.w;
}
}e[N];
int find(int x){ // 并查集的find操作,找到节点x所属的集合的根节点
if(p[x] != x) p[x] = find(p[x]); // 路径压缩,将x的父节点直接设为根节点
return p[x];
}
int main(){
cin >> n >> m;
for(int i = 0; i < m; i++){
int a, b, w;
cin >> a >> b >> w;
e[i] = {a, b, w};
}
sort(e, e + m); //对边按照权重从小到大排序。头文件 #include<algorithm>
//for(int i = 0; i < m; i ++) cout<<e[i].a <<' '<<e[i].b<<" "<<e[i].w<<endl; //看一下排序后的结果
for(int i = 1; i <= n; i++) p[i] = i; // 初始化并查集,将每个节点的父节点设为自身
int res = 0, cnt = 0; // res:集合中的边长总和 cnt:边数
for(int i = 0; i < m; i++){ // 枚举所有边
int a = e[i].a;
int b = e[i].b;
int w = e[i].w;
a = find(a), b = find(b); // 并查集中的find,找根节点,看是否在一个集合中
if(a != b){ // 如果a和b不在同一个集合中(即不连通)
p[a] = b; //并查集中的合并操作:把集合a加入集合b
res += w;
cnt++;
}
}
if(cnt < n - 1) puts("impossible"); // 如果最小生成树的边数小于n-1,说明图不连通
else cout << res << endl;
return 0;
}
如果find(a) == find(b),那么在这之前已经有更短的边将a、b连通。 则忽视这条边(a,b)。继续枚举后面的边。直到所有的点都加入集合,即 cnt == n - 1
排序函数sort,需要重载:
sort(start, end); // 对[start, end)范围内的元素进行升序排序这些位置可以是迭代器、指针或数组的首尾指针。
sort(e, e + m):对数组e中的元素进行排序,范围是从e开始的m个元素。数组名e可以转换为指向第一个元素的指针。
sort()函数会根据元素的类型调用相应的比较函数来进行排序。对于自定义的结构体类型,可以通过重载结构体中的小于运算符<来定义排序规则。在代码中的使用示例为:
bool operator < (const Edge &W) const {
return w < W.w;
}该重载运算符定义了Edge结构体的小于运算符,根据边的权重w来进行排序。
五、二分图
二分图定义:
二分图又称作二部图,是图论中的一种特殊模型。 设G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点 i 和 j 分别属于这两个不同的顶点集:(i in A,j in B),则称图G为一个二分图。
简而言之,就是顶点集V可分割为两个互不相交的子集,并且图中每条边依附的两个顶点都分属于这两个互不相交的子集,两个子集内的顶点不相邻。
二分图判断:
对于二分图的问题我们首先要判断一个图它是不是二分图。对于二分图的判断方法最常见的是染色法,就是对每一个点进行染色,只用黑白两种颜色,能不能使所有的点都染上了色,而且相邻两个点的颜色不同,如果可以,那么这个图就是一个二分图。
可以用dfs和bfs两种方式去实现。下面我就上一个bfs的判断二分图的代码。
二分图的充要条件:
当且仅当图中没有奇数环。二分图一定不含有奇数环,因为奇数环分配到最后一定会有两种颜色一样挨着,所以不符合条件。但包含长度为偶数的环, 不一定是连通图。

5.1 染色体法
例题
acwing 860. 染色法判定二分图
给定一个 n 个点 m 条边的无向图,图中可能存在重边和自环。
请你判断这个图是否是二分图。
输入格式
第一行包含两个整数 n 和 m。接下来 m 行,每行包含两个整数 u 和 v,表示点 u 和点 v 之间存在一条边。
输出格式
如果给定图是二分图,则输出 Yes,否则输出 No。数据范围
1≤n,m≤105输入样例:
4 4
1 3
1 4
2 3
2 4
输出样例:
Yes
思路:
染色可以使用1和2区分不同颜色,用0表示未染色
遍历所有点,每次将未染色的点进行dfs, 默认染成1或者2
由于某个点染色成功不代表整个图就是二分图,因此只有某个点染色失败才能立刻break/return
注: 染色失败相当于存在相邻的2个点染了相同的颜色
用DFS实现:
#include<iostream>
#include<cstring>
using namespace std;
const int N = 100010;
int h[N], e[N], ne[N], idx;
int n, m;
int color[N]; // 1、2两种颜色
void add(int a, int b){
e[idx] = b;
ne[idx] = h[a];
h[a] = idx++;
}
bool dfs(int u, int c){ // u表示当前点,c表示点的颜色
color[u] = c;
for(int i = h[u]; ~i; i = ne[i]){
int j = e[i];
if(!color[j]){ // 如果点j还没染色
if(!dfs(j, 3 - c)) return false; // 这次染1,下一次染2;这次染2,下一次染1
}else if(color[j] == c) return false; // 染色了,但颜色和上一个点相同
}
return true;
}
int main(){
memset(h, -1, sizeof h); // 别忘记初始化!否则得不出结果
cin >> n >> m ;
while(m--){
int a, b;
cin >> a >> b ;
add(a, b), add(b, a); // 无向图
}
bool flag = true;
for(int i = 1; i <= n; i++){
if(!color[i]){ //点i还没被染色
if(!dfs(i, 1)){ //从第1节点开始染,颜色1
flag = false;
break;
}
}
}
if(flag) puts("YES");
else puts("NO");
return 0;
} 5.2 匈牙利算法
匈牙利算法主要用来解决两个问题:求二分图的最大匹配数和最小点覆盖数。
最小点覆盖:我们想找到最少的一些点,使二分图所有的边都至少有一个端点在这些点之中。倒过来说就是,删除包含这些点的边,可以删掉所有边。
匹配的两个重点:1. 匹配是边的集合;2. 在该集合中,任意两条边不能有共同的顶点。
1. 匈牙利算法寻找最大匹配,就是通过不断寻找原有匹配M的增广路径,因为找到一条M匹配的增广路径,就意味着一个更大的匹配M' , 其恰好比M 多一条边。 2. 对于图来说,最大匹配不是唯一的,但是最大匹配的大小是唯一的。
acwing 861. 二分图的最大匹配(匈牙利算法)
给定一个二分图,其中左半部包含 n1 个点(编号 1∼n1),右半部包含 n2 个点(编号 1∼n2),二分图共包含 m 条边。
数据保证任意一条边的两个端点都不可能在同一部分中。
请你求出二分图的最大匹配数。
二分图的匹配:给定一个二分图 G,在 G 的一个子图 M 中,M 的边集 {E} 中的任意两条边都不依附于同一个顶点,则称 M 是一个匹配。
二分图的最大匹配:所有匹配中包含边数最多的一组匹配被称为二分图的最大匹配,其边数即为最大匹配数。输入格式
第一行包含三个整数 n1、 n2 和 m。接下来 m 行,每行包含两个整数 u 和 v,表示左半部点集中的点 u 和右半部点集中的点 v 之间存在一条边。
输出格式
输出一个整数,表示二分图的最大匹配数。数据范围
1≤n1,n2≤500,
1≤u≤n1,
1≤v≤n2,
1≤m≤105输入样例:
2 2 4
1 1
1 2
2 1
2 2
输出样例:
2
注意:如果数组越界,什么错误都有可能出现。
#include<iostream>
#include<cstring>
using namespace std;
const int N = 100010;
int h[N], e[N], ne[N], idx;
int n1, n2, m;
int st[N]; // 记录每个女生是否被访问过
int match[N]; // 记录每个女生匹配的男生
void add(int a, int b){
e[idx] = b; // 边的终点
ne[idx] = h[a]; // 当前边的next指针指向头结点指向的边的序号
h[a] = idx++; // 更新头结点指向的边的序号
}
bool find(int x){
for(int i = h[x]; ~i; i++){ // 遍历以男生x为起点的所有边
int j = e[i]; // 边的终点
if(!st[j]){ // 如果女生j还未被访问过
st[j] = true; // 标记女生j已被访问
if(match[j] == 0 || find(match[j])){ // 如果女生j还未匹配或者男生可以找到另一个女生
match[j] = x; // 将女生j与男生x匹配
return true; // 匹配成功
}
}
}
return false; // 匹配失败
}
int main(){
memset(h, -1, sizeof h);
cin >> n1 >> n2 >> m ;
while(m--){
int a, b;
cin >> a >> b ;
add(a, b), add(b, a);
}
int res = 0; // 匹配成功的对数
for(int i = 1; i <= n1; i++){ // 遍历每个男生
memset(st, false, sizeof st); // 每次匹配前将st数组重置为false
if(find(i)) res++; // 如果能找到一个女生与男生i匹配,则匹配数加1
}
cout << res << endl;
return 0;
}思路:用深度优先搜索来寻找匹配。首先遍历以男生 x 为起点的所有边,找到一个未被访问过的女生节点 j 。如果女生 j 还未匹配,或者能找到另一个女生 k ,使得女生 k 与男生 match[ j ] 匹配,那么就将女生 j 与男生 x 匹配,然后返回匹配成功。否则,继续查找下一个未被访问的女生节点。
过程:

典型的图搜索问题——八数码问题
八数码问题也叫九宫问题,是人工智能中状态搜索中的经典问题。问题描述为:在3×3的棋盘,摆有八个棋子,每个棋子上标有1至8的某一数字,不同棋子上标的数字不相同。棋盘上还有一个空格,与空格相邻的棋子可以移到空格中。要求解决的问题是:给出一个初始状态和一个目标状态,找出一种从初始转变成目标状态的移动棋子步数最少的移动步骤。
BFS的思路:一边搜索结点一边生成新的子结点。将新生成的结点放入队列queue中,将访问过的结点放入集合set中。当某结点与目标状态相同时,那么最短路径长度就是该结点的长度。而最短路径可以通过存储父节点信息已经当前的操作算子得出。
有两个关键点:如何计算bfs中结点的层数(进而得出最短路径长度),如何记录最短路径。
(but我是真理解不了了T T 待深入了解出门右转请:八数码问题_AdaMeta的博客-CSDN博客
直观的状态表示方法:采用字符串方式编码,把3*3的九宫格展平为一个长度为9的串,这样一个串即可代表一种当前数码盘的状态。从初始的状态扩展为一颗向目标状态的状态搜索树如下:
不难看出,一颗搜索树的深度,即为当前空格所对换的次数。
使用BFS更适合,思路不再是“一股脑走到底”,而是“泛的扩展”。这样,在同一个深度下分布在搜索树上右边的目标节点 和 分布在搜索树左边的节点 在搜索的次数上是大致相同的。
可以看出,节点从根部节点开始扩展,首先访问的是根节点的子节点们,然后从子节点们扩展到下一层的子节点们,即扩展是有层次关系的。这样,对于层次位于叶子节点附近的集合,就能有公平的概率搜索到。上图中的节点访问顺序就是先访问层次1的所有节点,随后是层次2的所有节点,直到搜索到目标解,或者无法继续扩展而结束。这样,对于广度优先搜索中,每一次扩展都是搜索当前状态可以拓展的下一次状态,即搜索的是树中的每一层。
伪代码:
访问顶点v;visited[v]=1;顶点v入队列Q;
while(队列Q非空)
v=队列Q的对头元素出队;
w=顶点v的第一个邻接点;
while(w存在)
如果w未访问,则访问顶点w;
visited[w]=1;
顶点w入队列Q;
w=顶点v的下一个邻接点。例题
acwing 845. 八数码
在一个 3×3 的网格中,1∼8 这 8 个数字和一个 x 恰好不重不漏地分布在这 3×3 的网格中。
例如:
1 2 3
x 4 6
7 5 8
在游戏过程中,可以把 x 与其上、下、左、右四个方向之一的数字交换(如果存在)。我们的目的是通过交换,使得网格变为如下排列(称为正确排列):
1 2 3
4 5 6
7 8 x
例如,示例中图形就可以通过让 x 先后与右、下、右三个方向的数字交换成功得到正确排列。交换过程如下:
1 2 3 1 2 3 1 2 3 1 2 3
x 4 6 4 x 6 4 5 6 4 5 6
7 5 8 7 5 8 7 x 8 7 8 x
现在,给你一个初始网格,请你求出得到正确排列至少需要进行多少次交换。输入格式
输入占一行,将 3×3 的初始网格描绘出来。例如,如果初始网格如下所示:
1 2 3
x 4 6
7 5 8
则输入为:1 2 3 x 4 6 7 5 8输出格式
输出占一行,包含一个整数,表示最少交换次数。
如果不存在解决方案,则输出 −1。
输入样例:
2 3 4 1 5 x 7 6 8
输出样例
19
思路:
求最少交换次数, 我们可以将二维坐标的其实状态看成树的根节点,然后需要找到走到结束状态的最短的走法。本质上是求最短距离。将每一个可能出现的状态作为一个结点,每次扩展的时候步数都是1。这个时候我们可以将一个状态用字符串表示。
求最短距离: 我们需要想到BFS。按照之前学习BFS 的思路:需要有队列保存不同的状态,有一个距离数据存储到哪个状态走了多少步。和迷宫那道题类似,可以看AcWing 844. 走迷宫。
难点:
- 如何把状态存储在队列中
- 如何记录状态距离
解决方案:直接用字符串进行存储不同的状态
queue<string> q 保存不同的状态
unordered_map<string, int> dist 哈希表存储到不同状态的步数
代码:
#include<iostream>
#include<unordered_map>
#include<queue>
using namespace std;
const int N = 100010;
int bfs(string start){
string end = "12345678x"; // 目标状态
queue<string> q; // 队列用于存储待搜索的状态
unordered_map<string, int> d; // 哈希表d用于记录每个状态的步数
q.push(start); // 将初始状态加入队列
d[start] = 0; // 初始状态的步数为0
int dx[4] = {-1, 0, 1, 0}, dy[4] = {0, 1, 0, -1}; // 定义方向数组,用于表示上、右、下、左四个方向的移动
while(q.size()){
auto t = q.front(); // 取出队首的状态
q.pop();
int distance = d[t]; // 当前状态的步数
if(t == end) return distance; // 如果当前状态等于目标状态,则返回步数
// 状态转移
int k = t.find('x'); // 找到空格在当前状态中的位置
int x = k / 3, y = k % 3; // 计算空格的坐标,x为行号,y为列号
for(int i = 0; i < 4; i++){ // 遍历四个方向
int a = x + dx[i], b = y + dy[i]; // 计算下一个状态的坐标
if(a >= 0 && a < 3 && b >=0 && b < 3){ // 如果下一个状态的坐标合法(在3x3矩阵内)
swap(t[k], t[a * 3 + b]); // 将空格与相邻位置的数字进行交换
if(!d.count(t)){ // 如果这个状态之前没有被搜索过
d[t] = distance + 1; // 更新这个状态的步数
q.push(t); // 将这个状态加入队列
}
swap(t[k], t[a * 3 + b]); // 恢复原来的状态,以便搜索其他可能的状态
}
}
}
return -1; // 如果无法达到目标状态,则返回-1
}
int main(){
string start;
for(int i = 0; i < 9; i++){
char c;
cin >> c;
start += c; // 初始状态,转换为字符串
}
cout << bfs(start) << endl;
return 0;
}
步骤:
-
bfs函数接收一个初始状态start作为参数。 -
函数内,定义了目标状态
end为"12345678x",其中"x"代表空格。 -
创建了一个队列
q和一个哈希表d,用于存储待搜索的状态和记录每个状态的步数。 -
将初始状态
start加入队列q中,并将初始状态的步数设为0,即d[start] = 0。 -
定义了方向数组
dx和dy,分别表示上、右、下、左四个方向的移动。 -
进入循环,当队列
q不为空时进行迭代。循环执行步骤7~13. -
从队列
q中取出队首的状态t,并弹出队首的状态。 -
获取当前状态的步数
distance,即int distance = d[t]。 -
把空格的一维下标转换为二维坐标,即
int k = t.find('x'); int x = k / 3, y = k % 3。 -
遍历上右下左四个方向,对于每一个方向,计算下一个状态的坐标
a和b。 -
如果下一个状态的坐标合法(在3x3矩阵内),则将空格与相邻位置的数字进行交换,即
swap(t[k], t[a * 3 + b])。空格的二维坐标转换为一维下标。 -
判断这个状态是否之前已经被搜索过,如果没有,则更新这个状态的步数,并将其加入队列
q中,即d[t] = distance + 1; q.push(t)。 -
恢复原来的状态,以便搜索其他可能的状态,即再次交换空格与相邻位置的数字,即
swap(t[k], t[a * 3 + b])。 -
循环过程中,如果当前状态等于目标状态
end,则返回步数distance。循环结束后,如果无法达到目标状态,则返回-1。
参考
C++ 语言中 priority_queue 的常见用法详解 - 知乎 (zhihu.com)
图算法——求最短路径(Dijkstra算法)_黑夜里的小夜莺的博客-CSDN博客
【算法】 有边数限制的最短路(bellman - ford算法)_am brother的博客-CSDN博客
Bellman-ford算法详解_bellmanford算法_真的没事鸭的博客-CSDN博客














 789
789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









