






 文章介绍了LoRA方法,通过在预训练大语言模型(LLMs)的Transformer架构中添加低秩分解矩阵,显著减少下游任务的可训练参数和GPU内存需求。这种方法在保持模型性能的同时,降低了微调成本并提高了通用性。
文章介绍了LoRA方法,通过在预训练大语言模型(LLMs)的Transformer架构中添加低秩分解矩阵,显著减少下游任务的可训练参数和GPU内存需求。这种方法在保持模型性能的同时,降低了微调成本并提高了通用性。
做法:
- 把预训练LLMs里面的参数权重给冻结;
- 向transformer架构中的每一层,注入可训练的 rank decomposition matrices-(低)秩分解矩阵,从而可以显著地减少下游任务所需要的可训练参数的规模。
效果举例:
相比于使用Adam的gpt3 175B,LoRA可以降低可训练参数规模,到原来的1/10000,以及GPU内存的需求是原来的1/3。
介绍
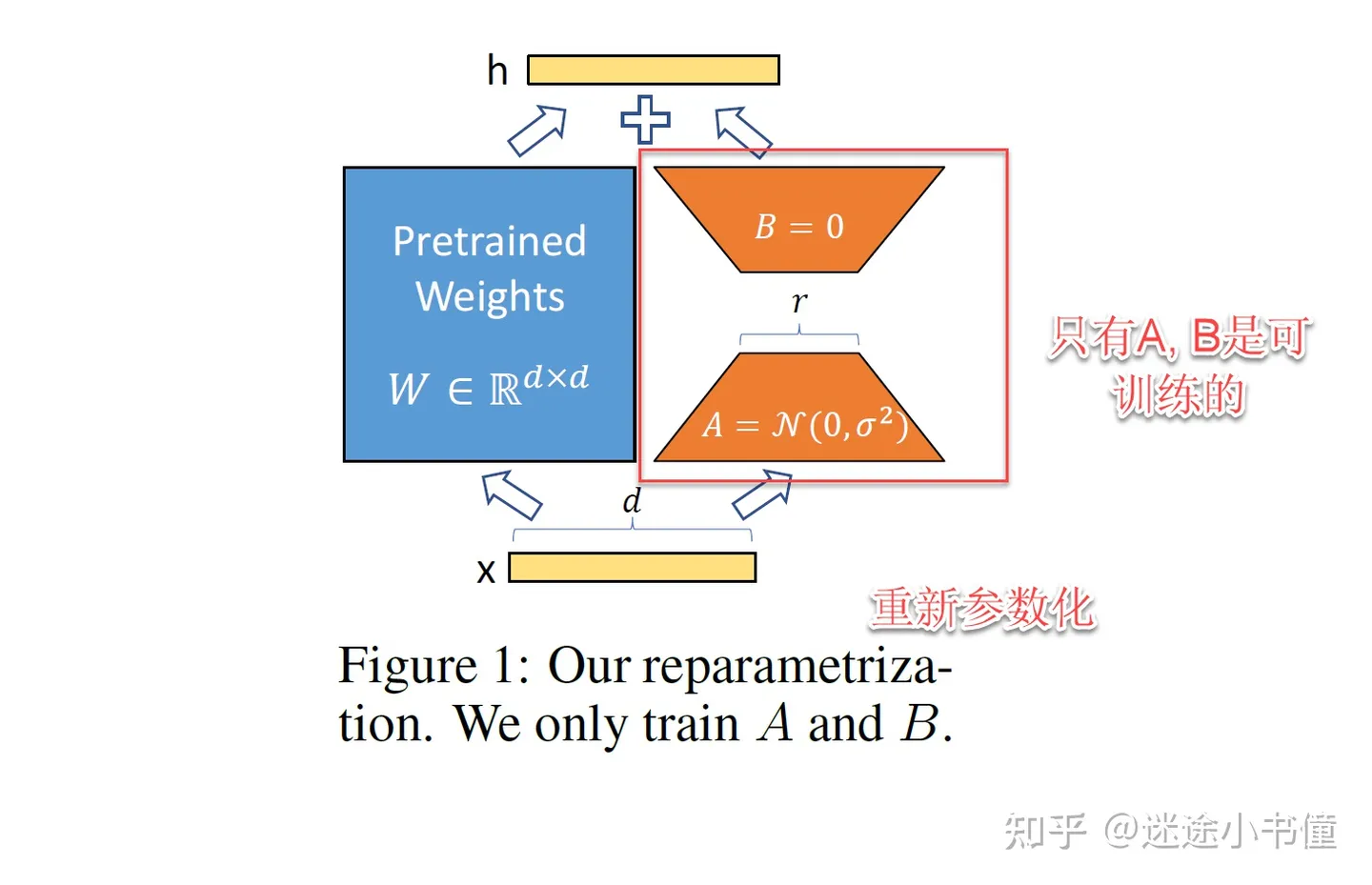
本文中的重新参数化(重参数化),只有A和B是可训练的。
上图中,左边的蓝色的部分,冻住了。
右边的橙色部分,是可训练的。注意,r = rank,即矩阵的秩,可以是非常小的一个量。(例如,r=1, 2 在上面图1中)
上面还有个+号,是把左右两个分支,合并起来了。
下面的输入是x,一个d维度(例如,可以是d=12288)的向量;上面的输出是h,也是一个向量。
问题描述

目前的基于有标签数据集Z={(x, y)}的微调,代价大,容易分裂
容易分裂是说,在一个数据集上微调,可能会拉低微调得到的模型,在其他任务上的效果;无法达到真正的通用性。而且每个任务下的数据集都这么搞,代价(运算成本,使用成本)太高了。
从而引入本文的,数学建模:

保持原来的参数不动,而引入少量的一些可训练参数,从而让这些参数帮忙做针对下游任务的“适应性微调”
下面是一个初步的结果,对比几种baseline和RoLA的微调方法,指标用的是推理延时(milliseconds, ms, 用时,越小越好)。

推理用时的对比,越小越好。
方法

核心方法的描述,数学建模,和图形化表示
公式(3)完整地对应到了图1
不过,如果是每个线性层W,都准备一个这样的B和A,那么对于原来的transformer里面的FFN的两个线性层,一个mhsa中的W_q,k,v,o的四个线性层,都可以按照这个方式改造。
所以,拿一个线性层举例,还是很具有代表性的。毕竟,说到底,transformer里面的基本模块,还是一个个的线性层。】
应用LoRA到transformer中
在后续的论述中,作者们只对attention里面的四个线性层,进行LoRA的处理。对于mlp那边的两个线性层,还是冻结,不用LoRA:

把LoRA应用到transformer中的具体的细节:只改动attention里面的四个线性层。其他的MLP的两个线性层不动。
整体动机,就是为原来的线性层变换,增加了一个low-rank的参数r,以及(r, d)和(d, r)的两个线性层。从而有:h = W_0x + BAx


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









