










 本文详细描述了在使用Moore-AnimateAnyone项目时遇到的各种问题,包括权重下载、数据预处理、模型训练(如关键点提取、多GPU配置、分布式训练等)及其解决方案。重点讨论了GPU内存溢出、模块未找到错误、配置错误和模型在不同设备间的张量问题等。
本文详细描述了在使用Moore-AnimateAnyone项目时遇到的各种问题,包括权重下载、数据预处理、模型训练(如关键点提取、多GPU配置、分布式训练等)及其解决方案。重点讨论了GPU内存溢出、模块未找到错误、配置错误和模型在不同设备间的张量问题等。
code:MooreThreads/Moore-AnimateAnyone (github.com)
paper:Animate Anyone (humanaigc.github.io)
1. Inference
Inference没啥难度,按照readme来就行,就是分开下载权重比较慢,注意权重文件严格按照文档目录树来放。
python -m scripts.pose2vid --config ./configs/prompts/animation.yaml -W 512 -H 784 -L 64默认的参数我cuda.OutOfMemoryError了(服务器12G显存),调小为-W 256 -H 392 -L 32就可以了,但是测试出来的demo效果非常差,和moore自己展示的没法比
视频放不上来,不展示了
2. Training
Data Preparation
用HDTF数据集试一下
Extract keypoints from raw videos:
python tools/extract_dwpose_from_vid.py --video_root /path/to/your/video_dir问题1:ModuleNotFoundError: No module named 'src'
解决:参考这篇python 服务器运行代码报错ModuleNotFoundError的解决办法_modulenotfounderror: no module named 'py01_robor_a-CSDN博客
在报错的文件顶端添加:
import sys
import os
sys.path.append(os.path.dirname(sys.path[0]))问题2:按照文件里的提示
# Extract dwpose mp4 videos from raw videos
# /path/to/video_dataset/*/*.mp4 -> /path/to/video_dataset_dwpose/*/*.mp4(maa)root@:/data/Moore-AnimateAnyone# python tools/extract_dwpose_from_vid.py --video_root /data/Moore-AnimateAnyone/video/*.mp4
return register_model(fn_wrapper)
usage: extract_dwpose_from_vid.py [-h] [--video_root VIDEO_ROOT] [--save_dir SAVE_DIR] [-j J]
extract_dwpose_from_vid.py: error: unrecognized arguments: /data/Moore-AnimateAnyone/v/video/RD_Radio11_000.mp4 /data/Moore-AnimateAnyone/v/video/RD_Radio11_001.mp4 /data/Moore-AnimateAnyone/v/video/RD_Radio12_000.mp4 解决:不要写通配符,展开成实际的文件夹路径即可,python tools/extract_dwpose_from_vid.py --video_root /data/Moore-AnimateAnyone/video

参考:
如果要后台运行:
nohup和&后台运行,进程查看及终止 - Mr_Yun - 博客园 (cnblogs.com)
Extract the meta info of dataset:
python tools/extract_meta_info.py --root_path /path/to/your/video_dir --dataset_name anyone Stage1
accelerate launch train_stage_1.py --config configs/train/stage1.yaml问题1:TypeError: ClusterConfig.__init__() got an unexpected keyword argument 'debug'
我没找到我的本地default_config .yaml文件,用的是pip install --upgrade accelerate有效解决
问题2:subprocess.CalledProcessError: Command '['/opt/conda/envs/maa/bin/python3.10', 'train_stage_1.py', '--config', 'configs/train/stage1.yaml']' returned non-zero exit status 1.
需要把这个错误之前的所有报错都解决掉,之后就可以顺利进行分布式训练了
之前的报错:RuntimeError: PytorchStreamReader failed reading zip archive: failed finding central directory
报错的位置:
File "/data/Moore-AnimateAnyone/train_stage_1.py", line 293, in main
controlnet_openpose_state_dict = torch.load(cfg.controlnet_openpose_path)检查后发现是controlnet上传了一半断掉了,文件不完整,重新上传,解决
问题3:RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:0! (when checking argument for argument weight in method wrapper_CUDA___slow_conv2d_forward)
这个错误是由于在模型计算过程中发现了不同设备的张量混合使用导致的问题。具体来说,错误信息显示了至少有两个设备上的张量被发现在同一个操作中,一个在CPU上,另一个在cuda:0(GPU)上。
没解决,调试确定模型和计算都移动到GPU上了
解决2:仔细看了一下报错,有这样一行:
The following values were not passed to `accelerate launch` and had defaults used instead:
`--num_cpu_threads_per_process` was set to `28` to improve out-of-box performance when training on CPUs
To avoid this warning pass in values for each of the problematic parameters or run `accelerate config`.
才想起来之前碰到过这个问题,是accelerate的设置问题,解决:输入accelerate config,改变默认设置:
training on cpu only 选择no,其他的看情况选择,最好选择支持fp16混合精度训练,以节省内存
accelerate launch train.py和python train.py是两种不同的命令,有以下区别:
python train.py是在Python环境下直接运行train.py脚本。这将使用Python解释器执行脚本,并按照脚本中的代码逻辑进行训练。
accelerate launch train.py是使用NVIDIA的Accelerate库来运行train.py脚本。Accelerate是一个用于简化和加速深度学习训练的工具包。它提供了一组功能,用于自动化并行训练、分布式训练和混合精度训练等任务。通过使用Accelerate,可以更方便地配置和管理训练过程,同时充分利用GPU资源以加速训练。
问题4:报错:torch.distributed.elastic.multiprocessing.errors.ChildFailedError
解决1:参考【解决】pytorch单机多卡问题:ERROR: torch.distributed.elastic.multiprocessing.api:failed_error:torch.distributed.elastic.multiprocessing.ap-CSDN博客
没用
解决2:参考Having "ChildFailedError"..? - distributed - PyTorch Forums 重新安装cuda
顺便学习一下如何单机多卡训练:pytorch 分布式多卡训练DistributedDataParallel 踩坑记_加载多卡训练的预训练模型default process group has not been ini-CSDN博客
解决3:想起来创建虚拟环境时指定用pip安装torch,但我用的是conda安装pytorch,于是用pip重装了cuda,解决
问题5:import PIL可以,但是from PIL import Image报错
解决:尝试了网上各种解决方法,无效,还是想起来创建虚拟环境时用的conda而不是readme指定的python venv,也许是这个原因,于是重装虚拟环境,解决(看别人的解决办法应该不用这么麻烦,也许可以自己uninstall几次试试)
问题6:torch.cuda.OutOfMemoryError: CUDA out of memory.
还没开始迭代就爆了
想了想还是accelerate的问题,参考GPU分布式训练推理——Accelerate - 知乎 (zhihu.com) 调了一下config,结果:
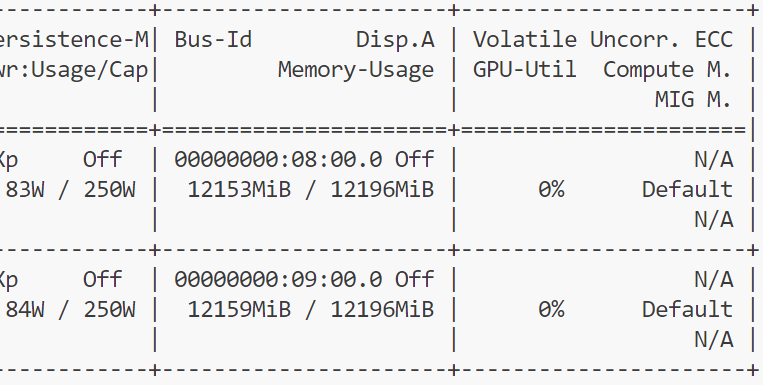
24G显存都爆了,论文issue区有人提到单卡4090能训练起来,多卡反而会OOM,不知道会不会是这个原因(我是两张12G卡),batch size之类的都调到最小了,不知道该怎么办了。。。
Stage2
3. 代码学习
并行unet:
reference_unet (UNet2DConditionModel):
- 这是一个 2D UNet 模型,用于处理二维图像数据。
- 主要用于对静态的二维图像进行条件建模,例如图像分割、图像生成等任务。
- 模型的输入和输出都是二维图像数据。
denoising_unet (UNet3DConditionModel):
- 这是一个 3D UNet 模型,但在代码中通过 from_pretrained_2d 参数初始化,可能是为了使用 2D 预训练模型进行初始化。
- 主要用于处理三维数据,用于视频数据等具有时间维度的数据。
- 模型需要额外考虑时间维度的信息,例如是否使用运动模块(use_motion_module)和是否使用时间注意力机制(unet_use_temporal_attention)。
可见两个unet都是从SD1.5初始化:
# 创建并加载自动编码器模型,并将其移动到GPU上
vae = AutoencoderKL.from_pretrained(cfg.vae_model_path).to(
"cuda", dtype=weight_dtype
)
reference_unet = UNet2DConditionModel.from_pretrained(
cfg.base_model_path, # 用sd1.5的unet初始化
subfolder="unet",
).to(device="cuda")
denoising_unet = UNet3DConditionModel.from_pretrained_2d(
cfg.base_model_path,
"",
subfolder="unet",
unet_additional_kwargs={
"use_motion_module": False,
"unet_use_temporal_attention": False,
},
).to(device="cuda")
# 创建并加载图像编码器模型,并将其移动到GPU上
image_enc = CLIPVisionModelWithProjection.from_pretrained(
cfg.image_encoder_path,
).to(dtype=weight_dtype, device="cuda")
其中vae来自sd-vae-ft-mse,具体的解释参考:关于Stable Diffusion中的VAE使用 - 知乎 (zhihu.com)
Stability AI发布了两种精调后的VAE解码器变体,ft-EMA和ft-MSE,它们强调的部分不同。EMA和MSE:指数移动平均(Exponential Moving Average)和均方误差(Mean Square Error)是测量自动编码器好坏的指标。在256×256图像上的评估是:EMA生成更清晰的图像,而MSE生成的图像更平滑。
image_encoder来自sd-image-variations-diffusers。模型介绍:lambdalabs/sd-image-variations-diffusers | ATYUN.COM 官网-人工智能教程资讯全方位服务平台















 244
244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









