









StableDiffusionPipeline
Pipeline基本结构
一个pipeline包含了如下大模块:
VAE,变分自编码器,把图像编码到特征,进行生成过程后再把特征解码到图像。
UNet,扩散模型的部分
Text-Encoder,用于把tokens编码为一串向量,用来控制扩散模型的生成。
小模块:
Tokenizer,把输入的文本按照字典编码为上面的tokens,
Scheduler,定义用哪种采样方法
Safety_checker,NSFW检测器
Feature_extractor,也是NSFW检测器的一部分
model_index.json负责把它们整合起来。
__init__函数
from diffusers import StableDiffusionPipeline
# 进入StableDiffusionPipeline函数:
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: xxxSchedulers, # 一般用DDIMSchedulers
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
):
super().__init__()其中vae,text_encoder,tokenizer,unet和scheduler是必需的
__call__函数
即生成环节的代码:
def __call__(
self,
prompt: Union[str, List[str]] = None,
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
guidance_rescale: float = 0.0,
):流程
编码提示词prompt
def encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
lora_scale: Optional[float] = None,
):首先使用tokenizer对prompt进行编码,max_length一般为77(CLIP)。一般而言,每一个prompt词对应一个token;如果是不存在于token字典中的词,tokenizer会将其分解成两个或以上的tokens:
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)之后用text_encoder对tokens进行编码,生成[1,77,768]的编码向量。这个text_encoder是CLIP中的Transformer,所以最后的输出结果就是Transformer中的last_hidden_state。
prompt_embeds = self.text_encoder(
text_input_ids.to(device),
attention_mask=attention_mask,
)
prompt_embeds = prompt_embeds[0] #取出'last_hidden_state'最后return了文本编码和空prompt文本编码。
接下来,准备随机噪声:
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)这个函数调用了torch.randn_tensor生成指定大小随机tensor。tensor的大小:[bs,4,64,64],bs是batchsize。如果一直生成512x512(这个尺寸上基本上不用动),tensor的大小就是固定的。
扩散:
for i, t in enumerate(timesteps):
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)首先,根据classifier-free guidance,设置有条件生成与无条件生成的两个latents。
随后,使用unet进行逐步去噪。
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
return_dict=False,
)[0]利用预测的噪声和当前latent预测一步去噪后的latent:
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]最后跳出循环,将latent使用VAE转为图像。从[bs, 4, 64, 64] -> [bs, 3, 512, 512],成为三通道图像的尺寸,并使用一些处理方法变为PIL格式的图像。
__call__函数返回bs张图像
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)UNet 2D Condition Model
代码位置:src/diffusers/models/unet_2d_condition.py
参考:Diffusers代码级讲解(一)—— StableDiffusionPipeline(2) - 知乎 (zhihu.com)
stable diffusion 中使用的 UNet 2D Condition Model 结构解析(diffusers库) - 知乎 (zhihu.com)
__init__函数
def __init__(
self,
sample_size: Optional[int] = 64,
in_channels: int = 4,
out_channels: int = 4,
down_block_types: Tuple[str] = (
"CrossAttnDownBlock2D",
"CrossAttnDownBlock2D",
"CrossAttnDownBlock2D",
"DownBlock2D",
),
mid_block_type: Optional[str] = "UNetMidBlock2DCrossAttn",
up_block_types: Tuple[str] = (
"UpBlock2D",
"CrossAttnUpBlock2D",
"CrossAttnUpBlock2D",
"CrossAttnUpBlock2D"),
only_cross_attention: Union[bool, Tuple[bool]] = False,
block_out_channels: Tuple[int] = (320, 640, 1280, 1280),
layers_per_block: Union[int, Tuple[int]] = 2,
attention_head_dim: Union[int, Tuple[int]] = 8,
cross_attention_dim: Union[int, Tuple[int]] = 768, #注意这里在原代码中是1280但config.json中是768
)sample_size:输入输出的size
in_channels:输入的通道数
out_channels:输出的通道数
down_block_types:使用的下采样块元组,默认为("CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D")
up_block_types:使用的上采样块元组,默认为("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D",)
layers_per_block:每个块中包含的层数,默认为2
VAE将[bs, 3, 512, 512]的噪声编码为[bs, 4, 64, 64]。
模型结构: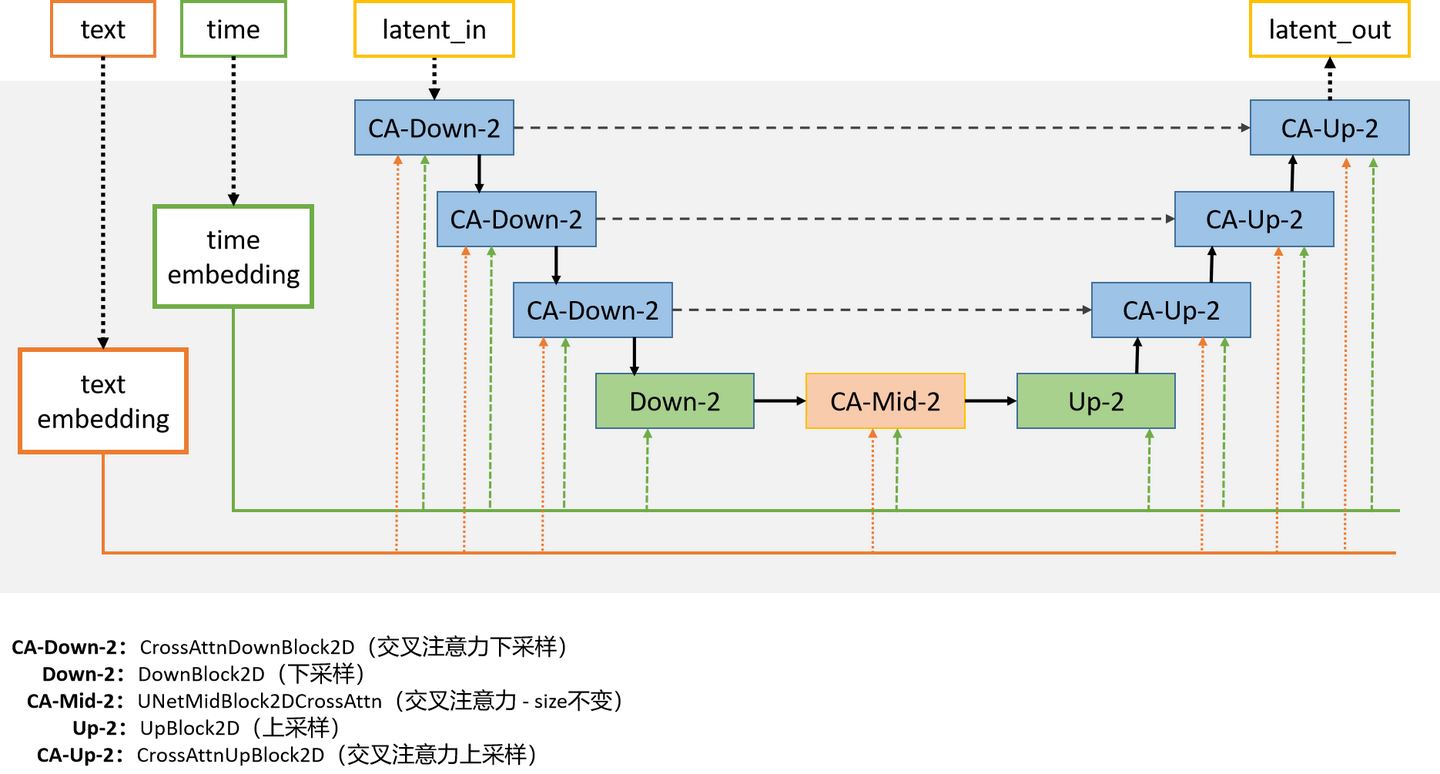
主要关注三个点:下采样模块、中间模块、上采样模块
其中 time_embedding 和 text_embedding 都是不变的,在每一个块里边都对模型提供当前Unet所处time信息以及全局text的指导信息(就是prompt),Resnet 中 xx_embeding 的生效方式就是直接加上去(简单粗暴),Transformer 中执行交叉注意力来使用指导信息 xx_embeding,大部分区域中 time_embeding 和 text_embeding 也都是直接加和然后当作一个最终 embeding 来用的。
所有的模块中都包含Resnet层,而这里的Resnet是改进后的,可以使用time_embedding嵌入,而text_embedding则被模块中的Transformer层使用,所以说我们输入的两个嵌入其实是分开使用的,最后在某处合并
U-Net的特点是输入输出尺寸一致,因此一定也会有3次upsample,然而此时会先经过UpBlock发生一次upSample,然后在前两个CrossAttnUpBlock2D会发生upsample,第三个CrossAttnUpBlock2D不upsample。
only_cross_attention一定是False,文本控制必然发生cross-attention
block_out_channels,这是CrossAttnDownBlock2D中使用Conv对通道数进行变化。
layers_per_block: CrossAttnDownBlock2D中包含的(ResnetBlock+Transformer2DModel)对数。
attention_head_dim和cross_attention_dim:我们所说的Transformer是一种多头注意力机制,常见的头数就是8。cross_attention_dim代表文本编码的维数。
进入函数主体,上来一大堆if语句是判断你的 注意力维度/注意力头数/注意力每头多少维 是否能对应。只要不修改config.json,这些都是不会发生问题的。
然后出现self.conv_in,用来把输入的[bs, 4, 64, 64]的latent用卷积层变为[bs, 320, 64, 64],从而正式进入Transformer部分。
conv_in_padding = (conv_in_kernel - 1) // 2
self.conv_in = nn.Conv2d(
in_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding
)然后又是一大堆的if语句,它们负责为你生成正确的self.time_proj和self.time_embedding(是MLP,负责编码时间t,也是Transformer要用到的)。
之后就是
output_channel = block_out_channels[0]
for i, down_block_type in enumerate(down_block_types):
input_channel = output_channel
output_channel = block_out_channels[i]
is_final_block = i == len(block_out_channels) - 1
down_block = get_down_block(
down_block_type,
num_layers=layers_per_block[i],
transformer_layers_per_block=transformer_layers_per_block[i],
in_channels=input_channel,
out_channels=output_channel,
#xxxxx省略一千字
)
self.down_blocks.append(down_block)使用get_down_block函数,我们设置的down_block_type有四个,那么这个函数就会找对应的block类进行初始化,初始化用到的参数就是我们之前输的那一大堆东西,但无论如何最后down_block就是一个能用的CrossAttnDownBlock2D或DownBlock2D。使用self.down_blocks把它们连成一串。get_up_block也是一样的道理。
中间有一个self.mid_block则直接new了一个UNetMidBlock2DCrossAttn类对象。
self.conv_out = nn.Conv2d(
block_out_channels[0], out_channels, kernel_size=conv_out_kernel, padding=conv_out_padding
)最后self.conv_out把320维的latent重新变为4维。(到这里返回的已经是预测的噪声了)
至此 UNet2DConditionModel 的各种子子模块都定义完了
forward(__call__)
def forward(
self,
sample: torch.FloatTensor,
timestep: Union[torch.Tensor, float, int],
encoder_hidden_states: torch.Tensor,
class_labels: Optional[torch.Tensor] = None,
timestep_cond: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
mid_block_additional_residual: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
return_dict: bool = True,
) -> Union[UNet2DConditionOutput, Tuple]:这个参数没有__init__那么多,但也是只有前三个是常用的:
sample就是latent,timestep是你的扩散模型进行到第几步了;encoder_hidden_states是控制向量也就是文本编码。返回的是latent对应预测的噪声
step1 time
是很重要的一部分,我们知道扩散模型是一步步进行的,时间戳step代表了我们进行到了第几步。又由于Transformer需要用到time-embedding,因此我们把当前时间step使用self.time_proj和self.time_embedding编码成Transformer能接受的time-embedding,这样U-Net能正确预测出当前step的噪声。
这个time-embedding被嵌入到所有CrossAttnUp/Mid/DownBlock2D中,十分重要。
step2 pre-process
[bs, 4, 64, 64] -> [bs, 320, 64, 64]
step3 down
将latent按照self.down_blocks的顺序依次forward一遍,注意U-Net一直是一个residual的过程,会保存res_samples用来加到上采样的过程中。
for downsample_block in self.down_blocks:
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
# For t2i-adapter CrossAttnDownBlock2D
additional_residuals = {}
if is_adapter and len(down_block_additional_residuals) > 0:
additional_residuals["additional_residuals"] = down_block_additional_residuals.pop(0)
sample, res_samples = downsample_block(
hidden_states=sample,
temb=emb,
encoder_hidden_states=encoder_hidden_states,
attention_mask=attention_mask,
cross_attention_kwargs=cross_attention_kwargs,
encoder_attention_mask=encoder_attention_mask,
**additional_residuals,
)
else:
sample, res_samples = downsample_block(hidden_states=sample, temb=emb, scale=lora_scale)
if is_adapter and len(down_block_additional_residuals) > 0:
sample += down_block_additional_residuals.pop(0)
down_block_res_samples += res_samples这里用了一个很巧妙的方法判断是哪个down_blocks:如果是CrossAttnDownBlock2D,那么它会出现一个属性叫做has_cross_attention,就会走第一个if分支;如果是DownBlock2D,就会走第二个分支。
仅第一个分支输入了encoder_hidden_states,也就是cross-attention要用到的文本编码。
这个版本添加了对ControlNet的支持,也就是downsample_block旁边多了一些新的block,那么对这些新block也forward一下就好了。
step4 mid
将latent输入到mid_block进行一次forward
step5 up
和down部分很像,不过由于添加了res_sample部分,
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]直接提取出来就好了。upsample_block中会输入这些res_sample,做一个求和。
step6 post-process
[bs, 320, 64, 64] -> [bs, 4, 64, 64]
最后使用一个UNet2DConditionOutput,以tensor的形式返回预测的噪声。
参考:stable diffusion 中使用的 UNet 2D Condition Model 结构解析(diffusers库) - 知乎 (zhihu.com)
Diffusers代码级讲解(一)—— StableDiffusionPipeline(2) - 知乎 (zhihu.com)

















 3451
3451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









