






内容:
非线性可分支持向量机模型
分别使用线性核﹑多项式核与高斯核对lris 数据集的2/3数据训练支持向量机,剩余1/3数据进行测试,计算正确率。 分别使用线性核、多项式核与高斯核对lris数据集的2/3数据训练支持向量机,剩余1/3数据进行测试,计算正确率。
数据集(150)
具体数据如下(如果不能运行,尝试在末尾加回车)
5.1 3.5 1.4 0.2 1
4.9 3 1.4 0.2 1
4.7 3.2 1.3 0.2 1
4.6 3.1 1.5 0.2 1
5 3.6 1.4 0.2 1
5.4 3.9 1.7 0.4 1
4.6 3.4 1.4 0.3 1
5 3.4 1.5 0.2 1
4.4 2.9 1.4 0.2 1
4.9 3.1 1.5 0.1 1
5.4 3.7 1.5 0.2 1
4.8 3.4 1.6 0.2 1
4.8 3 1.4 0.1 1
4.3 3 1.1 0.1 1
5.8 4 1.2 0.2 1
5.7 4.4 1.5 0.4 1
5.4 3.9 1.3 0.4 1
5.1 3.5 1.4 0.3 1
5.7 3.8 1.7 0.3 1
5.1 3.8 1.5 0.3 1
5.4 3.4 1.7 0.2 1
5.1 3.7 1.5 0.4 1
4.6 3.6 1 0.2 1
5.1 3.3 1.7 0.5 1
4.8 3.4 1.9 0.2 1
5 3 1.6 0.2 1
5 3.4 1.6 0.4 1
5.2 3.5 1.5 0.2 1
5.2 3.4 1.4 0.2 1
4.7 3.2 1.6 0.2 1
4.8 3.1 1.6 0.2 1
5.4 3.4 1.5 0.4 1
5.2 4.1 1.5 0.1 1
5.5 4.2 1.4 0.2 1
4.9 3.1 1.5 0.1 1
5 3.2 1.2 0.2 1
5.5 3.5 1.3 0.2 1
4.9 3.1 1.5 0.1 1
4.4 3 1.3 0.2 1
5.1 3.4 1.5 0.2 1
5 3.5 1.3 0.3 1
4.5 2.3 1.3 0.3 1
4.4 3.2 1.3 0.2 1
5 3.5 1.6 0.6 1
5.1 3.8 1.9 0.4 1
4.8 3 1.4 0.3 1
5.1 3.8 1.6 0.2 1
4.6 3.2 1.4 0.2 1
5.3 3.7 1.5 0.2 1
5 3.3 1.4 0.2 1
7 3.2 4.7 1.4 2
6.4 3.2 4.5 1.5 2
6.9 3.1 4.9 1.5 2
5.5 2.3 4 1.3 2
6.5 2.8 4.6 1.5 2
5.7 2.8 4.5 1.3 2
6.3 3.3 4.7 1.6 2
4.9 2.4 3.3 1 2
6.6 2.9 4.6 1.3 2
5.2 2.7 3.9 1.4 2
5 2 3.5 1 2
5.9 3 4.2 1.5 2
6 2.2 4 1 2
6.1 2.9 4.7 1.4 2
5.6 2.9 3.6 1.3 2
6.7 3.1 4.4 1.4 2
5.6 3 4.5 1.5 2
5.8 2.7 4.1 1 2
6.2 2.2 4.5 1.5 2
5.6 2.5 3.9 1.1 2
5.9 3.2 4.8 1.8 2
6.1 2.8 4 1.3 2
6.3 2.5 4.9 1.5 2
6.1 2.8 4.7 1.2 2
6.4 2.9 4.3 1.3 2
6.6 3 4.4 1.4 2
6.8 2.8 4.8 1.4 2
6.7 3 5 1.7 2
6 2.9 4.5 1.5 2
5.7 2.6 3.5 1 2
5.5 2.4 3.8 1.1 2
5.5 2.4 3.7 1 2
5.8 2.7 3.9 1.2 2
6 2.7 5.1 1.6 2
5.4 3 4.5 1.5 2
6 3.4 4.5 1.6 2
6.7 3.1 4.7 1.5 2
6.3 2.3 4.4 1.3 2
5.6 3 4.1 1.3 2
5.5 2.5 4 1.3 2
5.5 2.6 4.4 1.2 2
6.1 3 4.6 1.4 2
5.8 2.6 4 1.2 2
5 2.3 3.3 1 2
5.6 2.7 4.2 1.3 2
5.7 3 4.2 1.2 2
5.7 2.9 4.2 1.3 2
6.2 2.9 4.3 1.3 2
5.1 2.5 3 1.1 2
5.7 2.8 4.1 1.3 2
6.3 3.3 6 2.5 3
5.8 2.7 5.1 1.9 3
7.1 3 5.9 2.1 3
6.3 2.9 5.6 1.8 3
6.5 3 5.8 2.2 3
7.6 3 6.6 2.1 3
4.9 2.5 4.5 1.7 3
7.3 2.9 6.3 1.8 3
6.7 2.5 5.8 1.8 3
7.2 3.6 6.1 2.5 3
6.5 3.2 5.1 2 3
6.4 2.7 5.3 1.9 3
6.8 3 5.5 2.1 3
5.7 2.5 5 2 3
5.8 2.8 5.1 2.4 3
6.4 3.2 5.3 2.3 3
6.5 3 5.5 1.8 3
7.7 3.8 6.7 2.2 3
7.7 2.6 6.9 2.3 3
6 2.2 5 1.5 3
6.9 3.2 5.7 2.3 3
5.6 2.8 4.9 2 3
7.7 2.8 6.7 2 3
6.3 2.7 4.9 1.8 3
6.7 3.3 5.7 2.1 3
7.2 3.2 6 1.8 3
6.2 2.8 4.8 1.8 3
6.1 3 4.9 1.8 3
6.4 2.8 5.6 2.1 3
7.2 3 5.8 1.6 3
7.4 2.8 6.1 1.9 3
7.9 3.8 6.4 2 3
6.4 2.8 5.6 2.2 3
6.3 2.8 5.1 1.5 3
6.1 2.6 5.6 1.4 3
7.7 3 6.1 2.3 3
6.3 3.4 5.6 2.4 3
6.4 3.1 5.5 1.8 3
6 3 4.8 1.8 3
6.9 3.1 5.4 2.1 3
6.7 3.1 5.6 2.4 3
6.9 3.1 5.1 2.3 3
5.8 2.7 5.1 1.9 3
6.8 3.2 5.9 2.3 3
6.7 3.3 5.7 2.5 3
6.7 3 5.2 2.3 3
6.3 2.5 5 1.9 3
6.5 3 5.2 2 3
6.2 3.4 5.4 2.3 3
5.9 3 5.1 1.8 3代码:
有不对的请多指正
实在不想写了就来这看看吧~~~
import math # 数学
import random # 随机
import numpy as np
import matplotlib.pyplot as plt
def zhichi_w(zhichi, xy, a): # 计算更新 w
w = [0, 0]
if len(zhichi) == 0: # 初始化的0
return w
for i in zhichi:
w[0] += a[i] * xy[0][i] * xy[2][i] # 更新w
w[1] += a[i] * xy[1][i] * xy[2][i]
return w
def zhichi_b(zhichi, xy, a): # 计算更新 b
b = 0
if len(zhichi) == 0: # 初始化的0
return 0
for s in zhichi: # 对任意的支持向量有 ysf(xs)=1 所有支持向量求解平均值
sum = 0
for i in zhichi:
sum += a[i] * xy[2][i] * (xy[0][i] * xy[0][s] + xy[1][i] * xy[1][s])
b += 1 / xy[2][s] - sum
return b / len(zhichi)
def SMO(xy, m):
a = [0.0] * len(xy[0]) # 拉格朗日乘子
zhichi = set() # 支持向量下标
loop = 1 # 循环标记(符合KKT)
w = [0, 0] # 初始化 w
b = 0 # 初始化 b
while loop:
loop += 1
if loop == 150:
print("达到早停标准")
print("循环了:", loop, "次")
loop = 0
break
# 初始化=========================================
fx = [] # 储存所有的fx
yfx = [] # 储存所有yfx-1的值
Ek = [] # Ek,记录fx-y用于启发式搜索
E_ = -1 # 贮存最大偏差,减少计算
a1 = 0 # SMO a1
a2 = 0 # SMO a2
# 初始化结束======================================
# 寻找a1,a2======================================
for i in range(len(xy[0])): # 计算所有的 fx yfx-1 Ek
fx.append(w[0] * xy[0][i] + w[1] * xy[1][i] + b) # 计算 fx=wx+b
yfx.append(xy[2][i] * fx[i] - 1) # 计算 yfx-1
Ek.append(fx[i] - xy[2][i]) # 计算 fx-y
if i in zhichi: # 之前看过的不看了,防止重复找某个a
continue
if yfx[i] <= yfx[a1]:
a1 = i # 得到偏离最大位置的下标(数值最小的)
if yfx[a1] >= 0: # 最小的也满足KKT
print("循环了:", loop, "次")
loop = 0 # 循环标记(符合KKT)置零(没有用到)
break
for i in range(len(xy[0])): # 遍历找间隔最大的a2
if i == a1: # 如果是a1,跳过
continue
Ei = abs(Ek[i] - Ek[a1]) # |Eki-Eka1|
if Ei < E_: # 找偏差
E_ = Ei # 储存偏差的值
a2 = i # 储存偏差的下标
# 寻找a1,a2结束===================================
zhichi.add(a1) # a1录入支持向量
zhichi.add(a2) # a2录入支持向量
# 分析约束条件=====================================
# c=a1*y1+a2*y2
c = a[a1] * xy[2][a1] + a[a2] * xy[2][a2] # 求出c
# n=K11+k22-2*k12
if m == "xianxinghe": # 线性核
n = xy[0][a1] ** 2 + xy[1][a1] ** 2 + xy[0][a2] ** 2 + xy[1][a2] ** 2 - 2 * (
xy[0][a1] * xy[0][a2] + xy[1][a1] * xy[1][a2])
elif m == "duoxiangshihe": # 多项式核(这里是二次)
n = (xy[0][a1] ** 2 + xy[1][a1] ** 2) ** 2 + (xy[0][a2] ** 2 + xy[1][a2] ** 2) ** 2 - 2 * (
xy[0][a1] * xy[0][a2] + xy[1][a1] * xy[1][a2]) ** 2
else: # 高斯核 取 2σ^2 = 1
n = 2 * math.exp(-1) - 2 * math.exp(-((xy[0][a1] - xy[0][a2]) ** 2 + (xy[1][a1] - xy[1][a2]) ** 2))
# 确定a1的可行域=====================================
if xy[2][a1] == xy[2][a2]:
L = max(0.0, a[a1] + a[a2] - 0.5) # 下界
H = min(0.5, a[a1] + a[a2]) # 上界
else:
L = max(0.0, a[a1] - a[a2]) # 下界
H = min(0.5, 0.5 + a[a1] - a[a2]) # 上界
if n > 0:
a1_New = a[a1] - xy[2][a1] * (Ek[a1] - Ek[a2]) / n # a1_New = a1_old-y1(e1-e2)/n
# print("x1=",xy[0][a1],"y1=",xy[1][a1],"z1=",xy[2][a1],"x2=",xy[0][a2],"y2=",xy[1][a2],"z2=",xy[2][a2],"a1_New=",a1_New)
# 越界裁剪============================================================
if a1_New >= H:
a1_New = H
elif a1_New <= L:
a1_New = L
else:
a1_New = min(H, L)
# 参数更新=======================================
a[a2] = a[a2] + xy[2][a1] * xy[2][a2] * (a[a1] - a1_New) # a2更新
a[a1] = a1_New # a1更新
w = zhichi_w(zhichi, xy, a) # 更新w
b = zhichi_b(zhichi, xy, a) # 更新b
# print("W=", w, "b=", b, "zhichi=", zhichi, "a1=", a[a1], "a2=", a[a2])
# 标记支持向量======================================
for i in zhichi:
if a[i] == 0: # 选了,但值仍为0
loop = loop + 1
e = 'silver'
else:
if xy[2][i] == 1:
e = 'b'
else:
e = 'r'
plt.scatter(x1[0][i], x1[1][i], c='none', s=100, linewidths=1, edgecolor=e)
print("支持向量数为:", len(zhichi), "\na为零支持向量:", loop)
print("有用向量数:", len(zhichi) - loop)
# 返回数据 w b =======================================
return [w, b]
def panduan(xyz, w_b1,w_b2):
c = 0
for i in range(len(xyz[0])):
if (xyz[0][i] * w_b1[0][0] + xyz[1][i] * w_b1[0][1] + w_b1[1]) * xyz[2][i][0] < 0:
c = c + 1
continue
if (xyz[0][i] * w_b2[0][0] + xyz[1][i] * w_b2[0][1] + w_b2[1]) * xyz[2][i][1] < 0:
c = c + 1
continue
return (1 - c / len(xyz[0])) * 100
def huitu(x1,x2,wb1,wb2,name):
x = [x1[0][:],x1[1][:],x1[2][:]]
for i in range(len(x[2])): # 对训练集‘上色’
if x[2][i] == [1, 1]:
x[2][i] = 'r' # 训练集 1 1 红色
elif x[2][i] == [-1, 1]:
x[2][i] = 'g' # 训练集 -1 1 绿色
else:
x[2][i] = 'b' # 训练集 -1 -1 蓝色
plt.scatter(x[0], x[1], c=x[2], alpha=0.8) # 绘点训练集
x = [x2[0][:],x2[1][:],x2[2][:]]
for i in range(len(x[2])): # 对测试集‘上色’
if x[2][i] == [1, 1]:
x[2][i] = 'orange' # 训练集 1 1 橙色
elif x[2][i] == [-1, 1]:
x[2][i] = 'y' # 训练集 -1 1 黄色
else:
x[2][i] = 'm' # 训练集 -1 -1 紫色
plt.scatter(x[0], x[1], c=x[2], alpha=0.8) # 绘点测试集
plt.xlabel('x') # x轴标签
plt.ylabel('y') # y轴标签
plt.title(name) # 标题
xl = np.arange(min(x[0]), max(x[0]), 0.1) # 绘制分类线一
yl = (-wb1[0][0] * xl - wb1[1]) / wb1[0][1]
plt.plot(xl, yl, 'r')
xl = np.arange(min(x[0]), max(x[0]), 0.1) # 绘制分类线二
yl = (-wb2[0][0] * xl - wb2[1]) / wb2[0][1]
plt.plot(xl, yl, 'b')
# 主函数=======================================================
f = open('Iris.txt', 'r') # 读文件
x = [[], [], [], [], []] # 花朵属性,(0,1,2,3),花朵种类
while 1:
yihang = f.readline() # 读一行
if len(yihang) <= 1: # 读到末尾结束
break
fenkai = yihang.split('\t') # 按\t分开
for i in range(4): # 分开的四个值
x[i].append(eval(fenkai[i])) # 化为数字加到x中
if (eval(fenkai[4]) == 1): # 将标签化为向量形式
x[4].append([1, 1])
else:
if (eval(fenkai[4]) == 2):
x[4].append([-1, 1])
else:
x[4].append([-1, -1])
print('数据集=======================================================')
print(len(x[0])) # 数据大小
# 选择数据===================================================
shuxing1 = eval(input("选取第一个属性:"))
if shuxing1 < 0 or shuxing1 > 4:
print("无效选项,默认选择第1项")
shuxing1 = 1
shuxing2 = eval(input("选取第一个属性:"))
if shuxing2 < 0 or shuxing2 > 4 or shuxing1 == shuxing2:
print("无效选项,默认选择第2项")
shuxing2 = 2
# 生成数据集==================================================
lt = list(range(150)) # 得到一个顺序序列
random.shuffle(lt) # 打乱序列
x1 = [[], [], []] # 初始化x1
x2 = [[], [], []] # 初始化x2
for i in lt[0:100]: # 截取部分做训练集
x1[0].append(x[shuxing1][i]) # 加上数据集x属性
x1[1].append(x[shuxing2][i]) # 加上数据集y属性
x1[2].append(x[4][i]) # 加上数据集c标签
for i in lt[100:150]: # 截取部分做测试集
x2[0].append(x[shuxing1][i]) # 加上数据集x属性
x2[1].append(x[shuxing2][i]) # 加上数据集y属性
x2[2].append(x[4][i]) # 加上数据集c标签
print('\n\n开始训练==============================================')
print('\n线性核==============================================')
# 计算 w b============================================
plt.figure(1) # 第一张画布
x = [x1[0][:], x1[1][:], []] # 第一次分类
for i in x1[2]:
x[2].append(i[0]) # 加上数据集标签
wb1 = SMO(x,"xianxinghe")
x = [x1[0][:], x1[1][:], []] # 第二次分类
for i in x1[2]:
x[2].append(i[1]) # 加上数据集标签
wb2 = SMO(x,"xianxinghe")
print("w1为:", wb1[0], " b1为:", wb1[1])
print("w2为:", wb2[0], " b2为:", wb2[1])
# 计算正确率===========================================
print("训练集上的正确率为:", panduan(x1, wb1,wb2), "%")
print("测试集上的正确率为:", panduan(x2, wb1,wb2), "%")
# 绘图 ===============================================
# 圈着的是曾经选中的值,灰色的是选中但更新为0
huitu(x1,x2,wb1,wb2,"xianxinghe")
print('\n多项式核============================================')
# 计算 w b============================================
plt.figure(2) # 第二张画布
x = [x1[0][:], x1[1][:], []] # 第一次分类
for i in x1[2]:
x[2].append(i[0]) # 加上数据集标签
wb1 = SMO(x,"duoxiangshihe")
x = [x1[0][:], x1[1][:], []] # 第二次分类
for i in x1[2]:
x[2].append(i[1]) # 加上数据集标签
wb2 = SMO(x,"duoxiangshihe")
print("w1为:", wb1[0], " b1为:", wb1[1])
print("w2为:", wb2[0], " b2为:", wb2[1])
# 计算正确率===========================================
print("训练集上的正确率为:", panduan(x1, wb1,wb2), "%")
print("测试集上的正确率为:", panduan(x2, wb1,wb2), "%")
# 绘图 ===============================================
# 圈着的是曾经选中的值,灰色的是选中但更新为0
huitu(x1,x2,wb1,wb2,"duoxiangshihe")
print('\n高斯核==============================================')
# 计算 w b============================================
plt.figure(3) # 第三张画布
x = [x1[0][:], x1[1][:], []] # 第一次分类
for i in x1[2]:
x[2].append(i[0]) # 加上数据集标签
wb1 = SMO(x,"gaosihe")
x = [x1[0][:], x1[1][:], []] # 第二次分类
for i in x1[2]:
x[2].append(i[1]) # 加上数据集标签
wb2 = SMO(x,"gaosihe")
print("w1为:", wb1[0], " b1为:", wb1[1])
print("w2为:", wb2[0], " b2为:", wb2[1])
# 计算正确率===========================================
print("训练集上的正确率为:", panduan(x1, wb1,wb2), "%")
print("测试集上的正确率为:", panduan(x2, wb1,wb2), "%")
# 绘图 ===============================================
# 圈着的是曾经选中的值,灰色的是选中但更新为0
huitu(x1,x2,wb1,wb2,"gaosihe")
#显示所有图
plt.show() # 显示结果实例:
选取 0 1
数据集=======================================================
150
选取第一个属性:0
选取第一个属性:1
开始训练==============================================
线性核==============================================
循环了: 59 次
支持向量数为: 58
a为零支持向量: 43
有用向量数: 15
循环了: 81 次
支持向量数为: 80
a为零支持向量: 37
有用向量数: 43
w1为: [-1.2015577886380138, 1.0472346551913316] b1为: 3.193887811107239
w2为: [-0.9046180342303862, -0.050401017033139706] b2为: 5.818677047436661
训练集上的正确率为: 84.0 %
测试集上的正确率为: 80.0 %
多项式核============================================
达到早停标准
循环了: 150 次
支持向量数为: 70
a为零支持向量: 2
有用向量数: 68
达到早停标准
循环了: 150 次
支持向量数为: 100
a为零支持向量: 2
有用向量数: 98
w1为: [-1.5323422583266884, -0.6451163863274796] b1为: 10.19605818386737
w2为: [-0.32703052684507555, -0.07341379665570845] b2为: 2.474197513122665
训练集上的正确率为: 55.00000000000001 %
测试集上的正确率为: 60.0 %
高斯核==============================================
循环了: 44 次
支持向量数为: 43
a为零支持向量: 37
有用向量数: 6
循环了: 66 次
支持向量数为: 65
a为零支持向量: 37
有用向量数: 28
w1为: [-1.4000000000000004, 1.2000000000000002] b1为: 3.821860465116281
w2为: [-1.2206265744055393, -0.29455424617379977] b2为: 8.488342156179229
训练集上的正确率为: 84.0 %
测试集上的正确率为: 80.0 %


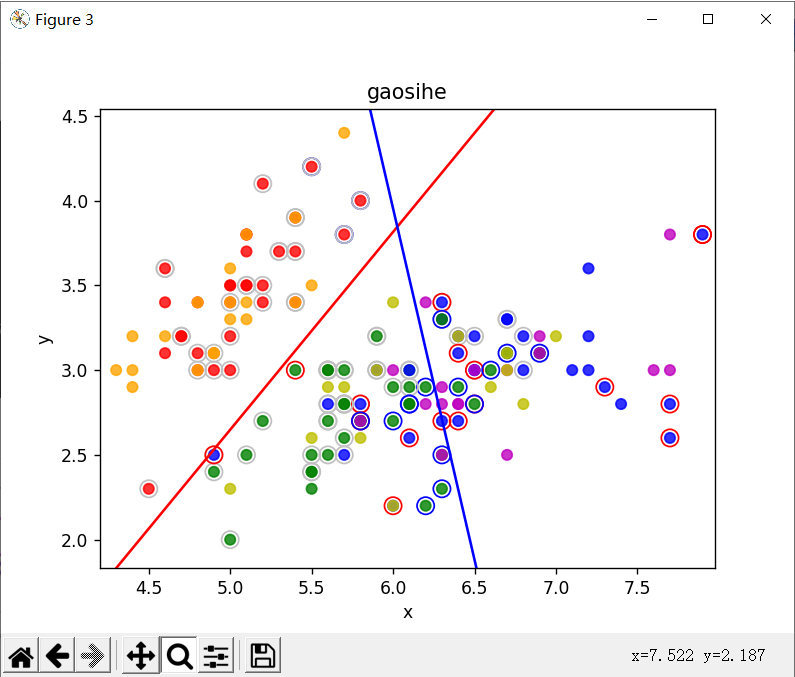
选取 1 3
数据集=======================================================
150
选取第一个属性:1
选取第一个属性:3
开始训练==============================================
线性核==============================================
循环了: 67 次
支持向量数为: 66
a为零支持向量: 50
有用向量数: 16
循环了: 44 次
支持向量数为: 43
a为零支持向量: 17
有用向量数: 26
w1为: [0.5633951571969109, -1.042348513330865] b1为: -0.9195155744439709
w2为: [-0.06277727278771472, -2.4362648813243806] b2为: 4.185161300086744
训练集上的正确率为: 97.0 %
测试集上的正确率为: 94.0 %
多项式核============================================
达到早停标准
循环了: 150 次
支持向量数为: 88
a为零支持向量: 19
有用向量数: 69
达到早停标准
循环了: 150 次
支持向量数为: 39
a为零支持向量: 4
有用向量数: 35
w1为: [0.21771014101070363, -0.5387711292789139] b1为: -0.3383609523351082
w2为: [-0.010052537823134533, -0.3832264577071416] b2为: 0.6811197228851011
训练集上的正确率为: 96.0 %
测试集上的正确率为: 94.0 %
高斯核==============================================
循环了: 45 次
支持向量数为: 44
a为零支持向量: 36
有用向量数: 8
达到早停标准
循环了: 150 次
支持向量数为: 44
a为零支持向量: 42
有用向量数: 2
w1为: [0.9855920219400248, -1.21694723510404] b1为: -2.034100651391037
w2为: [0.19999999999999996, -0.9500000000000001] b2为: 1.0344318181818182
训练集上的正确率为: 97.0 %
测试集上的正确率为: 94.0 %

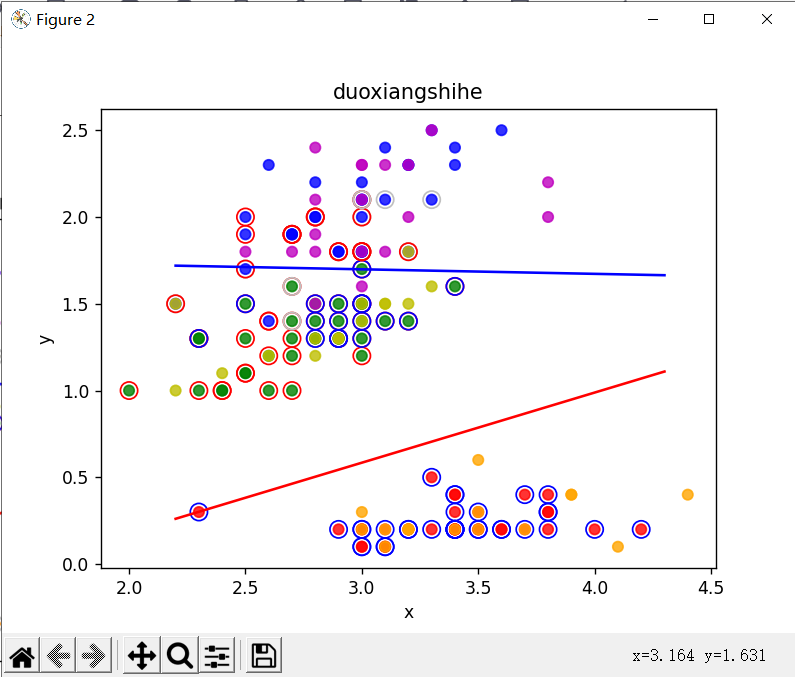
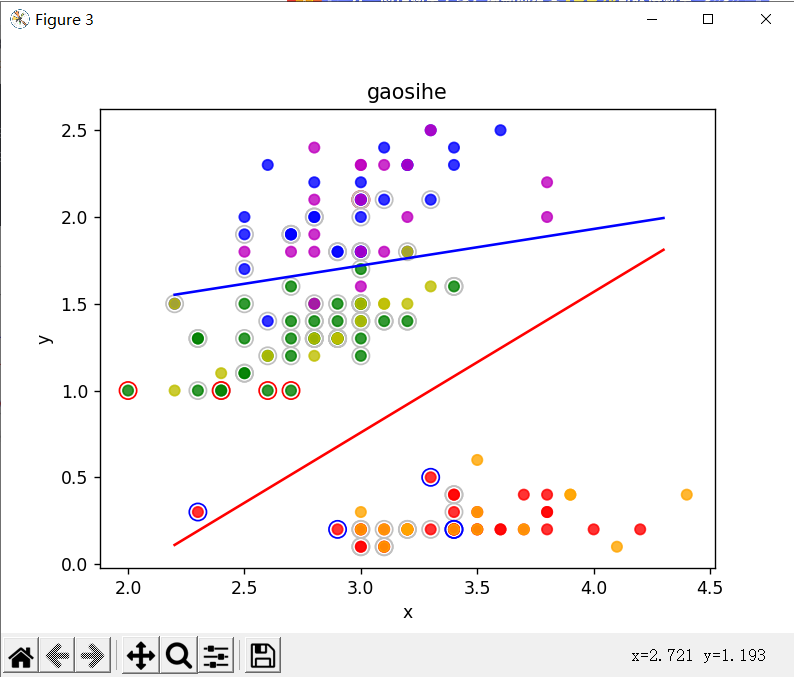
可以对所有属性组合。
可以看出,多项式核一定有一些错误,,,希望能够有人指正














 881
881











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









