






连续松弛(Continuous Relaxation) 是神经架构搜索(Neural Architecture Search, NAS)中的一种重要技术,它的核心思想是将传统的离散架构搜索问题转化为一个连续优化问题,从而能够利用现有的优化算法(如梯度下降)进行高效的搜索。由于神经网络架构空间通常是离散的,传统的搜索方法(例如强化学习、进化算法)往往面临较大的计算开销,而通过连续松弛技术,可以大大简化搜索过程,提升搜索效率。
1. 神经架构搜索问题
神经架构搜索旨在从大量可能的网络结构中自动寻找最优的网络架构。通常,神经网络的架构由多个超参数(如层数、每层的神经元数、卷积核大小等)组成,而这些超参数通常是离散的。对于一个给定的任务,我们需要在这些离散的架构中搜索最优架构。
传统的搜索方法,如基于强化学习的架构搜索和进化算法,都依赖于从离散空间中选择不同的网络架构进行训练和评估,通常这些方法在计算开销和搜索时间上都非常昂贵。
2. 连续松弛的动机
神经架构搜索中的一个核心问题是离散优化:架构空间通常是离散的,例如,我们无法对卷积核的大小、网络层数等进行连续的微调。在这种情况下,很多搜索算法(如强化学习、进化算法)通过对每种架构进行训练、评估并选择表现最好的架构,但这个过程非常费时且资源密集。
连续松弛通过将离散的架构空间“松弛”成一个连续的空间,使得优化问题可以通过梯度下降等连续优化方法来求解,从而减少搜索过程中的计算开销。
3. 连续松弛的实现方式
连续松弛技术通常是通过对离散架构空间进行某种形式的松弛(relaxation),将其变成一个连续可微的优化问题。最常见的实现方式有以下几种:
3.1 使用连续变量表示架构
最常见的做法是通过引入连续控制变量来表示离散的架构选择。例如,在搜索神经架构时,假设我们需要选择某些网络组件(如卷积层、全连接层)的类型。通过将每个组件的选择变为一个连续的值,网络架构的搜索过程就变成了对这些连续变量的优化。
假设我们有一个卷积层的操作空间 {Conv3x3,Conv5x5,MaxPool3x3,AvgPool3x3}\{Conv3x3, Conv5x5, MaxPool3x3, AvgPool3x3\},我们可以将其转化为一个连续值 xi∈[0,1]x_i \in [0, 1] 表示每种操作的权重。然后,在训练过程中,根据这些连续变量的值来加权选择不同的操作。具体来说,使用一个softmax或sigmoid函数将离散选择转化为概率分布,再通过这些概率加权选择不同的网络操作。
3.2 基于连续的超参数搜索
在连续松弛的框架下,我们可以将网络架构的超参数(例如,卷积层的数量、每层的神经元数、卷积核大小等)转化为连续变量,并使用连续优化算法(如梯度下降)来优化这些超参数。这样,架构搜索问题就转化为一个连续的优化问题,可以直接应用常见的优化方法。
3.3 结构化稀疏化(Structured Sparsity)
一种改进的连续松弛方法是通过结构化稀疏化来控制网络的结构。通过将网络中某些参数设置为稀疏(即接近零),我们可以控制模型的结构。这种方法不仅减少了计算开销,还可以有效地降低网络的复杂度。例如,使用L1正则化来诱导稀疏性,或通过引入稀疏化技术直接优化网络的架构。
4. 连续松弛的关键技术与方法
以下是一些常见的技术和方法,通常会在连续松弛的框架中使用:
4.1 架构梯度优化
架构梯度优化方法是一种直接通过梯度下降优化架构的策略。在这种方法中,我们对离散架构的表示进行松弛,使得架构可以通过连续参数进行调节。例如,假设一个架构是通过控制某些超参数(如卷积层的大小或选择某种激活函数)来表示的,我们可以通过梯度反向传播来更新这些超参数,从而找到最优的架构。
4.2 基于超参数的连续松弛
另一种常见的方法是将神经网络的超参数(如卷积层的大小、每层的神经元数等)视为连续的变量,并使用优化算法(如梯度下降)来优化这些超参数。这种方法不仅能处理离散架构选择问题,还能处理一些超参数选择问题,如学习率、批量大小等。
4.3 可微分架构搜索(Differentiable NAS)
可微分架构搜索是一种通过将神经网络架构表示成一个可微分的连续函数,使得网络架构的搜索可以通过标准的梯度下降方法来进行优化。通过对离散操作进行松弛,我们可以直接使用梯度信息来优化架构。
最著名的可微分架构搜索方法是DARTS(Differentiable Architecture Search),它通过对架构的操作空间进行连续松弛,并利用梯度下降来优化架构的选择,从而使得架构搜索问题变得更加高效。
好的,我明白你对连续松弛的实现方式还有些疑惑。让我尝试通过更具体的例子来帮助你理解。
问题背景:离散架构空间
在神经架构搜索(NAS)中,通常我们的目标是从一些离散的架构选择空间中找到最优的架构。假设你要选择网络的某些组件(比如卷积层类型、池化层、激活函数等),这些选择是离散的:
例如:
- 对于一个卷积层,你可能有多个选项:3×3卷积、5×5卷积、最大池化、平均池化等。
- 对于每一层,你还需要选择不同的超参数,比如卷积核的数量或大小。
2. 连续松弛的核心思想
连续松弛的核心思想是将这些离散的选择转化为连续的变量,这样就可以用标准的优化算法(如梯度下降)进行优化,而不必直接枚举所有的离散架构。这种方式可以显著减少搜索成本,因为你不再需要对每种架构进行完全的训练和评估。
3. 如何实现连续松弛?
3.1 将离散选择转化为连续变量
假设你有一个选择操作的空间,比如:
- 卷积操作:{3×3 Conv,5×5 Conv,MaxPool,AvgPool}
传统的做法是直接在这四种操作中选择一个进行训练。而通过连续松弛,你将这四种操作转化为连续的概率变量。具体步骤如下:
-
为每个操作定义一个连续权重:我们为每个操作定义一个连续值,例如 x1,x2,x3,x4,每个 xi∈[0,1],表示选择每个操作的权重。
- x1 表示 3×3卷积操作的权重。
- x2 表示 5×5 卷积操作的权重。
- x3 表示最大池化操作的权重。
- x4 表示平均池化操作的权重。
-
将这些权重归一化:为了确保它们能够反映概率,通常这些权重会进行softmax归一化(或其他方法),使得它们的总和为1。通过这种方式,x1,x2,x3,x4 实际上表示了从四个操作中选择一个的概率。
例如,经过softmax之后,得到:
然后你就可以通过概率 p1,p2,p3,p4 来加权选择每个操作。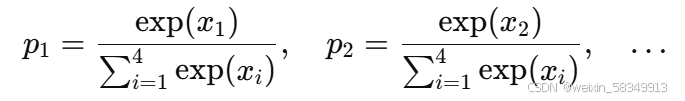
-
加权组合操作:在前向传播中,使用加权平均的方式将这些操作“软选择”出来。假设你希望选择一个卷积层,但不一定选择一个完全的卷积核,而是选择一个加权的组合。通过softmax后得到的权重可以让每个操作根据权重进行加权组合。例如,某一层的输出可以表示为:
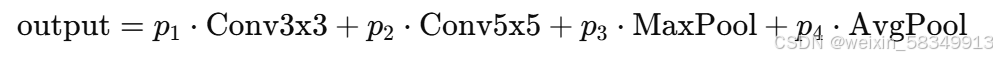
3.2 通过梯度下降进行优化
在训练过程中,我们通过反向传播来计算梯度,并通过梯度下降来优化这些连续的权重 x1,x2,x3,x4,使得最终网络的表现最优。这意味着你不再需要训练每个架构的离散选择,而是通过学习权重(概率)来直接选择最适合的操作。
更具体的例子:DARTS(Differentiable Architecture Search)
在 DARTS(Differentiable Architecture Search) 方法中,连续松弛技术的实现非常经典。DARTS 是一种 可微分架构搜索(Differentiable NAS) 方法,它将架构搜索问题转化为一个连续优化问题。
DARTS的核心步骤:
-
定义操作空间:假设你有多个操作(如不同大小的卷积、池化等),DARTS会为每个操作定义一个连续变量(通常是一个权重)。
-
松弛操作选择:每个操作的选择变为一个概率分布,通过softmax来实现。在训练过程中,网络会基于这个连续变量选择不同的操作。所有的操作都是软选择的,也就是不是完全选择某一个操作,而是根据概率进行加权选择。
-
优化架构参数和模型参数:DARTS 会同时优化两类参数:
- 架构参数(连续变量):表示每个操作的权重,最终决定架构的选择。
- 模型参数(权重):代表具体的网络权重,通过梯度下降进行优化。
-
网络架构和参数共享:在搜索过程中,通过共享网络参数和梯度计算,DARTS 可以高效地进行架构搜索。这样,整个架构搜索过程和传统的神经网络训练过程非常相似,只是多了一些控制操作选择的连续变量。
-
最终架构:在搜索结束后,DARTS 会选择那些权重较大的操作,构建出最终的架构。
5. 总结
通过连续松弛,我们可以将神经架构搜索中的离散选择问题转化为一个连续优化问题。这意味着:
- 我们不再需要离散地选择每个操作,而是通过连续变量(如权重或概率)加权选择不同的操作。
- 训练过程中,这些连续变量通过梯度下降进行优化,而不需要遍历所有可能的架构。
这种方法的优势是可以利用现有的高效优化算法(如梯度下降)来优化架构,从而大大提高搜索效率,尤其是在大规模的网络架构搜索中。
5. 连续松弛的优点
-
计算效率高:通过将离散问题转化为连续优化问题,连续松弛能够利用高效的优化算法(如梯度下降)来进行架构搜索,从而大大减少了计算成本。
-
优化算法简化:连续松弛使得架构搜索过程可以采用标准的优化方法(如梯度下降、Adam等),避免了传统搜索方法(如强化学习、进化算法)中的复杂性和资源消耗。
-
搜索空间平滑:通过连续松弛,架构搜索问题的空间变得更加平滑,优化过程能够更容易地收敛到全局最优解或局部最优解。

















 573
573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









