






逻辑回归(Logistic Regression)属于概率型非线性回归,是一种广泛用于研究二分类(可扩展到多分类)问题的统计方法,流行病学研究中,经常需要分析二分类变量,如是否发病、新药是否有效、受试者是否死亡等。
一、基本概念
1、回归模型
设因变量Y为二值变量,取值为1(出现阳性结果,如发病)、0(出现阴性结果,如未发病),另外有影响Y取值的m个自变量X1,.......,Xm。
记P=P(Y=1 | X1,......,Xm),表示在m个自变量作用下阳性结果发生的概率。

(1)式左边为阳性和阴性结果发生概率之比的自然对数,成为P的logit变换,记为logit P。
2、参数意义
常数项B0表示暴露剂量为0时个体阳性与阴性之比的自然对数,回归系数Bj表示自变量Xj改变一个单位时logit P的改变量。
回归系数与优势比OR(odds ratio)关系如下:

若为某些罕见疾病,优势比OR可以作为相对危险度RR(relative risk)的近似估计。
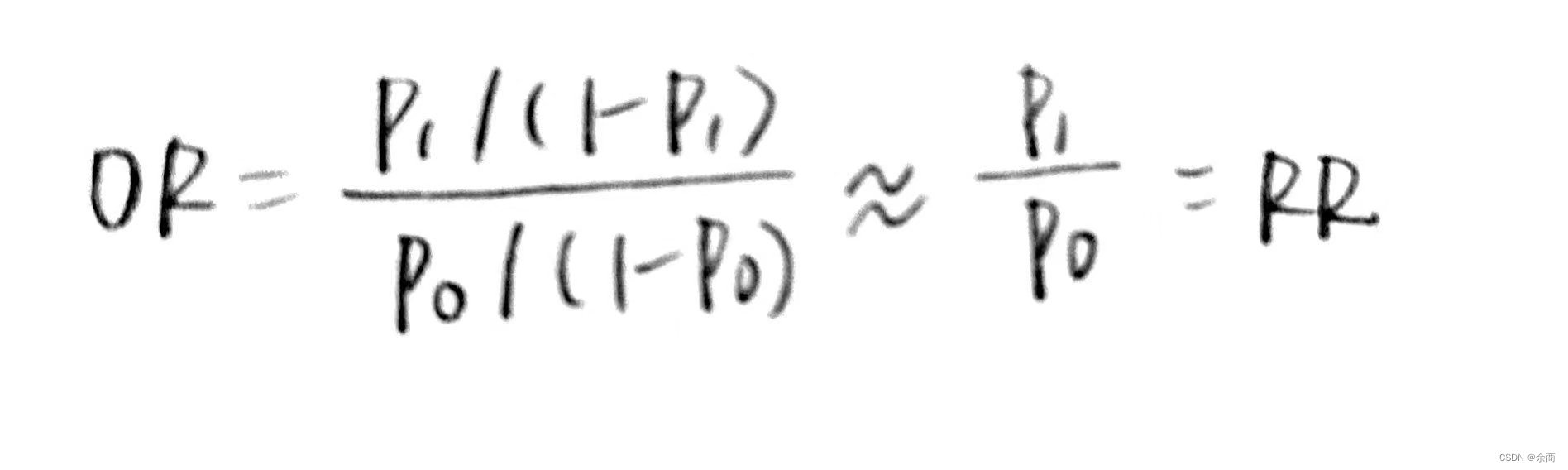

















 1484
1484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









