







正则表达式不属于任何一种语言,python java go php 都可以使用正则表达式。
正则表达式通过获取一些文本的特征,写出一个正确的表达式语法。
学习正则表达式之前,我们先认识一个正则表达式正确与否,在线验证工具。
https://regex101.com/ https://regex101.com/
https://regex101.com/
通过使用在线验证工具,正确匹配到需要获取的字符串。
正则表达式同样也是一个字符串,只是这些字符串符合正则表达式的语法,这些字符留有特殊的含义。
普通字符和特殊字符,特殊字符也可以称为元字符()
普通字符就是我们字节从直接文本中匹配我们需要的信息。
例如 : 我们是我们的孩子的我们的父亲的孩子。
让我们把匹配“我们”字符提取出来,这就是普通字符,理解起来比较简单
但是有些特殊字符,元字符(metacharacters),如:
. * + ? \ [ ] ^ $ { } | ( )
他们出现在正则表达式中,是为了表示特殊的含义,再也不是符号原来的意思
1、 . 字符:
.表示要匹配除了换行符之外的任何单个字符 (\n 换行符)
例如: 从下面文本中,选择出所有颜色
红色的苹果
橘色的橙子
黄色的香蕉
正则表达式的写法 ^.色 ^ 表示从头开始,. 匹配除了换行符的任意字符,色 是普通字符 。找出和相关的词语
python语法写法:
fuck = '''红色的苹果
橘色的橙子
黄色的香蕉
'''
import re
p = re.compile(r'^.色') # r 的意思是,不需要,python语言将该符号识别为python中字符的意思,只需要正确表达 正则表达式中该符号的意思即可
print(type(p))
for one in p.findall(fuck):
print(one)
* 号 表示匹配前面的子表达式任意次,包括0次
比如如下文本,选择逗号前面的水果名称包括逗号本身
苹果,红彤彤圆又圆
橙子,黄色的橙子黄橙橙
西瓜,绿油油甜又甜
,金灿灿热又热
正则表达式的写法: .*, . 表示除换行符外所有单个字符,* 表示重复匹配任意次,, 表示普通字符逗号的意思, .*, 意思保证最后一个字符是逗号,一段任意字符(将除去换行符的单个字符实现任意次)。
python语法:
fuck = '''苹果,红彤彤圆又圆
橙子,黄色的橙子黄橙橙
西瓜,绿油油甜又甜
,金灿灿大又圆
'''
import re
p = re.compile(r'.*,') # r 的意思是,不需要,python语言将该符号识别为python中字符的意思,只需要正确表达 正则表达式中该符号的意思即可
print(type(p))
for one in p.findall(fuck):
print(one)
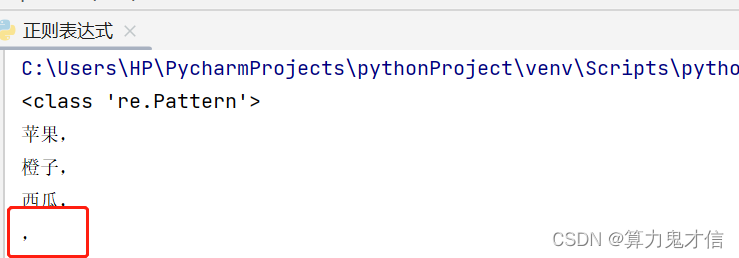
为什么把 ,(逗号) 也提取出来,因为 * 可以表示任意次,(0 ——N)。
+ 号 表示匹配前面的子表达式出现至少一次,不包括0 次
案例: + 和 * 的唯一区别是 + 号 至少要出现一次
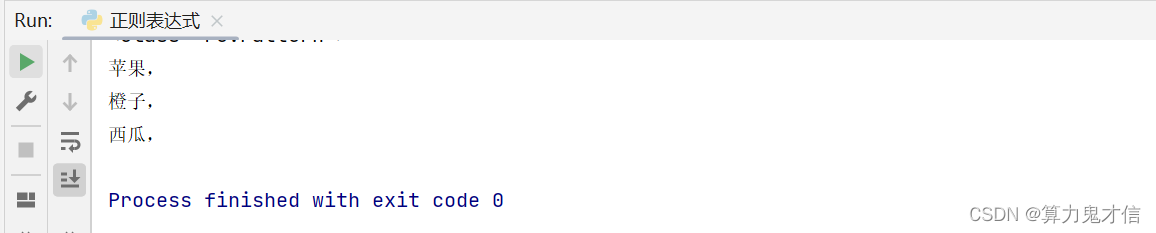
fuck = '''苹果,红彤彤圆又圆
橙子,黄色的橙子黄橙橙
西瓜,绿油油甜又甜
,金灿灿大又圆
'''
import re
p = re.compile(r'.+,') # r 的意思是,不需要,python语言将该符号识别为python中字符的意思,只需要正确表达 正则表达式中该符号的意思即可
print(type(p))
for one in p.findall(fuck):
print(one)
和 * 号相比,+ 缺少了最后一行, ' , ' 因为 + 要求前面的至少出现一个字符,“,金灿灿大又圆 ” 逗号前面啥都没有能提取出就不正常了。
{ } (花括号)表示前面的字符匹配,指定次数
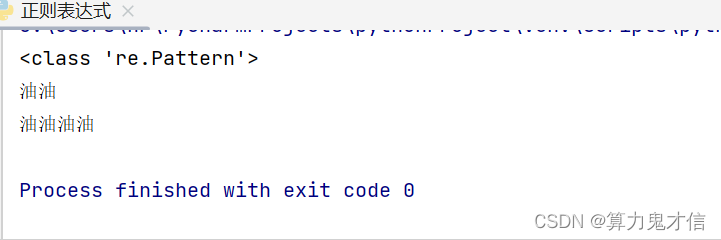
比如下面的文本:提取绿油油,汽油油油油 这两串字符
红彤彤,绿油油,黑乎乎,汽油油油油
正则表达式的语法: 油{2,4} ,{ } 表示匹配前面的字符出现指定次数,油,普通字符,在文本中找到油这个字符。油{2,4} 找到油至少出现2次,至多出现 4次,这串字符
python语法:
fuck = '''红彤彤,绿油油,黑乎乎,汽油油油油
'''
import re
p = re.compile(r'油{2,4}') # r 的意思是,不需要,python语言将该符号识别为python中字符的意思,只需要正确表达 正则表达式中该符号的意思即可
print(type(p))
for one in p.findall(fuck):
print(one)
贪婪模式:
在正则表达式中,使用 * + ? 都是贪婪地,使用它们时会尽可能多的匹配内容
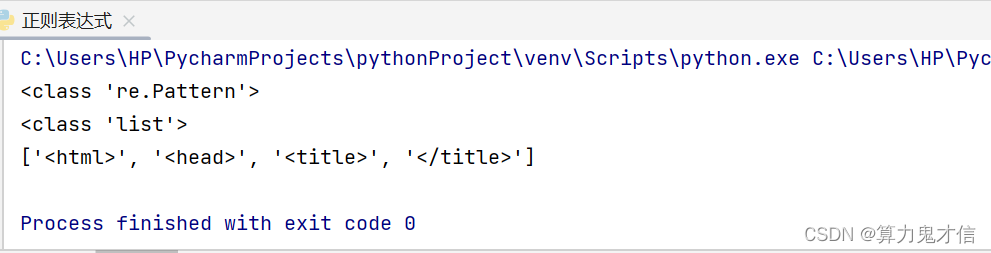
我们把下面的字符串中的所有html 标签都提取出来
source = '<html><head><title>Title</title>'
得到这样一个列表: '[<html>' , '<head>' , '<title>' , '</title>']
按照常规用法来看 是不是需要用 一对尖括号 < >作为外围,在尖括号里面匹配任意多的字符。
正则表达式语法: <.*>
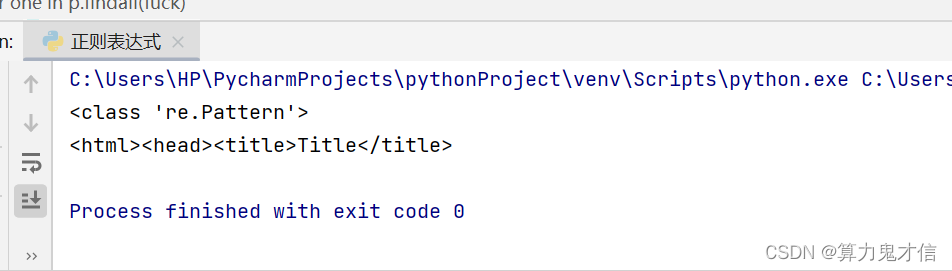
看结果显示不是我们想要的,这是因为,*是贪婪模式的作用符号,只要第一个符号是 “ < ”,最后一个符号是“ > ” 就算符合要求,< html><head><title > ,这也算符合我们书写正则表达式的要求,但是不符合我们题目的要求。
如何解决呢? 是贪婪模式,我们给正则表达式中的 * 号后面添加上 ? 号 就表示非贪婪模式,因为 * 可以表示任意多字符也可以表示任意少字符,加上 ? 号那就是任意少了。任意多那就是包括所有含有 一对尖括号的内容,任意少,包括一对尖括号就可以了。
fuck = '<html><head><title>Title</title>'
import re
p = re.compile(r'<.+?>') # r 的意思是,不需要,python语言将该符号识别为python中字符的意思,只需要正确表达 正则表达式中该符号的意思即可
print(type(p))
i = p.findall(fuck)
print(type(i))
print(i)
总结:(论语二则)
逝者如斯夫,不舍昼夜。
博学而笃志,切问而近思,仁其中矣。
广泛的追求知识,坚定自己的志向,勤恳的向他人追问知识,经常的思考问题。认得就体现在你的日常的行为中。

















 2011
2011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









