






一、Transformer是什么?
Transformer架构最初由谷歌研究人员于2017年在论文《注意力就是你所需要的一切》(“Attention Is All You Need”)中提出。这一架构的诞生标志着自然语言处理领域的一次重大突破,因为它彻底颠覆了传统的序列到序列学习模型的设计思路。在此之前,基于循环神经网络(RNN)的模型在机器翻译、语音识别等任务中占据主导地位,但RNN的串行处理方式使其计算效率低下,时间复杂度为O(n),且难以捕捉长距离依赖关系。
Transformer通过引入自注意力机制(Self-Attention),彻底改变了这一局面。它不再需要逐个处理序列中的元素,而是能够同时关注整个输入序列,从而实现了并行计算。这种设计将时间复杂度从O(n)降低到接近O(1),大幅提升了模型的训练和推理速度,同时显著增强了对长距离依赖关系的建模能力。自注意力机制的核心思想是通过计算序列中每个元素与其他元素的相关性,动态地捕捉全局上下文信息,从而实现高效的并行处理。

Transformer的提出不仅解决了RNN的计算瓶颈,还为深度学习模型的设计提供了全新的思路。它迅速成为自然语言处理领域的主流架构,并在计算机视觉、语音处理等多个领域展现出强大的适应性和扩展性。如今,Transformer已经成为现代人工智能技术的基石之一,推动了语言模型、多模态学习等领域的飞速发展,深刻改变了深度学习的研究与应用格局。
Transformer的整体架构是一种基于编码器-解码器(Encoder-Decoder)结构的模型,专为处理序列到序列(seq2seq)任务而设计,例如机器翻译、文本生成等。它的核心创新在于引入了自注意力机制(Self-Attention),使得模型能够并行处理整个输入序列,而不是像传统的循环神经网络(RNN)那样逐个处理序列元素。以下是Transformer的整体架构的详细描述:
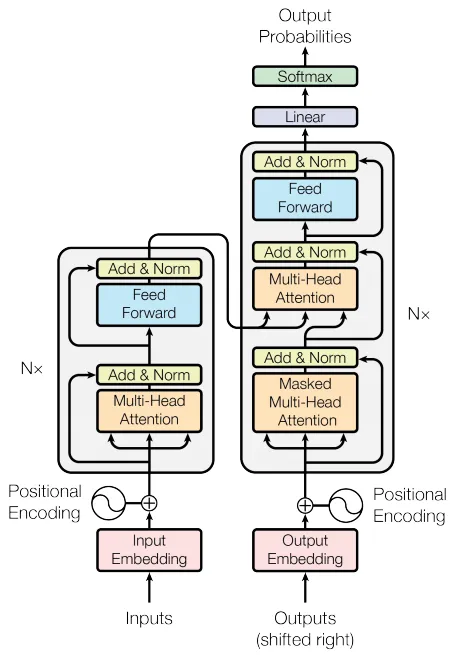
1、总体结构
Transformer由两部分组成:
- 编码器(Encoder):负责处理输入序列,并将其转换为上下文相关的表示。
- 解码器(Decoder):负责根据编码器的输出生成输出序列。
编码器和解码器都由多个相同的层(通常为6层)堆叠而成,每层包含不同的模块。
2、编码器(Encoder)
编码器由以下模块组成:
- 输入嵌入(Input Embedding):
- 将输入序列中的每个词或符号映射到固定维度的向量(词嵌入)。
- 通常会加上位置编码(Positional Encoding),以保留序列中元素的顺序信息。
- 多头自注意力机制(Multi-Head Self-Attention):
- 这是Transformer的核心模块,用于捕捉输入序列中元素之间的全局依赖关系。
- 通过将输入向量分解为多个“头”(head),模型可以并行计算不同子空间的注意力,从而增强表达能力。
- 前馈神经网络(Feed-Forward Network):
- 每个编码器层包含一个全连接的前馈神经网络,用于进一步处理自注意力机制的输出。
- 网络的结构是相同的,但参数独立。
- 残差连接与归一化(Residual Connections & Layer Normalization):
- 每个模块(自注意力和前馈网络)的输出都会与输入相加(残差连接),然后通过层归一化(LayerNorm)进行稳定化。
3、解码器(Decoder)
解码器的结构与编码器类似,但增加了以下模块:
- 掩码多头自注意力(Masked Multi-Head Self-Attention):
- 与编码器的自注意力机制类似,但会引入掩码(masking),以确保在生成输出序列时,每个位置的预测只能依赖于前面的词,而不能看到未来的词。
- 编码器-解码器注意力(Encoder-Decoder Attention):
- 这一模块允许解码器从编码器的输出中获取上下文信息,从而更好地生成输出序列。
- 前馈神经网络(Feed-Forward Network):
- 与编码器中的前馈网络结构相同,用于进一步处理注意力机制的输出。
- 输出层(Output Layer):
- 解码器的最后一层是一个线性层,将模型的输出映射到目标词汇表的大小,并通过Softmax计算每个词的概率分布。
4、位置编码(Positional Encoding)
由于Transformer不依赖于RNN的顺序处理,它需要一种方法来保留输入序列中元素的顺序信息。位置编码通过将位置信息嵌入到输入向量中,使得模型能够感知序列的顺序。位置编码可以是固定的(如正弦函数)或通过学习得到。
5、并行化优势
Transformer的一个显著特点是它的并行化能力。由于自注意力机制可以同时处理整个输入序列,模型的训练和推理速度远快于基于RNN的模型。这种并行化能力使得Transformer在大规模数据集上的表现尤为突出。
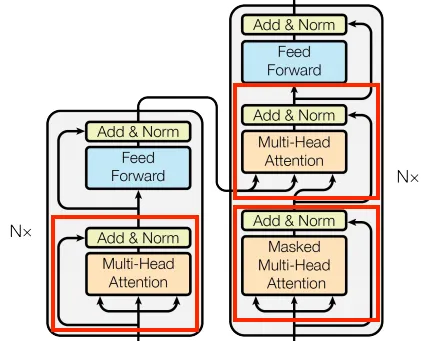
二、多头注意力机制
我们将要实现的第一个块实际上是 Transformer 中最重要的部分,称为多头注意力。让我们看看它在整体架构中的位置。
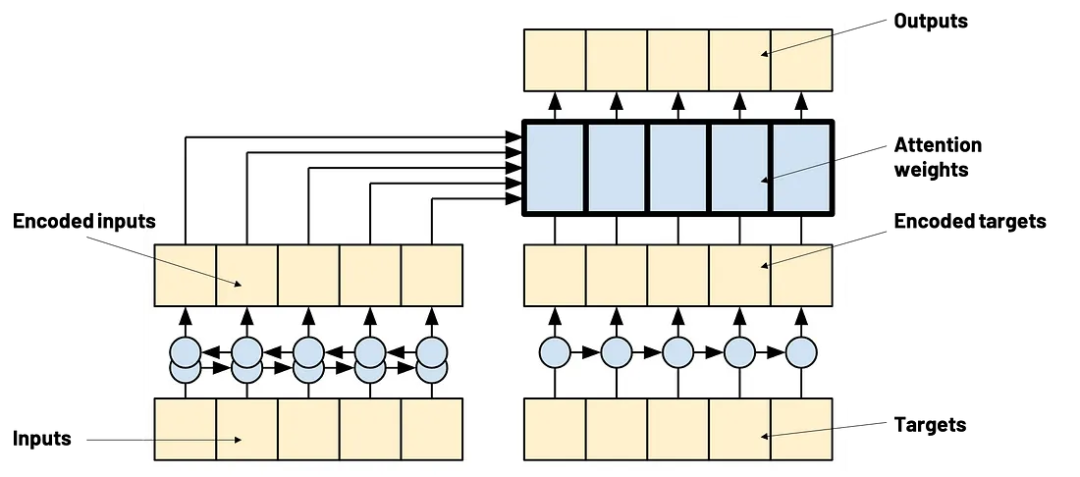
Attention 实际上并不是 Transformer 特有的机制,它已经在 RNN 序列到序列模型中使用。
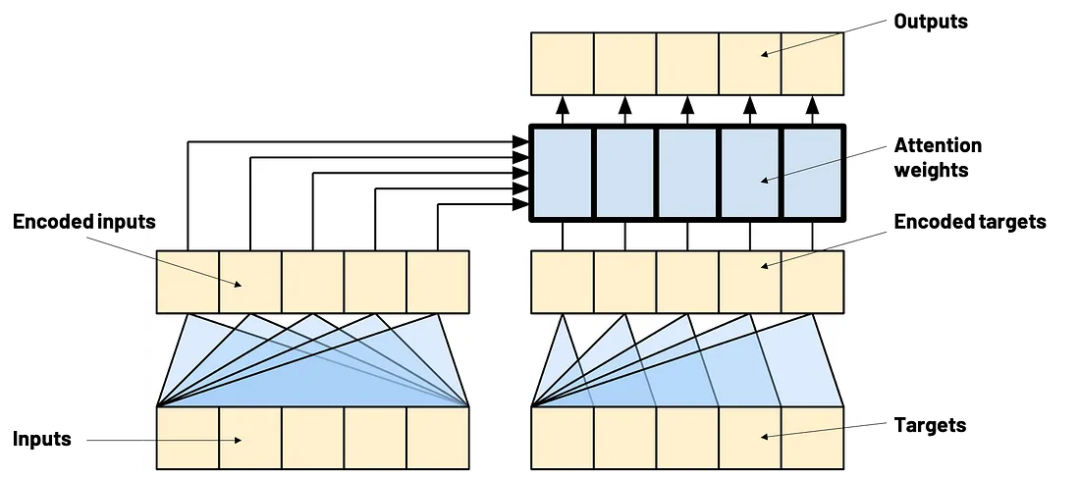 Transformer 中的注意力机制
Transformer 中的注意力机制
import torch
import torch.nn as nn
import math
class MultiHeadAttention(nn.Module):
def __init__(self, hidden_dim=256, num_heads=4):
"""
input_dim: Dimensionality of the input.
num_heads: The number of attention heads to split the input into.
"""
super(MultiHeadAttention, self).__init__()
self.hidden_dim = hidden_dim
self.num_heads = num_heads
assert hidden_dim % num_heads == 0, "Hidden dim must be divisible by num heads"
self.Wv = nn.Linear(hidden_dim, hidden_dim, bias=False) # the Value part
self.Wk = nn.Linear(hidden_dim, hidden_dim, bias=False) # the Key part
self.Wq = nn.Linear(hidden_dim, hidden_dim, bias=False) # the Query part
self.Wo = nn.Linear(hidden_dim, hidden_dim, bias=False) # the output layer
def check_sdpa_inputs(self, x):
assert x.size(1) == self.num_heads, f"Expected size of x to be ({-1, self.num_heads, -1, self.hidden_dim // self.num_heads}), got {x.size()}"
assert x.size(3) == self.hidden_dim // self.num_heads
def scaled_dot_product_attention(
self,
query,
key,
value,
attention_mask=None,
key_padding_mask=None):
"""
query : tensor of shape (batch_size, num_heads, query_sequence_length, hidden_dim//num_heads)
key : tensor of shape (batch_size, num_heads, key_sequence_length, hidden_dim//num_heads)
value : tensor of shape (batch_size, num_heads, key_sequence_length, hidden_dim//num_heads)
attention_mask : tensor of shape (query_sequence_length, key_sequence_length)
key_padding_mask : tensor of shape (sequence_length, key_sequence_length)
"""
self.check_sdpa_inputs(query)
self.check_sdpa_inputs(key)
self.check_sdpa_inputs(value)
d_k = query.size(-1)
tgt_len, src_len = query.size(-2), key.size(-2)
# logits = (B, H, tgt_len, E) * (B, H, E, src_len) = (B, H, tgt_len, src_len)
logits = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# Attention mask here
if attention_mask is not None:
if attention_mask.dim() == 2:
assert attention_mask.size() == (tgt_len, src_len)
attention_mask = attention_mask.unsqueeze(0)
logits = logits + attention_mask
else:
raise ValueError(f"Attention mask size {attention_mask.size()}")
# Key mask here
if key_padding_mask is not None:
key_padding_mask = key_padding_mask.unsqueeze(1).unsqueeze(2) # Broadcast over batch size, num heads
logits = logits + key_padding_mask
attention = torch.softmax(logits, dim=-1)
output = torch.matmul(attention, value) # (batch_size, num_heads, sequence_length, hidden_dim)
return output, attention
def split_into_heads(self, x, num_heads):
batch_size, seq_length, hidden_dim = x.size()
x = x.view(batch_size, seq_length, num_heads, hidden_dim // num_heads)
return x.transpose(1, 2) # Final dim will be (batch_size, num_heads, seq_length, , hidden_dim // num_heads)
def combine_heads(self, x):
batch_size, num_heads, seq_length, head_hidden_dim = x.size()
return x.transpose(1, 2).contiguous().view(batch_size, seq_length, num_heads * head_hidden_dim)
def forward(
self,
q,
k,
v,
attention_mask=None,
key_padding_mask=None):
"""
q : tensor of shape (batch_size, query_sequence_length, hidden_dim)
k : tensor of shape (batch_size, key_sequence_length, hidden_dim)
v : tensor of shape (batch_size, key_sequence_length, hidden_dim)
attention_mask : tensor of shape (query_sequence_length, key_sequence_length)
key_padding_mask : tensor of shape (sequence_length, key_sequence_length)
"""
q = self.Wq(q)
k = self.Wk(k)
v = self.Wv(v)
q = self.split_into_heads(q, self.num_heads)
k = self.split_into_heads(k, self.num_heads)
v = self.split_into_heads(v, self.num_heads)
# attn_values, attn_weights = self.multihead_attn(q, k, v, attn_mask=attention_mask)
attn_values, attn_weights = self.scaled_dot_product_attention(
query=q,
key=k,
value=v,
attention_mask=attention_mask,
key_padding_mask=key_padding_mask,
)
grouped = self.combine_heads(attn_values)
output = self.Wo(grouped)
self.attention_weigths = attn_weights
return output
我们需要解释几个概念:
1. 查询(Query)、键(Key)和值(Value)
想象一下,这就像使用一个Python字典:当你查询的键不在字典中时,字典不会返回任何结果。但如果我们希望字典能够返回与查询“接近”的信息,而不是完全匹配的结果呢?
例如,假设我们有这样的场景:
-
如果查询与键不完全匹配,我们是否可以返回一个“接近”的结果?
-
或者,是否可以返回多个值的“混合”信息,而不是单一的精确匹配?
-
查询(Query):是你试图查找的信息。
-
键(Key)和值(Value):是存储的数据。
这种机制正是**注意力机制(Attention Mechanism)**的核心思想:通过计算查询与键之间的相似性,动态地从值中提取相关信息,而不需要完全匹配。
d = {"panther": 1, "bear": 10, "dog":3}
d["wolf"] = 0.2*d["panther"] + 0.7*d["dog"] + 0.1*d["bear"]
这段代码的核心在于计算查询(query)与键(keys)之间的注意力权重,这些权重决定了哪些部分的信息对回答查询更重要。通过这种方式,模型可以动态地从数据中提取相关信息,而不需要逐个检查所有部分。
logits = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k) # we compute the weights of attention
注意力机制的核心在于通过计算查询(query)与键(keys)之间的相似性,生成注意力权重,然后将这些权重应用于值(values),以提取与查询最相关的信息。
attention = torch.softmax(logits, dim=-1)
output = torch.matmul(attention, value) # (batch_size, num_heads, sequence_length, hidden_dim)
2. 注意力掩码与填充(Attention Masking and Padding)
在处理序列输入时,我们希望注意力机制能够专注于相关的信息,而忽略无用或禁止的信息。
1. 无用信息(Padding)
无用信息的一个典型例子是填充(padding)。为了对齐一个批次中所有序列的长度,我们通常会使用填充符号(如``)将较短的序列扩展到与最长序列相同的长度。然而,这些填充符号并不包含任何有意义的信息,因此模型在计算注意力时需要忽略它们。
为了实现这一点,我们通常会引入一个填充掩码(Padding Mask),将填充位置的注意力权重设置为零,从而确保模型不会关注这些无用信息。填充掩码的具体实现会在最后一节中详细讨论。
2. 禁止信息(Forbidden Information)
禁止信息的处理稍微复杂一些。在训练过程中,模型需要学习如何将输入序列编码为上下文表示,并将目标序列与输入对齐。然而,在推理阶段(如文本生成任务中),模型需要根据之前生成的词来预测下一个词,而不能看到未来的词。
为了模拟这种推理过程,我们在训练时也需要对模型施加相同的限制。具体来说,我们会使用一个因果掩码(Causal Mask),确保在每个时间步中,目标序列只能访问过去的信息(即之前的时间步),而不能访问未来的信息(即之后的时间步)。
if attention_mask is not None:
if attention_mask.dim() == 2:
assert attention_mask.size() == (tgt_len, src_len)
attention_mask = attention_mask.unsqueeze(0)
logits = logits + attention_mask
三、位置编码
它对应Transformer的如下部分:
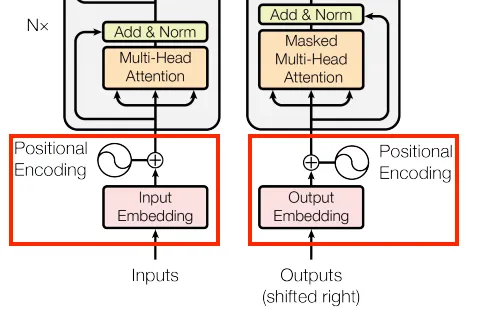
在接收和处理输入时,Transformer 没有顺序感,因为它将序列视为一个整体,这与 RNN 的做法相反。因此,我们需要添加一点时间顺序,以便 Transformer 能够学习依赖关系。
# Taken from https://pytorch.org/tutorials/beginner/transformer_tutorial.html#define-the-model
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
"""
Arguments:
x: Tensor, shape ``[batch_size, seq_len, embedding_dim]``
"""
x = x + self.pe[:, :x.size(1), :]
return x
四、编码器
编码器是 Transformer 的左侧部分。
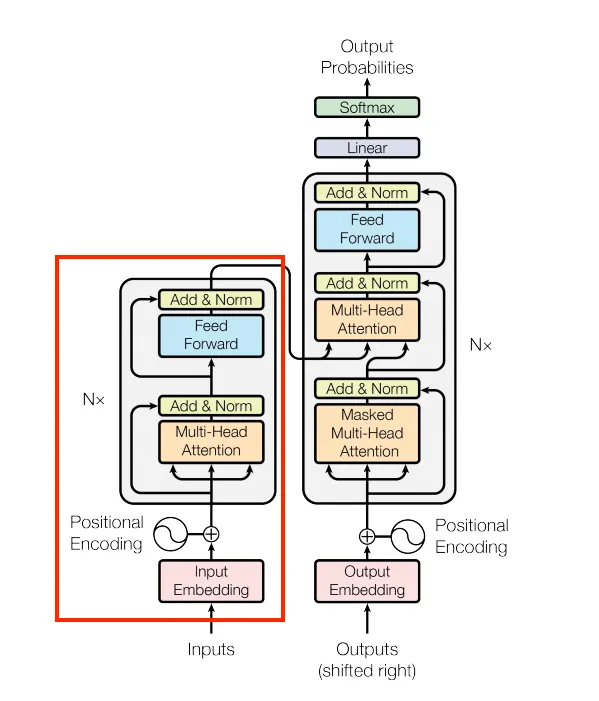
先在代码中添加一小部分,即前馈部分:
class PositionWiseFeedForward(nn.Module):
def __init__(self, d_model: int, d_ff: int):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))
将各个部分组合在一起,得到了一个编码器模块!
class EncoderBlock(nn.Module):
def __init__(self, n_dim: int, dropout: float, n_heads: int):
super(EncoderBlock, self).__init__()
self.mha = MultiHeadAttention(hidden_dim=n_dim, num_heads=n_heads)
self.norm1 = nn.LayerNorm(n_dim)
self.ff = PositionWiseFeedForward(n_dim, n_dim)
self.norm2 = nn.LayerNorm(n_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x, src_padding_mask=None):
assert x.ndim==3, "Expected input to be 3-dim, got {}".format(x.ndim)
att_output = self.mha(x, x, x, key_padding_mask=src_padding_mask)
x = x + self.dropout(self.norm1(att_output))
ff_output = self.ff(x)
output = x + self.norm2(ff_output)
return output
编码器实际上包含 N 个编码器块或层,以及用于输入的嵌入层。因此,通过添加嵌入、位置编码和编码器块来创建一个编码器:
class Encoder(nn.Module):
def __init__(
self,
vocab_size: int,
n_dim: int,
dropout: float,
n_encoder_blocks: int,
n_heads: int):
super(Encoder, self).__init__()
self.n_dim = n_dim
self.embedding = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=n_dim
)
self.positional_encoding = PositionalEncoding(
d_model=n_dim,
dropout=dropout
)
self.encoder_blocks = nn.ModuleList([
EncoderBlock(n_dim, dropout, n_heads) for _ in range(n_encoder_blocks)
])
def forward(self, x, padding_mask=None):
x = self.embedding(x) * math.sqrt(self.n_dim)
x = self.positional_encoding(x)
for block in self.encoder_blocks:
x = block(x=x, src_padding_mask=padding_mask)
return x
五、解码器
解码器部分是左边的部分。
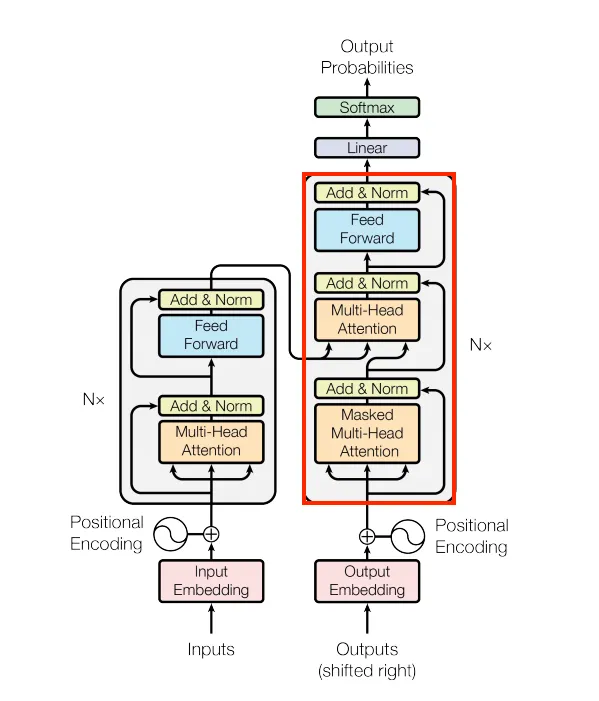
Masked Multi-Head Attention 是一种特殊的注意力机制,主要用于防止模型在训练或推理过程中访问未来的信息。这种机制在序列生成任务(如文本生成、机器翻译等)中尤为重要,因为它确保模型在生成每个词时只能依赖于之前的信息,而不是未来的上下文。
# Stuff before
self.self_attention = MultiHeadAttention(hidden_dim=n_dim, num_heads=n_heads)
masked_att_output = self.self_attention(
q=tgt,
k=tgt,
v=tgt,
attention_mask=tgt_mask, <-- HERE IS THE CAUSAL MASK
key_padding_mask=tgt_padding_mask)
# Stuff after
第二个注意力机制称为交叉注意力机制。它将使用解码器的查询来匹配编码器的键和值!注意:它们在训练期间可能具有不同的长度,因此通常最好明确定义输入的预期形状。
def scaled_dot_product_attention(
self,
query,
key,
value,
attention_mask=None,
key_padding_mask=None):
"""
query : tensor of shape (batch_size, num_heads, query_sequence_length, hidden_dim//num_heads)
key : tensor of shape (batch_size, num_heads, key_sequence_length, hidden_dim//num_heads)
value : tensor of shape (batch_size, num_heads, key_sequence_length, hidden_dim//num_heads)
attention_mask : tensor of shape (query_sequence_length, key_sequence_length)
key_padding_mask : tensor of shape (sequence_length, key_sequence_length)
"""
下面是我们将编码器的输出(称为内存)与解码器输入一起使用的部分:
# Stuff before
self.cross_attention = MultiHeadAttention(hidden_dim=n_dim, num_heads=n_heads)
cross_att_output = self.cross_attention(
q=x1,
k=memory,
v=memory,
attention_mask=None, <-- NO CAUSAL MASK HERE
key_padding_mask=memory_padding_mask) <-- WE NEED TO USE THE PADDING OF THE SOURCE
# Stuff after
把这些部分放在一起,最终得到了解码器:
class DecoderBlock(nn.Module):
def __init__(self, n_dim: int, dropout: float, n_heads: int):
super(DecoderBlock, self).__init__()
# The first Multi-Head Attention has a mask to avoid looking at the future
self.self_attention = MultiHeadAttention(hidden_dim=n_dim, num_heads=n_heads)
self.norm1 = nn.LayerNorm(n_dim)
# The second Multi-Head Attention will take inputs from the encoder as key/value inputs
self.cross_attention = MultiHeadAttention(hidden_dim=n_dim, num_heads=n_heads)
self.norm2 = nn.LayerNorm(n_dim)
self.ff = PositionWiseFeedForward(n_dim, n_dim)
self.norm3 = nn.LayerNorm(n_dim)
# self.dropout = nn.Dropout(dropout)
def forward(self, tgt, memory, tgt_mask=None, tgt_padding_mask=None, memory_padding_mask=None):
masked_att_output = self.self_attention(
q=tgt, k=tgt, v=tgt, attention_mask=tgt_mask, key_padding_mask=tgt_padding_mask)
x1 = tgt + self.norm1(masked_att_output)
cross_att_output = self.cross_attention(
q=x1, k=memory, v=memory, attention_mask=None, key_padding_mask=memory_padding_mask)
x2 = x1 + self.norm2(cross_att_output)
ff_output = self.ff(x2)
output = x2 + self.norm3(ff_output)
return output
class Decoder(nn.Module):
def __init__(
self,
vocab_size: int,
n_dim: int,
dropout: float,
n_decoder_blocks: int,
n_heads: int):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=n_dim,
padding_idx=0
)
self.positional_encoding = PositionalEncoding(
d_model=n_dim,
dropout=dropout
)
self.decoder_blocks = nn.ModuleList([
DecoderBlock(n_dim, dropout, n_heads) for _ in range(n_decoder_blocks)
])
def forward(self, tgt, memory, tgt_mask=None, tgt_padding_mask=None, memory_padding_mask=None):
x = self.embedding(tgt)
x = self.positional_encoding(x)
for block in self.decoder_blocks:
x = block(
x,
memory,
tgt_mask=tgt_mask,
tgt_padding_mask=tgt_padding_mask,
memory_padding_mask=memory_padding_mask)
return x
六、Padding 与 Masking
在多头注意力机制中,我们提到过在计算注意力时需要排除输入序列中的某些部分。这在处理不同长度的序列时尤为重要。
1. 序列对齐与填充(Padding)
在训练过程中,我们通常会将多个输入和目标序列组合成一个批次进行处理。然而,每个序列的长度可能各不相同。为了能够将它们作为一个批次处理,我们需要将所有序列对齐到最长序列的长度。这通常是通过添加一个特殊的填充符号(如PAD)来实现的。
例如,假设我们有一个批次包含四个单词:banana、watermelon、pear和blueberry。为了将它们作为一个批次处理,我们需要将所有单词的长度对齐到最长单词(watermelon)的长度。我们通过在较短的单词末尾添加PAD符号来实现这一点。
2. 填充掩码(Padding Mask)
在注意力计算中,我们希望模型忽略这些填充符号,因为它们不包含任何有意义的信息。为了实现这一点,我们使用一个填充掩码(Padding Mask),将填充位置的注意力权重设置为零。这样,模型在计算注意力时就不会关注这些无用的信息。
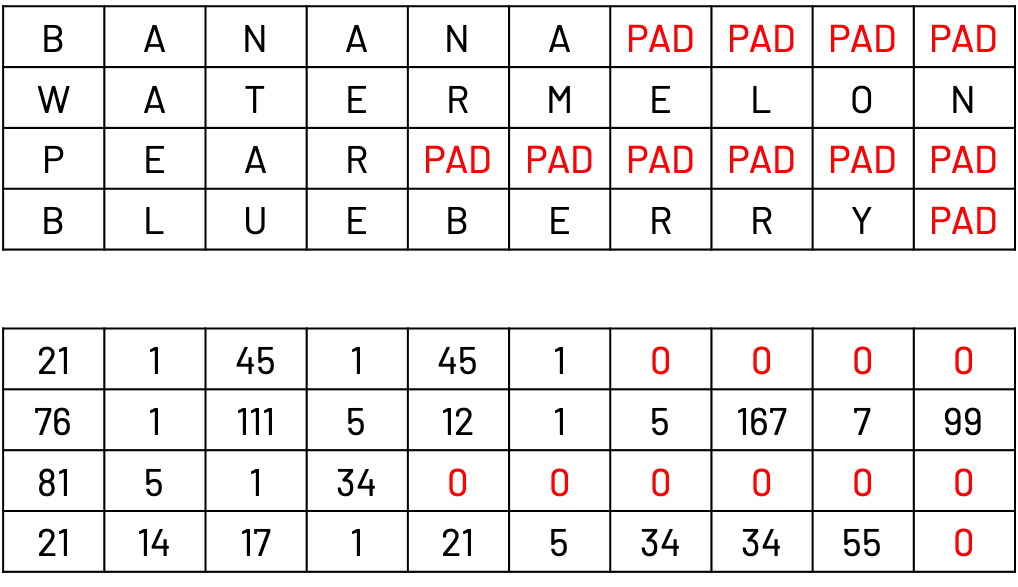
在上面的例子中,希望从正在计算的注意力权重中排除填充索引。因此,可以按如下方式计算源数据和目标数据的掩码:
padding_mask = (x == PAD_IDX)
那么因果掩码现在怎么样了?如果希望模型在每个时间步骤中只能关注过去的步骤,这意味着对于每个时间步骤 T,模型只能关注 1…T 中的每个步骤 t。这是一个双 for 循环,因此可以使用矩阵来计算:
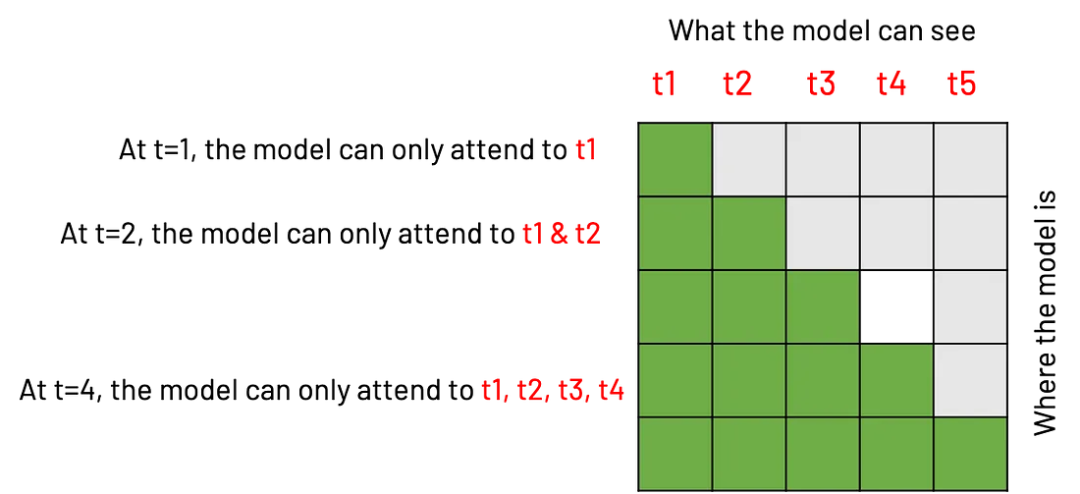
def generate_square_subsequent_mask ( size: int ):
"""生成一个三角形 (size, size) 掩码。来自 PyTorch 文档。"""
mask = ( 1 - torch.triu(torch.ones(size, size), diagonal= 1 )). bool ()
mask = mask. float ().masked_fill(mask == 0 , float ( '-inf' )).masked_fill(mask == 1 , float ( 0.0 ))
return mask
现在将各个部分组合在一起来构建我们的 Transformer!
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









