







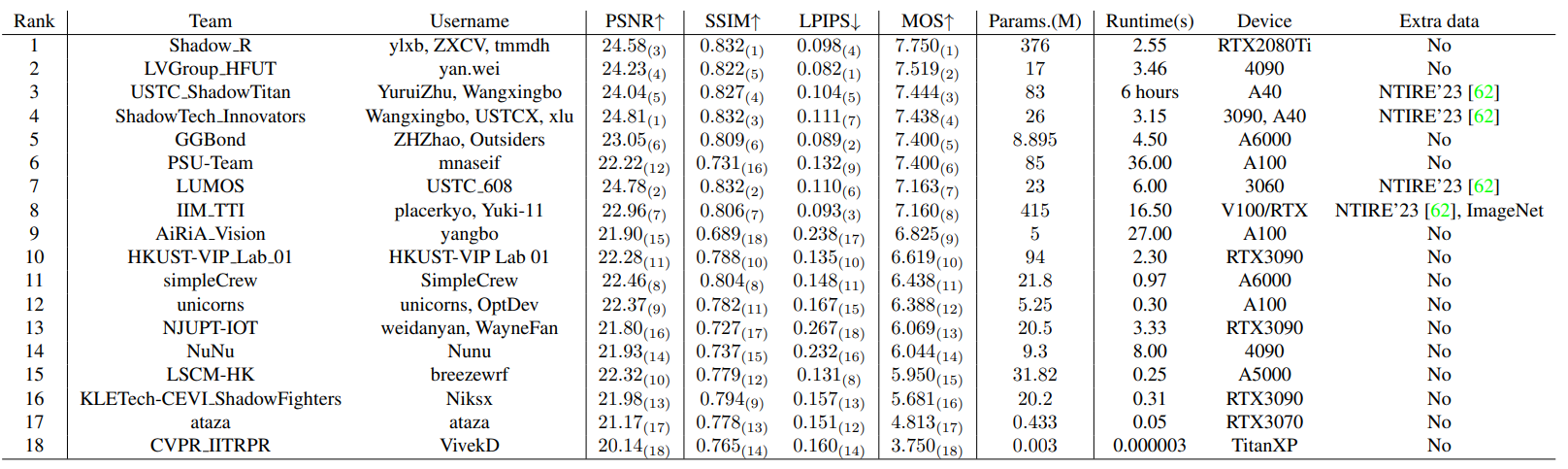
NTIRE 2024 Image Shadow Removal Challenge Report
NTIRE 2024图像阴影去除挑战赛报告
摘要
本文回顾了NTIRE 2024阴影去除挑战赛的成果。在去年赛事的基础上,本次挑战赛设置了两个赛道,一个赛道专注于高保真度重建,另一个则针对感知质量优异的解决方案进行单独排名。赛道1(保真度)有214名注册参与者,17支队伍进入决赛提交成果;赛道2(感知)有185名参与者,18支队伍在决赛阶段提交作品。两个赛道均基于WSRD数据集的数据,模拟了自阴影和投射阴影之间的相互作用,涵盖了种类繁多的物体、纹理和材质。改进后的图像对齐技术提高了重建的保真度,表现最佳的解决方案所恢复的图像与参考图像几乎难以区分。
一、引言
阴影去除在研究领域备受关注。阴影形成模型本质上描述的是一种非常复杂的现象。阴影的强度和形状由众多因素决定,首先是光源的属性,其次是遮挡光线从而产生阴影的物体的几何形状和特征,最后还取决于阴影投射表面的属性。这样一个复杂的系统需要深入研究,因此阴影去除和/或检测仍然是一个活跃的研究领域。
早期的研究自然是基于特定阴影形成模型的物理属性,这些模型通常适用于(通常是有限的)一组条件,在这些条件下测量能够成功进行。一类基于经典图像处理流程的阴影去除方法,旨在通过将未受阴影影响的图像区域的局部统计信息转移到受影响区域,来成功恢复无阴影图像。这是一种特别困难的策略,因为它涉及到阴影检测(这本身就是一个同样具有挑战性的问题)作为子任务。然而,基于受阴影影响区域定位信息的解决方案仍然是一种流行的设计选择,有各种算法都认可可靠的阴影检测掩模的重要性。
后来,硬件和软件开发的进步,以及大规模用于阴影去除和/或检测的图像数据库的引入,推动了深度学习解决方案的发展。这使得大量深度学习方法将阴影去除作为特定的图像恢复子任务来解决,这些方法在全监督训练框架下或使用弱监督、自监督设置进行开发。
最近,日益流行的扩散模型在各种图像阴影去除解决方案中成为骨干架构。自然地,这类新引入的方法在感知质量方面具有卓越性能,在当前已建立的基准测试(如ISTD、ISTD+或SRD)中代表了该领域的参考标准。
上述所有解决方案都代表了阴影去除领域的进步,但遗憾的是,所研究的阴影形成模型局限于数据层面所呈现的场景子集。虽然LRSS是一个包含各种软阴影的大型图像集合,但SRD和ISTD都聚焦于硬阴影,且针对的是简化场景。采集设置是将自然光作为唯一光源,并使用一个遮光物体。这个物体不会出现在采集的图像中,但它是在拍摄场景中产生阴影的物体。移除遮光物体后可采集到参考图像。将自然光作为唯一光源是为了在无阴影区域实现输入图像和参考图像之间(在一定程度上)的颜色一致性。文献提出了一种颜色校正方法,产生了(调整后的)ISTD+和SRD+数据集变体。这消除了同一图像对之间的颜色不一致性,但各种语义不一致性仍然存在。
然而,这种设置的主要限制在于阴影可投射的表面类型。这些表面必须是平坦的,以避免参考图像中出现任何自阴影。然而,自阴影是最常见的自然阴影类型,因此对于实际领域的应用(而非特定场景的原型)来说,研究自阴影至关重要。
为了解决这个问题,在WSRD中,基于柔光灯的实验室设置被用于采集图像,这些图像涵盖了粗糙表面和复杂几何形状产生的自阴影与外部投射阴影之间的相互作用,这些阴影是固定方向光所特有的。一组柔光灯用于实现近乎最佳的光照分布,在采集参考图像时尽量减少自阴影。最近,该设置得到了扩展,引入了多个方向光,从而打破了无阴影区域的颜色一致性。这将研究扩展到了更广泛的任务,引入了一个用于解决相关光照归一化问题的图像数据库。
二、WSRD+
NTIRE 2023图像阴影去除挑战赛中使用的WSRD数据在研究更复杂的阴影相互作用、更高复杂度的表面和内容方面向前迈进了一步。然而,该设置的一个组成部分是作为阴影投射表面的移动物体,这引入了一定的像素对齐不一致问题,从去年参赛队伍的反馈来看,这是一个具有挑战性的问题。
在本次赛事中,我们基于单应性估计步骤进行了初步的图像对齐,使输入图像和参考图像之间的PSNR提高了1.52dB,一致性得到增强。这使得参赛作品的质量有所提升,恢复图像的质量也有所改善,无论是在量化的重建保真度还是图像质量属性方面都有所体现。改进后的对齐方式让参赛队伍能够专注于阴影去除算法,而上一届的获胜队伍在高性能监督方案上投入了大量精力。
此外,考虑到用于验证的Codalab服务器的限制,我们从测试集中删除了25个样本,保留了最具挑战性的样本,同时没有改变所代表的场景、内容的分布,关键是也没有改变训练集中未见过的物体或表面的分布。最终提交的测试集包含75张图像,分辨率与WSRD 1中发布的一致。
本次挑战赛是NTIRE 2024研讨会相关挑战赛之一,其他挑战赛包括:密集和非均匀去雾、夜景摄影渲染、盲压缩图像增强、阴影去除、高效超分辨率、图像超分辨率(×4)、光场图像超分辨率、立体图像超分辨率、从镜面和透明表面图像获取高分辨率深度、包围曝光图像恢复和增强、人像质量评估、人工智能生成内容质量评估、野外任意图像恢复模型(RAIM)、RAW图像超分辨率、短视频用户生成内容(UGC)质量评估、低光增强以及RAW图像对齐和图像信号处理(ISP)挑战赛。
三、评估
本次挑战赛采用双赛道竞赛模式,两个赛道的排名标准不同。以下是我们列出的所有评估标准:
- 基于PSNR值的重建保真度;
- 结构相似性指数(SSIM)得分;
- 恢复图像与真实图像之间的LPIPS距离。我们使用在ImageNet上预训练的AlexNet进行LPIPS特征提取;
- 提交预测结果的平均意见得分(MOS);
- 基于各参赛队伍报告的参数数量的效率指标。
对于保真度赛道,我们对前三个标准给予同等权重。第五个标准仅用于区分性能相似的解决方案,更倾向于复杂度较低的方法。对于感知赛道,主要评估指标是平均意见得分(MOS),这是在决赛阶段截止后进行的用户研究的结果。
四、挑战赛阶段
- 开发阶段:在这个阶段,参与者可以获取任务描述以及一组1000对图像,用于训练他们的模型;
- 验证阶段:为了验证解决方案,参与者会收到来自WSRD+验证集的100张图像作为输入图像。真实图像不会公开,但会搭建一个Codalab验证服务器,将每个用户上传的提交图像与私有参考图像进行比较;
- 决赛阶段:一组75张来自WSRD+测试集的输入图像会发送给挑战赛参与者。他们可以使用Codalab服务器验证解决方案。每个用户的提交次数有限,以限制对测试集的微调。最后,会提供一个提交模板,包含最终提交准备的说明,每个队伍需要提供方法描述、相应代码、团队成员及其所属机构的信息,以及一组与测试集输入对应的75张恢复图像。
五、用户研究
挑战赛感知赛道提交解决方案的主要排名标准是平均意见得分(MOS)。这是通过用户研究确定的,参与研究的成像专家包括专业摄影师。评分系统设定输入图像对应等级为3。等级1和2用于算法使输入图像质量下降且在阴影处理方面没有改进的情况。对于在输出恢复图像方面表现成功的算法,使用3-10的分数范围,以0.5为增量。
用户研究是在WSRD+测试集中具有挑战性的样本子集上进行的,子集中样本的索引i满足 i ∈ 2 , 4 , 11 , 14 , 38 , 39 , 53 , 54 , 57 , 69 i \in{2,4,11,14,38,39,53,54,57,69} i∈2,4,11,14,38,39,53,54,57,69(测试集样本从0开始索引)。选择这些分析图像是考虑到阴影场景的复杂性,其内容在训练过程中既有见过的也有未见过的。
六、挑战赛结果
挑战赛结束时,赛道1有17份有效提交,赛道2有18份提交。有三个团队(IIM TTI、AiRiA Vision和NuNu)专门针对感知质量优化了他们的解决方案,仅参加了第二个赛道。第7节提供了两个赛道决赛阶段排名中每个解决方案的详细信息。
赛道1(保真度)提交结果在重建保真度和量化的感知质量方面都达到了较高水平,视觉比较结果也支持所提供的评估。赛道2的排名主要基于用户研究结果,前六个解决方案产生的结果在MOS上相似,两个赛道的顶尖团队提交的解决方案都具有较低程度的重影伪影,能够正确恢复颜色和纹理,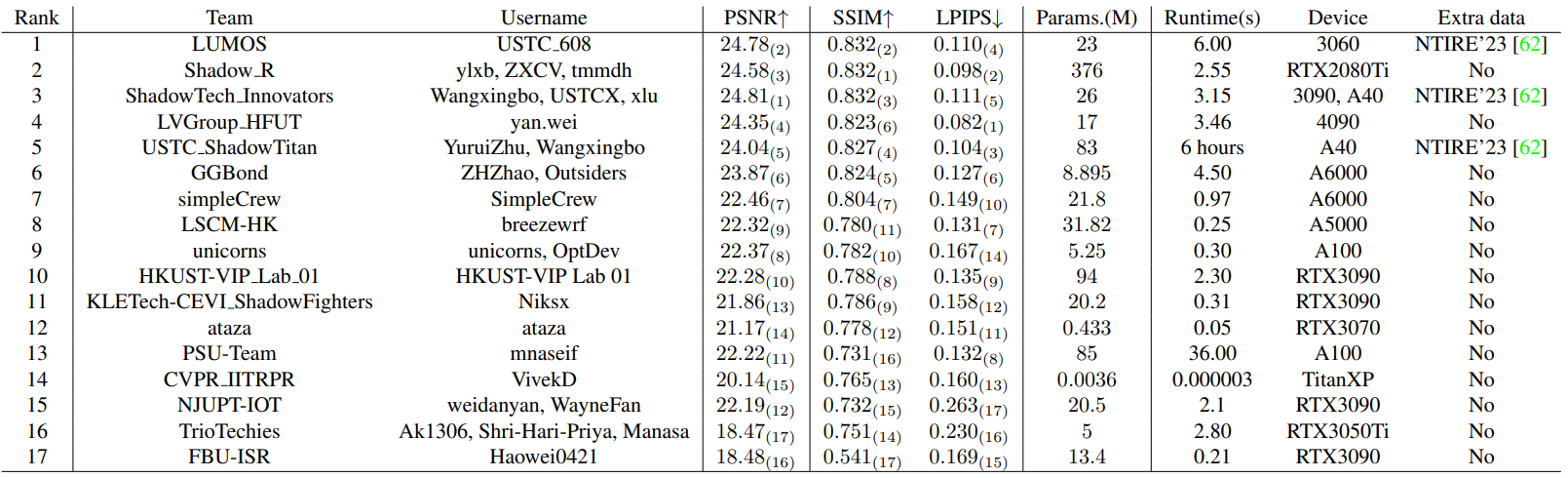
并且能够很好地处理WSRD+测试集中最复杂的阴影场景。


七、挑战赛方法
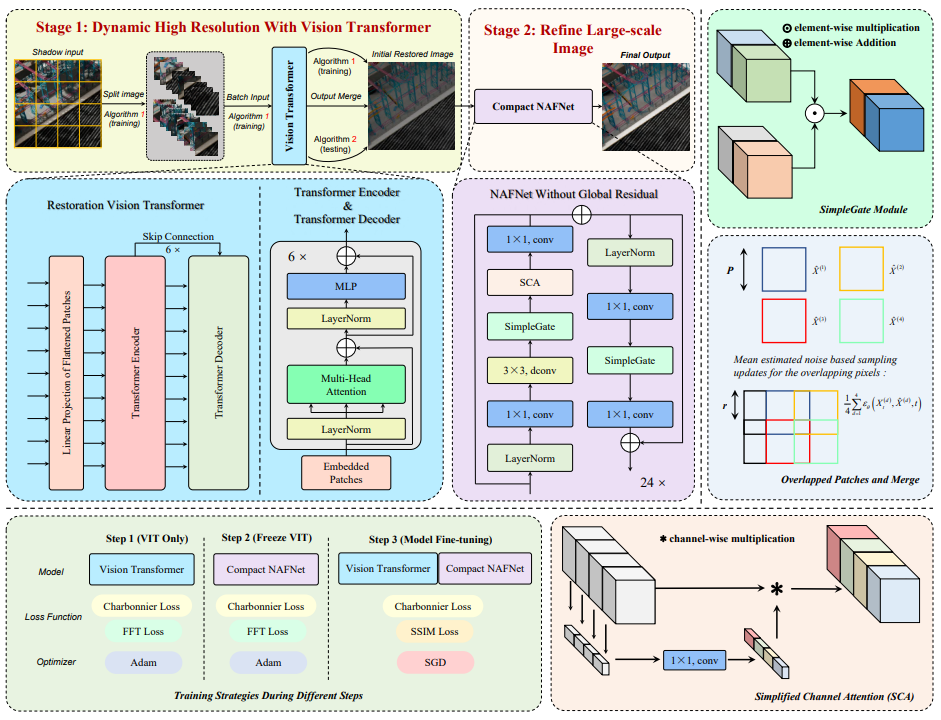
7.1 LUMOS
LUMOS团队提出了一种新颖的两阶段方法,称为HirFormer(用于大规模图像阴影去除的动态高分辨率Transformer),以提高高分辨率阴影图像的恢复质量。由于Transformer在建模长序列方面具有强大的上下文信息提取能力,他们采用与文献一致的视觉Transformer框架,来实现针对不均匀分布阴影去除任务的图像恢复。对于本次竞赛中的高分辨率图像,他们提出了一种动态高分辨率方法,以帮助Transformer有效地处理2K大小的大图像。为了解决单阶段网络在处理暗阴影时性能不佳的问题,他们从文献中的粗到细图像恢复概念中获得灵感,引入了使用NAFNet网络对恢复图像进行细化的步骤,这有助于消除Transformer模块效应导致的不良情况。具体的建模细节可参考相关图示。
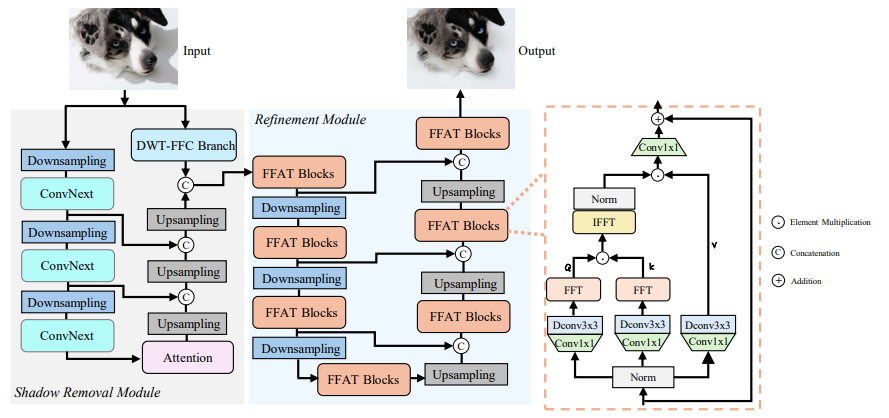
7.2 Shadow R
Shadow R团队提出了一种新颖的无掩模阴影去除和细化(ShadowRefiner)模型来处理阴影去除任务。整体框架包含阴影去除模块和细化模块。阴影去除模块旨在通过空间和频率表示学习从输入图像中去除阴影,该团队设计了一种基于ConvNext的U-Net架构,在每个分辨率上都使用7×7的深度卷积,并采用了频率分支网络,使其能够同时利用光谱和空间信息进行受阴影影响和无阴影图像的映射。
由于阴影去除模块的结果在细节和局部一致性方面与原始干净图像存在像素错位问题,该团队引入了一个基于Transformer的增强和细化模块。在细化模块中,编码器会分层降低输入图像的空间尺寸并扩展通道容量,生成潜在特征,解码器则以这些潜在特征为输入逐步恢复图像。在每个分辨率上,编码器和解码器都融入了几个基于快速傅里叶注意力(FFA)的Transformer(FFAT)块,FFA是该团队设计的一种不同于传统Transformer注意力操作的新机制。
7.3 ShadowTech Innovators
ShadowTech Innovators团队提出的阴影去除网络主要由门控线性单元、SimpleGate和简化通道注意力等模块组成,这些模块的设计灵感来源于相关参考文献。这些复杂组件的集成形成了一个强大的基线模型,能够有效地处理高分辨率阴影去除任务。
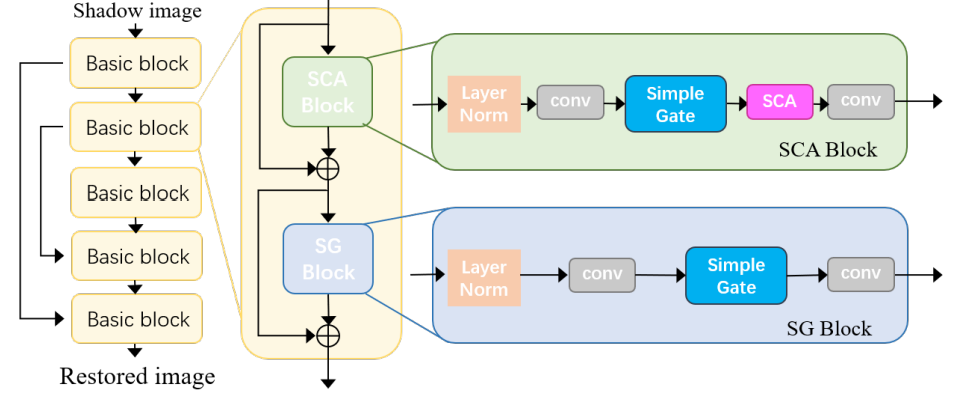
7.4 LVGroup HFUT
阴影去除是指从数字图像或视频中检测并消除阴影,同时保留受阴影影响区域的原始纹理和颜色的过程。然而,阴影去除结果通常包含严重的边界伪影和残留的阴影图案,这可能是由于缺乏强大的感知约束。因此,该团队选择具有LPIPS感知约束的NAFNet作为网络架构。
输入图像会经过训练和推理两个阶段的处理。在训练阶段,输入图像被输入到NAFNet网络中,并使用三个损失函数进行约束:权重为0.5的LPIPS损失 L L P I P S L_{LPIPS} LLPIPS、权重为0.1的FFT损失 L F F T L_{FFT} LFFT和权重为1的L1损失 L 1 L_{1} L1,总损失函数为:
L t o t a l = 0.5 L L P I P S + 0.1 L F F T + L 1 L_{total}=0.5L_{LPIPS}+0.1L_{FFT}+L_{1} Ltotal=0.5LLPIPS+0.1LFFT+L1
在推理阶段,首先将训练阶段获得的n个等间隔的检查点进行组合,然后输入图像依次通过这些检查点,得到n个输出。最后,使用最大集成方法处理这些输出,得到最终结果。
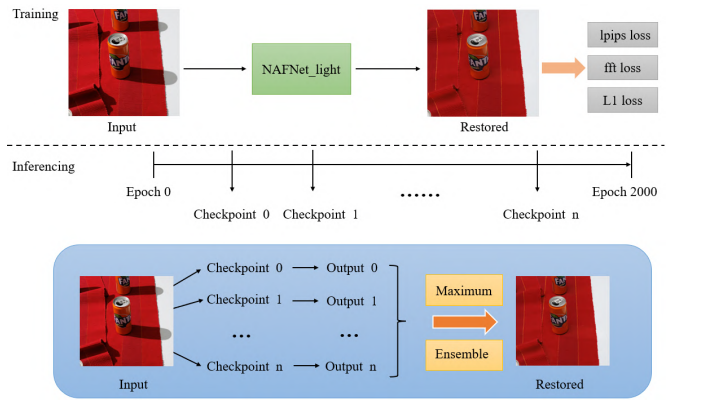
该团队还面临确定模型拟合良好的大致训练轮次,并据此确定等间隔检查点的问题。他们使用用户研究工具比较早期模型的性能,确定模型刚好拟合的时间点P,并在此基础上确定从时间点P到训练结束之间的等间隔检查点。整个架构基于PyTorch 2.2.1和具有24G内存的NVIDIA 4090进行搭建。该团队设置训练轮次为2000次,批次大小为6,使用AdamW优化器( β 1 = 0.9 \beta_{1}=0.9 β1=0.9, β 2 = 0.999 \beta_{2}=0.999 β2=0.999)进行优化,初始学习率设置为0.001,并使用余弦退火调整学习率。在数据增强方面,会随机裁剪图像至512×512大小,然后以0.5的概率进行水平翻转。对于保真度赛道,在最大集成方法中使用训练阶段的10个等间隔检查点;对于感知赛道,检查点数量翻倍至20个。
7.5 USTC ShadowTitan
USTC ShadowTitan团队提出的方法采用两阶段策略进行阴影去除,该策略注重GPU的内存效率和大图像分辨率处理。首先,应用传统的恢复模型(NAFNet)进行初步的阴影去除。随后,利用WeatherDiffusion对结果进行细化,同时解决内存约束问题并提高图像质量。这种方法使他们能够在优化内存使用和保持图像分辨率的同时,实现具有竞争力的阴影去除性能。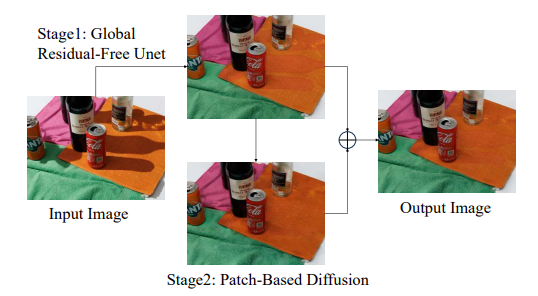
7.6 GGBond
GGBond团队提出的方法,对于给定的模糊图像 I ∈ R 3 × H × W I \in \mathbb{R}^{3 ×H ×W} I∈R3×H×W,首先使用卷积作为特征提取模块,从图像中提取浅层特征 F 0 ∈ R C × H × W F_{0} \in \mathbb{R}^{C ×H ×W} F0∈RC×H×W,其中H和W表示空间分辨率,C表示通道数。然后,浅层特征被输入到一个基于编码器-解码器的网络中,以获得特征 F d ∈ R C × H × W F_{d} \in \mathbb{R}^{C ×H ×W} F
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











