






Jina CLIP v2:

Jina-CLIP-v2是一个全新的通用多语言多模态向量模型 ,该模型基于 jina-clip-v1 和 jina-embeddings-3 构建,实现了一些关键改进。
关于Jina-CLIP-v2的更多介绍点此可了解
模型特点
模型开源链接:https://huggingface.co/jinaai/jina-clip-v2
在它的开源链接的介绍中,我们可以得知,Jina-CLIP-v2的参数量很小,大约为0.9B,属于”小模型“,相较于其他大语言模型是比较小的,因此对显存要求不高,甚至在cpu上也可以跑起来。它的核心就是结合了两个编码器:文本编码器和图像编码器,各自对应的参数量和特点见下表:

这两个编码器经过联合训练,以创建图像和文本的对齐表示。
使用方法:
Huggingface上提供了几种使用方法的代码,包括通过API、通过Transformer、通过onnx等进行使用,并提供了相关代码。
通过API的此处略过,主要介绍后两种方法的使用。
1.via Transformers
用这个方法主要就是需要挂梯子
①下载模型,此处推荐直接下载到本地或者去modelscope上通过指令下载
modelscope download --model jinaai/jina-clip-v2 --local_dir ./dir
注意下载好之后对几个较大文件(model.safetensors、pytorch_model.bin、tokenizer)的大小进行核对,确定完整。
②配好环境、安好依赖即可运行代码,需要注意的是:
若下载了模型,则将此处的模型改为本地的路径。
model = AutoModel.from_pretrained('E:\projects\jina-clipv2', trust_remote_code=True,cache_dir='E:\projects\jina-clipv2\cache')
注意:该模型本地部署时需要去huggingface网站加载models–jinaai–jina-clip-implementation等缓存文件,因此需要挂梯子,否则会报错:无法连接http://huggingface.co。且可以添加’cache_dir=path_to_your_dir’参数,将缓存文件缓存到指定路径,否则会加载到“C:\Users\Administrator.cache\huggingface”默认路径。
并且下面图片的url也可提前保存到本地并替换为本地路径。
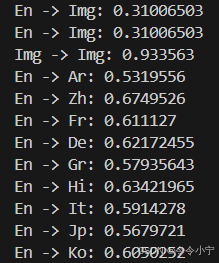
最终运行结果为:
2.via ONNX
这个方法相对简单
①下载onnx文件夹中的几个.onnx模型;
②把huggingface上提供的代码拉下来运行即可(注意替换本地路径)。

















 135
135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









