







1.结构体定义及初始化
程序开发人员可以使用结构体来封装一些属性, 设计出新的类型,在C语言中称为结构体类型。结构体里可以是任意类型,可供需求进行设计
- 定义格式:
struct 结构体名
{
自定义类型;
};
typedef struct Student
{
const char* name;
const char* sex;
int age;
}Student;
Student std = {"张三","男",30}; //使用{}来进行初始化或赋值
我们一般搭配typedef关键字来进行使用,在C语言中定义结构体变量时,要用struct Student,而在C++中则直接用Student,而为了代码的通用性,我们通常将结构体用typedef进行重命名
2.结构体嵌套及结构体数组
而遇见结构体嵌套结构体的,初始化时就像初始化二维数组一样,在{}里再套一个{}。
结构体数组也是类似
typedef struct grade
{
int math;
int english;
}grade;
typedef struct Student
{
grade gra;
const char* name;
const char* sex;
int age;
}Student;
Student std = {{100,100},"张三","男",30}; //结构体嵌套
Student std[10] = {{{100,100},"张三","男",30},{{50,50},"李四","男",20}}; //结构体数组
3.结构体成员访问
- 1.通过 . 访问
- 2.通过指针访问
typedef struct Student
{
const char* name;
const char* sex;
int age;
}Student;
Student std = {"张三","男",30};
std.age = 20;
Student* p = &std;
(*p).age = 30;
p->age = 30;
- .访问是通过结构体变量来进行访问的,这里就不用再解释了。
- 而定义一个结构体指针指向一个结构体变量,此时的*p就是std,然后就可以使用 . 访问了,然而 . 的优先级时高于*的,所以得使用()来提升优先级来保证使用顺序。而c语言中专门有一个运算符->来表示上述运算符,这两个运算符是等价的,只不过为了方便过着更加简洁、可读一点。
4.结构体大小、内存对齐问题
-
内存划分基本单位是按字节划分的,但CPU对内存不是单个字节划分的,通常为2,4,8的倍数。
-
对齐方式 : Windows:8字节 ,Linux:4字节
一般来说32位为4字节,64位为8字节,但你在vs上切换不起作用,除非这样,否则默认为8字节的对齐方式
-
修改对齐方式,如下代码
#pragma pack(2) //修改对齐方式为2字节
... //这里中间包含的代码,划分方式为2字节
#pragma pack()
- 结构体大小:关于结构体大小,这里首先知道如下规则:
1.结构体变量首地址,必须是{最大基本数据类型字节数,指定对齐方式}的最小值的倍数
2.每个结构体成员的首地址的偏移量,是{当前成员数据类型字节数,成员对齐方式}的最小值的倍数,不是倍数则空出一段内存,直至是倍数。注:非基本数据类型也算,对齐方式是该数据成员所对应的对齐方式(如下有例子),数组单看类型即可,或者看成一连串类型也行,联合体就看最大的类型就行。
3.结构体总大小{最大数据类型字节数(不包括嵌套的结构体),对齐方式}的最小值的倍数,不是倍数则空出一段内存,直至为倍数
注:不是倍数的,需空出相应的内存,直至为对应的倍数
- 目的:CPU处理效率高
实例1:
这里默认对齐方式为4字节,则从上往下看,char a没问题,int b 它的首地址的偏移量为1字节,所以需要空出3字节,这时b的地址偏移量为4字节,符合规则2,然后按照规则如下,则总内存大小为11+1,因为最后还有规则3,总大小必须是4的倍数,则最后的内存大小为12
struct A
{
char a; //1+3
int b; //4
short c; //2
char d //1
};
实例2:
这里说明的一点是:规则2如果成员是非基本数据类型,也算,否则不看的话,就按对齐方式8来了,就是加7了,所以规则2:偏移量为Min{ 任意类型成员,当前类型的对齐方式},为什么是当前类型的对齐方式呢,见实例4
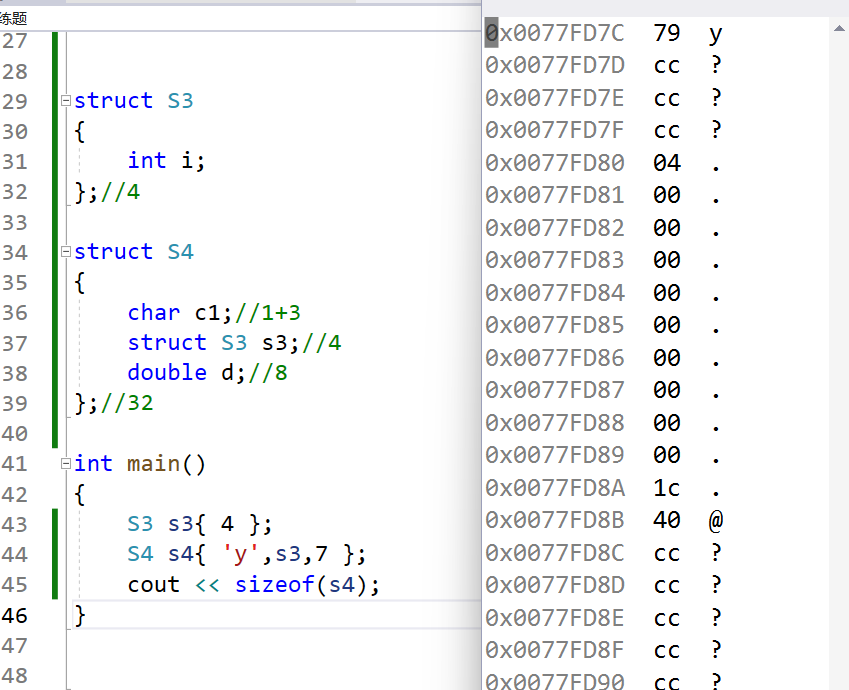
实例3:
这里需要强调的是:规则2中的成员任意成员即可,这里的S3为16个字节,在S4中,16与8(对齐方式)中取8的倍数,所以加7,这里说明了,或许非基本数据类型,不看,单看对齐方式
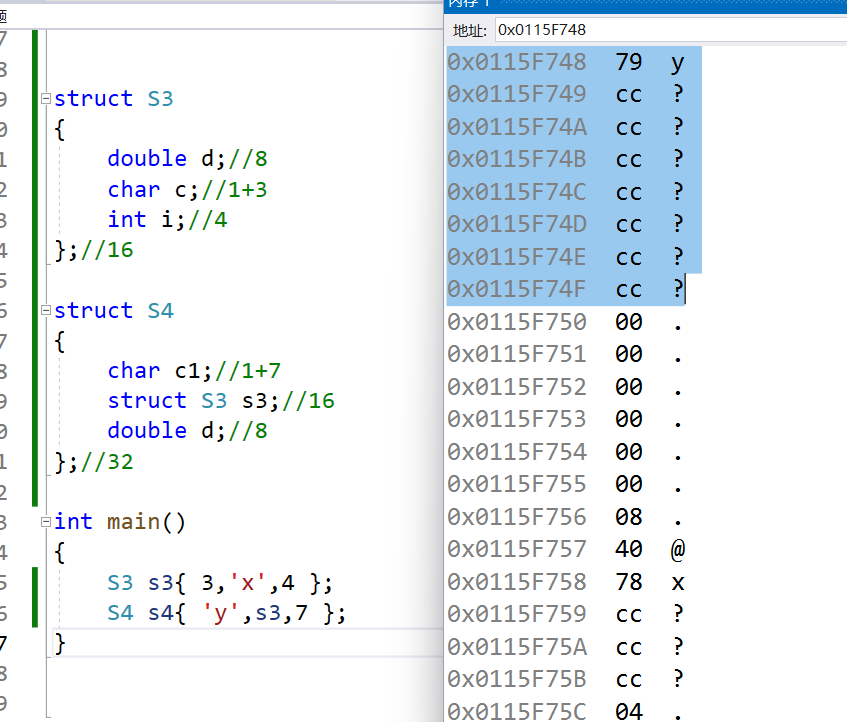
struct S3
{
double d;//8
char c;//1+3
int i;//4
};//16
struct S4
{
char c1;//1+7
struct S3 s3;//16
double d;//8
};//32
实例4:
这里注意一下,看B中第三行e,A为6个字节,与对齐方式4的最小值为4,所以偏移量为4的倍数,但却不是,此时的内存为b的分布情况,开始为0x…20,综合得出此时e的偏移量为6,这也不是4的倍数啊,反而是6的倍数。经过多次思考,觉得此时的对齐方式应该是A原来的对齐方式为2,4与2的最小为2,此时偏移量为5,所以应该加1,而不是加3。这里注意的点是,对齐方式是看当前数据成员类型在定义时所对应的对齐方式
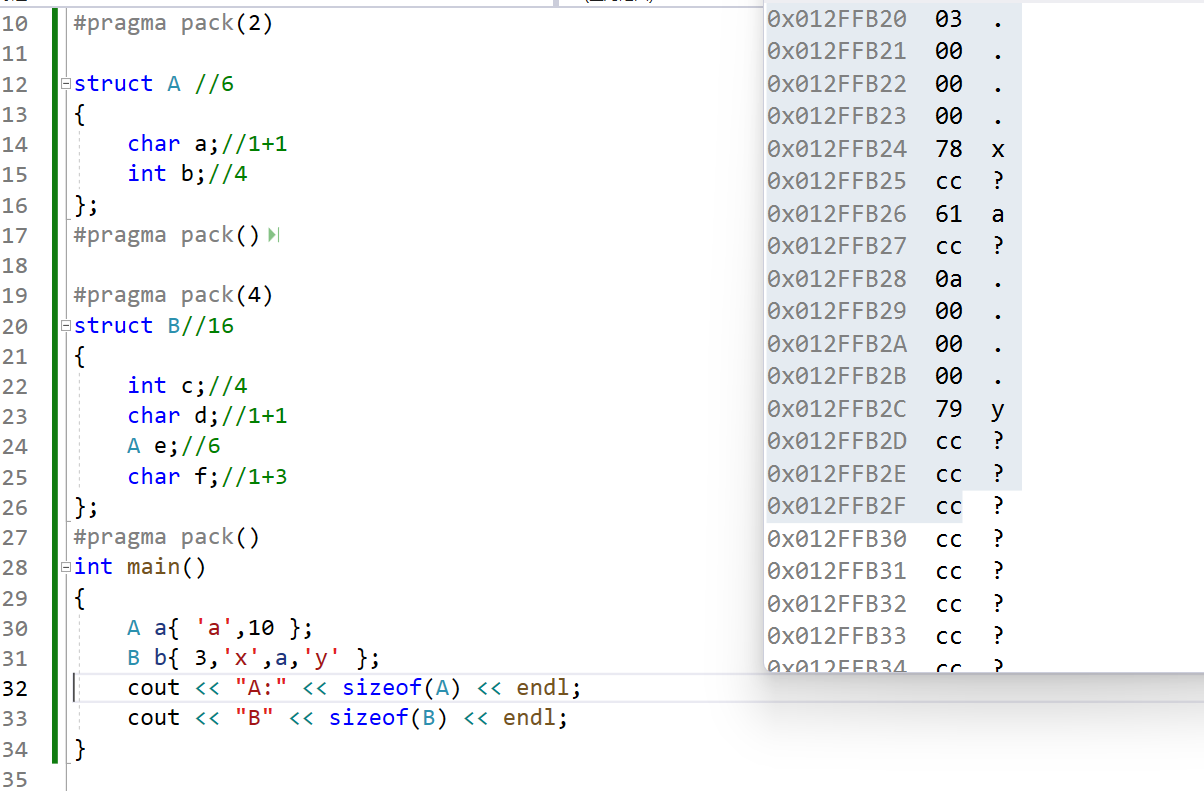
#pragma pack(2)
struct A //6
{
char a;//1+1
int b;//4
};
#pragma pack()
#pragma pack(4)
struct B//16
{
int c;//4
char d;//1+1
A e;//6
char f;//1+3
};
#pragma pack()
实例5:
这里讨论的是:规则3,最大数据类型包括非基本数据类型(结论错误,但例子不足以说明,下面有推翻),数组单看类型就行了,看偏移量和结构体大小时当成类型的大小就行了。解释:首先S4为12字节,根据上述推论int后不用跟字节,因为是b的对齐方式为2,不是8,拿6的话要加2,所以再次证明推论正确。然后看内存分布得b后要加2个字节,所以如果不考虑非基本类型的话,最大的数据类型就为4与对齐方式8比,取4的倍数,还要加2,但取6结果也一样,那么这个例子就不行了
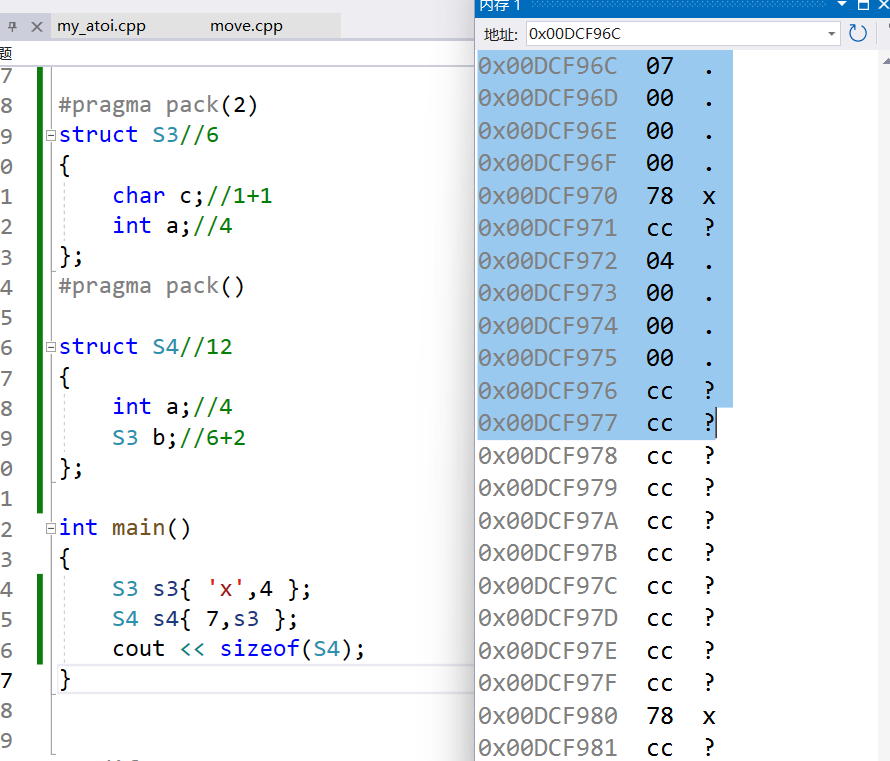
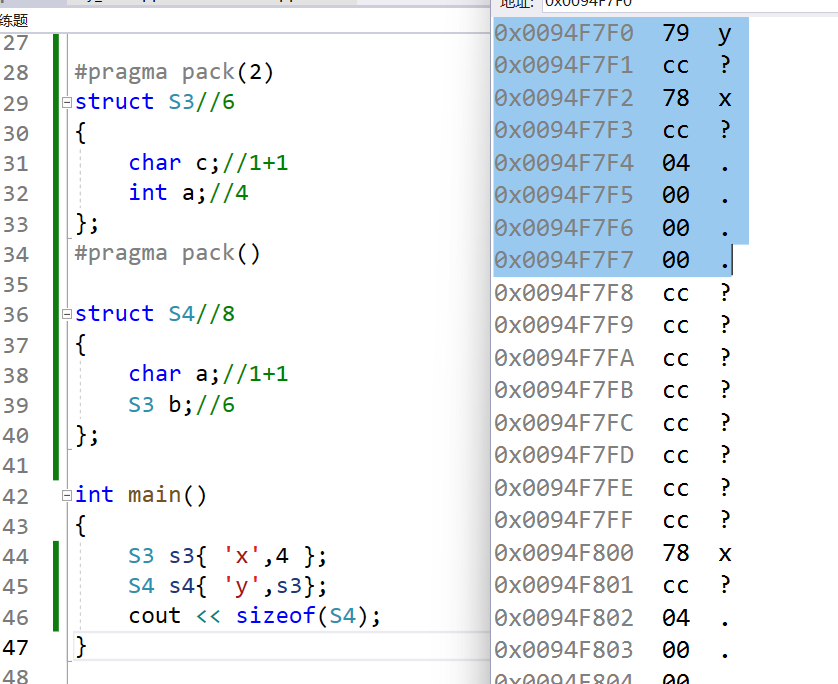
然后看这个例子:规则3首先内存分布已经根据编译器,写好了。再推导验证,若不看非基本类型,就按最大类型1与对齐方式8,取1,所以1的倍数即可,但看的话,就为6与8比较,取6的倍数,但却不一样,所以这里规则3的最大基本数据类型不包括非基本数据类型
















 618
618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











