






目前生产部署 Kubernetes 集群主要有两种方式
- kubeadm
Kubeadm是一个k8s部署工具,提供 kubeadm init 和 kubeadm join,用于快速部署 Kubernetes 集群。
kubeadm 是由 k8s 官方所提供的专门部署集群的管理工具。
在每一个节点主机上都要手动安装并运行 docker ,同时也都要手动安装并运行 kubelet。master 节点初始化的这个步骤,其实就是通过kubeadm 工具将 API Server、etcd、controller-manager、scheduler 各组件运行为 Pod,也就是跑在 docker 上。而其他 node 节点,因为已经运行了 kubelet、docker 组件,剩下的 kube-proxy 组件也是要运行在 Pod 上。
kubelet:负责能运行 Pod 化容器的核心组件。
docker:运行容器的引擎。
但是以上 master 节点上的 Pod 都是静态 Pod (static Pod),并不受 k8s 自身管理,只是运行为 Pod 形式而已,也可运行为自托管 Pod。
下图为此种方式部署的架构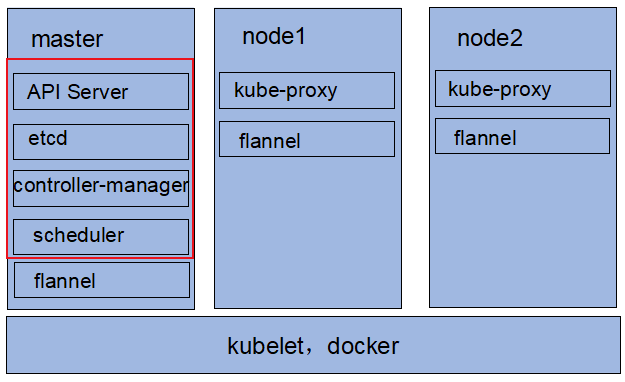
- 二进制包
从 github 下载发行版的二进制包,手动部署每个组件,组成 Kubernetes 集群。
此方法是将 API Server、etcd、controller-manager、schedule 等各组件进行 install、编译安装或者展开安装的方式手动直接安装在 master 节点主机上,作为系统级守护进程运行。
将 kube-proxy、kubelet、docker、flannel 各组件进行 install 或下载已预制好的二进制程序包手动安装在 node 节点主机上,作为系统级守护进程运行。
此部署方式非常的繁琐,出于安全方面的考虑,各组件之间通信都需要配置 CA 和证书,且如果 master 宕机了,需要手动启动这些系统级的守护进程。
以下采用 kubeadm 的方式搭建集群。
安装主要事项:
- 一台节点安装master,一台安装node,不能在一个主机同时安装master和node;
- k8s里的每一个主机名不能一样;
1. 环境准备
虚拟机/服务器要求:
建议硬件配置:2核CPU、4G内存、40G硬盘。
k8s-master:192.168.10.97
k8s-node1:192.168.10.100
k8s-node2:192.168.10.111
2. 初始化系统
系统:ubuntu 20.04
以下操作在三台机器上都需要执行。
2.1 更改主机名
sudo hostnamectl set-hostname k8s-mastersudo hostnamectl set-hostname k8s-node1sudo hostnamectl set-hostname k8s-node2
2.2 修改hosts文件
大型环境可以使用 DNS 的方式来使主机名和 ip 互相解析vim /etc/hosts
192.168.10.97 k8s-master
192.168.10.100 k8s-node1
192.168.10.111 k8s-node2
2.3 配置网卡 ip
系统不同,配置文件可能不同vim /etc/netplan/00-installer-config.yaml
# Let NetworkManager manage all devices on this system
network:
ethernets:
ens33: #注意修改为实际的网卡 ens33
dhcp4: no
addresses: [192.168.10.97/24] #静态ip,node1/node2换成机器对应的 ip 即可
gateway4: 192.168.10.1 #网关,可在windows设置里查看
nameservers:
addresses: [192.168.10.1] #DNS,需要根据实际修改,可在windows设置里查看
version: 2
sudo netplan apply配置生效
2.4 关闭防火墙
sudo systemctl stop ufw.service
sudo systemctl disable ufw.service #开机禁用
sudo systemctl status ufw.service
ufw disable
测试网络是否正常ping www.baidu.comping 192.168.10.100ping 192.168.10.111
2.5 修改 apt 源
cd /etc/aptcp sources.list sources.list.bak:备份vim sources.list
deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
# deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
# deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
apt update:更新
2.6 禁用 swap
systemctl stop swap.target
systemctl status swap.target
systemctl disable swap.target #开机禁用
systemctl stop swap.img.swap
systemctl status swap.img.swap
# 关闭虚拟交换分区
sudo vim /etc/fstab
将 swap.img 的一行注释掉
2.7 修改内核参数
安装 ipvsadmapt install -y ipvsadm
sudo tee /etc/sysctl.d/k8s.conf << 'EOF'
net.ipv4.ip_forward = 1
EOF
sudo sysctl -p /etc/sysctl.d/k8s.conf
sudo cat > /etc/modules-load.d/ipvs.conf << EOF
ip_vs dh
ip_vs_fo
ip_vs_ftp
ip_vs
ip_vs_1blc
ip_vs lblcr
ip_vs_lc
ip_vs_mh
ip_vs_nq
ip_vs_ovf
ip_vs_pe_sip
ip_vs_rr
ip vs sed
ip_vs_sh
ip_vs_wlc
ip_vs_wrr
nf_conntrack
EOF
lsmod I grep ip_vs
systemctl enable --now systemd-modules-load.service
reboot:重启lsmod | grep -e ip_vs -e nf_conntrack_ipv4:重启后确认内核模块是否加载成功
2.8 时间同步
先查看时区是否正常,不正确则替换为上海时区。
date
timedatectl set-timezone Asia/Shanghai #设置时区
apt -y install ntp #安装ntp服务
systemctl start ntp
systemctl enable ntp
2.9 安装 docker
apt install -y docker.iosystemctl status dockersystemctl enable docker:开机自启
# 配置镜像下载加速
sudo mkdir -p /etc/docker
vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://7ske187f.mirror.aliyuncs.com"], #镜像加速
"exec-opts": ["native.cgroupdriver=systemd"], #更换驱动,k8s用systemd驱动
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
sudo systemctl daemon-reload:重新加载配置文件sudo systemctl restart docker:重启dockerdocker info | grep -i "Cgroup Driver":查看驱动是否更换docker ps:测试docker命令是否可以正常使用
注意:
如果出现如下报错,执行代码框内的命令Job for docker.service failed because the control process exited with error code.See "systemctl status docker.service" and "journalctl -xe" for details.
mv daemon.json daemon.conf
cp daemon.conf ./daemon.json
sudo systemctl daemon-reload
sudo systemctl restart docker
2.10 使用阿里云 kubernetes 镜像
Kubernetes 镜像配置
https://developer.aliyun.com/mirror/kubernetes/?spm=a2c6h.25603864.0.0.3de125c52PZTug
apt update && apt install -y apt-transport-https
# 下载安装源的gpg秘钥
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
apt update
sudo apt install -y kubeadm=1.23.6-00 kubelet=1.23.6-00 kubectl=1.23.6-00 #安装指定版本
查看版本apt-mark hold kubeadm kubelet kubectl:为设置相应资源不自动更新,此处不执行systemctl enable kubelet.service:开机自启kubeadm versionkubelet --versionkubectl version --client
3. master 初始化
以下操作只在 master 机器执行。
sudo kubeadm init \
--kubernetes-version v1.23.6 \
--apiserver-advertise-address=192.168.10.97 \
--pod-network-cidr=10.244.0.0/16 \
--image-repository registry.aliyuncs.com/google_containers
# --pod-network-cidr 10.244.0.0/16 参数与后续 CNI 插件有关,这里以 flannel 为例,若部署其他类型的网络插件请更改此参数。
# 使用国内镜像可以指定镜像仓库:--image-repository
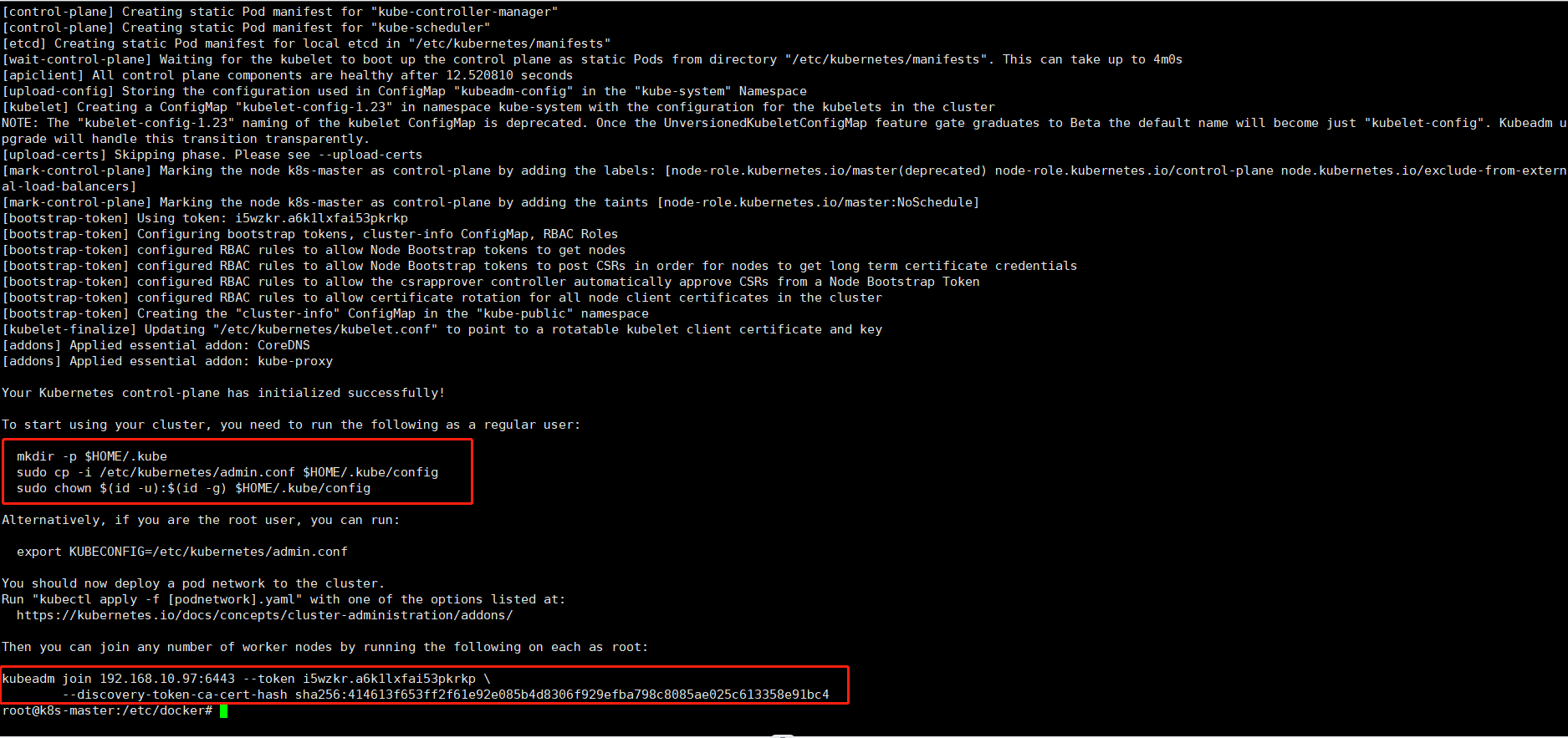
将 kubeadm join 这一段命令记下来,后面加入节点时会用到。
按提示操作mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/configexport KUBECONFIG=/etc/kubernetes/admin.confkubectl get pods -A -o wide
注意:
这里面 coredns 全部是 Pending 是正常的现象,因为系统就是这么设计的。 kubeadm 的网络供应商是中立的,因此管理员应该选择 安装 pod 的网络插件。 你必须完成 Pod 的网络配置,然后才能完全部署 CoreDNS。 在网络被配置好之前,DNS 组件会一直处于 Pending 状态。
4. 部署 CNI
使用 kubectl 部署 flannel 。vim /etc/hosts/
加入 185.199.110.133 raw.githubusercontent.com 否则下载 kube-flannel.yml 会失败
不想下载直接在这拿 kube-flannel.yml
# 下载 kube-flannel.yml
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f kube-flannel.yml
kubectl get nodes
安装完成后检查一下状态
附:
解决下载 kube-flannel.yml 失败
https://blog.csdn.net/weibo1230123/article/details/121737413
5. 加入节点
以下操作在 node1 和 node2 执行。
# 加入节点
kubeadm join 192.168.10.97:6443 --token xwwf3c.posdgk2m48ysh52l --discovery-token-ca-cert-hash sha256:414613f653ff2f61e92e085b4d8306f929efba798c8085ae025c613358e91bc4
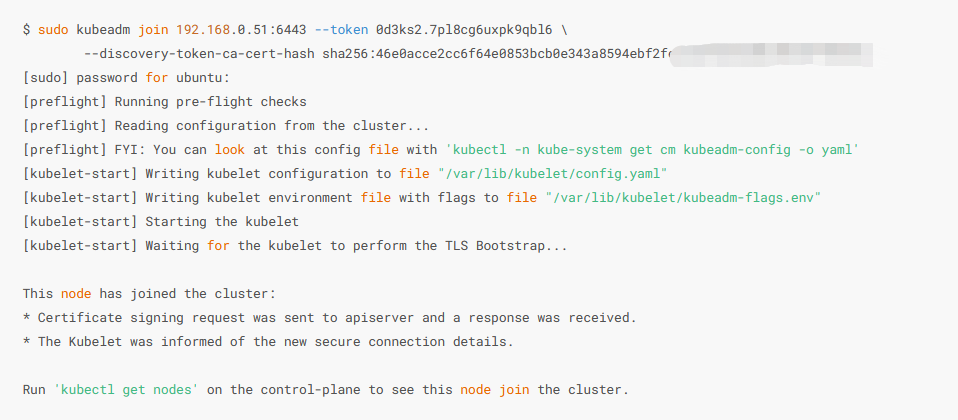
如果忘记了上面 kubeadm join 的命令,可以在 master 执行kubeadm token create --print-join-command:打印添加数据平面(work node)的命令。kubeadm token create --print-join-command --ttl=0:如果 token 失效,在 master 节点执行重新生成。其中 --ttl=0 表示生成的 token 永不失效。如果不带 --ttl 参数,那么默认有效时间为24小时,在24小时内,可以无数量限制添加 worker。kubeadm token list:查看所有token。
注意:加入集群后要将master上的 admin.conf 文件拷到node中(可以通过scp传),否则运行“kubectl get nodes”会报错
The connection to the server localhost:8080 was refused - did you specify the right host or port?
# 将 master /etc/kubernetes/admin.conf 复制到node1和node2中,再执行下面的命令
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> /etc/profile
source /etc/profile
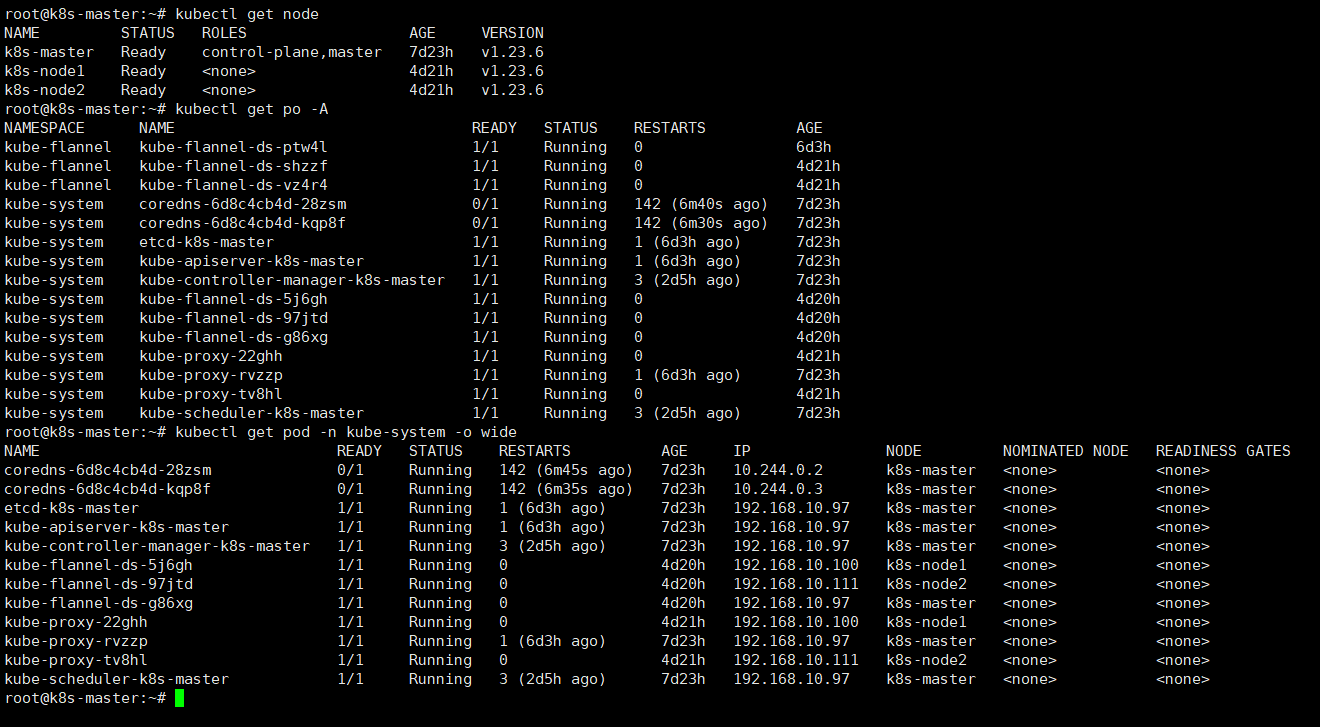
:查看是否加入成功
可以看到 node1 和 node2 已经加入到集群中,网络没问题就会显示 Ready。
6. 测试集群
采用 nginx 来测试集群,在 master 节点上依次执行如下命令:kubectl create deployment nginx --image=nginxkubectl expose deployment nginx --port=80 --type=NodePortkubectl get pod,svc
kubectl get pod -o wide可以看到是运行在 node1 节点
查看下,在浏览器输入 node1节点 ip+端口192.168.10.100:31369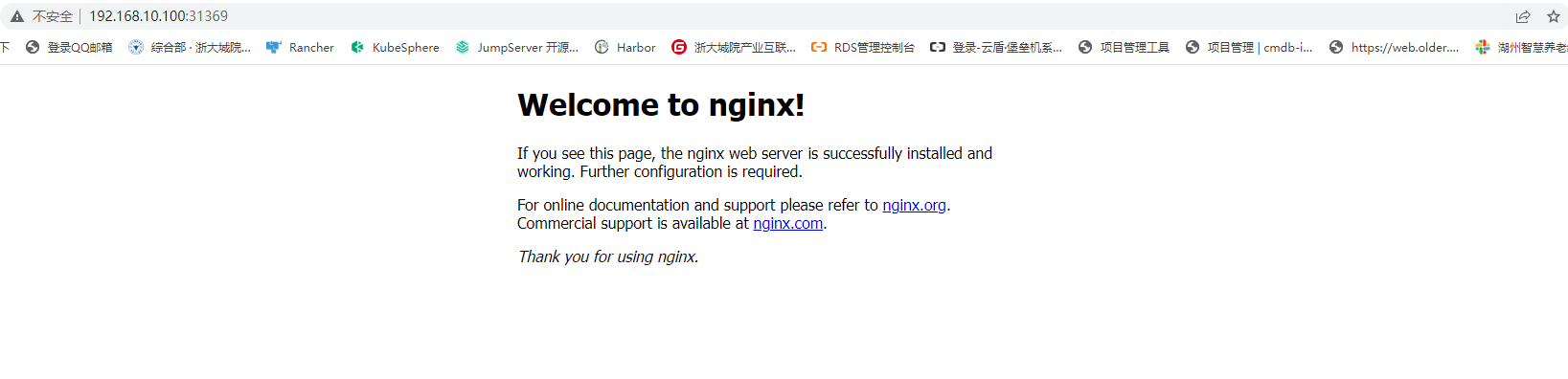
测试完毕,删除 nginxkubectl delete deployment nginxkubectl delete service nginx
常用命令
# 查看node节点和服务版本信息
kubectl get nodes
# 查看node节点和服务版本信息,并查看详细信息
kubectl get nodes -o wide
# 查看pod信息,默认是default名称空间
kubectl get pod
# 获取所有名称空间的pod
kubectl get po -A
# 查看pod信息,并查看详细信息
kubectl get pod -o wide
# 查看pod信息,以yaml或json格式展示(可以看到许多详细信息)
kubectl get pod pod_name -o yaml/json
# 获取指定名称空间的pod
kubectl get pod -n kube-system
kubectl get pod -n kube-system -o wide
# 获取指定名称空间的指定pod
kubectl get pod -n kube-system podName
# 删除节点,在 master 节点执行
kubectl delete node [node name]
# 删除所有的 pod
kubectl delete pod --all
# 查看 pod 日志
kubectl describe pod [pod名称]
参考文档:https://www.cnblogs.com/seaskyccl/articles/16424149.html
7. 卸载
# 停止相关服务
systemctl stop kubelet
systemctl stop etcd
systemctl stop docker
# 清空K8s集群设置,卸载管理组件
sudo kubeadm reset -f
apt remove -y kubelet kubeadm kubectl
# 删除k8s相关目录
sudo rm -rvf $HOME/.kube
sudo rm -rvf ~/.kube/
sudo rm -rvf /etc/kubernetes/
sudo rm -rvf /etc/systemd/system/kubelet.service.d
sudo rm -rvf /etc/systemd/system/kubelet.service
sudo rm -rvf /usr/bin/kube*
sudo rm -rvf /etc/cni
sudo rm -rvf /opt/cni
sudo rm -rvf /var/lib/etcd
sudo rm -rvf /var/etcd
8. FAQ
8.1 kuberlet 服务启动报错
**问题:**无法运行Kubelet:配置错误 Kubelet cgroup 驱动程序\cgroupfs\不同"Failed to run kubelet"err="failed to run kubelet: misconfiguration: kubelet cgroup driver: \"systemd"\ is different from docker cgroup driver:\"cgroupfs\"" 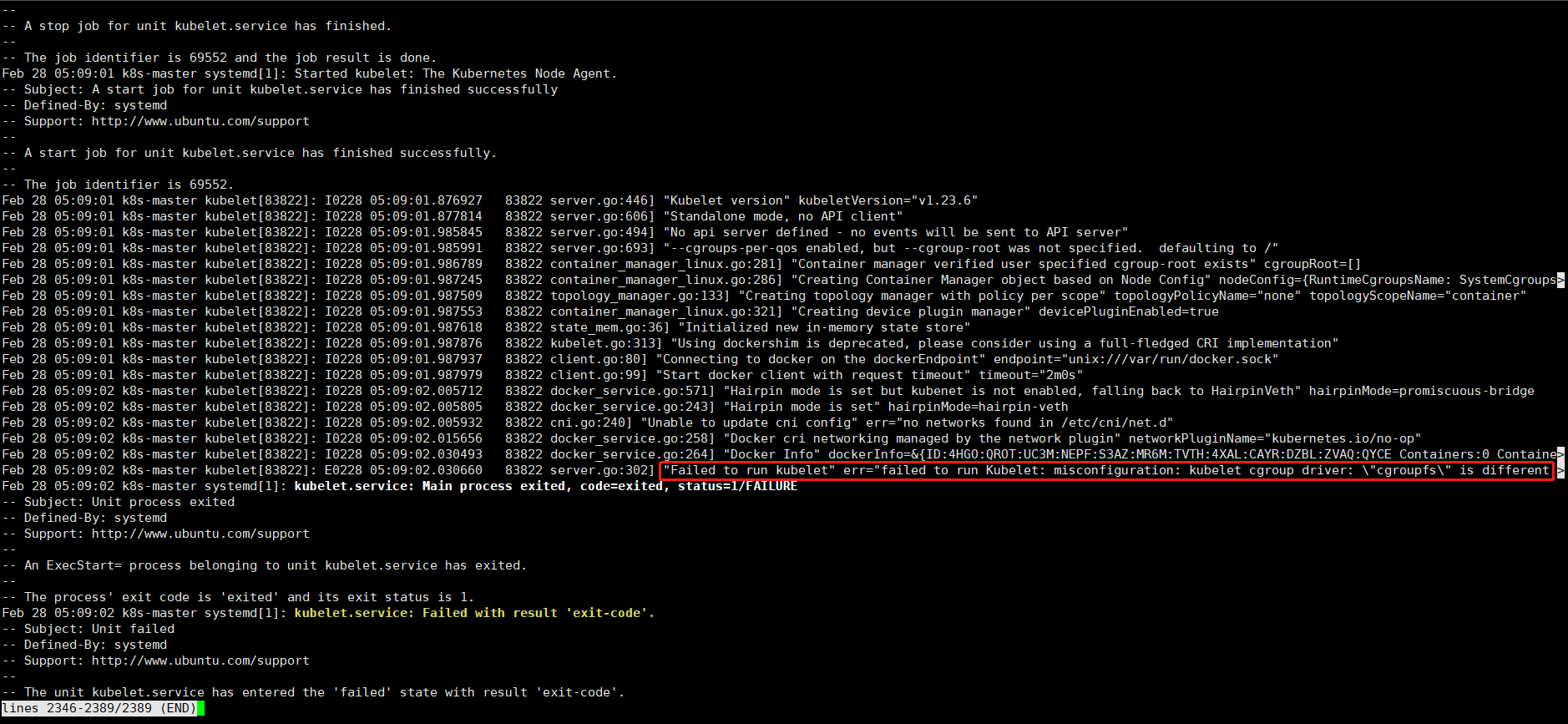
原因:
经过分析后发现,是因为“kebernetes默认设置cgroup驱动为systemd,而docker服务的cgroup驱动为cgroupfs”。
解决:
有两种决解决方法。方法一是将docker的服务配置文件修改为何kubernetes的相同,方法二是修改kebernetes的配置文件为cgroupfs,这里采用第一种。
# 修改docker服务配置文件/etc/docker/daemon.json
{
"registry-mirrors": ["https://7ske187f.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"], #改为systemd
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
# 重启docker服务
sudo systemctl daemon-reload
sudo systemctl restart docker
# 修改后查看docker的cgroup
docker info | grep "Cgroup Driver"
# 重启kuberlet
systemctl restart kubelet
systemctl status kubelet
参考文档:https://www.cnblogs.com/cosmos-wong/p/15709464.html
8.2 kubectl get node 报错
问题:
报错 The connection to the server localhost:8080 was refused - did you specify the right host or port?
这个问题非常常见,master 和 node 机器都有可能碰到,报错与服务器连接被拒绝。
原因:
kubectl 的运行是需要进行配置的,它的配置文件是$HOME/.kube,如果想要在 node 节点运行此命令,需要将master 上的.kube文件复制到 node 节点上。
解决:
先查看下 /etc/kubernetes/ 目录下是否存在 admin.conf,然后将上述文件路径写入到 /.bash_profile 环境变量配置文件中。node节点如果没有 admin.conf 该文件的话,可以将 master 中的拷贝过来。
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
chown $(id -u):$(id -g) $HOME/.kube/config
参考文档:https://blog.csdn.net/D1179869625/article/details/126929738
8.3 网络问题报错
问题:
查看 kubelet 服务状态发现报错 "Error validating CNI config list" configList="{\n \"name\": \"cbr0\",\n ……
或是Unable to update cni config: No networks found in /etc/cni/net.d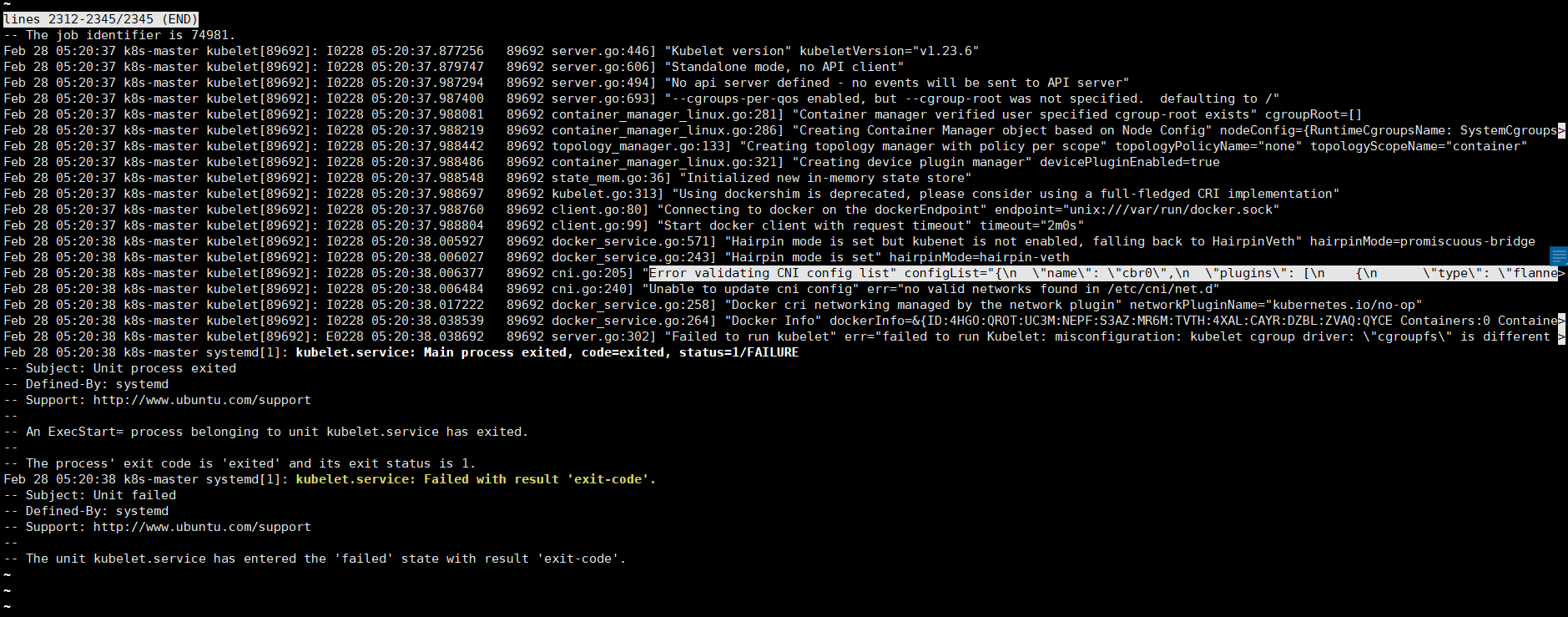
解决:
这个错误和 cni 网络插件有关,修改 10-kubeadm.conf 网络插件配置参数, 需要注意下配置路径和插件路径。
cd /etc/systemd/system/kubelet.service.d/
vim 10-kubeadm.conf #增加一行Environment,如下
# Note: This dropin only works with kubeadm and kubelet v1.11+
[Service]
Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf"
Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml"
Environment="KUBELET_NETWORK_ARGS=--network-plugin=cni --cni-conf-dir=/etc/cni/ --cni-bin-dir=/opt/cni/bin"
# This is a file that "kubeadm init" and "kubeadm join" generates at runtime, populating the KUBELET_KUBEADM_ARGS variable dynamically
EnvironmentFile=-/var/lib/kubelet/kubeadm-flags.env
# This is a file that the user can use for overrides of the kubelet args as a last resort. Preferably, the user should use
# the .NodeRegistration.KubeletExtraArgs object in the configuration files instead. KUBELET_EXTRA_ARGS should be sourced from this file.
EnvironmentFile=-/etc/default/kubelet
ExecStart=
ExecStart=/usr/local/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS
systemctl daemon-reload
systemctl restart docker
systemctl restart kubelet
systemctl status kubelet
常见错误汇总
https://www.cnblogs.com/taoweizhong/p/11545953.html
https://blog.csdn.net/xjpk0/article/details/108704273
参考文档:
https://blog.csdn.net/week_ed/article/details/127376925
https://blog.csdn.net/qq_20143059/article/details/116156448
https://blog.csdn.net/qq_29078779/article/details/106373812
Megrez wiki















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









