







前言
本专栏RPC项目使用数据压缩编码方式为Protobuf。
协议
协议:协议是⼀种约定,通过约定,不同的进程可以对⼀段数据产生相同的理解,从⽽可以相互协 作,存在进程间通信的程序就⼀定需要协议。
说白了协议就是为了让对端知道如何给消息帧分界,如果两端进行通信没有约定好协议,那彼此是不知道对方发送的数据是什么意义。为了能让对端知道如何给包分界,⽬前⼀般有以下做法:
1. 以固定大小字节数目来分界,如每个包100个字节,对端每收齐100个字节,就当成⼀个包来解析;
2. 以特定符号来分界,如每个包都以特定的字符来结尾(如\r\n),当在字节流中读取到该字符时,则表 明上⼀个包到此为⽌ ;
3. 固定包头+包体结构,这种结构中⼀般包头部分是⼀个固定字节⻓度的结构,并且包头中会有⼀个特定的字段指定包体的⼤⼩。收包时,先接收固定字节数的头部,解出这个包完整⻓度,按此⻓度接收包体。这是⽬前各种⽹络应⽤⽤的最多的⼀种包格式;header + body
4. 在序列化后的buffer前⾯增加⼀个字符流的头部,其中有个字段存储包总⻓度,根据特殊字符(⽐如根 据\n或者\0)判断头部的完整性。这样通常⽐3要麻烦⼀些,HTTP和REDIS采⽤的是这种⽅式。收包的时候,先判断已收到的数据中是否包含结束符,收到结束符后解析包头,解出这个包完整⻓度,按此⻓度接收包体。header + \r\n + body,比较起第三种较为麻烦。
序列化就是把对象转化为可传输的字节序列过程;反序列化就是把字节序列还原为对象的过程。数据传输是一定需要序列化的,不然不同平台怎么去知晓并使用你的数据。
序列化的方法
序列化的方法:
- TLV编码及其变体(TLV是tag, length和value的缩写):⽐如Protobuf。
- ⽂本流编码:⽐如XML/JSON
- 固定结构编码: 基本原理是,协议约定了传输字段类型和字段含义,和TLV的⽅式类似,但是没有了 tag和len,只有value,⽐如TCP/IP
- 内存dump:基本原理是,把内存中的数据直接输出,不做任何序列化操作。反序列化的时候,直接还原内存
主流序列化协议:xml、json、protob
- XML指可扩展标记语⾔(eXtensible Markup Language)。是⼀种通用和重量级的数据交换格式。以⽂本⽅式存储。
- JSON(JavaScript ObjectNotation, JS 对象简谱) 是⼀种通⽤和轻量级的数据交换格式。以⽂本结构进⾏存储。
- protocol buffer是Google的⼀种独⽴和轻量级的数据交换格式。以⼆进制结构进⾏存储。
序列化、反序列化速度对比
测试10万次序列化:

测试10万次反序列化:
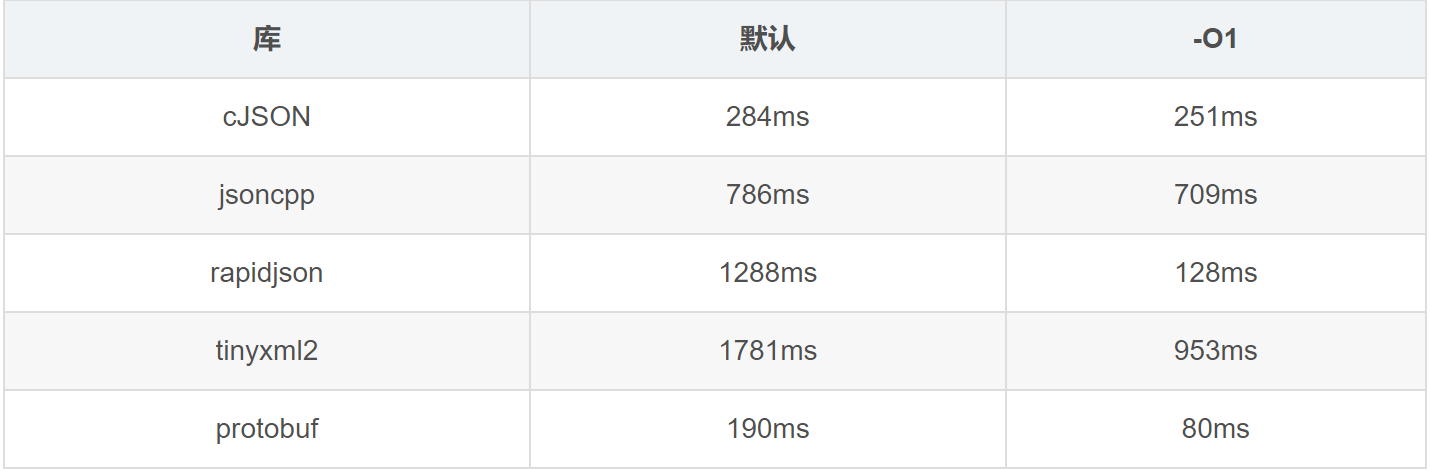
Protobuf这种以⼆进制结构进行存储的效率是很高的,所以RPC项目中数据的序列化和反序列化使用的就是它。
Protobuf
protobuf的介绍
Protocol buffers 是一种语言中立,平台无关,可扩展的序列化数据的格式,可用于通信协议,数据存储等。
Protocol buffers 在序列化数据方面,它是灵活的,高效的。相比于XML 来说,Protocol buffers 更加小巧,更加快速,更加简单。一旦定义了要处理的数据的数据结构之后,就可以利用 Protocol buffers 的代码生成工具生成相关的代码。甚至可以在无需重新部署程序的情况下更新数据结构。只需使用 Protobuf 对数据结构进行一次描述,即可利用各种不同语言或从各种不同数据流中对你的结构化数据轻松读写。Protocol buffers 很适合做数据存储或 RPC 数据交换格式。
protobuf的安装
&emsp 在github上先下载好对应的压缩包,点击这里下载,我下载的是protobuf-cpp-3.21.7.tar.gz这个cpp版本的。
接下来解压:
tar zxvf protobuf-cpp-3.21.7.tar.gz
然后进入目录:
cd protobuf-cpp-3.21.7
编译,依次执行以下命令:
1 ./configure
2 make
3 sudo make install
4 sudo ldconfig
protobuf的编译
编译后会⽣成对应的.cc和.h⽂件.
将proto⽂件⽣成对应的.cc和.h⽂件:
protoc -I=/路径1 --cpp_out=./路径2 /路径1/addressbook.proto
路径1为.proto所在的路径
路径2为.cc和.h⽣成的位置
将指定proto⽂件⽣成.pb.cc和.pb.h :
protoc -I=./ --cpp_out=./ test.proto
将对应⽬录的所有proto⽂件⽣成.pb.cc和.pb.h :
protoc -I=./ --cpp_out=./ *.proto
protobuf的简单使用
syntax = "proto3";
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
}
文件的第一行指定了你正在使用proto3语法:如果你没有指定这个,编译器会使用proto2。这个指定语法行必须是文件的非空非注释的第一个行。
SearchRequest消息格式有3个字段,在消息中承载的数据分别对应于每一个字段.其中每个字段都有一个名字和一种类型。
下面是proto文件中各类型在各语言中对应的类型:
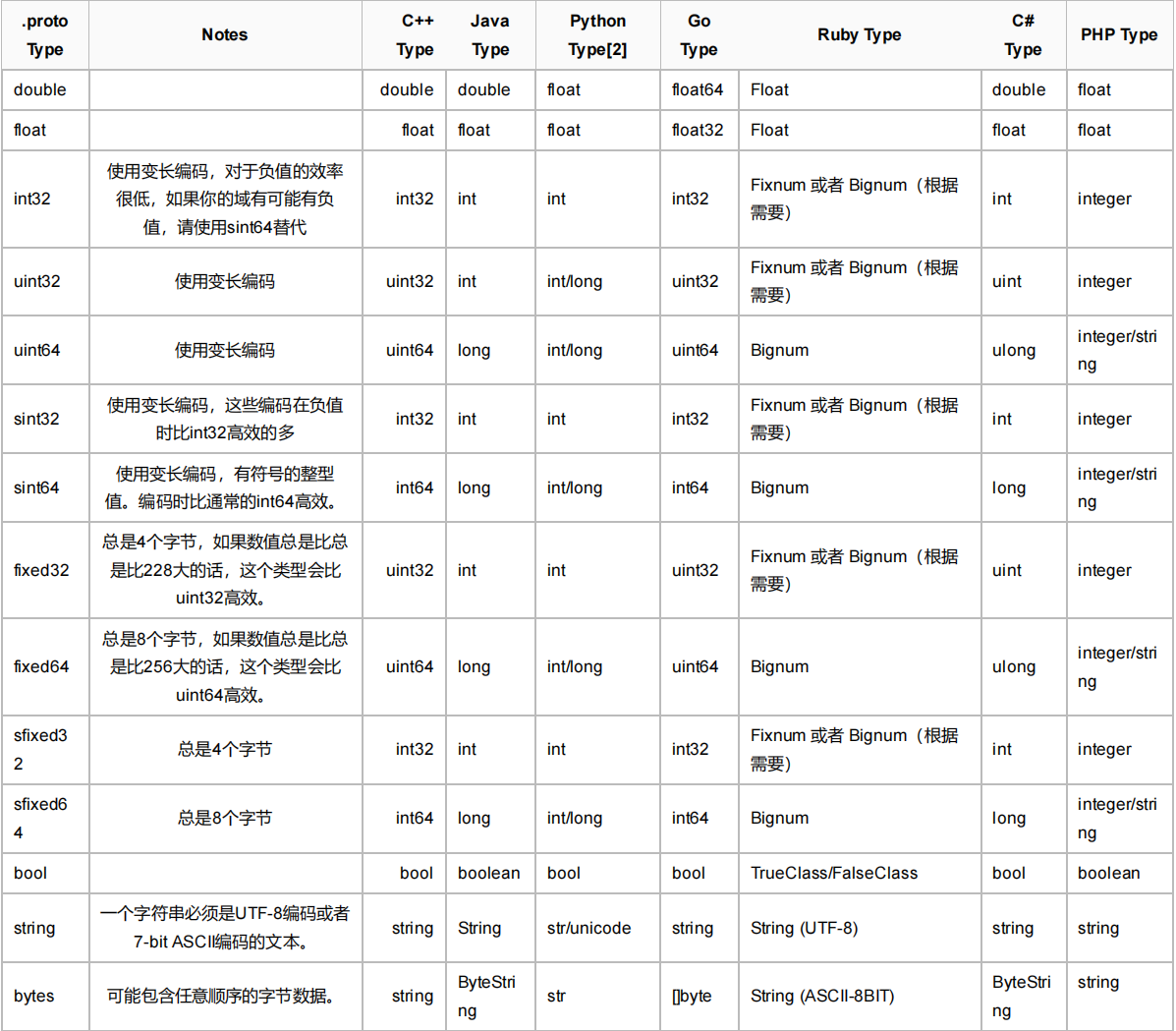
=1,=2,=3不是初始值,是标识符,从1开始最大到2^29 1, or 536,870,911。不可以使用其中的[19000-19999]( (从 FieldDescriptor::kFirstReservedNumber 到FieldDescriptor::kLastReservedNumber))的标识号, Protobuf协议实现中对这些进 行了预留。如果非要在.proto文件中使用这些预留标识号,编译时就会报警。同样你也不能使用早期保留的标识号。
当需要定义一个消息类型的时候,可能想为一个字段指定某“预定义值序列”中的一个值。例如,假设要为每一个SearchRequest 消息添加一个 corpus字段,而corpus的值可能是UNIVERSAL,WEB,IMAGES,LOCAL,NEWS,PRODUCTS或VIDEO中 的一个。 其实可以很容易地实现这一点:通过向消息定义中添加一个枚举(enum)并且为每个可能的值定义一个常量就可以 了。在下面的例子中,在消息格式中添加了一个叫做Corpus的枚举类型——它含有所有可能的值 ——以及一个类型为Corpus的字段。
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
enum Corpus {
UNIVERSAL = 0;
WEB = 1;
IMAGES = 2;
LOCAL = 3;
NEWS = 4;
PRODUCTS = 5;
VIDEO = 6;
}
Corpus corpus = 4;
}
repeated:在一个格式良好的消息中,这种字段可以重复任意多次(包括0次)。重复的值的顺序会被保留。可以简单理解为把它放在定义的语句前就是定义了一个数组或者列表。
message SearchRequest {
repeated string query = 1;
}
Protobuf的编码原理
可以直接完整阅读此篇,写的很详细,点击这里















 860
860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









