







中文名:评估文本到图像生成:图像质量评估指标的综述与分类
下载链接:https://arxiv.org/abs/2405.16640[2403.11821] A Survey on Quality Metrics for Text-to-Image Modelshttps://arxiv.org/abs/2405.16640
一句话介绍:这篇文章是对文本到图像合成的评估指标的全面综述,涵盖了指标分类、优化及挑战等内容。
1 介绍
文本条件下的图像生成领域正在快速发展,稳健的T2I(文本到图像)对齐指标 是不可或缺的。
文本条件下的图像整体质量定义为通用图像质量与组合质量的结合,其中组合质量衡量文本与图像之间的对齐程度。
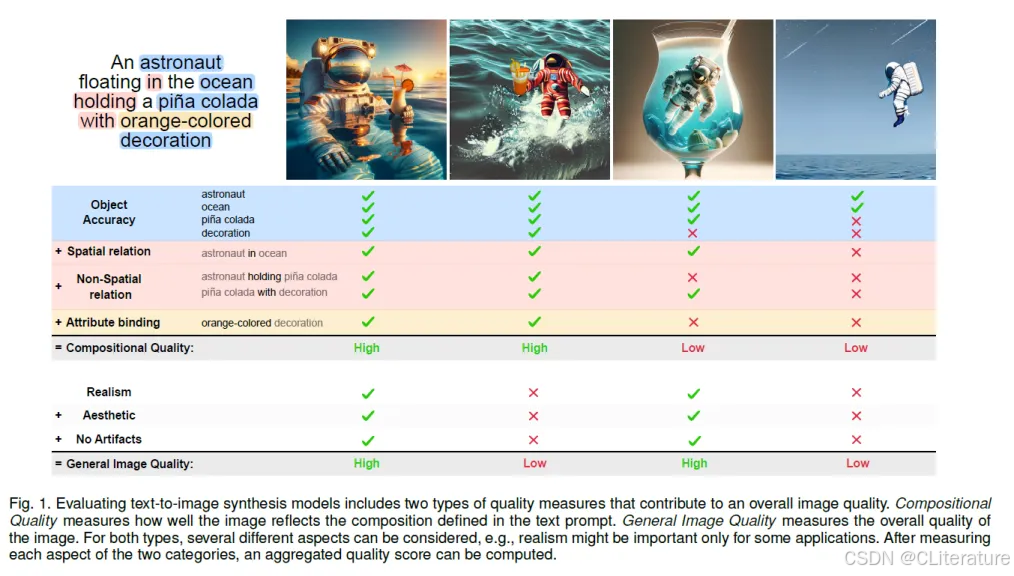
图1是一个评估文生图质量的例子。
prompt为“一位宇航员漂浮在海洋中,手里拿着一杯有橙色装饰的椰林飘香”。
也就是说希望图片中有:
- 一个宇航员
- 海洋
- 宇航员手里有一杯饮料(叫“椰林飘香”)
- 饮料有橙色的装饰。
分别用组合质量和通用质量(即整体的质感)来对图片进行评估
对于图1来说:
组合质量:高
- 物体准确性: 宇航员、海洋、饮料和橙色装饰都在,打勾!
- 空间关系: 宇航员真的漂浮在海洋里,打勾!
- 非空间关系: 宇航员手里确实拿着饮料,饮料也有橙色装饰,打勾!
- 属性绑定: 饮料的装饰颜色是橙色,打勾。
整体质量:高
- 现实感: 很像真的照片,打勾!
- 美感: 很漂亮,打勾!
- 没有明显问题(例如奇怪的形状): 很好,打勾。
2 分类法
本文奖评估指标分为两类。一种是纯粹基于图像的评估指标,旨在测量图像质量;另一种是文本 - 图像评估指标,用于测量文本提示与生成图像之间的对齐程度。
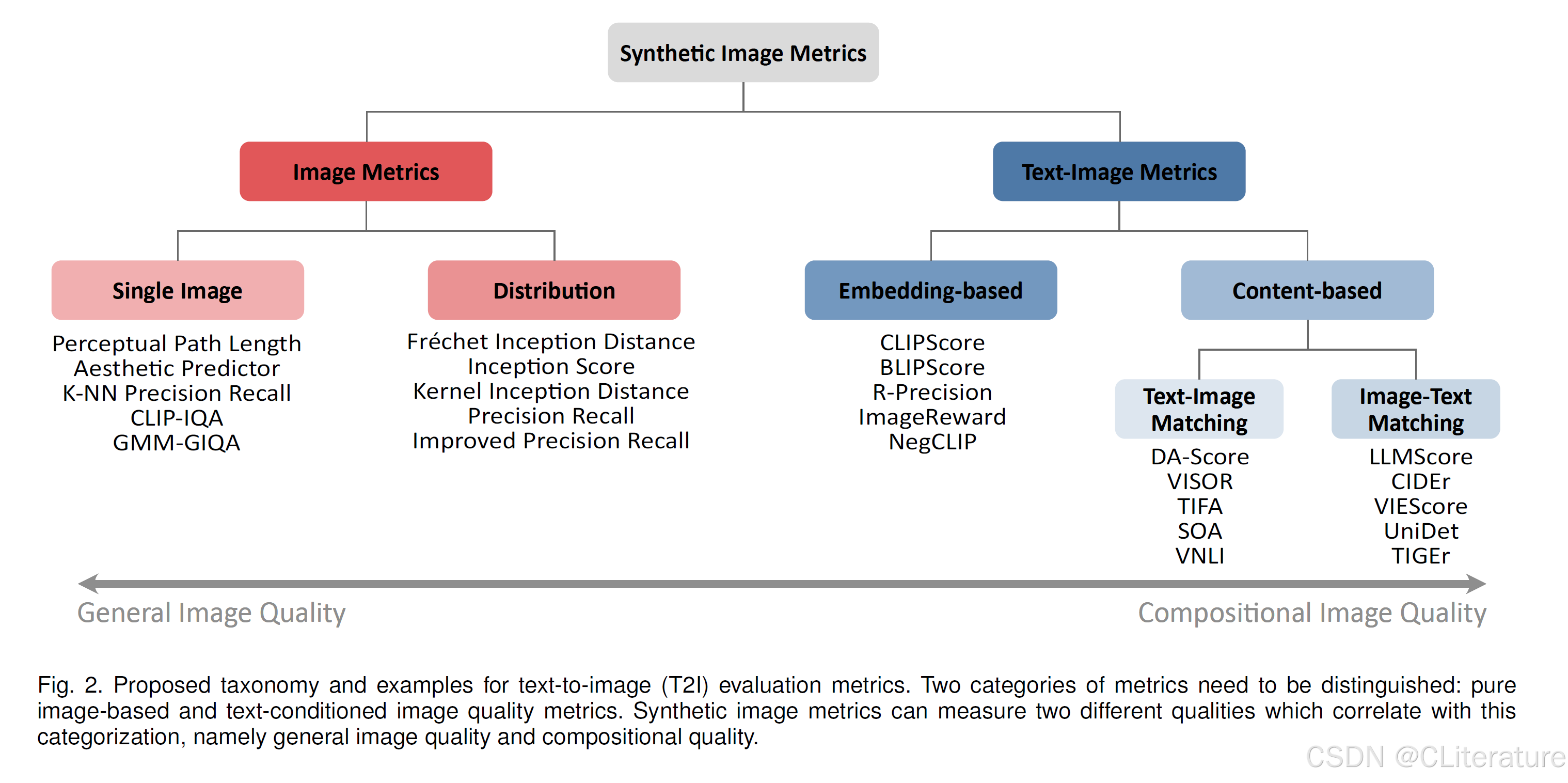
图2展示了本文的分类法
图像指标主要衡量一般图像质量
文本图像指标主要衡量组合质量
2.1 图像指标
基于图像的指标完全不考虑图像生成的文本输入。也就是说图像质量的评估独立于文本 - 图像质量。比如一张看起来逼真但忽略文本事实的图像会有较高的图像质量分数但较低的对齐分数。
2.1.1 基于分布的指标
主要依赖于统计方法来评估生成数据的分布与给定(通常是真实世界)数据的分布之间的差异。
2.1.2 单图像指标
通过基于图像的结构和语义组成分析图像来衡量单个图像的质量。这些指标从图像中提取特征,然后推断质量。与基于分布的指标不同,单图像指标的计算不需要任何目标图像或分布。
2.2 文本-图像对齐指标
文本 - 图像指标衡量文本提示与生成图像的对齐程度。又可分为基于嵌入的指标和基于内容的指标。基于嵌入的指标根据文本 - 图像对齐来量化图像生成质量,而基于内容的指标则检查生成图像和文本提示的内容。
2.2.1 基于嵌入的指标
质量评估基于对视觉和语言输入学习到的嵌入表示。
文本->分词器->文本编码器->文本嵌入向量
图像->图像编码器->图像嵌入向量
由于所使用的基础模型是通过表示学习进行训练以输出有意义的嵌入,因此可以计算文本和图像嵌入之间的余弦相似度来衡量对齐程度。
在训练强大的文本到图像模型时,文本 - 图像对的嵌入向量通过视觉和语言预训练策略(如 CLIP [24]、BLIP [25]、BLIP - 2 [26])进行对齐。
2.2.2 基于内容的指标
基于内容的指标根据语义内容分析语言和视觉表示,其实际测量是针对分解后的组件分别计算的。
类似于人类的比较方式,例如,阅读提示中的单词并将它们与图像中描绘的区域进行匹配。
文本-图像内容匹配
首先将文本提示分解为子字符串,每个字符串描述不同细节,形成断言集。
接下来有两种方法可以与图像进行匹配。
- 利用视觉问答模型。利用基准数据集的提示模板形式组合提示,比如“{objectA}{空间关系}{objectB}”,然后再借助VQA模型,询问图像中特定元素的存在情况。
- 提取
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









