






在信息科学中的应用
贝叶斯定理在信息科学中应用非常广泛。例如,在机器学习中,可以使用贝叶斯定理计算数据样本属于某个类别的概率,从而实现分类任务。具体来说,可以通过以下步骤实现基于朴素贝叶斯算法的文本分类:
- 将文本转化为词袋模型,并统计每个词出现的次数。
- 计算每个类别的先验概率P(Ci),即所有训练数据中属于该类别的样本数占总样本数的比例。
- 对于每个词 wj,计算在给定类别 Ci 的条件下该词出现的概率 P(wj∣Ci),即在属于该类别的所有样本中,出现该词的样本数占该类别的总样本数的比例。
- 对于每个测试样本 x,计算其属于每个类别的概率P(Ci∣x),并选择概率最大的类别作为该样本的预测类别。
SVM应用
SVM(支持向量机)是一种常见的机器学习算法,其在信息科学中的应用也非常广泛。SVM 的主要思想是寻找一个能够将不同类别的样本分隔开的超平面,从而实现分类任务。具体来说,可以通过以下步骤实现基于 SVM 的二元分类:
- 将原始数据映射到高维空间中。
- 在高维空间中寻找一个能够将不同类别的样本分隔开的超平面,并最大化该超平面与训练数据之间的边缘距离。
- 对于新的测试样本,根据其在高维空间中的映射结果,判断其位于超平面的哪一侧,从而进行分类。
SVM 在实际应用中表现良好,尤其适用于高维度的数据集。
数学原理
首先,我们需要介绍两个概念:函数间隔和几何间隔。
给定一个分类超平面 w^Tx+b=0,样本点 (xi,yi) 到超平面的函数间隔定义为:
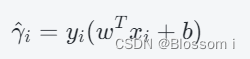
其中,∥⋅∥ 表示向量的模长。显然,几何间隔是函数间隔乘上∥w∥ 的值。同时,几何间隔更能够反映样本点与分类超平面的距离。
SVM 的目标是寻找一个能够将不同类别的样本分隔开的超平面,并最大化该超平面与训练数据之间的边缘距离。因此,可以得到以下优化问题:
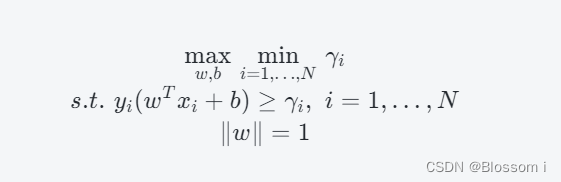
由于约束条件中的 γi 可以通过 γ^i / ∥w∥计算得到,因此可以将其带入到优化问题中,得到等价形式的优化问题:
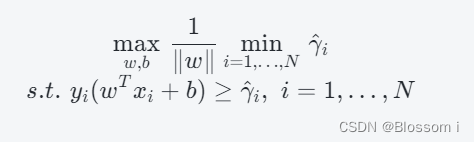
为了解决上述优化问题,可以使用拉格朗日乘子法,并求解其对偶问题:
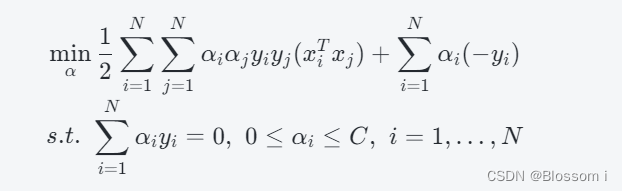
其中,α 是拉格朗日乘子,C 是一个常数。通过求解上述对偶问题,可以得到分类超平面 w^Tx+b=0:
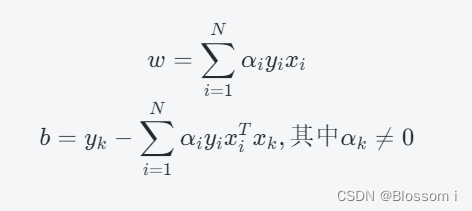
其中,αi 是对应样本点 (xi,yi) 的拉格朗日乘子。将上述分类超平面引入到新的测试样本 x中,可以计算其预测类别:
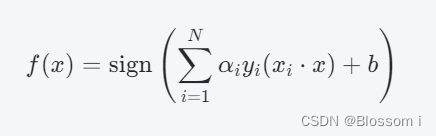
Python代码实现
下面给出在Python中实现 SVM 的示例代码。这里以 sklearn 中自带的 iris 数据集为例,演示如何基于 SVM 实现分类任务。
# 导入相关库
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import svm
# 加载 iris 数据集
iris = datasets.load_iris()
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=0)
# 基于 SVM 进行分类
svm_model = svm.SVC(kernel='rbf', gamma=0.7, C=1.0)
svm_model.fit(X_train, y_train)
print("SVM algorithm accuracy:", svm_model.score(X_test, y_test))
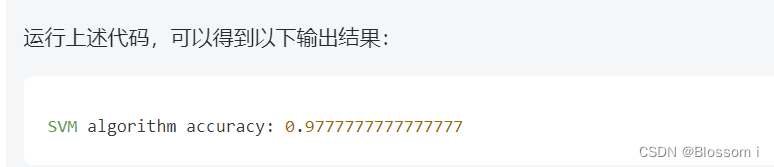
因此,基于 SVM 进行 iris 数据集分类时的准确率为97.78%。















 3151
3151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









