







本章着重对算法部分进行讲解,原理部分不过多叙述,有兴趣的小伙伴可以自行查阅其他文献/文章
一、什么是svm
支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解最大边距超平面(maximum-margin hyperplane) 。
1、支持向量与超平面
在了解svm算法之前,我们首先需要了解一下线性分类器这个概念。比如给定一系列的数据样本,每个样本都有对应的一个标签。为了使得描述更加直观,我们采用二维平面进行解释,高维空间原理也是一样。
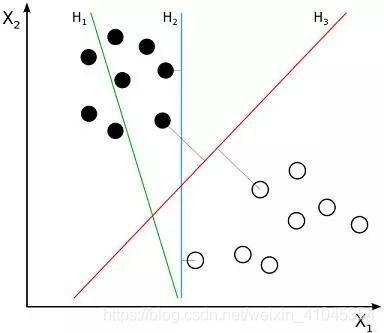
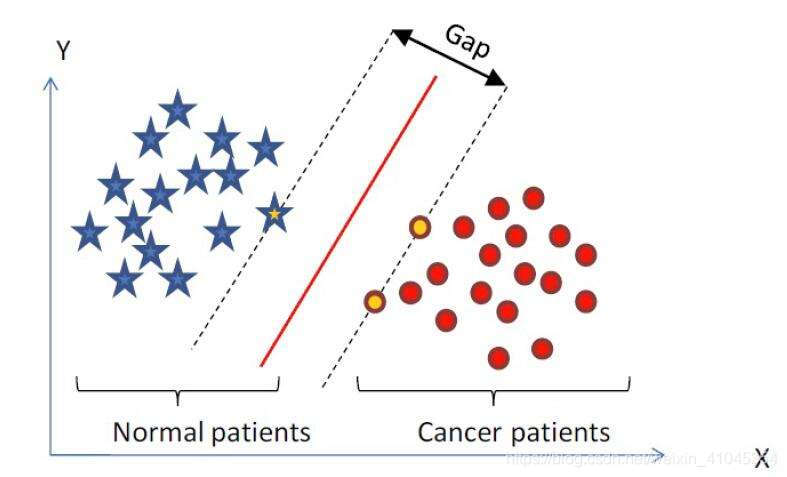
举个例子,假设在一个二维线性可分的数据集中,如下图所示,我们要找到一条线(称为超平面)把两组数据分开,这条直线可以是图中的直线H1,也可以是直线H2,或者H3,但哪条直线才最好呢,也就是说哪条直线能够达到最好的分类效果呢?那就是一个能使两类之间的空间大小最大的一个超平面,即图二中的gap在两个分类之间所占空间最大。
-
这个超平面在二维平面上看到的就是一条直线,在三维空间中就是一个平面,高纬度下以此类推,因此,我们把这个划分数据的决策边界统称为超平面。
-
离这个超平面最近的点就叫做支持向量,
-
点到超平面的距离叫间隔。支持向量机就是要使超平面和支持向量之间的间隔尽可能的大,这样超平面才可以将两类样本准确的分开,而保证间隔尽可能的大就是保证我们的分类器误差尽可能的小,尽可能的健壮。
2、松弛变量
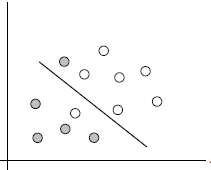
实际分类当中很多样本数据都不能够用一个超平面把数据完全分开。如果数据集中存在噪点的话,那么在求超平的时候就会出现很大问题。从图中课看出灰点和白点并不完全分布于直线两端,如果按正常逻辑去计算超平面,可能得到的间隙会很小甚至无法求出,这时候分类模型就起不到应有的作用,甚至会对新样本进行错误分类。因此我们需要引入一个松弛变量,来允许一些数据样本可以处于超平面错误的一侧。
3、核函数
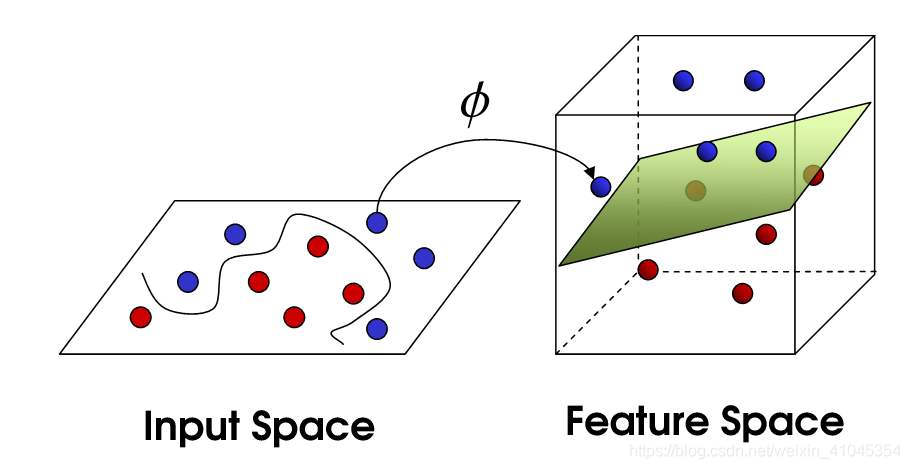
以上讨论的都是在线性可分情况进行讨论的,但是实际问题中给出的数据并不是都是线性可分的,比如有些数据可能是如图样子。
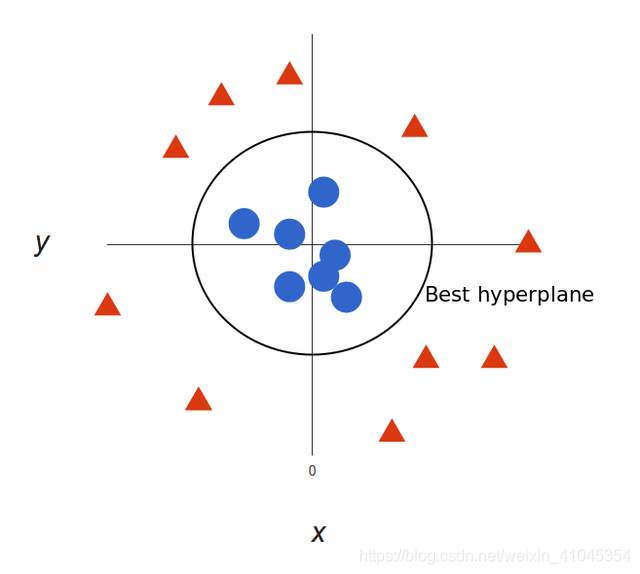
而对于非线性的情况,SVM 的处理方法是选择一个核函数 κernel,通过将数据映射到高维空间,来解决在原始空间中线性不可分的问题。
在线性不可分的情况下,支持向量机首先在低维空间中完成计算,然后通过核函数将输入空间映射到高维特征空间,最终在高维特征空间中构造出最优分离超平面,从而把平面上本身不好分的非线性数据分开。
代码
1、sklearn简单例子
from sklearn import svm
X = [[2, 0], [1, 1], [2, 3]]
y = [0, 0, 1]
clf = svm.SVC(kernel='linear')
clf.fit(X, y)
print(clf)
# 打印支持向量
print(clf.support_vectors_)
# g打印支持向量在数组中的坐标
print(clf.support_ )
# 打印每一类里面有多少个是支持向量
print(clf.n_support_)
结果:
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='linear',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
[[1. 1.]
[2. 3.]]
[1 2]
[1 1]
2、利用pylab画出图像
import numpy as np
import pylab as pl
from sklearn import svm
# 生成40个随机的离散点
np.random.seed(0)
X = np.r_[np.random.randn(20, 2) - [2, 2], np.random.randn(20, 2) + [2 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











