







目录
➢有道词典网页爬取:找到的数据包的Headers,可以记录下请求的相关数据
Urllib基本操作-GET
➢
先导入urllib模块,定义想要访问的网址,使用urlopen()对参数中的URL发送请求
➢
urllib.request.urlopen(
url, data=None, [timeout, ]
*, cafile=None,
capath=None, cadefault=False, context=None)
# 使用urllib来获取百度首页的源码
import
urllib.request
# 1.定义一个url 就是要访问的地址
url =
‘http://www.baidu.com’
# 2.模拟浏览器向服务器发送请求(需要联网) response=响应
response = urllib.request.urlopen(url)
# 3.获取响应中的页面源码 content内容的意思
content = response.read()
# read方法 返回的是字节式的二进制数据
print(content)
# 我们要将二进制数据转换为字符串,二进制-->字符串 解码 decode('编码的格式')
content = response.read().decode(
'utf-8’
)
print(content)
# 使用urllib来获取百度首页的源码
import urllib.request
# 1.定义一个url 就是要访问的地址
url = 'http://www.baidu.com'
# 2.模拟浏览器向服务器发送请求(需要联网) response=响应
response = urllib.request.urlopen(url)
# 3.获取响应中的页面源码 content内容的意思
content = response.read()
print(content)
# read方法 返回的是字节式的二进制数据
# 我们要将二进制数据转换为字符串
# 二进制-->字符串 解码 decode('编码的格式')
content = response.read().decode('utf-8') # 这一步非常重要
# 4.打印数据
print(content)
# #获取状态码 如果是200了,那么就证明我们的逻辑没有错
#print(response.getcode())
#
# #返回url地址
#print(response.geturl())
#
# #获取是一个状态信息
#print(response.getheaders())➢没有进行utf-8编码的输出

➢经过utf-8decode之后的输出

➢ Timeout参数:捕获由于连接超时而引发的异常

# 使用urllib来获取百度首页的源码
import urllib.request
# 1.定义一个url 就是要访问的地址
url = 'http://www.baidu.com'
# 2.模拟浏览器向服务器发送请求(需要联网) response=响应
response = urllib.request.urlopen(url)
# 3.获取响应中的页面源码 content内容的意思
content = response.read()
print(content)
# read方法 返回的是字节式的二进制数据
# 我们要将二进制数据转换为字符串
# 二进制-->字符串 解码 decode('编码的格式')
content = response.read().decode('utf-8') # 这一步非常重要
# # timeout 参数
response = urllib.request.urlopen('http://httpbin.org/get', timeout=1)
print(response.read())
import socket
import urllib.error
#
try:
response = urllib.request.urlopen('http://httpbin.org/get',timeout=0.1)
except urllib.error.URLError as e:
if isinstance(e.reason,socket.timeout):
print('TIME OUT')
# 4.打印数据
print(content)
# #获取状态码 如果是200了,那么就证明我们的逻辑没有错
#print(response.getcode())
#
# #返回url地址
#print(response.geturl())
#
# #获取是一个状态信息
#print(response.getheaders())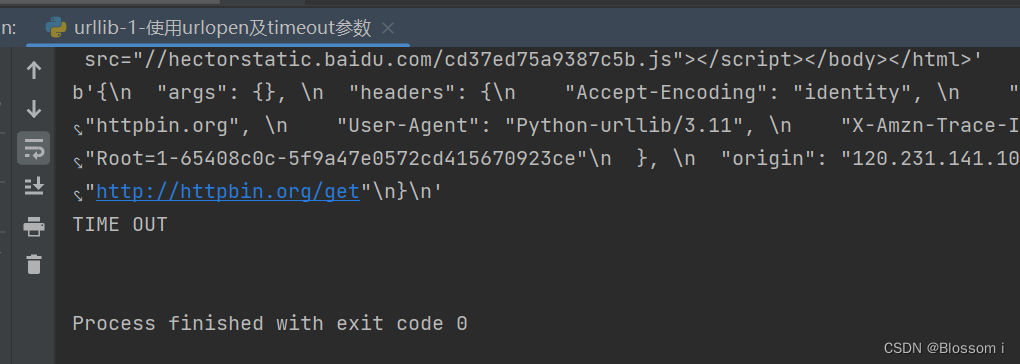
◆Urllib基本操作-定制请求头
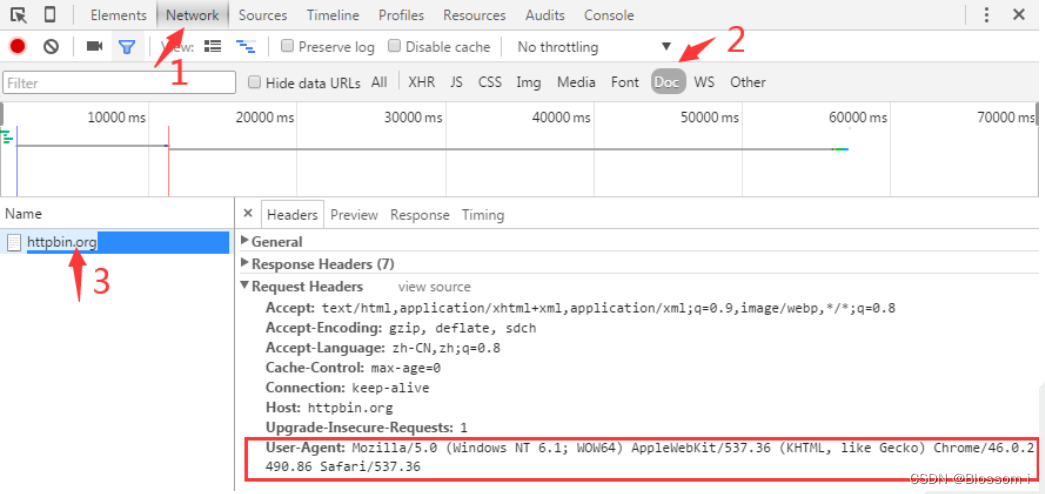
➢ 在爬取网页的时候,输出的信息中有时候会出现“抱歉,无法访问”等字眼,这就是禁止爬取,需要通过定制请求头Headers来解决这个问题。定制Headers是解决requests请求被拒绝的方法之一,相当于我们进入这个网页服务器,假装自己本身在爬取数据。请求头Headers提供了关于请求、响应或其他发送实体的消息,如果没有定制请求头或请求的请求头和实际网页不一致,就可能无法返回正确结果。➢ 获取一个网页的Headers的方法如下:使用360、火狐或谷歌浏览器打开一个网址(比如“http://www.baidu.com”),在网页上单击鼠标右键,在弹出的菜单中选择“查看元素”,然后刷新网页,再按照如图3-4所示的步骤,先点击“Network”选项卡,再点击“Doc”,接下来点击“Name”下方的网址,就会出现类似如下的Headers信息:➢ User-Agent:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/46.0.2490.86 Safari/537.36



➢ 在GET请求中加入访问参数:在百度中搜索北京,获取搜索结果页面• 是否可以直接定义url=https://www.baidu.com/s?wd=北京?• 不可以,默认只搜索ascii编码,没有北京这两个字,所以需要把它变成unicode让机器识别

# #get请求中加入访问参数
import urllib.request
import urllib.parse
#直接复制一些搜索北京的网址:
# https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6
# 需求:获取https://www.baidu.com/s?wd=北京的网页代码
# 是否可以直接定义url=https://www.baidu.com/s?wd=北京?
#不可以,默认只搜索ascii编码,没有北京这两个字,所以需要把它变成unicode让机器识别
# 寻找url
url = "https://www.baidu.com/s?wd="
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.66 Safari/537.36 Edg/103.0.1264.44'
}
# 使用quote方法进行编码转换
name = urllib.parse.quote("北京")
# 组装url
url = url + name
# print(url)
# 请求对象的定制
request = urllib.request.Request(url=url, headers=headers)
# 向服务器发请求
response = urllib.request.urlopen(request)
# 获取响应信息
content = response.read().decode('utf-8')
# 打印响应信息
print(content)
#多于一个参数时,请求头定制
#参数不止有一个,可以用&符号链接多个,假设我们加一个两会。出现一个问题,不仅要把北京编码unicode,还要把两会也编码,可以用quote逐个转换,但效率低,且要拼接。要解决多参数问题,可以用urlencode帮助我们
#urlencode要求里面的参数以字典形式存在,逗号分割

➢ 在GET请求中加入多个访问参数
•
参数不止有一个,可以用&符号在转换后进行链接。
•
为方便解决多参数转换及拼接问题,可以用urlencode帮助我们;urlencode要求里面的参数
以字典形式存在,逗号分割


import urllib.request
import urllib.parse
url = 'https://cn.bing.com/search?'
data={
'go':'搜索',
'q':'北京 天气'
}
new_data = urllib.parse.urlencode(data)
print(new_data)
headers={
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Cookie': 'BIDUPSID=83261851D92939FFFF2D2C3800B6CCA2; PSTM=1574440855; __yjs_duid=1_6e86551c30fb47a64a0c5e667dea7db81620194211269; BD_UPN=12314753; BAIDUID=ED1F16239BBD2AB0CF8AF7923E3A68DE:FG=1; ispeed_lsm=2; BDUSS=XVyNi1XcXZ-eTJCMnhzeURYYUstOGh0T3N1WnN0cTIwRGNrRDczRlJsY2ptMXhqRVFBQUFBJCQAAAAAAAAAAAEAAAD-PGUJt8W~1V9pbmcAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACMONWMjDjVjb; BDUSS_BFESS=XVyNi1XcXZ-eTJCMnhzeURYYUstOGh0T3N1WnN0cTIwRGNrRDczRlJsY2ptMXhqRVFBQUFBJCQAAAAAAAAAAAEAAAD-PGUJt8W~1V9pbmcAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACMONWMjDjVjb; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BA_HECTOR=8l0g0l2ga00h25a52g81dkhm1hk9pd81a; BAIDUID_BFESS=ED1F16239BBD2AB0CF8AF7923E3A68DE:FG=1; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; delPer=0; BD_CK_SAM=1; PSINO=7; ZFY=SR4hfozWRIXmU7ouv2ASem0KdSz0WImntiWy4T8Nftw:C; BD_HOME=1; baikeVisitId=53b5daaa-05ec-4fc4-b9d5-a54ea3e0658d; H_PS_PSSID=37542_36559_37561_37550_37299_36885_34813_37486_37402_36805_37406_36786_37482_37497_26350_37365_37455; H_PS_645EC=878fjGnEi%2FQTHR5lTn8cql%2FqGCKSJk5xVRVe%2FWpoH2dRPvRJayxDhPJv8U3BoEGTXa%2Bd; COOKIE_SESSION=1103_9_9_9_19_6_0_0_9_2_0_0_2611_8863_3_0_1665474424_1665471813_1665474421%7C9%23358_1132_1665459981%7C9; BDSVRTM=0'
}
url=url+new_data
print(url)
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
◆Urllib基本操作-POST
➢ urllib.request模块实现发送POST请求获取网页内容的实例➢ post请求的参数,一定要先进行编码,使用url.parse.urlencode,返回值类型是字符串类型➢ 编码结果还需要转换成byte类型:之前定义的data是字符串类型。而发送请求的request中,要求的data是byte字节型(否则urlopen时报错)可以使用data = bytes(data, ‘utf-8’) 也可以 data = data.encode('utf-8')➢ 与GET请求不同,post参数不是直接拼在url后面,而是放在请求对象的参数里面
➢有道词典网页爬取:找到的数据包的Headers,可以记录下请求的相关数据
➢
请求链接https://dict.youdao.com/jsonapi_s?doctype=json&jsonversion=4
➢
请求方式:POST请求头




import urllib.request
import urllib.parse
# 请输入您要翻译的内容
content ='你好' #最后用input('请输入您要翻译的内容:')替代'你好'
url = 'https://dict.youdao.com/jsonapi_s?doctype=json&jsonversion=4'
headers = {
"Cookie": 'OUTFOX_SEARCH_USER_ID=-1124603977@10.108.162.139; JSESSIONID=aaamH0NjhkDAeAV9d28-x; OUTFOX_SEARCH_USER_ID_NCOO=1827884489.6445506; fanyi-ad-id=305426; fanyi-ad-closed=1; ___rl__test__cookies=1649216072438',
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36"
}
# 携带数据
data = {
'q': content,
'le': 'ja',
't': '9',
'client': 'web',
'sign': '520a657bfae6f88b2deaa67067865128',
'keyfrom': 'webdict',
}
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url, data=data)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
print('翻译结果:\n', html)

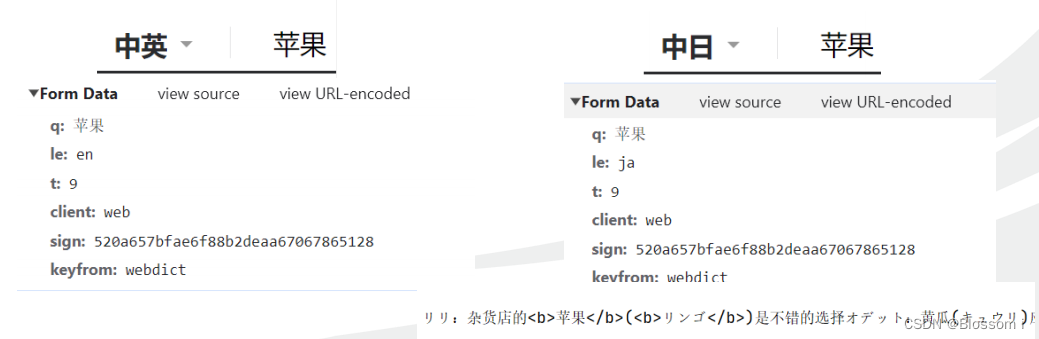
➢查看请求携带参数
当我们查询的词不一样的时候,sign这个参数会不同

当我们查询的所用语言不一样的时候,le这个参数会不同
Urllib3
➢
urllib3是一个功能强大、条理清晰、用于HTTP客户端的Python库,许多Python的
原生系统已经开始使用urllib3。urllib3提供了很多python标准库里所没有的重要特
性,包括:线程安全、连接池、客户端SSL/TLS验证、文件分部编码上传、协助处
理重复请求和HTTP重定位、支持压缩编码、支持HTTP和SOCKS代理、100%测试
覆盖率等。
➢
在使用urllib3之前,需要打开一个cmd窗口使用如下命令进行安装
pip install urllib3◆Urllib3完成get请求

import urllib3
http=urllib3.PoolManager()
response=http.request('GET','http://www.baidu.com'
)
print(response.status)
print(response.data)















 3236
3236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









