







数据集简介
该数据集包含美国人口普查局收集的美国马萨诸塞州波士顿住房价格的有关信息, 数据集很小,只有506个案例。
- CRIM–城镇人均犯罪率
- ZN - 占地面积超过25,000平方英尺的住宅用地比例
- INDUS - 每个城镇非零售业务的比例
- CHAS - Charles River虚拟变量(如果是河道,则为1;否则为0)
- NOX - 一氧化氮浓度(每千万份)
- RM - 每间住宅的平均房间数
- AGE - 1940年以前建造的自住单位比例
- DIS -波士顿的五个就业中心加权距离
- RAD - 径向高速公路的可达性指数
- TAX - 每10,000美元的全额物业税率
- PTRATIO - 城镇的学生与教师比例
- B - 1000(Bk - 0.63)^ 2其中Bk是城镇黑人的比例
- LSTAT - 人口状况下降%
- MEDV - 自有住房的中位数报价, 单位1000美元
其中RM - 每间住宅的平均房间数比较重要
数据集下载地址:http://t.cn/RfHTAgY
载入数据
from sklearn import datasets
# 加载波士顿房子数据集
boston = datasets.load_boston()
print(boston.DESCR) # 查看数据描述

共有506个样本,14个特征,其中一个作为标签
展示数据特征散点图分布
import matplotlib.pyplot as plt
X = boston.data # 样本特征
y = boston.target # 样本标签
# 从图中发现,房价超过50万的样本可能有异常
plt.scatter(X[:,5],y)
plt.show()
从图中发现,房价超过50万的样本可能存在异常
缩小样本范围
X = X[y<50.0] # 选择房价小于50万的样本特征
y = y[y<50.0] # 选择房价小于50万的样本标签
拆分数据集
from sklearn.model_selection import train_test_split
# 拆分数据集
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=666)
特征标准化处理
# 特征标准化处理
from sklearn.preprocessing import StandardScaler
std = StandardScaler()
# 对训练样本集进行特征标准化处理
X_train_standard = std.fit_transform(X_train)
# 对测试样本集进行特征标准化处理,要注意这里不能fit了!
X_test_standard = std.transform(X_test)
训练拟合模型
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
# 使用标准化后的训练样本集进行拟合学习(建立合适的线性回归模型)
lin_reg.fit(X_train_standard,y_train)
# 在测试集上测试模型的优劣,使用的是R^2标准
print(lin_reg.score(X_test_standard,y_test))

能源效能数据的相关分析的线性回归模型
导入模块及一些设置
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
from sklearn import datasets
import pandas as pd
# 解决绘图中文乱码问题
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决绘图负号问题
matplotlib.rcParams['axes.unicode_minus']=False
# 设置绘图字体
sns.set(font= "Kaiti",style="ticks",font_scale=1.4)
查看部分数据集
# 读取数据
enbdf = pd.read_excel("ENB.xlsx")
# 对每个变量的取值进行标准化
enbdf_n = (enbdf - enbdf.mean()) / enbdf.std()
enbdf_n.head()

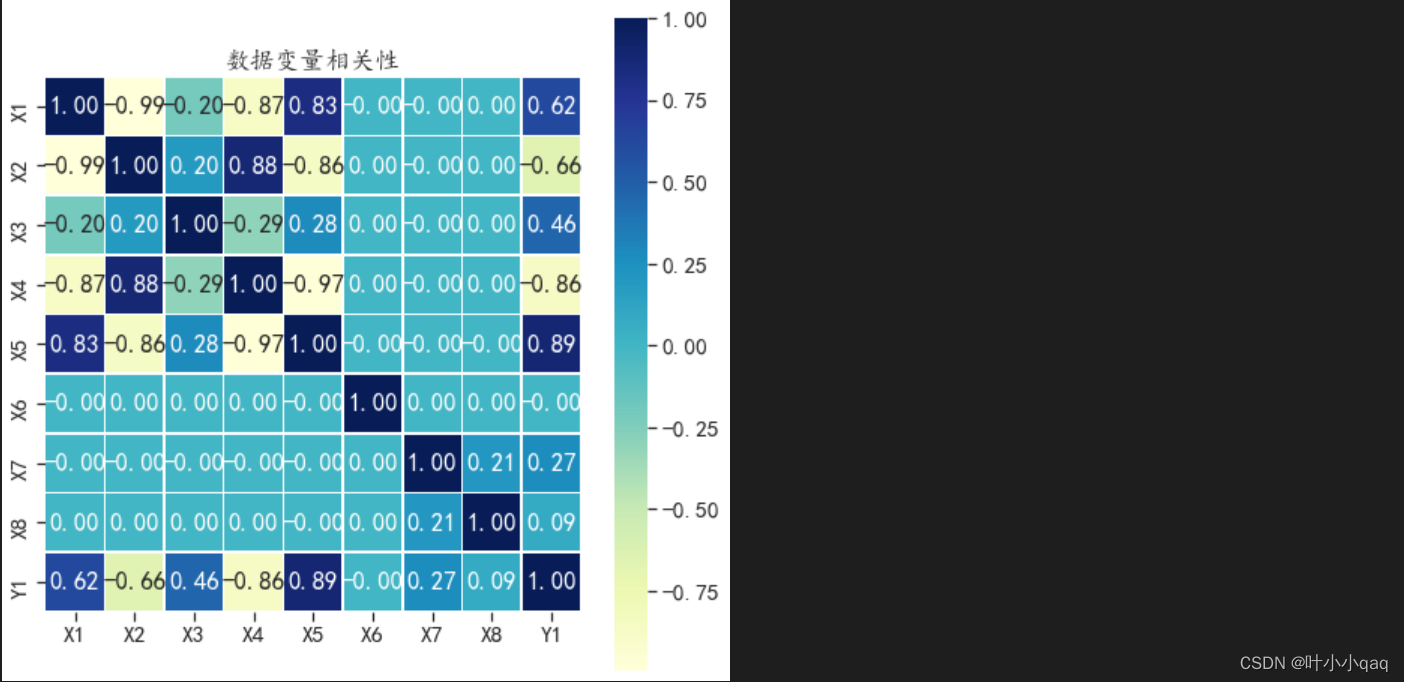
绘制相关系数热力图
# 使用相关系数热力图可视化变量之间的相关性
datacor = enbdf_n.corr() # 默认计算pearson相关系数
# 热力图可视化相关系数
plt.figure(figsize=(8,8))
# annot参数:默认为False,为True的话,会在格子上显示数字
ax = sns.heatmap(datacor,square=True,annot=True,fmt=".2f",
linewidths=.5,cmap="YlGnBu")
ax.set_title("数据变量相关性")
plt.show()
拆分数据集
X = np.array(enbdf_n)[:,:-1] # 样本特征
y = np.array(enbdf_n)[:,-1] # 样本标签
from sklearn.model_selection import train_test_split
# 拆分数据集
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=666)
训练拟合模型并预测
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X_train,y_train) # 使用训练集拟合模型
print(lin_reg.score(X_test,y_test)) # 使用测试集测试模型的优劣

完整代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
# 加载波士顿房子数据集
boston = datasets.load_boston()
print(boston.DESCR) # 查看数据描述
X = boston.data # 样本特征
y = boston.target # 样本标签
# 从图中发现,房价超过50万的样本可能有异常
plt.scatter(X[:,5],y)
plt.show()
X = X[y<50.0] # 选择房价小于50万的样本特征
y = y[y<50.0] # 选择房价小于50万的样本标签
# 拆分数据集
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=666)
# 特征标准化处理
std = StandardScaler()
# 对训练样本集进行特征标准化处理
X_train_standard = std.fit_transform(X_train)
# 对测试样本集进行特征标准化处理,要注意这里不能fit了!
X_test_standard = std.transform(X_test)
lin_reg = LinearRegression()
# 使用标准化后的训练样本集进行拟合学习(建立合适的线性回归模型)
lin_reg.fit(X_train_standard,y_train)
# 在测试集上测试模型的优劣,使用的是R^2标准
print(lin_reg.score(X_test_standard,y_test))
# ---------------能源效能数据的相关分析的线性回归模型
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
from sklearn import datasets
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# 解决绘图中文乱码问题
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决绘图负号问题
matplotlib.rcParams['axes.unicode_minus']=False
# 设置绘图字体
sns.set(font= "Kaiti",style="ticks",font_scale=1.4)
# 读取数据
enbdf = pd.read_excel("ENB.xlsx")
# 对每个变量的取值进行标准化
enbdf_n = (enbdf - enbdf.mean()) / enbdf.std()
enbdf_n.head()
# 使用相关系数热力图可视化变量之间的相关性
datacor = enbdf_n.corr() # 默认计算pearson相关系数
# 热力图可视化相关系数
plt.figure(figsize=(8,8))
# annot参数:默认为False,为True的话,会在格子上显示数字
ax = sns.heatmap(datacor,square=True,annot=True,fmt=".2f",
linewidths=.5,cmap="YlGnBu")
ax.set_title("数据变量相关性")
plt.show()
X = np.array(enbdf_n)[:,:-1] # 样本特征
y = np.array(enbdf_n)[:,-1] # 样本标签
# 拆分数据集
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=666)
lin_reg = LinearRegression()
lin_reg.fit(X_train,y_train) # 使用训练集拟合模型
print(lin_reg.score(X_test,y_test)) # 使用测试集测试模型的优劣
欢迎评论指正!
















 2004
2004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











