







目录
1、vector基本概念
- vector是表示可变大小数组的序列容器。
- 就像数组一样,vector也采用的连续存储空间来存储元素。也就是意味着可以采用下标对vector的元素进行访问,和数组一样高效。但是又不像数组,它的大小是可以动态改变的,而且它的大小会被容器自动处理。
- 本质讲,vector使用动态分配数组来存储它的元素。当新元素插入时候,这个数组需要被重新分配大小。为了增加存储空间。其做法是,分配一个新的数组,然后将全部元素移到这个数组。就时间而言,这是一个相对代价高的任务,因为每当一个新的元素加入到容器的时候,vector并不会每次都重新分配大小。
- vector分配空间策略:vector会分配一些额外的空间以适应可能的增长,因为存储空间比实际需要的存储空间更大。不同的库采用不同的策略权衡空间的使用和重新分配。但是无论如何,重新分配都应该是对数增长的间隔大小,以至于在末尾插入一个元素的时候是在常数时间的复杂度完成的。
- 因此,vector占用了更多的存储空间,为了获得管理存储空间的能力,并且以一种有效的方式动态增长。
- 与其它动态序列容器相比(deques, lists and forward_lists), vector在访问元素的时候更加高效,在末尾添加和删除元素相对高效。对于其它不在末尾的删除和插入操作,效率更低。比起lists和forward_lists统一的迭代器和引用更好。
2、vector的使用
2.1、vector的定义
(constructor)构造函数声明 接口说明 1、vector() (重点)
无参构造 2、vector(size_type n, const value_type& val = value_type()) 构造并初始化n个val 3、vector (const vector& x)(重点) 拷贝构造 4、vector (InputIterator first, InputIterator last) 使用迭代器进行初始化构造 示例说明:
- 1、vector() 无参构造
vector<int> v1; //存储int类型数据 v1.push_back(1); v1.push_back(2); v1.push_back(3); v1.push_back(4); vector<double> v2; //存储double类型数据 v2.push_back(1.1); v2.push_back(2.2); v2.push_back(3.3); vector<string> v3; //存储string类型数据 v3.push_back("李白"); v3.push_back("杜甫"); v3.push_back("苏轼"); v3.push_back("白居易");
- 2、vector(size_type n, const value_type& val = value_type())构造并初始化n个val
vector<int> v4(10, 5); //用10个5初始化v4
- 3、vector (const vector& x) 拷贝构造
vector<int> v4(10, 5); //用10个5初始化v4 vector<int> v5(v4); //用v4去拷贝构造v5
- 4、vector (InputIterator first, InputIterator last) 使用迭代器进行初始化构造
vector<string> v6(++v3.begin(), --v3.end());string s = "hello world"; vector<char> v(s.begin(), s.end());
2.2、vector的遍历
接口名称 使用说明 1、operator[ ] 下标+[ ] 2、迭代器 begin+end或rbegin+rend 3、范围for 底层还是迭代器实现 operator [ ]
operator[ ]就是对[ ]的重载,我们可以像数组那样利用下标+[ ]去访问元素。
void test() { vector<int> v; v.push_back(1); v.push_back(2); v.push_back(3); v.push_back(4); for (size_t i = 0; i < v.size(); i++) { v[i] += 1; cout << v[i] << " "; // 2 3 4 5 } }迭代器
vector的迭代器和string的迭代器几乎一致。
iterator的使用 接口说明 1、begin+end begin获取第一个数据位置的iterator/const_iterator,
end获取最后一个数据的下一个位置的iterator/const_iterator
2、rbegin+rend rbegin获取最后一个数据位置的reverse_iterator,
rend获取第一个数据前一个位置的reverse_iterator
- 正向迭代器:
//遍历 void test_vector2() { vector<int> v; v.push_back(1); v.push_back(2); v.push_back(3); v.push_back(4); //迭代器 vector<int>::iterator vit = v.begin(); while (vit != v.end()) { *vit -= 1; cout << *vit << " "; // 0 1 2 3 ++vit; } cout << endl; }
- 反向迭代器:
void test_vector2() { vector<int> v; v.push_back(1); v.push_back(2); v.push_back(3); v.push_back(4); vector<int>::reverse_iterator vit = v.rbegin(); while (vit != v.rend()) { cout << *vit << " "; vit++; } cout << endl; }范围for
范围for的底层就是替换了迭代器。
3、范围for void test() { vector<int> v; v.push_back(1); v.push_back(2); v.push_back(3); v.push_back(4); //3、范围for for (auto e : v) { cout << e << " "; //1 2 3 4 } }

2.3、vector的空间增长问题
容量空间 接口说明 1、size
获取数据个数 2、capacity 获取容量大小 3、max_size 获取做大储存元素个数 4、resize 改变vector中的size 5、reserve 改变vector中的capacity
6、empty
判断是否为空 7、shrink_to_fit
缩容量
size和capacity
vector中的size是用来获取有效数据个数,capacity是获取容量大小。
void test() { vector<int> v(10, 5); cout << v.size() << endl; //10 cout << v.capacity() << endl; //10 }
max_size
max_size的作用是返回vector容器可以容纳的最大元素个数。用类型最大值除以sizeof(类型)。
void test() { vector<int> v1; cout << v1.max_size() << endl;//1073741823 vector<char> v2; cout << v2.max_size() << endl;//2147483647 }
reserve和resize
reserve和resize我们在string哪里已经讲过,这里我们再简要回顾并补充一下:
- 测试代码:
void test() { size_t sz; std::vector<int> foo; sz = foo.capacity(); std::cout << "making foo grow:\n"; for (int i = 0; i < 100; ++i) { foo.push_back(i); if (sz != foo.capacity()) { sz = foo.capacity(); std::cout << "capacity changed: " << sz << '\n'; } } }
- 测试结果:
同样一份代码在vs和linux下分别运行我们可以发现:vs下capacity是大致按照1.5倍进行增长的,而g++是按照2倍增长的。vs是PJ版本STL,g++是SGI版本STL。
- 为什么要按照1.5倍或2倍进行扩容呢?
答:合适。单次增容越多,插入N个值增容的次数就越少,效率就越高,但是浪费空间就比较多。单次增容越少,就会导致频繁扩容,效率低下。增容1.5倍或2倍是比较合适的做法。
下面我们提前用reserve开辟好空间:
我们再用resize进行对比一下:
相比于reserve,resize进行了两次扩容。这是因为reserve只开辟空间,而resize即开辟空间又进行初始化。



shrink_to_fit
作用:请求容器减小其容量以适应其大小。
我们看代码示例:
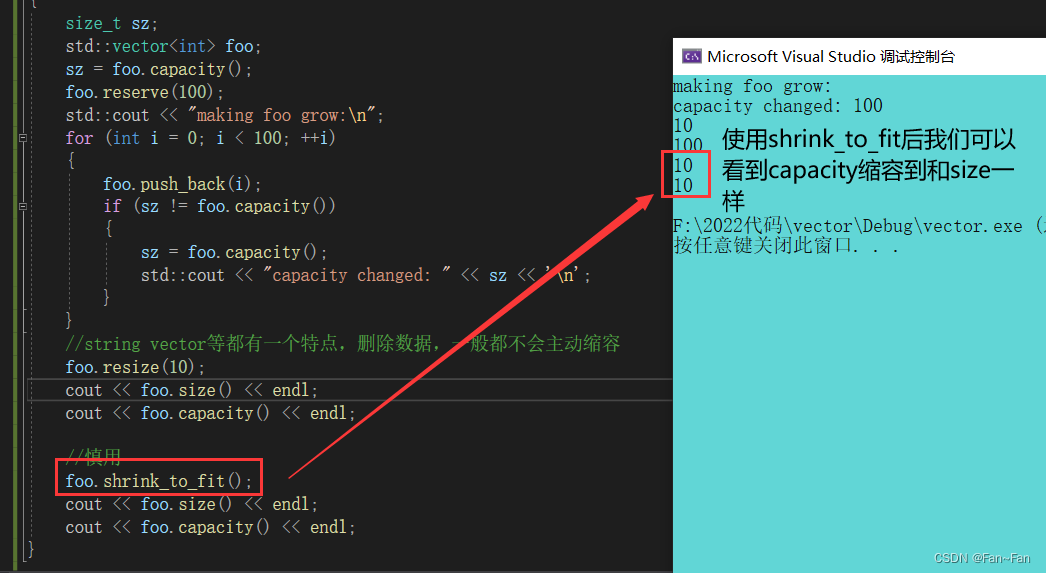
void test() { size_t sz; std::vector<int> foo; sz = foo.capacity(); foo.reserve(100); std::cout << "making foo grow:\n"; for (int i = 0; i < 100; ++i) { foo.push_back(i); if (sz != foo.capacity()) { sz = foo.capacity(); std::cout << "capacity changed: " << sz << '\n'; } } //string vector等都有一个特点,删除数据,一般都不会主动缩容 foo.resize(10); cout << foo.size() << endl; cout << foo.capacity() << endl; //慎用 foo.shrink_to_fit(); cout << foo.size() << endl; cout << foo.capacity() << endl; }
- shrink_to_fit 接口要慎用,因为用它是要付出代价的。
- 我们再插入数据后又要频繁扩容。
- 假如我们的capacity==100,我们将其缩小到10,并非是把后90个空间返还给操作系统,操作系统的空间并不允许一部分一部分的返还。而是直接再开辟十个元素大小的空间,然后将前十个元素拷贝过去。最后将100个元素大小的空间返还给操作系统。

2.4、vector的增删查改
vector增删查改 接口说明 1、push_back
尾插 2、pop_back
尾删 3、insert 在下标为pos前面插入val 4、erase 删除下标为pos的值
5、find 查找。(注意这个是算法模拟实现,不是vector的成员接口) 6、sort 排序。(注意这里也不是vector的函数接口,只是用于排序)
push_back和pop_back
这两个接口和string类的并没有什么区别,尾插和尾删
void test() { vector<int> v; v.push_back(1); v.push_back(10); v.pop_back(); v.pop_back(); }
insert和erase
- vector的insert和erase和string所不同的是其返回值返回的是迭代器,其作用是为了解决迭代器失效的问题,这个我们后续会讲到。并且其参数一般为迭代器,并非下标。
- 测试代码
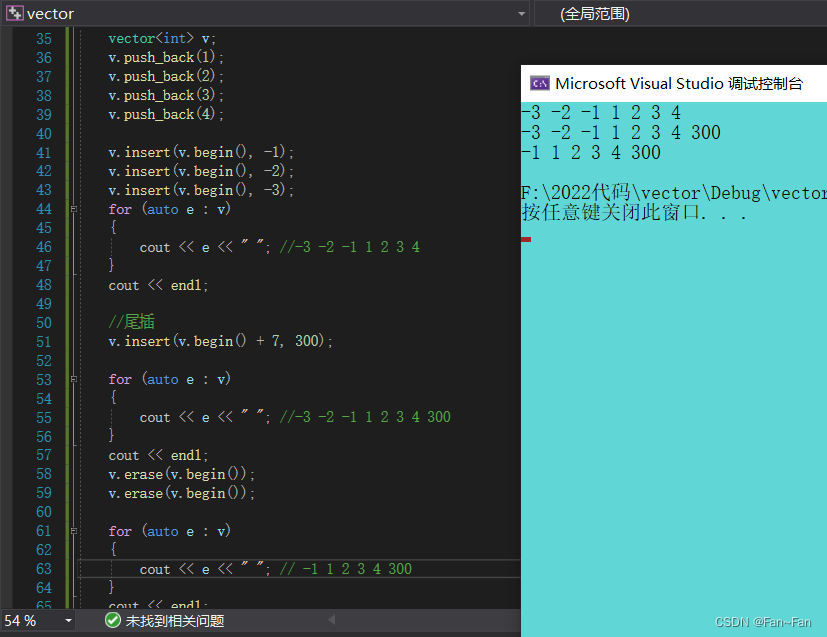
void test() { vector<int> v; v.push_back(1); v.push_back(2); v.push_back(3); v.push_back(4); v.insert(v.begin(), -1); v.insert(v.begin(), -2); v.insert(v.begin(), -3); for (auto e : v) { cout << e << " "; //-3 -2 -1 1 2 3 4 } cout << endl; //尾插 v.insert(v.begin() + 7, 300); for (auto e : v) { cout << e << " "; //-3 -2 -1 1 2 3 4 300 } cout << endl; v.erase(v.begin()); v.erase(v.begin()); for (auto e : v) { cout << e << " "; // -1 1 2 3 4 300 } cout << endl; }


find
这里的find并不是vector的成员函数,这个是复用算法库里面的find。
算法库头文件:<algorithm>
这里的find的查找原理本质就是在一段左闭右开的迭代器区间去寻找一个值。找到了就返回它的迭代器,找不到就返回它的开区间那个迭代器。
void test() { vector<int> v; v.push_back(1); v.push_back(2); v.push_back(3); v.push_back(4); //vector<int>::iterator pos=find(v.begin(),v.end(),3); auto pos = find(v.begin(), v.end(), 3); //调用find在左闭右开区间寻找val if (pos != v.end()) { cout << "找到了" << endl; v.erase(pos); //找到后把该值删掉 } else { cout << "没有找到" << endl; } for (auto e : v) { cout << e << " "; //1 2 4 } cout << endl; }

sort
我们用算法库里面的sort函数将vector里面的数据进行排序。
void test() { vector<int> v; v.push_back(1); v.push_back(4); v.push_back(6); v.push_back(2); v.push_back(5); v.push_back(3); //sort默认是升序 sort(v.begin(), v.end()); for (auto e : v) { cout << e << " "; //1 2 3 4 5 6 } cout << endl; //要排降序,我们就要用到仿函数,我们后面会讲到。仿函数包头文件<functional> sort(v.begin(), v.end(), greater<int>()); for (auto e : v) { cout << e << " "; //6 5 4 3 2 1 } cout << endl; }

















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









