






目录
13:为什么有的写 (*p).age,有的写 p->name?
15:智能指针(Smart Pointer)和原始指针(Raw Pointer)的区别
三:struct 的用法,以及为何用 struct 而不是 class?
四:如何在同一个项目中执行不同的main?除了把之前写的代码注释掉之外还有什么办法吗?
六:using namespace std; 什么时候不适用?
八:原生数组T a[N],std::array ,std::vector (动态数组)
六:Encoding, UTF-8和Unicode是什么?UTF-8属于Unicode吗?
十一:除了main()前面的这一块属于全局作用域,其他的任何.h或者是.cpp文件中只要在任何函数、类或命名空间之外的那块最外层区域都属于全局作用域?
C++基础概念整理及提问
以下是我个人在学习C++的时候所遇到问题和概念的一个整理,以下是基础篇
C++开发者应该掌握的能力
作为一名 C++ 开发者,除了熟练掌握语言语法外,需要在以下几个方面具备扎实的能力和实践经验:
1. 语言基础与现代特性
- C++ 核心语法:基本类型、指针与引用、作用域规则、函数与重载、构造/析构函数、拷贝/移动语义。
- 面向对象编程:类/继承/多态、虚函数、纯虚接口、抽象类、访问控制。
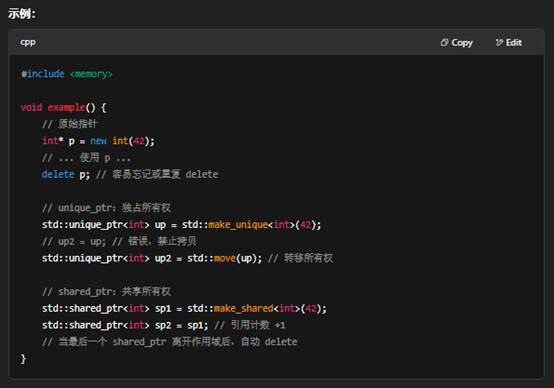
- RAII 与资源管理:RAII 原则、智能指针(std::unique_ptr、std::shared_ptr)、自定义 deleter。
- 模板与泛型编程:函数/类模板、模板特化、模板元编程(constexpr、类型萃取)。
- 现代 C++(C++11/14/17/20/23):
- auto、范围 for、初始化列表
- Lambda 表达式、函数对象
- constexpr, noexcept
- 移动语义(std::move、std::forward)
- 并发库(<thread>、<mutex>、<atomic>)
- 协程(C++20)与概念(Concepts)
2. 标准库与常用数据结构/算法
- STL 容器:std::vector、std::list、std::deque、std::map、std::unordered_map、std::string 等。
- 算法与迭代器:排序、查找、变换、std::algorithm 中的高阶算法(如 std::transform、std::accumulate)。
- 容器适配器:std::stack、std::queue、std::priority_queue。
- 复杂度分析:理解时间/空间复杂度,能够根据场景选择合适的结构。
3. 构建系统与工具链
- 构建工具:CMake(最常用)、Makefile、Ninja 等;能编写跨平台的 CMake 脚本。
- 编译器与链接:GCC/Clang/MSVC,不同编译器的宏、编译选项、ABI 差异;动态库(.dll/.so)与静态库(.lib/.a)的使用。
- 版本控制:Git(分支管理、冲突解决、PR 流程),必要时也熟悉 SVN、Perforce。
- 包管理:Conan、vcpkg 等 C/C++ 包管理工具。
4. 调试、测试与质量保证
- 调试技巧:gdb、Visual Studio 调试器、断点/条件断点、调用栈分析、核心转储(core dump)。
- 内存与线程检查:Valgrind(内存泄漏检测)、AddressSanitizer、ThreadSanitizer。
- 单元测试:Google Test、Catch2 或 Boost.Test;TDD(测试驱动开发)流程。
- 静态与动态分析:clang-tidy、cppcheck、Coverity,代码覆盖率工具(gcov、lcov)。
- 代码规范与自动格式化:clang-format、CPPCHECK,遵循公司/社区的编码规范(如 Google C++ Style)。
5. 性能优化与底层原理
- 性能分析:采样分析(Sampling Profiler)、Instrumentation(插桩)、Linux perf、Visual Studio Profiler。
- 缓存与内存布局:理解 CPU 缓存(L1/L2/L3)、连续/分散内存访问的性能差异。
- 并发与锁优化:避免锁竞争、读写锁(shared_mutex)、无锁编程(原子操作)。
- SIMD 与向量化:使用编译器自动向量化、手写 SSE/AVX 指令加速关键代码。
- 内存分配器:自定义内存池、对象池以减少频繁分配/释放开销。
6. 操作系统与网络编程
- 操作系统机制:进程/线程模型、系统调用、文件 I/O、内存映射(mmap)。
- Socket 网络:TCP/UDP 编程、阻塞/非阻塞 I/O、select/poll/epoll 机制;或使用 boost::asio。
- 跨平台注意事项:字节序(Endian)、目录分隔符、动态库加载(dlopen/LoadLibrary)。
7. 常用第三方库与框架
- Boost:常用模块(Boost.Asio、Boost.Filesystem、Boost.Serialization、Boost.Spirit)。
- GUI/游戏引擎:Qt、MFC、wxWidgets;或 Unreal Engine、Unity Native Plugin 开发。
- 序列化与消息:Protocol Buffers、FlatBuffers、JSON(RapidJSON)、XML(TinyXML2)。
- 日志框架:spdlog、log4cplus、glog。
8. 软件工程实践与软技能
- 设计模式:常见的 GoF 模式(工厂、单例、策略、观察者等)及在 C++ 中的应用。
- 架构能力:模块化设计、分层架构、接口与实现分离(PImpl)、依赖注入。
- 文档与沟通:撰写设计文档、代码注释;跨团队沟通与需求澄清。
- 敏捷/DevOps:Scrum/Kanban 流程,持续集成与持续部署(CI/CD)。
- 持续学习:关注 ISO C++ 标准进程、阅读优秀开源项目源代码(如 LLVM、Qt)。
小贴士:
- 从基础到进阶,建议先牢固掌握 C++14 核心特性,再逐步学习 C++17/20。
- 通过参与开源项目、代码审查与实践,快速提升代码质量和架构视野。
- 定期复盘自己的项目,从需求分析、设计、编码、测试到优化,形成闭环。
希望这些要点能帮助你规划 C++ 学习路线,全面提升从语言、工具到工程实践的综合能力。祝学习顺利!
C++学习推荐路线
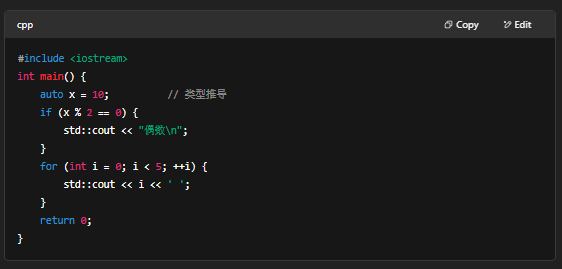
1. 基础语法与流程控制
- 变量与基本类型:int、double、bool、char、auto
- 运算与表达式
- 分支与循环:if/else、switch、for、while、do…while
- 示例:
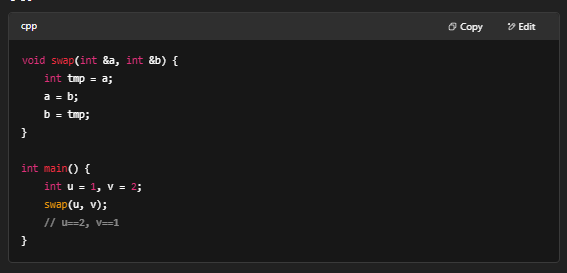
2. 指针与引用
- 指针(Pointer):地址运算符 &、解引用 *
- 引用(Reference):语法糖,常用于函数参数
- 示例:
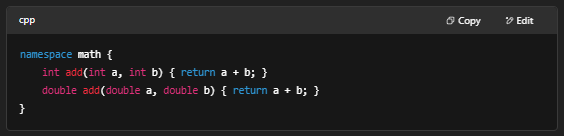
3. 函数与作用域
- 函数重载、默认参数
- 内联函数 (inline)
- 命名空间 (namespace) 防止命名冲突
- 示例:
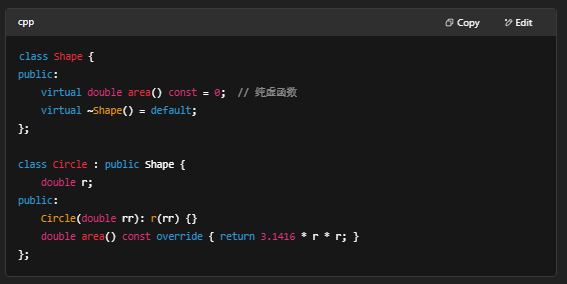
4. 面向对象(OOP)
- 类与对象:成员变量、成员函数
- 构造函数 / 析构函数
- 继承、多态(虚函数)
- 封装与访问控制 (public/protected/private)
- 示例:
5. 模板与泛型编程
- 函数模板、类模板
- 模板实参推导
- 示例:

6. 标准库(STL)
- 容器:vector、list、map、unordered_map…
- 算法:std::sort、std::find_if…
- 迭代器:与容器结合使用
- 示例:
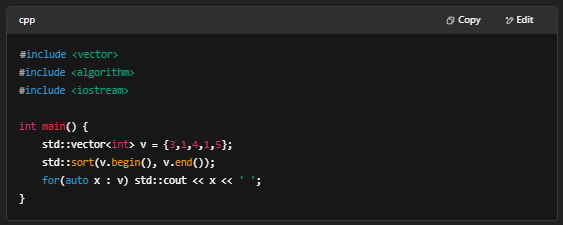
7. 现代 C++ 特性(C++11 及以后)
- 智能指针:std::unique_ptr、std::shared_ptr
- 移动语义:std::move、右值引用 T&&
- Lambda 表达式
- 范围 for、auto、constexpr、enum class
- 示例(Lambda):
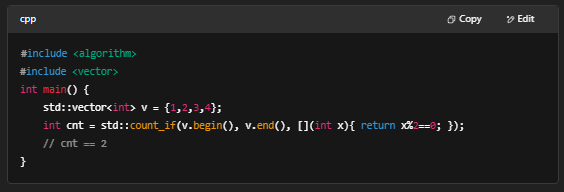
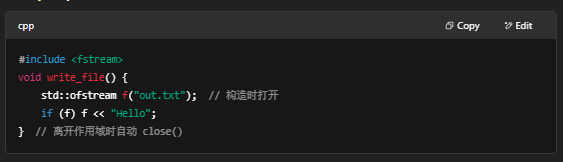
8. 内存与资源管理
- 动态分配:new / delete
- RAII(Resource Acquisition Is Initialization)
- 示例(RAII):
C++基础概念
函数
什么是函数(Function)?
概念
函数是一段具有独立功能的可重用代码块,可以接收零个或多个参数,对其进行处理,并(可选地)向调用者返回一个值。
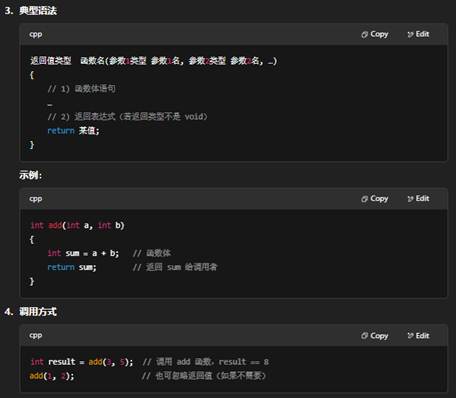
组成要素
- 返回值类型:指明函数执行后返回的数据类型(没有返回值则用 void)。
- 函数名:用来标识和调用该函数的名字。
- 参数列表:被调用时传入的变量列表,每个参数需指定类型。
- 函数体:由一对花括号 { … } 包围的语句块,完成具体操作。
- 返回表达式:通过 return 将值传递给调用者(如果返回类型为 void,则可省略)。

函数和class和void有什么不同
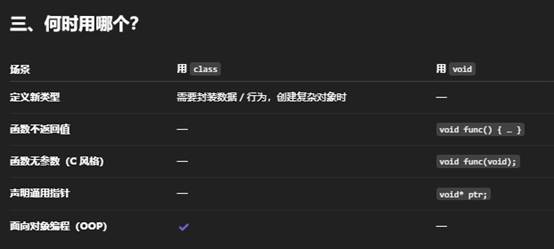
下面从“本质定义”、“用途”与“在代码中如何使用”三个维度,简单对比函数(Function)、类(class)和 void 三者的不同。
| 维度 | 函数(Function) | 类(class) | void |
| 本质定义 | 一段可复用的、具有输入(参数)和(可选)输出(返回值)的逻辑单元 | 用户自己定义的一种复合类型(Blueprint),封装数据和相关操作 | 一种特殊的“无类型”标识: |
| 用途 | 执行某项具体任务(计算、I/O、状态修改等),并可把结果反馈给调用者 | 描述并创建“对象”,管理状态(成员变量)与行为(成员函数) | 修饰函数签名: |
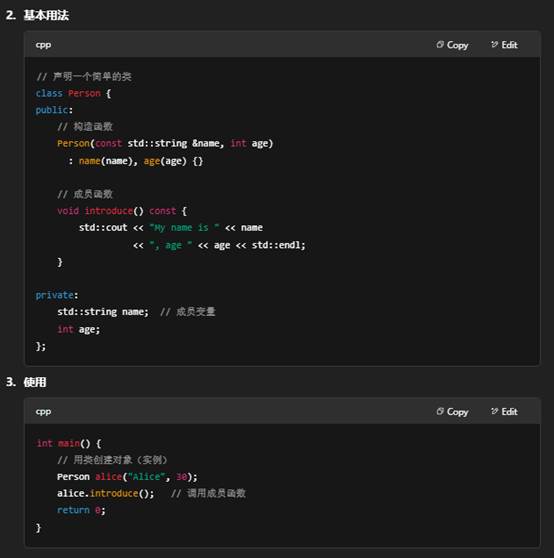
| 在代码中使用 | cpp<br>int add(int a,int b){ return a+b; }<br>…add(1,2); | cpp<br>class Person{<br> public:<br> void greet();<br> private:<br> string name;<br>};<br>Person p; p.greet(); | cpp<br>void sayHi(){ cout<<"Hi"; }<br>void foo(void); // C 风格,无参<br>void* buf; // 通用指针 |
| 与其它的关系 | – 可以返回任何类型(包括自定义的类类型) | – 可以包含多个成员函数(function) | – 不是一个可实例化的类型,只用在函数签名中表示“没有” |
核心区别:
- 函数 是“做事情”的基本单元,封装了一段可执行的逻辑。
- 类 则是“有状态、有行为”的自定义类型,用来创建对象并组织更复杂的程序结构。
- void 只是一个修饰符号,表示“此处没有类型”或“此处不保留任何返回结果”,它本身并不承载逻辑或数据。
一:函数常见样式
函数一共就四种样式
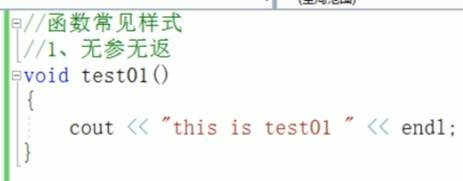
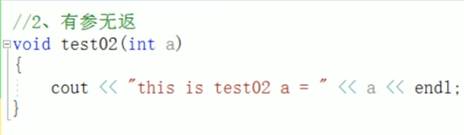

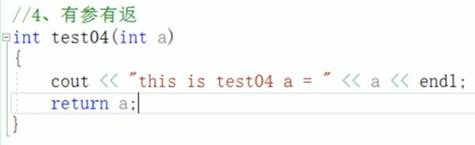
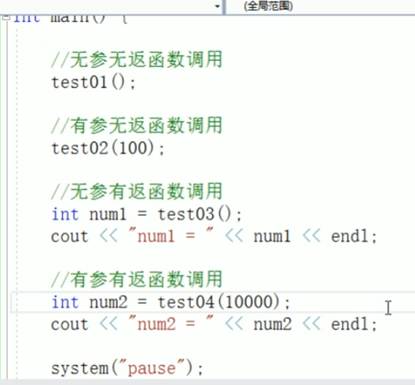
二:函数声明的意义
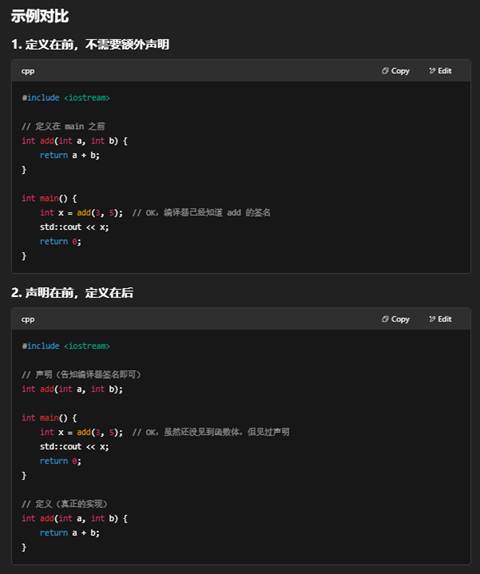
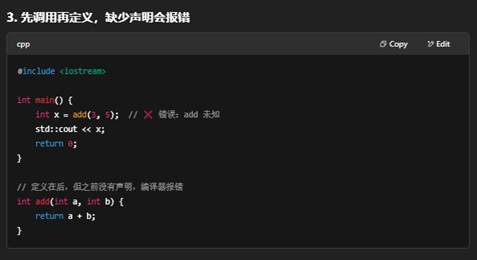
问:函数声明的意义是不是就是:如果我没有声明的时候,我先定义一个函数,然后再main()中调用它是可以的。 但是如果我是先在main()中调用,再定义就会报错,但是如果我先声明,再main()中调用,再定义,就不会有问题了。
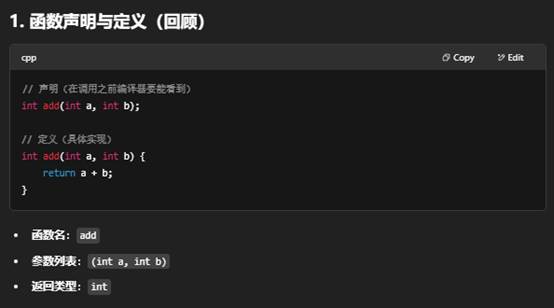
是的,你的理解基本没错。在 C++ 中,在使用(调用)一个函数之前,编译器必须知道它的签名(返回类型、函数名和参数列表)。函数声明(又叫“函数原型”)正是用来告诉编译器这些信息的。
为什么需要函数声明
- 编译器单遍扫描
C++ 编译器在一趟编译流程里从上到下读取源代码,它在遇到函数调用时,必须已经知道这个函数的签名,才能:- 检查参数类型是否匹配
- 确定调用约定(如何压栈、在哪里找符号)
- 两种常见写法
- 定义在前:把整个函数体写在 main() 之前,这时编译器读到调用处时,已经“见过”函数的定义,自然能正常编译。
- 声明在前,定义在后:在 main() 之前写一条函数声明,然后在 main() 之后或别的文件里再写函数体。
作用与好处
- 可读性与结构:把函数声明放在头文件(.h)里,定义放在源文件(.cpp)里,可以更清晰地组织大型项目。
- 接口与实现分离:调用者只需要看到声明(接口),无需关心实现细节;便于多人协作和模块化开发。
- 跨文件调用:在不同的 .cpp 之间,函数声明(通常在公共头文件里)保证链接时能正确找到对应的实现。
总结:
- 函数声明 的意义就在于:让编译器在真正看到函数定义之前,就能知道如何正确调用它;
- 你可以选择把定义写在调用之前,或者先声明再定义,两者都能让 main() 中的调用正常通过编译。
三:函数分文件编写的意义
将函数按功能或模块分散到不同的文件(通常是 .h/.hpp 头文件和对应的 .cpp 源文件)中,有助于树立清晰的项目结构与良好的开发协作习惯,其主要意义包括:
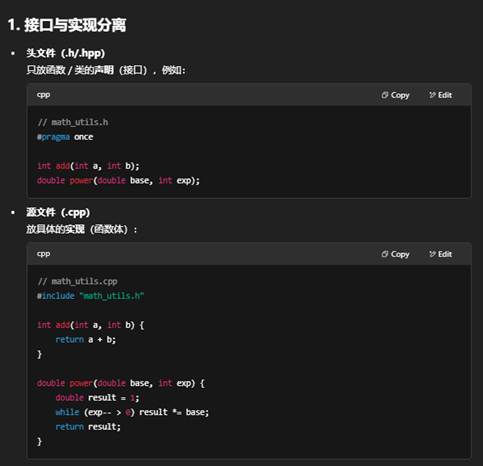
好处
- 调用者只需包含头文件,就能使用这些函数,无需关注内部细节。
- 实现更改(优化、修复)时,只要保持接口不变,依赖它的代码无需重新修改。
2. 提高可维护性与可读性
- 将功能相近的函数组织到同一个模块/文件夹,例如 io_utils.cpp、string_utils.cpp,让项目结构一目了然。
- 大文件拆分后,每个文件更短、更专注于一个责任,阅读和定位问题更快。
3. 支持“增量式编译”与缩短编译时间
- C++ 编译是基于“翻译单元”(.cpp + 它包含的头文件)逐个编译的。
- 当修改了一个源文件,只需要重新编译该文件并重新链接,而不必重新编译整个项目,显著节省时间。
4. 便于多人协作
- 不同开发者可以同时在不同模块(文件)上并行工作,减少冲突。
- 每个人只需关心自己负责的头文件接口和实现,不会频繁踩到他人代码。
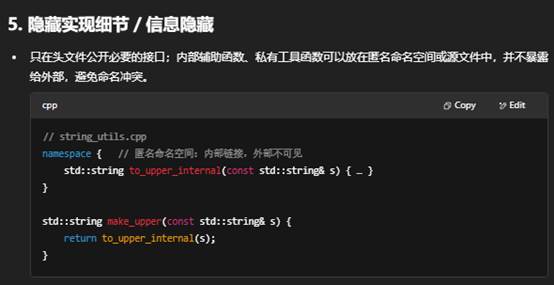
6. 模块化与重用
- 不同项目可复用已有模块,只需拷贝对应的头文件和编译好的库(或源文件)。
- 设计良好的功能模块,更容易在后续项目中直接引入。
总结
将函数分文件编写是一种工程化管理手段,通过“接口声明 + 单元实现 + 模块化组织”,实现了:
- 解耦:调用者与实现分离
- 可维护:修改实现不影响使用方
- 高效编译:增量编译,缩短编译时间
- 协作友好:多人成果并行开发
- 信息隐藏:只暴露必要接口
合理拆分,有助于大中型 C++ 项目的可扩展性与长期维护。
四:值传递

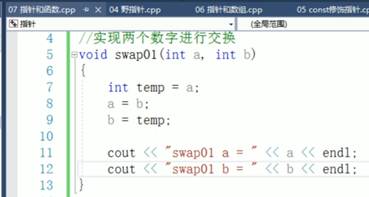

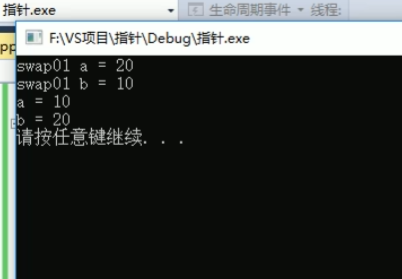
五:是不是所有void开头的都是属于函数?
不是的,并非凡是以 void 开头的语句都是函数。在 C++ 中,void 本身只是一个“无类型”(no-type)的标识符,常见用法有几种,不同用法对应不同的声明:

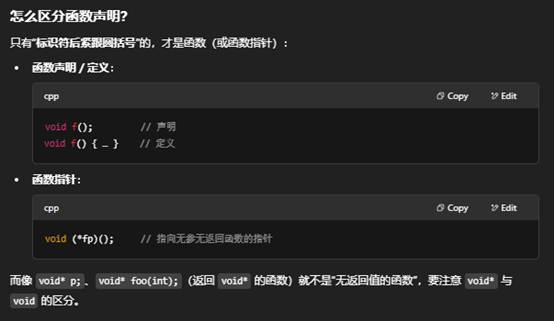
小结
- void 单独 出现在函数名前,才表示“这是个不返回任何值的函数”。
- 如果是 void*,那是“指向任意类型的指针”。
- 而且函数声明/定义能被识别的关键在于——名字后面有 ()。
六:函数的调用
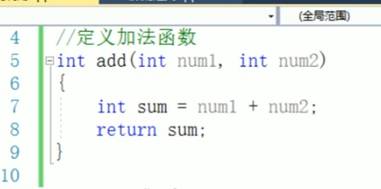
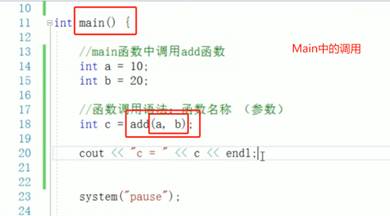
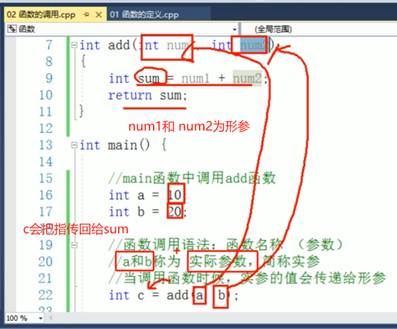
C++ 中,函数定义和类定义一般都写在 main() 函数之外(通常放在全局作用域或头文件里),而在 main()(或其他函数)里去 调用 这些函数/创建并操作这些类的对象。
下面给你一个完整的示例骨架,演示定义和调用是如何分开的: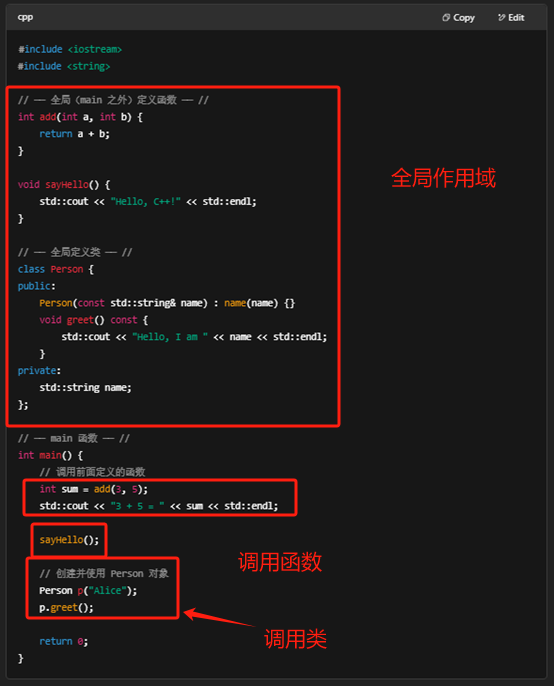
函数/类的“定义”(implementation)都放在 main 外,便于复用,也能在多个地方调用。
“调用”(calling)和对象实例化放在 main()(或其它函数)里,程序从 main() 开始执行。这样既结构清晰,又符合 C++ 的编译和链接规则。
调用函数,就是在代码中通过函数名加上“实参列表”来执行该函数体内的逻辑。下面分步骤说明:
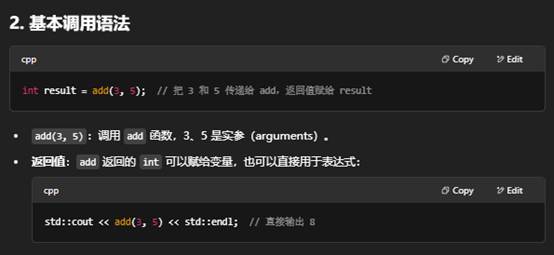
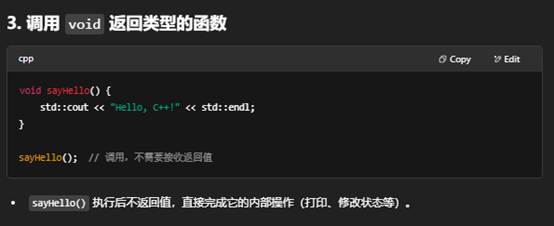
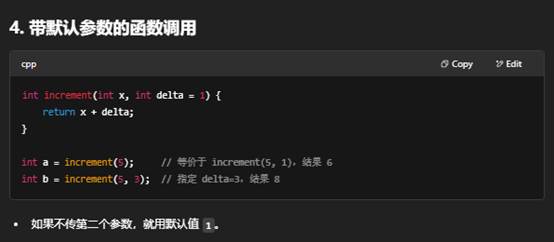
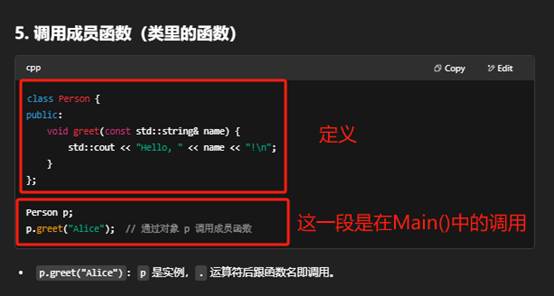
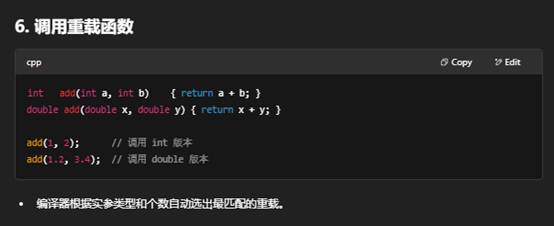
总结:调用函数的核心就是用 函数名(实参列表),根据返回值决定是否赋值或忽略,然后函数体内的代码就会执行。
Struct结构体
1:Struct结构
1 结构体基本概念
结构体属于用户自定义的数据类型,允许用户存储不同的数据类型。
2 结构体定义和使用
语法: struct 结构体名 { 结构体成员列表 };
通过结构体创建变量的方式有三种:
struct 结构体名 变量名
struct 结构体名 变量名 = { 成员1值 , 成员2值…}
定义结构体时顺便创建变量
示例:
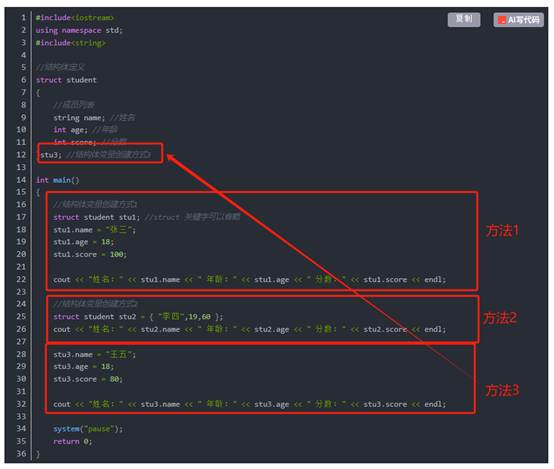
总结:
- 定义结构体时的关键字是struct,不可省略;
- 创建结构体变量时,关键字struct可以省略;
- 结构体变量利用操作符 ‘’.‘’ 访问成员。
建议用方法一和方法二,方法三不建议。
2:结构体数组
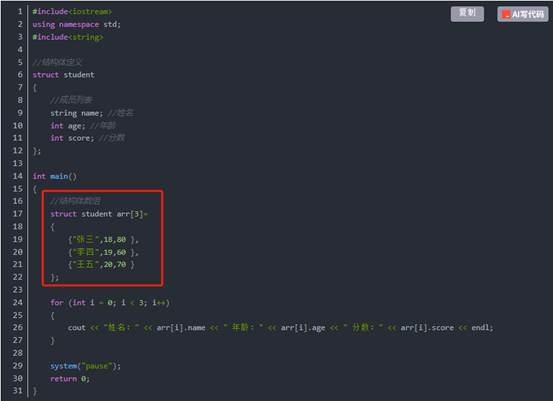
作用:将自定义的结构体放入到数组中方便维护。
语法: struct 结构体名 数组名[元素个数] = { {} , {} , ... {} }
示例:
3:结构体指针
作用:通过指针访问结构体中的成员。
- 利用操作符 ->可以通过结构体指针访问结构体属性。
示例:
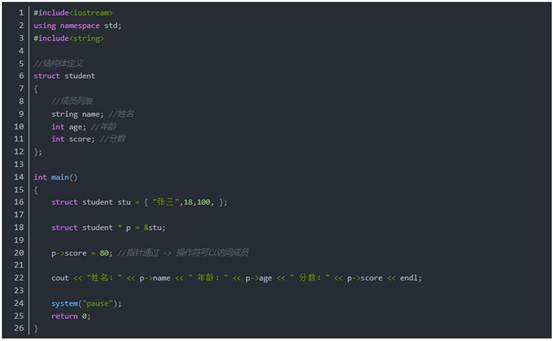
总结:结构体指针可以通过 -> 操作符来访问结构体中的成员。
4:结构体嵌套结构体
作用: 结构体中的成员可以是另一个结构体。
例如:每个老师辅导一个学员,一个老师的结构体中,记录一个学生的结构体。
示例:
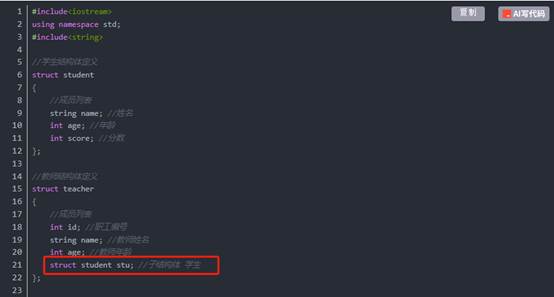

总结:在结构体中可以定义另一个结构体作为成员,用来解决实际问题。
5:结构体做函数参数
作用:将结构体作为参数向函数中传递。
传递方式有两种:
- 值传递
- 地址传递
示例:
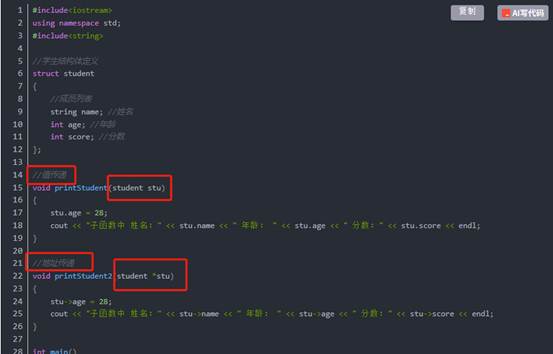
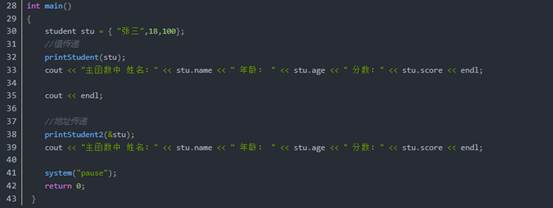
总结:如果不想修改主函数中的数据,用值传递,反之用地址传递。
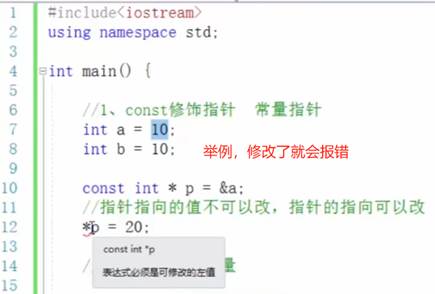
结构体中const使用场景
作用:用const来防止误操作。
示例:
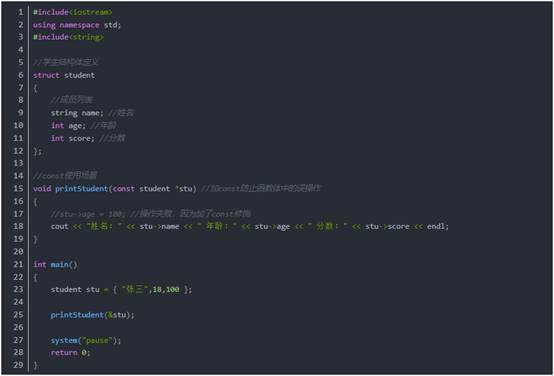
C++指针
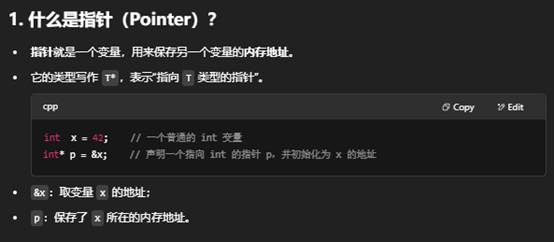
为什么需要指针?
问:为什么在C++中,要使用指针去间接修改,访问某些变量的地址或者是值,而不是直接去修改或者是访问那个变量本身呢?这不是多此一举吗?
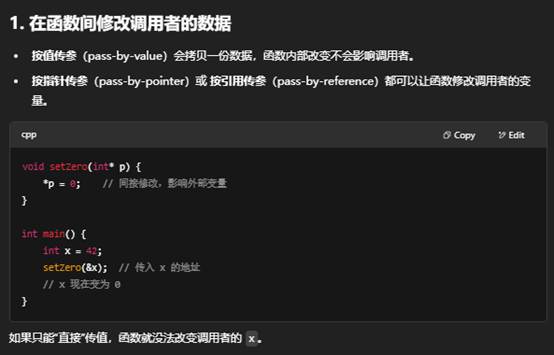
在 C++ 里,指针(pointer)并不是“多此一举”,而是一种“间接访问”机制,它带来了很多灵活性和能力,是语言设计中不可或缺的部分。下面从几个角度来说明为什么需要指针,以及它们能做哪些直接访问无法做到的事情。
6. 与底层 / C 接口互操作
- 许多操作系统 API、第三方 C 库都要求传入指针或返回指针:
- 文件读写:fread(void* buffer, size_t size, size_t count, FILE* fp)
- Socket 编程:recv(int sock, void* buf, int len, int flags)
没有指针,你就无法调用这些接口。
7. 指针的“可变性”——空指针与指针运算
- nullptr:指针可以表示“指向空”,通过检查指针是否为 nullptr 来判断某资源是否有效。
- 指针运算:在数组遍历、内存块操作里,可以做 p + i、p[i],这是数组之于内存的自然映射。
为什么不用“直接”访问?
- “直接访问”只适合固定、已知生命周期的变量。
- 很多场景下,你需要在不同函数、不同作用域之间共享、延长生命周期、动态增减元素、实现多态……指针(或引用、智能指针)是唯一能达成这些目标的手段。
小结
指针的核心作用就在于「间接引用」——让你能够:
- 在函数之间修改调用者数据;
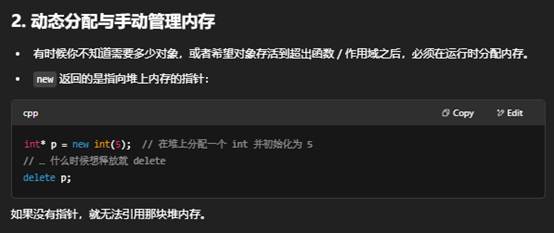
- 动态分配和管理对象;
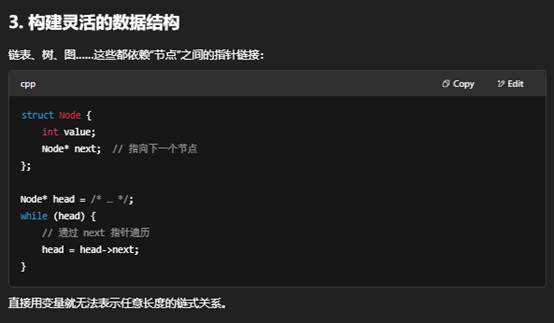
- 构建灵活的数据结构(链表、树等);
- 利用运行时多态;
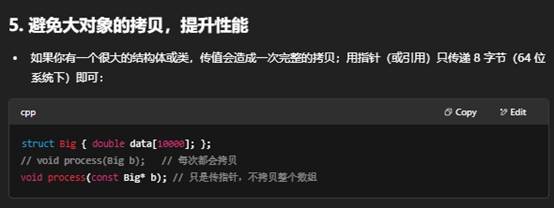
- 避免大对象拷贝以提高性能;
- 与底层/ C 接口互操作;
- 使用空指针与指针运算实现更精细的内存控制。
这些能力在系统级、库级、框架级开发中十分关键,并不是多余的,而是 C++ 追求“零开销抽象”与“高效灵活控制”的必要代价。
1:C++ 中指针的使用及其意义
我的理解:指针就是一个地址,正常的指针变量名都是p (point) 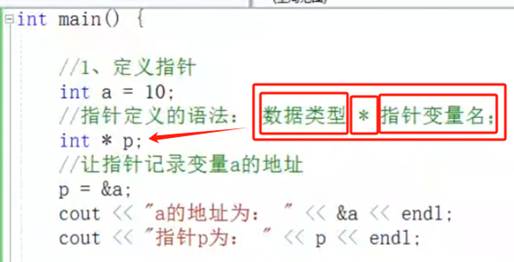
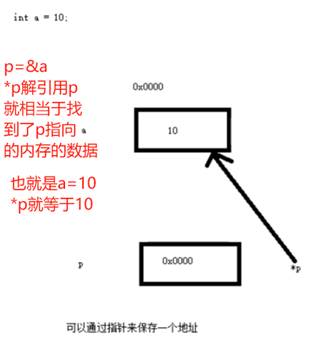
如果把*p改为1000,那么a也会=1000
指针可以间接的访问这块内存并且可以进行一个读和写的操作,我们可以修改它或者去访问它
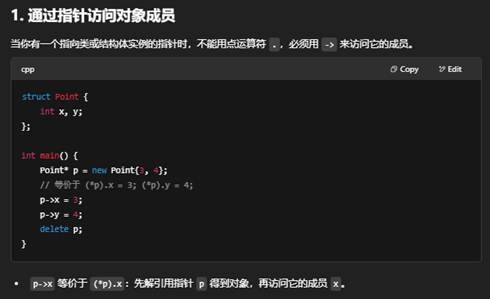
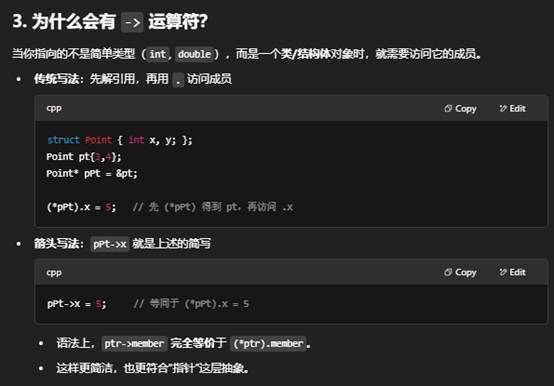
2:C++中,->的用法和意义是什么?
在 C++ 中,-> 是指针成员访问运算符(pointer-to-member operator),它的主要用途和意义有以下几点:
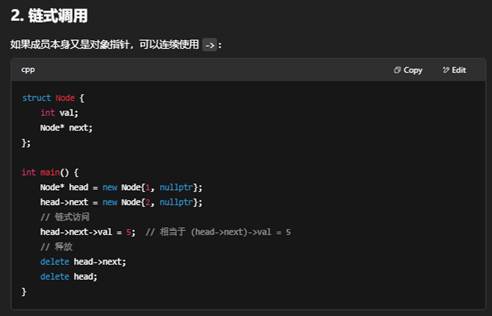
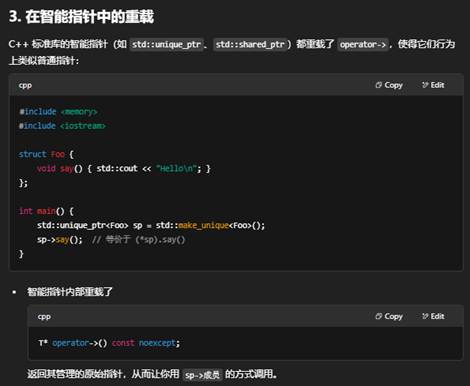
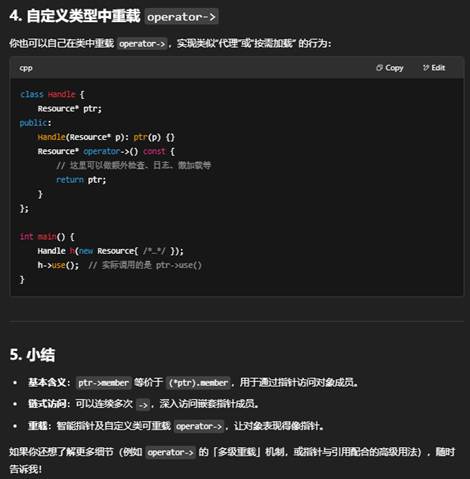
3:指针和 -> 的关系
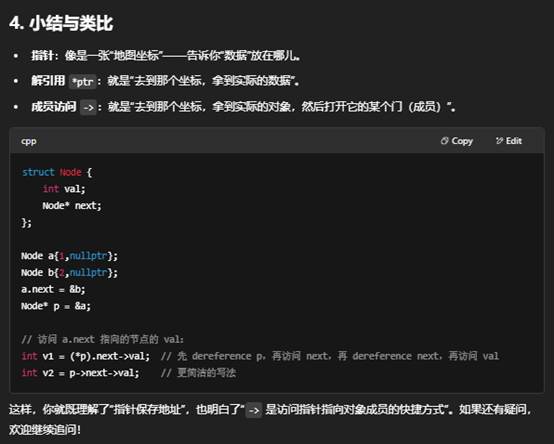
4:指针运算符 &、* 和 -> 的具体示例
下面用一个自定义类来演示各种运算符的含义。
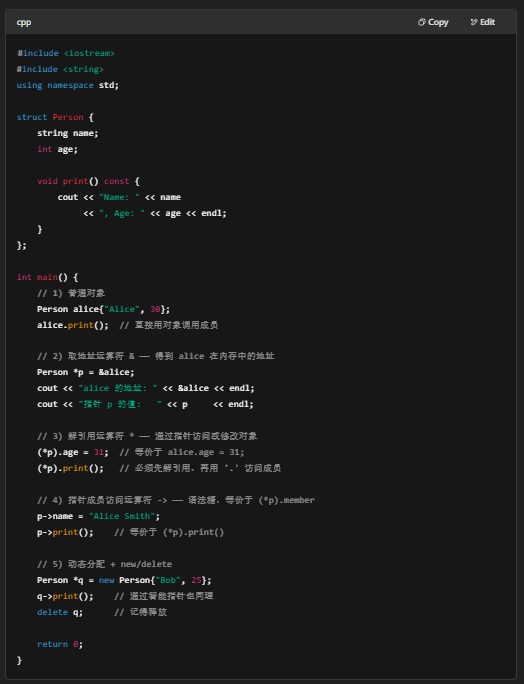
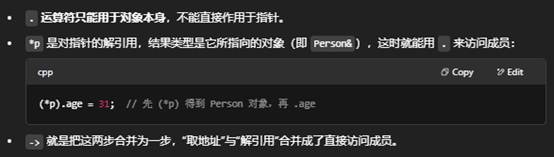
- &alice:取得 alice 变量的内存地址,类型是 Person*。
- Person *p = &alice;:声明一个指针 p,保存了 alice 的地址。
- *p:解引用,得到指针指向的那个 Person 对象本身。
- (*p).age = 31;:先解引用,再用点运算符修改成员。
- p->name = "Alice Smith";:p->name 就是 (*p).name 的简写,既可读又可写。
通过上面例子,你可以看到:
- &:取地址,得到指针。
- *:解引用,用指针访问或修改实际对象。
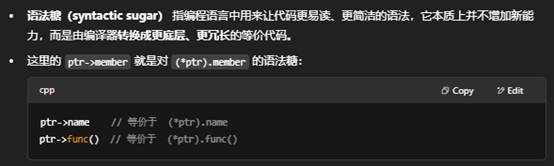
- ->:当指针指向结构体/类时,直接访问它的成员,是 (*ptr).member 的快捷写法。
如果你还想了解更多(比如函数指针、指向成员函数的指针、智能指针重载 operator-> 等),请告诉我!
5:例子中的运行输出(示例地址,实际环境中地址会不同)
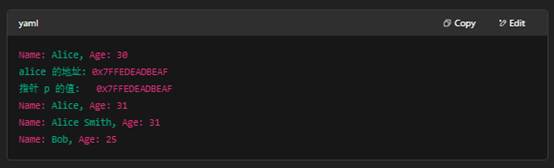
第一行是 alice.print() 的输出。
“alice 的地址” 与 “指针 p 的值” 两行打印的是同一个地址,说明 p == &alice。
随后三行分别是通过 *p 修改后的输出、通过 p-> 改名后的输出,以及 q(动态分配的 Bob)的输出。
6:指针所占的内存空间大小


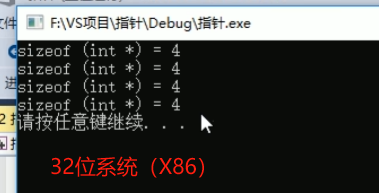
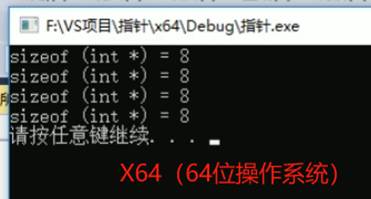
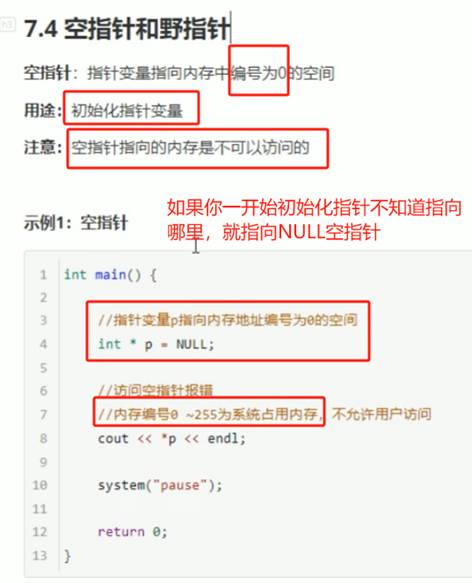
7:空指针和野指针
总结:空指针和野指针都不是我们申请的空间,因此不要去访问它

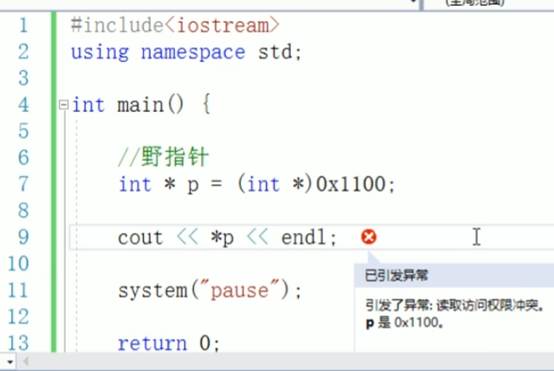
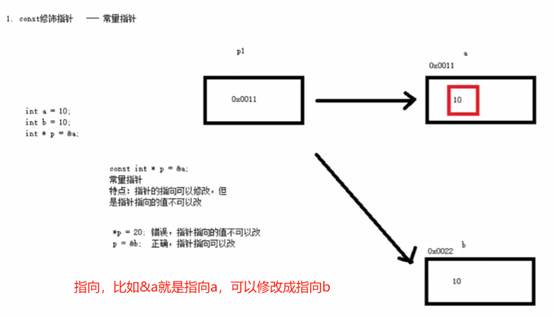
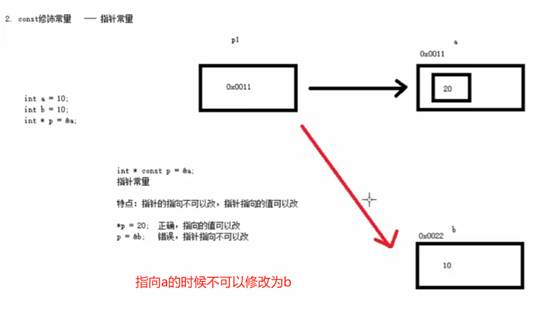
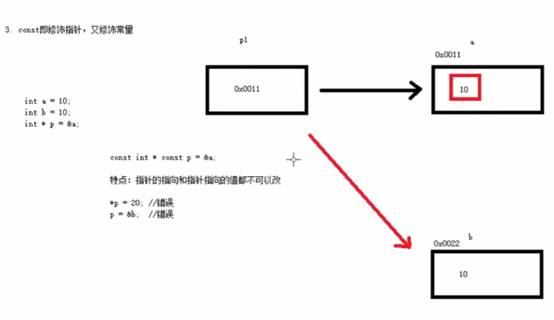
8:const修饰指针

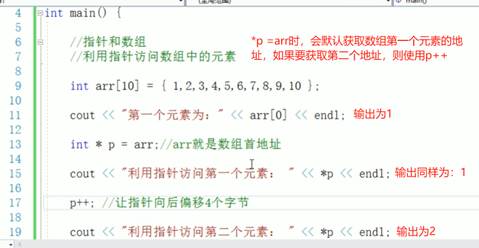
9:指针和数组
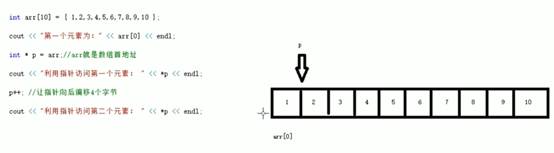
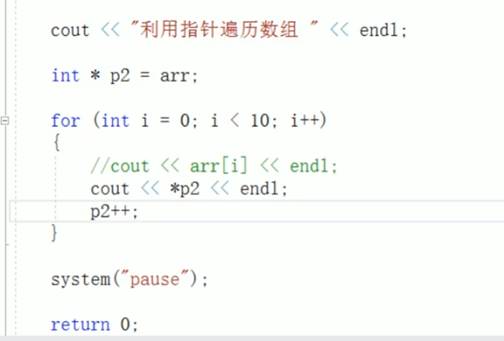
10:地址传递
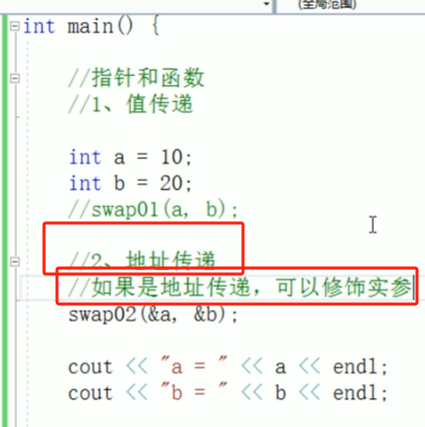
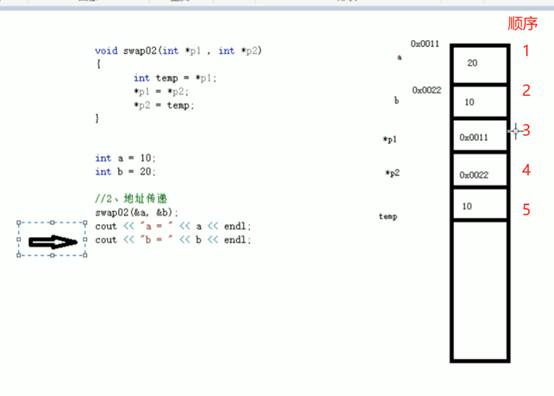

不想修改实参就用值传递,想修改实参就用地址传递
指针配合数组和函数案例
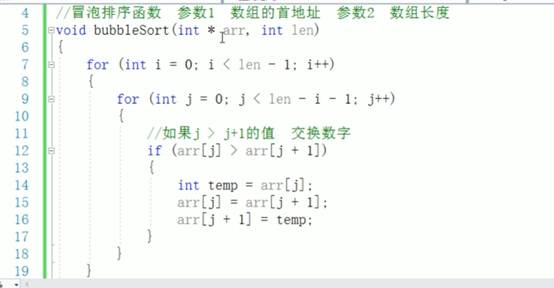

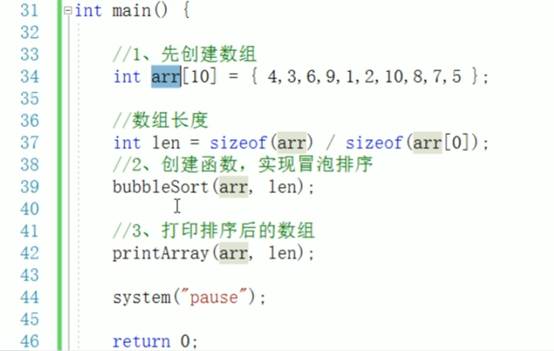
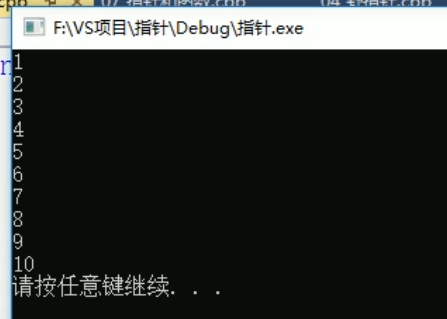
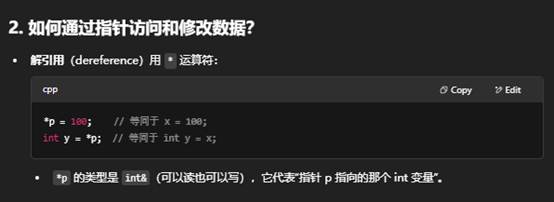
11:为什么要先解引用 *p 再用 . 访问成员?
12:指针是不是主要用来访问数组?单个变量能否直接赋值?
指针可以指向任何类型的对象——既可以是数组首元素,也可以是普通的单个变量、类实例、动态分配的内存等。
如果你操作的是本地的单个变量,像:

那当然没必要用指针去间接访问。
指针的作用主要在于:
- 动态分配:在堆上分配一块内存,必须通过指针来引用它;
- 函数间传递:如果想让函数内部修改调用处的变量,常通过指针参数或引用;
- 数据结构:链表、树、图等节点间通过指针连接;
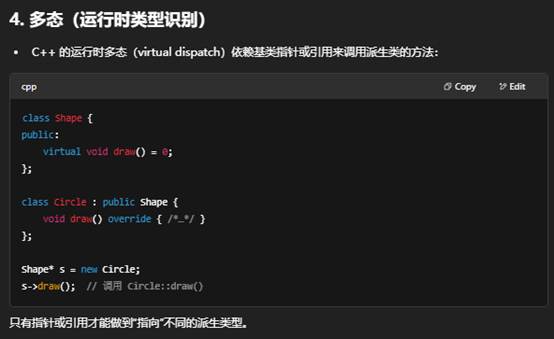
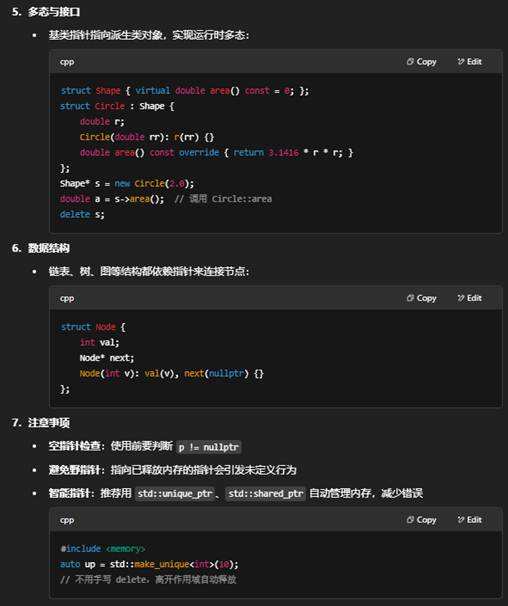
- 多态:基类指针指向派生类对象,用于运行时多态。
结论:只有在需要“间接引用”或“动态管理”时才用指针,否则直接变量名赋值最简单。
13:为什么有的写 (*p).age,有的写 p->name?
这两种写法其实等价,都是先对指针 p 做“解引用”(得到它指向的对象),再访问该对象的成员:
为什么例子里同时出现两种?
- (*p).age = 31; 强调了解引用再访问成员的过程,写法上要加括号,否者 *p.age 会被错误解析。
- p->name = "Alice"; 就是箭头语法,编译器自动帮你做了解引用和再访问成员:

推荐风格:
- 日常中只要指针指向的是类/结构体,就统一用 ->,既简洁又避免括号。
- 只有在讲解原理或演示 operator-> 重载时,才会写出 (*p).member。
小结
- 指针并不限于数组,单个变量完全可以直接赋值,指针主要用于需要间接访问或动态管理的场合。
- (*p).member 和 p->member 是一回事,后者是对前者的简写(语法糖),平时习惯用 ->。
14:指针访问数组时,只能访问和修改数组首元素吗?
不是的,指针只是存了数组第一个元素的地址,但利用 指针运算(也就是“指针加减”)就能访问数组中的任意元素。
1. 原理:指针加法
假设有一个整型数组:

- p 当前指向 arr[0]。
- 指针加法:p + 1 会跳过一个 int 大小,指向 arr[1];
- 一般地,p + i 就指向 arr[i](前提是 0 <= i < 5)。
2. 访问和修改
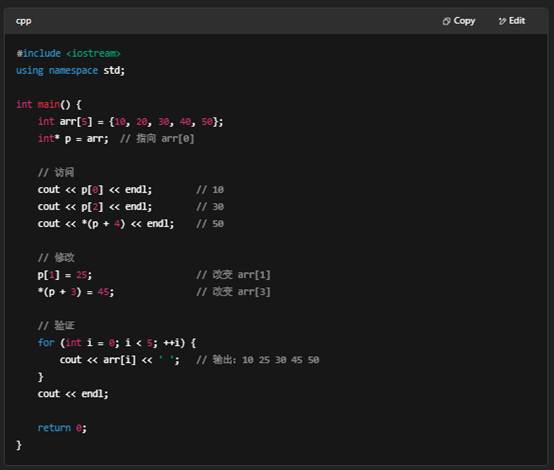
- p[i] 就是 *(p + i) 的语法糖,用来访问第 i 个元素。
- 同理,你可以写 *(p + i) = newValue; 或者 p[i] = newValue;,都能修改对应元素。
3. 小结
- 指针本身只保存一个地址(初始时通常是数组首元素的地址)。
- 指针加法让你在内存中按元素大小“跳转”到数组的任意位置。
- 这样就能访问和修改整个数组,而不仅仅是第一个元素。
15:智能指针(Smart Pointer)和原始指针(Raw Pointer)的区别

16:为什么指针只是存了数组第一个元素的地址?
当你把一个数组名赋给一个指针变量时,发生的是“数组到指针”的衰变(decay)——它会变成第一个元素的地址:
为什么这样设计?
- 类型匹配
- int* p 表示“指向 int 的指针”。
- arr 本身不是指针,但在大多数表达式里,它会被隐式转换为 “指向第一个元素的指针”——int*。
- 这样 p = arr; 就是把 &arr[0](类型为 int*)赋给 p。
- 方便遍历
- 数组在内存中是连续存放的:

有了“首元素地址”后,通过指针加法(p + i)或下标语法(p[i])就能访问整个数组。
区分“数组地址”与“元素地址”
- arr 衰变为 &arr[0],类型是 int*。
- 如果你写 &arr,它的类型是 int (*)[5](指向整个 5 元素数组的指针),虽然数值上也指向同一块内存的起始地址,但类型不同,做指针算术时就不一样。

小结
- 指针保存的地址类型 由它的声明决定:
- int* p → 它存的是 “一个 int” 的地址,所以赋 arr 时得到的是 &arr[0]。
- int (*pArr)[5] → 它存的是 “一个长度为 5 的 int 数组” 的地址,所以赋 &arr。
- “数组名衰变为指针” 是 C/C++ 的语法规则,目的是方便你通过指针遍历和操作数组元素。
基础问题提问 Part1
一:C++ 面向对象的构建能力
C++ 支持面向对象编程(OOP),主要体现在以下几方面:
- 封装(Encapsulation)
- 用 class/struct 将数据与操作数据的函数(成员函数)组合在一起,并通过访问控制符 (public/protected/private) 隐藏内部细节。
- 继承(Inheritance)
- 派生类继承基类的成员,可以代码复用和扩展。支持单继承和多重继承(需注意菱形继承问题)。
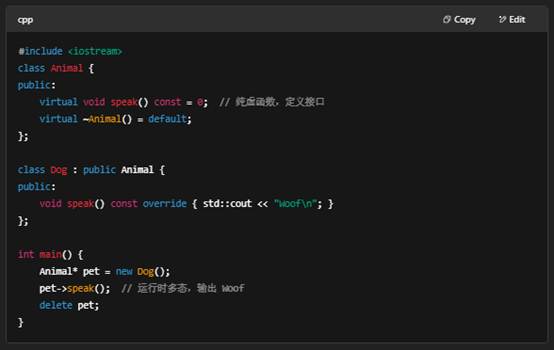
- 多态(Polymorphism)
- 编译时多态:函数重载、运算符重载、模板实例化。
- 运行时多态:基类指针/引用调用派生类的虚函数,借助虚函数表(vtable)实现动态绑定。
- 抽象(Abstraction)
- 通过纯虚函数(virtual … = 0)定义接口,将具体实现留给派生类。
二:C++ 的基础特性
除了面向对象,C++ 语言本身还包含以下核心特性:
- 静态类型系统
- 编译期类型检查,auto 推导与显式类型声明并存。
- 指针与引用
- 直接操作内存地址(指针 T*),引用 T& 作为别名。
- 模板与泛型编程
- 函数模板、类模板,支持在编译期生成类型安全的代码。
- 标准模板库(STL)
- 容器(vector、map 等)、算法(std::sort、std::find_if)、迭代器。
- RAII(资源获取即初始化)
- 通过栈对象的构造/析构管理资源(文件、锁、内存),保证异常安全。
- 异常处理
- try/catch/throw 提供统一的错误处理机制。
- 现代语法糖(C++11 及以后)
- Lambda、智能指针(unique_ptr/shared_ptr)、右值引用 (T&&)、constexpr、enum class 等。
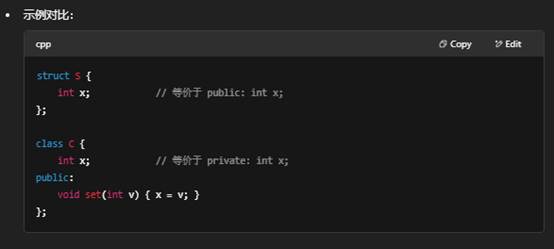
三:struct 的用法,以及为何用 struct 而不是 class?
在 C++ 中,struct 和 class 唯一的语法区别是默认的成员访问权限不同:
- struct:默认公有,即不加访问说明符的成员都是 public。
- class:默认私有,即不加访问说明符的成员都是 private。
用法上它们功能完全相同,都可以定义成员变量、成员函数、继承、多态等。
常见习惯:
- 简单的数据聚合(Plain-Old Data)或只包数据、少逻辑的类型常用 struct;
- 需要封装、接口与实现分离、强访问控制的类常用 class。
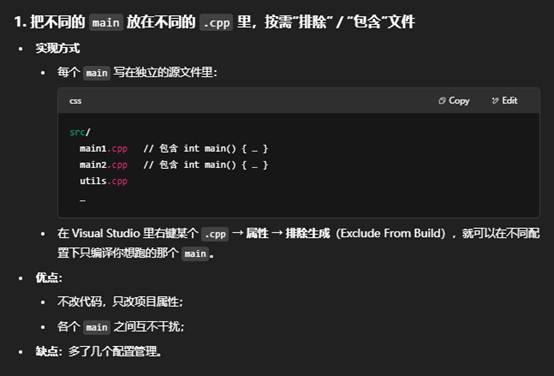
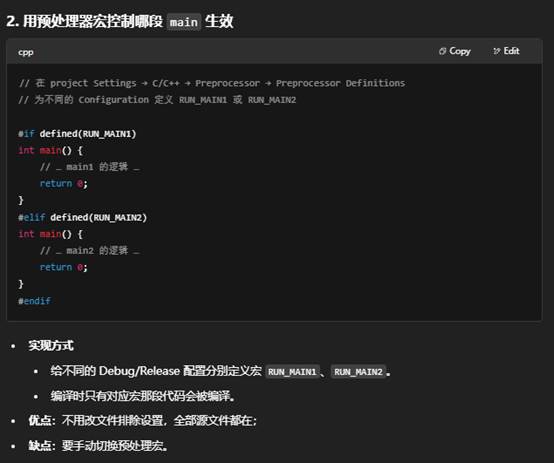
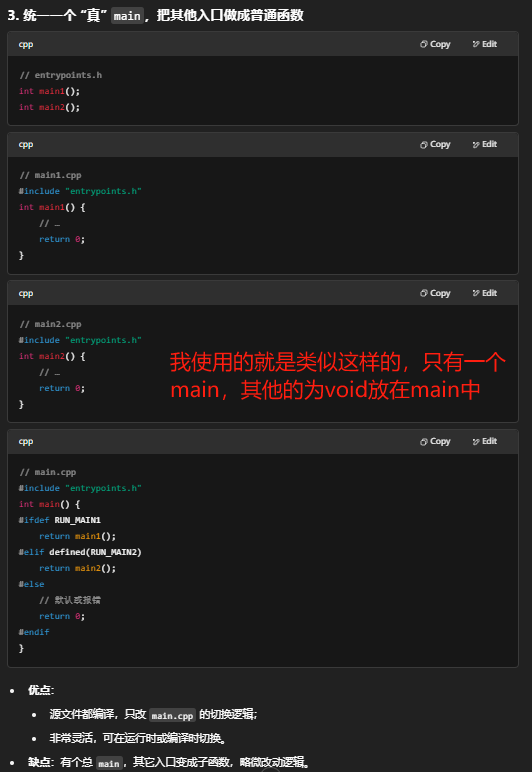
四:如何在同一个项目中执行不同的main?除了把之前写的代码注释掉之外还有什么办法吗?
在一个 C++ 项目里,编译、链接阶段只能有一个有效的 main,否则会报“重定义 entry point”之类的错误。除了“注释掉”不想跑的那段 main,常用的几种做法是:

五:什么是“语法糖”?
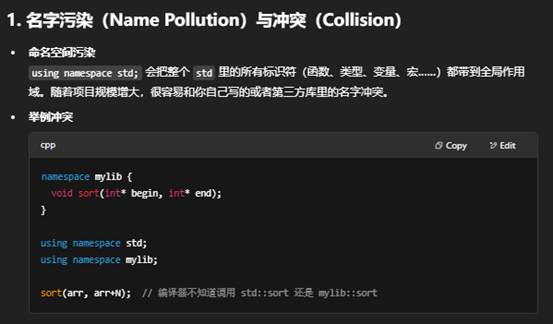
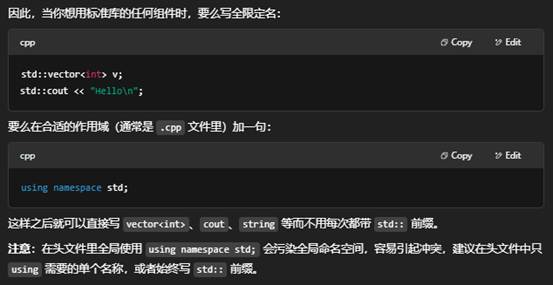
六:using namespace std; 什么时候不适用?
在 C++ 里,using namespace std; 的确可以让你在后面写代码时不用每次都敲 std::,比如

其背后有几个主要原因和注意事项:
2. 可读性与维护性
- 显式来源更清晰
当你在代码里看到 std::string、std::move、std::map,立刻就能知道这是标准库的类型或函数;如果都省掉了前缀,读者必须去猜它们来自哪个命名空间。 - 大规模团队协作
在多人或跨模块协作时,大家更倾向于显式地写 std::,以防某人无意间引入了同名的自定义类型或函数,导致别处编译出奇怪的错误。
3. 头文件(.h/.hpp)绝对忌用
千万不要在头文件里写 using namespace std;,因为:
- 它会“传染”所有包含这个头文件的源文件。
- 你难以预料在别的源文件里会因此引入哪些名字冲突。
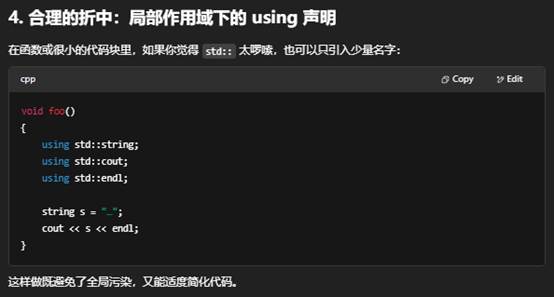
如果真的想让头文件里少写几次 std::,也只能用更局部的 using std::string; 这样的 using 声明,并且也要非常小心只引入少量标识符。
何时不该用 using namespace std;
- 任何头文件 —— 都不要写。
- 大型项目的全局或命名空间顶层 —— 会影响所有代码。
- 当你的工程里有多个命名空间,且有可能重名时 —— 绝对不要。
总结
- 小型、临时的示例代码(教学、Demo、快速原型)可以用 using namespace std;,让示例更简洁;
- 生产级代码、库/框架、头文件 则应显式地用 std:: 或者局部 using std::xxx;,以提升可读性、可维护性并防止名字冲突。
七:什么是自定义Node?
“自定义 Node”就是自己用 struct 或 class 定义一个“节点”类型,用来在链表、树、图等数据结构里串联各个元素。它不是标准库里提供的,而是程序员根据需求手写的。
1. 为什么要自定义 Node?
标准库里有像 std::list 这样封装好的链表容器,但如果你想自己实现一个链表学习原理,或者要在一个特殊场景下改造链表,就需要自己定义节点类型。
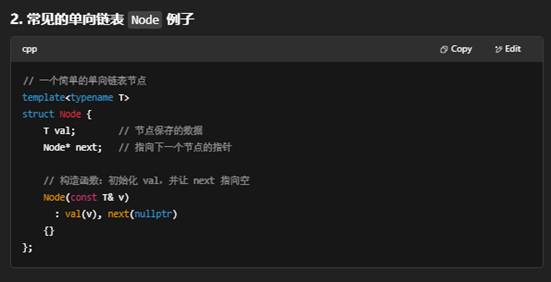
val:存放用户关心的数据,比如 int、string、或自定义对象。
next:指向链表中下一个节点,或为 nullptr 表示到达链表尾部。
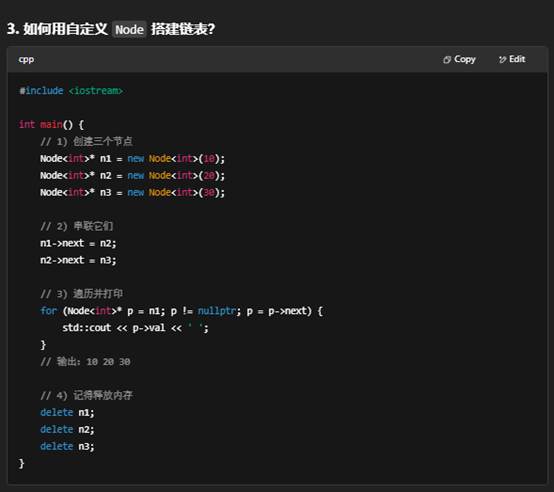
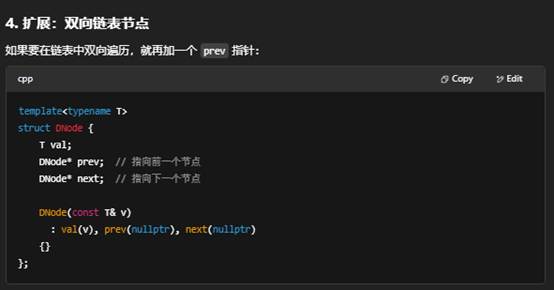
5. 小结
- “自定义 Node”:自己写 struct Node{…}; 来描述“节点”是什么。
- 用途广泛:学习链表原理、实现各种链式或树形数据结构。
- 与 STL 区别:STL 已经封装好,你只要直接用;自定义则可完全控制底层逻辑。
八:原生数组T a[N],std::array<T, N>,std::vector<T>(动态数组)


九:std是什么意思?
在 C++ 中,std 是“standard”(标准)的缩写,用来表示标准库所定义的命名空间(namespace)。
- 命名空间的作用是把一组相关的名字(类、函数、常量、对象等)组织在一起,避免与其他库或用户定义的名字冲突。
- C++ 标准库里的所有内容都放在 std 命名空间下,比如:
- 容器:std::vector、std::map
- 输入输出:std::cout、std::cin
- 字符串:std::string
- 算法:std::sort、std::find
- 智能指针:std::unique_ptr、std::shared_ptr
- …等等
基础问题提问 Part 2
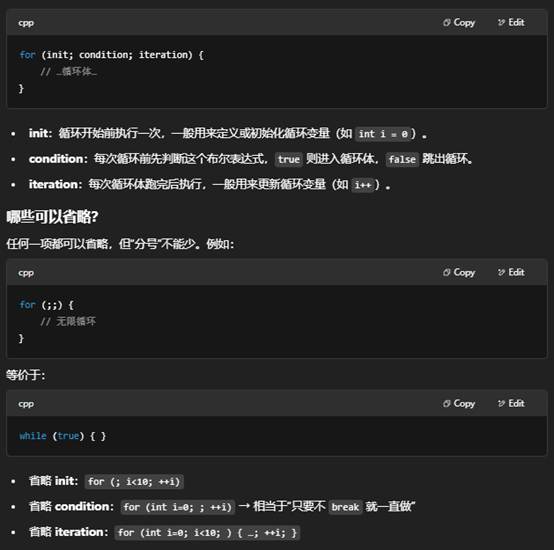
一:for 语句的三个“部分”是否都必须写?
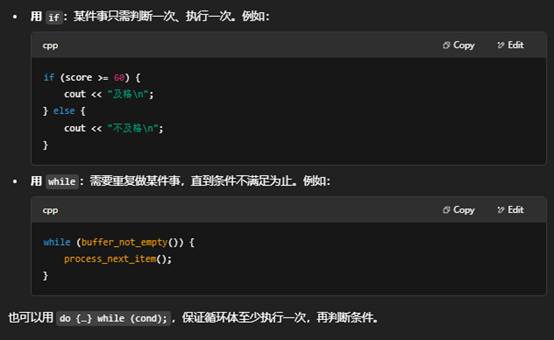
二:while 和 if 的“条件”写法
- if (condition)
- while (condition)
两者的括号里都只允许出现一个能转换为 bool 的表达式(条件),不能写三段式。常见写法包括:
- 关系表达式: i < 5、ptr != nullptr
- 逻辑表达式: x>0 && x<10、!flag
- 函数返回值: if (read() > 0) …
你可以把多个判断用逻辑运算符 &&、||、! 串起来,但整个 (...) 只有一个“条件表达式”。
三:while vs. if,何时用哪一个?

小结
- for(...) 括号里可写三段,也可各自省略,但之间的分号不能少。
- if(...) 和 while(...) 括号内都只要一个布尔表达式(可以通过 &&/||/! 组合)。
- if 用于做一次性的条件分支;while 用于在条件为真时重复执行循环体。
四:Class和void的区别是什么?
在 C++(以及大多数面向对象语言)里,class 和 void 是两个完全不同层面的关键字,分别用于类型定义和类型说明。
一、class —— 定义“类”这种用户自定义类型
- 作用
- class 用来声明一个“类”(class),它是 C++ 的核心——封装数据(成员变量)和行为(成员函数)的模板。
- 通过 class,你可以创建任意复杂度的类型,实现封装(encapsulation)、继承(inheritance)、多态(polymorphism)等面向对象特性。
二、void —— 表示“没有类型”或“空”
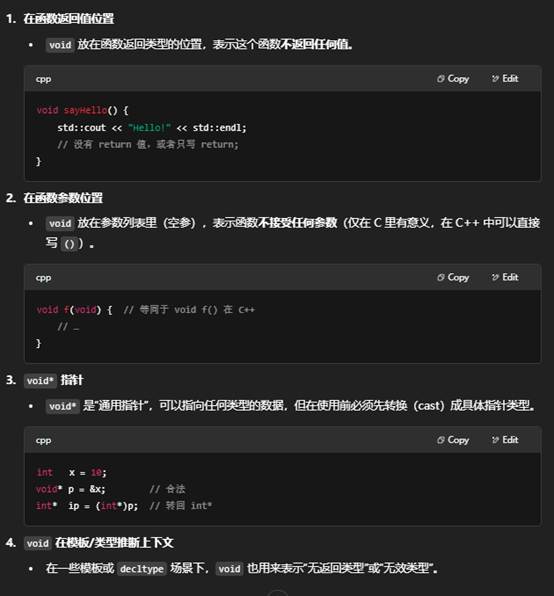
小结
- class:一种用户自定义的类型,用于封装成员变量和成员函数,是面向对象的基石。
- void:一种类型说明符,表示“没有具体类型”——常用于标记“无返回值的函数”或“通用指针”。
它们在语法上和语义上完全不冲突,经常在同一份代码里“组合”使用:用 class 定义类型,用 void 指定那些不需要返回值的成员函数。
五:介绍Json和XML
JSON(JavaScript Object Notation)
定义
- 一种轻量级的数据交换格式,以文本形式表示结构化数据。
- 源自 JavaScript,但与语言无关,支持多数编程语言。
特点
- 简洁:使用少量符号,易读易写。
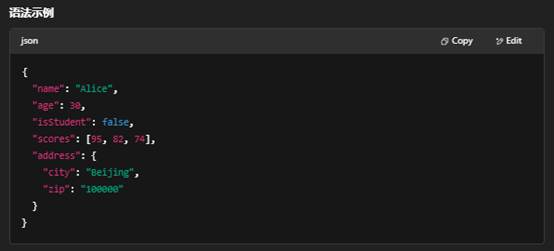
- 数据模型:仅支持两种结构:
- 对象(由 {} 包围,内部是键–值对,如 {"key": value})
- 数组(由 [] 包围,内部是按顺序的值列表,如 [1,2,3])
- 数据类型:字符串、数值、布尔、空、对象、数组。
- 无模式(Schema-less):不强制定义字段类型或顺序。
优缺点
- 优点:体积小、解析快、与现代 Web/REST API 天然契合。
- 缺点:不支持注释;对非常复杂的文档标记(如文档格式)不如 XML 灵活。
应用场景
- Web 前后端数据交换(AJAX/RESTful API)。
- 配置文件(如 .eslintrc.json、.babelrc)。
- NoSQL 数据库(MongoDB 存储的是 BSON,一种二进制 JSON 变体)。
XML(eXtensible Markup Language)
定义
- 一种可扩展的、标记型的文本格式,用来表示复杂的文档和数据。
- 由 W3C 标准化,强调可读性和可验证性。
特点
- 标签(Tag)结构:数据通过开始标签 <tag> 与结束标签 </tag> 标识,支持自定义标签名。
- 层次化:天然树状结构,适合描述文档型数据(如网页、文档、配置)。
- DTD/XSD:可配合文档类型定义(DTD)或 XML Schema(XSD)进行校验,保证结构与数据类型正确。
- 可混合内容:标签内部既可含文本也可嵌套子元素。
语法示例
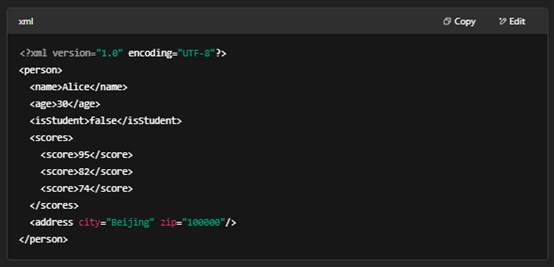
优缺点
- 优点:标签自描述、支持注释、标准化的校验机制(XSD)、可混合文本和子元素。
- 缺点:冗长(标签成对出现)、解析比 JSON 慢、对简单数据交换稍显臃肿。
应用场景
- 配置文件(如 Ant、Maven 的 pom.xml)。
- 文档格式(如 XHTML、SVG、Office Open XML)。
- 企业级 Web 服务(SOAP,多用 XML 构建请求与响应)。
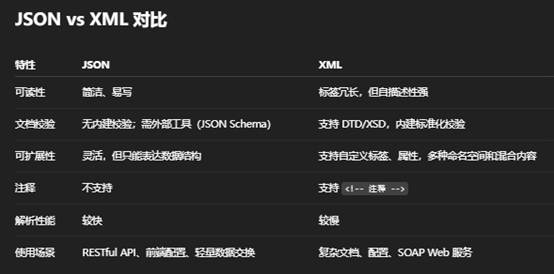
总结
- 选择 JSON:当你追求轻量、快速、与现代 Web/REST 接口无缝集成时。
- 选择 XML:当你需要严谨的结构校验、混合内容文档或标准化的企业级消息格式时。
六:Encoding, UTF-8和Unicode是什么?UTF-8属于Unicode吗?
Unicode 和 UTF-8 经常一起出现,但它们指的并不完全相同:
1. Unicode:字符集与代码点
- Unicode 是一个国际标准,定义了全球绝大多数书写系统中所有字符的“码点”(code point)。
- 每个字符被分配一个唯一的编号,记作 U+XXXX,其中 XXXX 是 16 进制数。例如:
- U+0041 → 拉丁字母大写 A
- U+4F60 → 中文“你”
- U+1F600 → 表情“😀”
- 注意:
- Unicode 本身只是一张“表”和一套规范,不规定具体在内存或文件里如何存储这些码点。
- Unicode 的范围很大,目前可用的码点超过 140 000 个,分布在多个平面(Plane 0…Plane 16)。
2. 字符编码(Encoding)
要把这些“码点”保存到磁盘或发送到网络上,必须把它们转换成字节序列,这就叫字符编码。常见的 Unicode 编码包括:
| 名称 | 描述 |
| UTF-8 | 可变长度编码:1~4 个字节表示一个码点。ASCII 范围(U+0000…U+007F)用单字节,高位字符用多字节。 |
| UTF-16 | 可变长度:2 或 4 个字节。BMP(基本多文种平面;U+0000…U+FFFF)用 2 字节,超出部分用一对代理项(surrogate pair)。 |
| UTF-32 | 固定 4 字节:每个码点都占用 4 字节。查表速度最快,但空间利用率最低。 |
3. 为什么选择 UTF-8?
- 向后兼容 ASCII:U+0000…U+007F 区间和 ASCII 完全相同,用单字节保存。
- 节省空间:对于英文文本,几乎和 ASCII 一样小;对多数字母文字也比 UTF-32 紧凑。
- 广泛支持:几乎所有 Web、Unix/Linux、现代编程语言和库都默认使用 UTF-8。
- 自同步性:从任意一个字节读取即可判断这是一个新字符的开始还是续字节,便于流式处理。
4. UTF-8 的编码规则示例
| 字节数 | 码点范围 | 编码格式(二进制) |
| 1 | U+0000 … U+007F | 0xxxxxxx |
| 2 | U+0080 … U+07FF | 110xxxxx 10xxxxxx |
| 3 | U+0800 … U+FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | U+10000 … U+10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
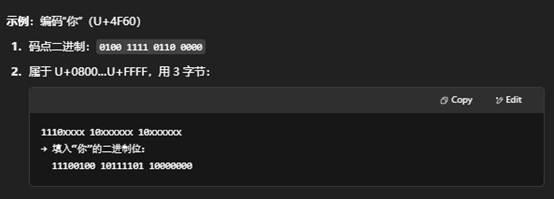
5. 小结
- Unicode:定义“字符 ↔ 码点”的映射,是字符的“编号表”。
- UTF-8:把这些码点编码成 1~4 个字节的序列,是字符的“存储/传输格式”。
在文件头看到 encoding="UTF-8",就是告诉程序:
“后面的文本内容用 UTF-8 编码,把字节流解析成 Unicode 码点,再渲染成真正的字符。”
UTF-8属于Unicode吗?
UTF-8 并不是“Unicode”本身,而是 Unicode 标准定义的一种 字符编码(Transformation Format),全称叫 UTF-8(Unicode Transformation Format – 8-bit)。
- Unicode:定义了一套“字符 ⇄ 码点”(code point)的映射表,比如 “A → U+0041”,“你 → U+4F60”。
- UTF-8:是把这些 Unicode 码点转换成 1~4 字节 的二进制序列的方式之一。
换句话说:
- Unicode 是一本“字符字典”,告诉你每个字符的编号(U+xxxx)。
- UTF-8 是把这些编号按照规则打包成字节流的“打包格式”。
除了 UTF-8,Unicode 还定义了其他几种打包格式:
- UTF-16(每个码点用 2 或 4 字节)
- UTF-32(每个码点固定用 4 字节)
所以,UTF-8 是实现 Unicode 字符集的三种主要编码之一,而不是 Unicode 本身。
七:什么是左值引用?什么是右值引用?区别在哪
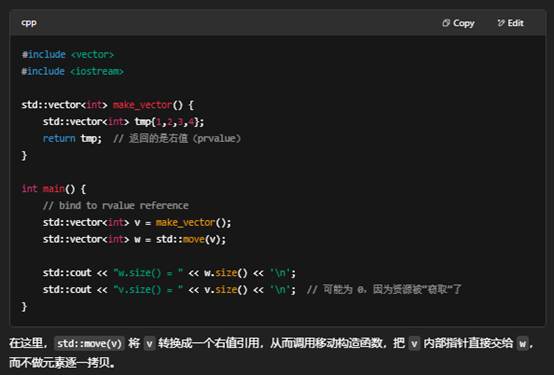
在 C++ 中,“引用”(reference)就是一个别名——它让你可以给一个已存在的对象取一个新名字。C++11 在原有“左值引用”(lvalue reference)的基础上,又引入了“右值引用”(rvalue reference),它们最大的区别就在于绑定对象类别不同,以及由此衍生出的语义用途也不一样:
一、左值引用(lvalue reference)
- 语法:T&
- 绑定规则:只能绑定到左值(lvalue),也就是具有持久存储、可取地址、有名字或能出现在赋值语句左边的表达式。
- 典型用途:
- 传参用来修改调用者的变量:
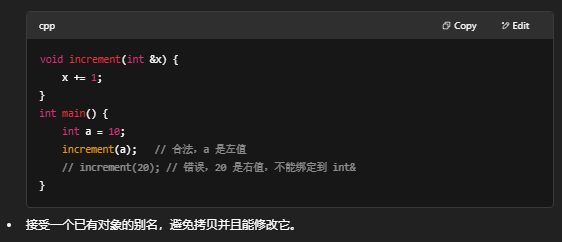
二、右值引用(rvalue reference)
- 语法:T&&
- 绑定规则:只能绑定到右值(rvalue),也就是临时对象、字面常量(如 20)、或 std::move(a) 之后返回的“可移动”对象。
- 典型用途:
- 实现移动语义(move semantics):在拷贝代价昂贵的类型(如 std::vector)上,把资源(内存、文件句柄等)“偷走”而不是复制。
- 完美转发(perfect forwarding):模板里用 T&& 接受任意值类别,再把它原样转发给另一个函数。

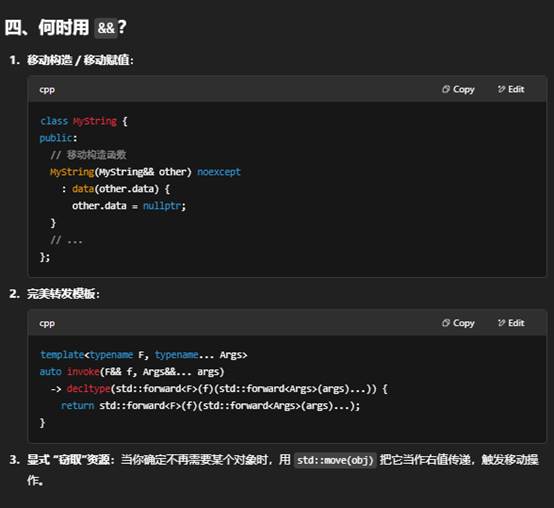
小结
- 左值引用 T&:给已有、持久的左值对象取别名,可以修改它。
- 右值引用 T&&:专门用来绑定右值(临时或可移动对象),核心在于移动语义与完美转发,让资源管理更高效。
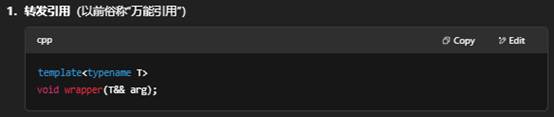
八:什么是完美转发?
“完美转发”(Perfect Forwarding)是 C++11 引入的一种技术,允许函数模板把参数“完完全全”、“原封不动”地转发给另一个函数——既保持左值/右值的语义,也保留 const/volatile 限定。它的核心要素是:
- 当模板参数 T 用于 T&& 时,参数 arg 会根据调用时传入的是左值还是右值推导出不同类型:
- 传入左值:T 推导为 引用类型(如 int&),此时 T&& 变成 int& &&,根据引用合成规则折叠为 int&。
- 传入右值:T 推导为 非引用类型(如 int),此时 T&& 即 int&&。
- std::forward
通过 std::forward<T>(arg),编译器会根据 T 的类型决定是把 arg 当作左值传递,还是把它当作右值移动传递。
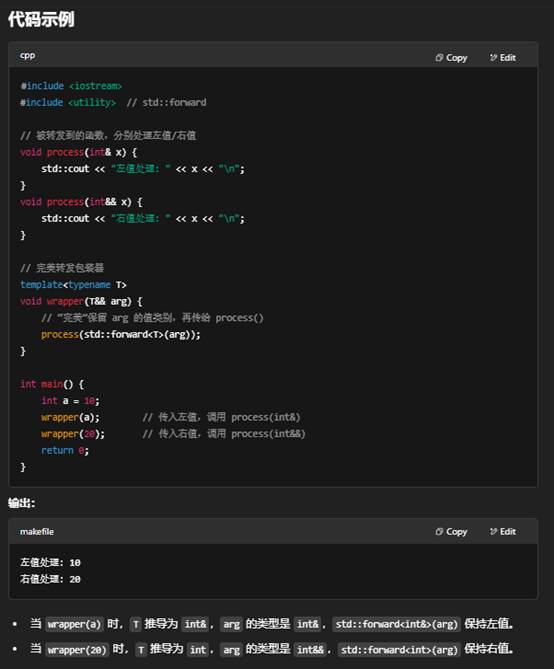
为什么需要完美转发?
- 避免不必要的拷贝/移动:传统地将所有参数都当作左值或右值传递,可能引发多余的拷贝或移动。
- 保留调用者本意:如果调用者传入的是右值(临时对象),你往往希望把它当作右值“移动”进去;如果传入的是左值,就应当保持左值语义。
- 通用代码库:在编写通用的模板库(比如工厂函数、容器、算法等)时,完美转发可让内部调用尽可能高效、语义正确。
小结
- 函数模板参数 用 T&& 来接收任意值类别的实参。
- 调用时 用 std::forward<T>(arg) 保持实参的左值/右值属性。
- 结果:被包装的函数(如 process)就能针对左值或右值各自优化或重载,达成“完美”转发。
九:什么是同一个作用域?
在 C++ 中,**作用域(scope)**就是一个名字(变量名、函数名、类型名……)被引入并且有效的区域。简单来说,作用域决定了“在哪儿可以访问这个名字”。
常见的几种作用域
- 全局作用域(global scope)
在所有函数和命名空间外部定义的名字,就属于全局作用域;从它被定义的点起,到整个程序结束,都可以访问。 - 命名空间作用域(namespace scope)
在某个 namespace { … } 块里定义的名字,只在该命名空间内可见(当然也可以用 using 或显式命名空间限定来访问)。 - 类作用域(class scope)
在类(或结构体)内部定义的成员函数、成员变量,都只在该类的内部或通过该类的对象/指针访问时可见。 - 函数作用域(function scope)
函数内部定义的名字(例如参数名、局部变量名),只在函数体内有效。 - 块作用域(block scope)
任何一对大括号 { … }(比如 if (...) { … }、for (…) { … })内部定义的名字,只在这一对大括号内可见。
“同一个作用域” 是什么意思?
两个名字如果是在同一对大括号(或同一个命名空间块)里声明的,就说它们处于“同一个作用域”。
- 如果你把两个函数的声明都写在全局最外层(或同一个 namespace 块里),它们就在同一个作用域,可以进行重载。
- 如果一个函数声明在全局作用域,另一个在某个命名空间里,它们不在同一个作用域;必须用 namespace::func 才能引用。
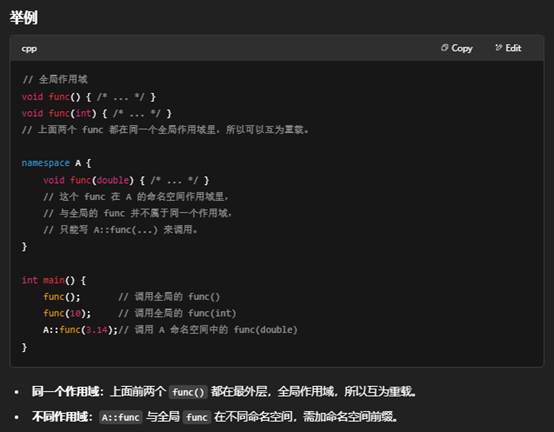
小结
- 作用域由花括号 {} 或 namespace … {} 划定。
- “同一个作用域”即“同一对 {} 或同一 namespace 块”内。
- 只有在同一个作用域中声明的名字,才互相可见、可重载(或隐藏)。
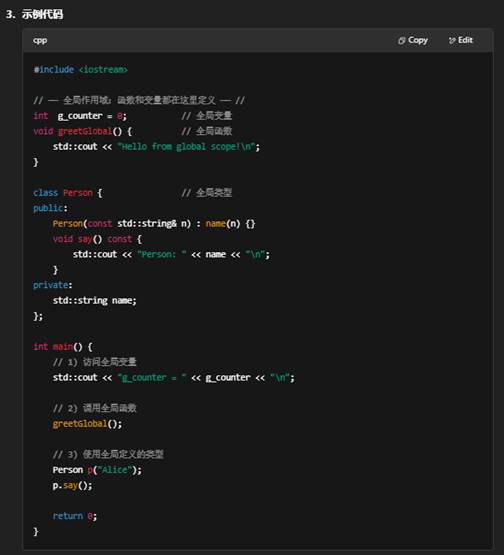
十:什么是全局作用域
在 C++ 中,全局作用域(Global Scope) 指的是在任何函数、类或命名空间之外的那块最外层区域。在全局作用域中声明的变量、函数或类型,具有以下特点:
- 可见性
- 在同一翻译单元(单个 .cpp 文件)里,任何地方(只要不被更内层作用域屏蔽)都能访问全局作用域中的名字。
- 如果在其他翻译单元里想使用,需要配合 extern 声明或把它放到头文件里并正确链接。
- 生命周期
- 全局变量从程序启动时就被分配,直到程序结束时才释放,生命周期覆盖整个程序执行期。
- 全局函数和类型自然“存在”于整个程序里,随时可被调用或实例化。
- 上面 g_counter、greetGlobal()、Person 都定义在全局作用域,所以无论在 main() 里,还是在其他非成员函数里,都可以直接访问它们。
-
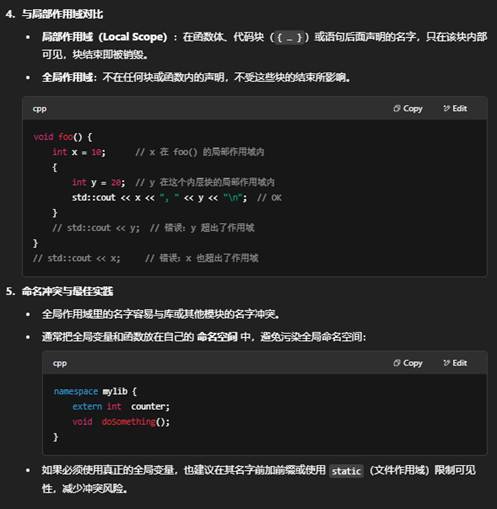
总结:
全局作用域 是程序中最外层的区域,放在这里的声明,对整个翻译单元(甚至多个翻译单元,经 extern)都是可见的,并且其生命周期与程序同长。
与之相对的 局部作用域 则只在小范围内可见且生存期有限。使用全局作用域时要谨慎,最好借助命名空间或文件作用域去控制可见性,避免命名冲突。
十一:除了main()前面的这一块属于全局作用域,其他的任何.h或者是.cpp文件中只要在任何函数、类或命名空间之外的那块最外层区域都属于全局作用域?
对,全局作用域并不局限于 main() 前面那几行,而是指在 任何 源文件(.cpp)或头文件(.h)里,只要 该声明或定义写在:
- 任意函数(包括 main)之外
- 任意类 或结构体之外
- 任意命名空间(显式的 namespace XXX { … })之外的顶层位置(也叫文件作用域/file scope),它就属于全局作用域,也就是全局命名空间(global namespace)。
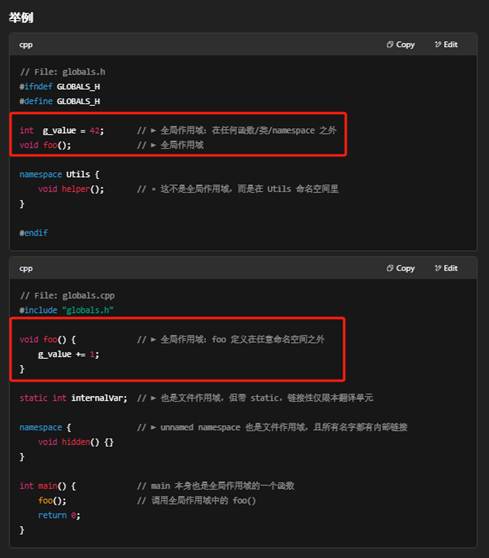
- g_value、foo()、main() 都是在全局作用域中声明/定义的。
- Utils::helper() 在显式命名空间里,不属于全局作用域。
- internalVar 虽然也是顶层声明,但因为加了 static,它的链接性(linkage)被限制在本 .cpp 文件;它仍然是文件作用域。
- namespace { … }(unnamed namespace)里声明的名字也只在本文件可见,但依然是顶层作用域。
小结
- “文件作用域”=顶层作用域=全局作用域,只要不在任何函数、类或(显式)命名空间内部。
- 放在头文件或源文件的最外层部分,都算全局作用域。
十二:黑箱白箱/黑盒白盒
“黑箱”原本是控制论和系统工程里的术语,用在编程里也是类似的意思:把一个功能模块(比如一个函数、一个类或一个库)当成“黑箱”使用,意味着:
- 不关心内部实现
- 你只知道它的输入是什么、输出是什么,而不需要了解它内部是如何一步步运算、做分支、管理内存的。
- 这样做可以减少认知负担,让你专注在整体架构和流程上。
- 只看接口
- “黑箱”对外暴露的就是函数签名(参数列表和返回类型)、文档里描述的行为和副作用(比如修改了哪些状态、是否会抛异常)。
- 调用者只要按照接口传入正确参数,就能得到正确结果。
- 好处:封装与复用
- 封装:隐藏细节,内部可以随时优化或改写,只要保证接口兼容,调用它的代码不用修改。
- 复用:当你习惯把某段逻辑封装成黑箱后,下次直接调用,避免重复造轮子。
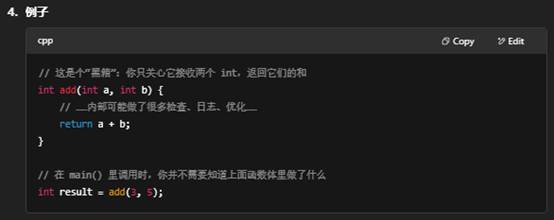
相对的,如果你打开这个“黑箱”——阅读甚至修改它的源码,理解其每行细节,就叫做“白箱”(White-box)或“透明箱”式使用。黑箱思想是软件工程里常用的抽象与封装原则,有助于降低系统复杂度。
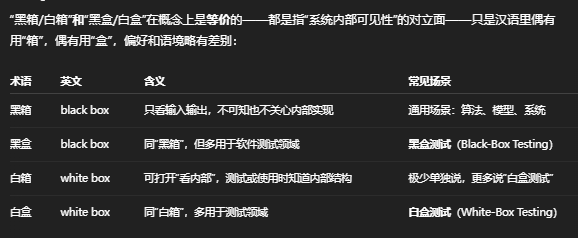
- 为什么两套说法都存在?
- “箱”字稍显抽象,更常用在“黑箱操作”“黑箱算法”等泛化场景;
- “盒”字则沿自“Black-box”直译,更常见于“黑盒测试/白盒测试”这类标准术语中。
- 实际工程中怎么选?
- 提到测试时,建议用 黑盒测试/白盒测试;
- 要表达“内部实现全然不露”的系统或组件,写成 黑箱系统/黑箱模型 更自然。
总之,四个词汇指向的是同一对立概念,只是“盒”“箱”二字在不同语境下的偏好而已。

















 5848
5848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









