







前言
在当今软硬件开发日益融合的时代,C++仍以其高性能、可控性与丰富的特性,成为系统软件、游戏引擎、嵌入式设备等领域的主力语言。对于初学者而言,面对其复杂的语法规则、丰富的标准库和多代特性,往往容易迷失在指针运算、内存管理、模板元编程等概念之中;而对于有经验的开发者,也常因对新标准、新范式了解不足而错失效率与安全的提升机会。
本篇文章基于作者在自学与项目实践过程中所遇到的疑难与思考,将 C++ 的核心能力要素、基础概念与进阶疑问全面梳理,力求做到:
-
体系化呈现:从“开发者应具备的能力”到“函数、结构体、指针、面向对象”等基础概念,再到“模板、并发、RAII、现代 C++ 特性”等进阶话题,层层递进、脉络清晰。
-
问题驱动:汇总学习过程中常见的提问与误区,让读者在阅读时即能自我检测理解盲点。
-
实用导向:结合示例与最佳实践,帮助你在今后的编码、调试与架构设计中少走弯路。
-
学习路径建议:针对不同阶段的学习者提供循序渐进的学习路线与资源推荐,让你做到有所学、有所问、有所悟。
无论你是初涉 C++、渴望打好根基,还是已有多年经验、希望掌握现代标准与高阶技巧,相信这份“C++ 基础概念整理及提问”都能成为你手边的思维导图与复习锦囊。愿它助你构建扎实的语言底座,提升编程效率,走得更远、更稳、更优雅。
本篇为学习提问篇,另一篇概念介绍篇:C++基础概念-CSDN博客
目录
3.为什么有的写 (*p).age,有的写 p->name?
5.智能指针(Smart Pointer)和原始指针(Raw Pointer)的区别
3.struct 的用法,以及为何用 struct 而不是 class?
4.如何在同一个项目中执行不同的main?除了把之前写的代码注释掉之外还有什么办法吗?
6.using namespace std; 什么时候不适用?
6.Encoding, UTF-8和Unicode是什么?UTF-8属于Unicode吗?
11.除了main()前面的这一块属于全局作用域,其他的任何.h或者是.cpp文件中只要在任何函数、类或命名空间之外的那块最外层区域都属于全局作用域?
3.示例中函数重载,如果把func(10)改为func(int a)会报错吗?
2. 访问权限:public,protected,private这三个都是围绕类来展开的吗,但是如果在全局作用域下面写这三个是不是就没有什么区别了?
4.构造函数(Constructor)与析构函数(Destructor)
7.冒泡排序中,两层for中的原理(即外层for和里层for)
基础概念提问
指针
1.为什么要先解引用 *p 再用 . 访问成员?
-
运算符只能用于对象本身,不能直接作用于指针。
-
*p是对指针的解引用,结果类型是它所指向的对象(即Person&),这时就能用.来访问成员:(*p).age = 31; // 先 (*p) 得到 Person 对象,再 .age->就是把这两步合并为一步,“取地址”与“解引用”合并成了直接访问成员。
2.指针是不是主要用来访问数组?单个变量能否直接赋值?
指针可以指向任何类型的对象——既可以是数组首元素,也可以是普通的单个变量、类实例、动态分配的内存等。
如果你操作的是本地的单个变量,像:
int age = 30;
age = 31; // 直接修改最简单
那当然没必要用指针去间接访问。
指针的作用主要在于:
- 动态分配:在堆上分配一块内存,必须通过指针来引用它;
- 函数间传递:如果想让函数内部修改调用处的变量,常通过指针参数或引用;
- 数据结构:链表、树、图等节点间通过指针连接;
- 多态:基类指针指向派生类对象,用于运行时多态。
结论:只有在需要“间接引用”或“动态管理”时才用指针,否则直接变量名赋值最简单。
3.为什么有的写 (*p).age,有的写 p->name?
这两种写法其实等价,都是先对指针 p 做“解引用”(得到它指向的对象),再访问该对象的成员:
(*p).age // 先 (*p),再 .age
p->age // 箭头运算符正是 (*p).age 的“语法糖”
为什么例子里同时出现两种?
- (*p).age = 31; 强调了解引用再访问成员的过程,写法上要加括号,否者 *p.age 会被错误解析。
- p->name = "Alice"; 就是箭头语法,编译器自动帮你做了解引用和再访问成员:
p->name // 等价于 (*p).name
推荐风格:
- 日常中只要指针指向的是类/结构体,就统一用 ->,既简洁又避免括号。
- 只有在讲解原理或演示 operator-> 重载时,才会写出 (*p).member。
小结
- 指针并不限于数组,单个变量完全可以直接赋值,指针主要用于需要间接访问或动态管理的场合。
- (*p).member 和 p->member 是一回事,后者是对前者的简写(语法糖),平时习惯用 ->。
4.指针访问数组时,只能访问和修改数组首元素吗?
不是的,指针只是存了数组第一个元素的地址,但利用 指针运算(也就是“指针加减”)就能访问数组中的任意元素。
1. 原理:指针加法
假设有一个整型数组:
int arr[5] = {10, 20, 30, 40, 50};
int* p = arr; // 等价于 int* p = &arr[0];
- p 当前指向 arr[0]。
- 指针加法:p + 1 会跳过一个 int 大小,指向 arr[1];
- 一般地,p + i 就指向 arr[i](前提是 0 <= i < 5)。
2. 访问和修改
#include <iostream>
using namespace std;
int main() {
int arr[5] = {10, 20, 30, 40, 50};
int* p = arr; // 指向 arr[0]
// 访问
cout << p[0] << endl; // 10
cout << p[2] << endl; // 30
cout << *(p + 4) << endl; // 50
// 修改
p[1] = 25; // 改变 arr[1]
*(p + 3) = 45; // 改变 arr[3]
// 验证
for (int i = 0; i < 5; ++i) {
cout << arr[i] << ' '; // 输出:10 25 30 45 50
}
cout << endl;
return 0;
}
- p[i] 就是 *(p + i) 的语法糖,用来访问第 i 个元素。
- 同理,你可以写 *(p + i) = newValue; 或者 p[i] = newValue;,都能修改对应元素。
3. 小结
- 指针本身只保存一个地址(初始时通常是数组首元素的地址)。
- 指针加法让你在内存中按元素大小“跳转”到数组的任意位置。
- 这样就能访问和修改整个数组,而不仅仅是第一个元素。
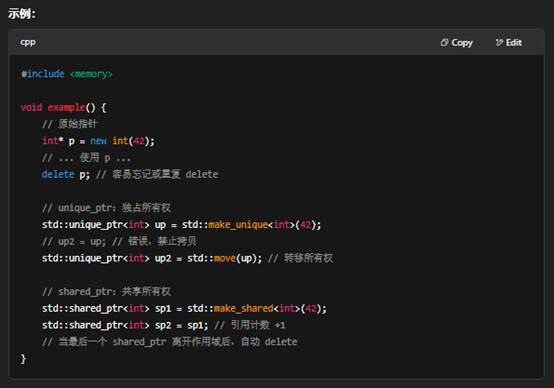
5.智能指针(Smart Pointer)和原始指针(Raw Pointer)的区别

6.为什么指针只是存了数组第一个元素的地址?
当你把一个数组名赋给一个指针变量时,发生的是“数组到指针”的衰变(decay)——它会变成第一个元素的地址:
int arr[5] = {10,20,30,40,50};
int* p = arr; // 等价于 int* p = &arr[0];
为什么这样设计?
- 类型匹配
- int* p 表示“指向 int 的指针”。
- arr 本身不是指针,但在大多数表达式里,它会被隐式转换为 “指向第一个元素的指针”——int*。
- 这样 p = arr; 就是把 &arr[0](类型为 int*)赋给 p。
- 方便遍历
- 数组在内存中是连续存放的:
[10][20][30][40][50]
↑ ↑ ↑ ↑ ↑
arr arr+1 arr+2 arr+3 arr+4
有了“首元素地址”后,通过指针加法(p + i)或下标语法(p[i])就能访问整个数组。
区分“数组地址”与“元素地址”
- arr 衰变为 &arr[0],类型是 int*。
- 如果你写 &arr,它的类型是 int (*)[5](指向整个 5 元素数组的指针),虽然数值上也指向同一块内存的起始地址,但类型不同,做指针算术时就不一样。
int (*pa)[5] = &arr; // pa 的类型是 “指向 5 个 int 的数组”
// pa + 1 会跳过整个数组(5 个 int),而 p + 1 只跳过 1 个 int
小结
- 指针保存的地址类型 由它的声明决定:
- int* p → 它存的是 “一个 int” 的地址,所以赋 arr 时得到的是 &arr[0]。
- int (*pArr)[5] → 它存的是 “一个长度为 5 的 int 数组” 的地址,所以赋 &arr。
- “数组名衰变为指针” 是 C/C++ 的语法规则,目的是方便你通过指针遍历和操作数组元素。
基础问题提问 Part1
1.C++ 面向对象的构建能力
C++ 支持面向对象编程(OOP),主要体现在以下几方面:
- 封装(Encapsulation)
- 用 class/struct 将数据与操作数据的函数(成员函数)组合在一起,并通过访问控制符 (public/protected/private) 隐藏内部细节。
- 继承(Inheritance)
- 派生类继承基类的成员,可以代码复用和扩展。支持单继承和多重继承(需注意菱形继承问题)。
- 多态(Polymorphism)
- 编译时多态:函数重载、运算符重载、模板实例化。
- 运行时多态:基类指针/引用调用派生类的虚函数,借助虚函数表(vtable)实现动态绑定。
- 抽象(Abstraction)
- 通过纯虚函数(virtual … = 0)定义接口,将具体实现留给派生类。
2.C++ 的基础特性
除了面向对象,C++ 语言本身还包含以下核心特性:
- 静态类型系统
- 编译期类型检查,auto 推导与显式类型声明并存。
- 指针与引用
- 直接操作内存地址(指针 T*),引用 T& 作为别名。
- 模板与泛型编程
- 函数模板、类模板,支持在编译期生成类型安全的代码。
- 标准模板库(STL)
- 容器(vector、map 等)、算法(std::sort、std::find_if)、迭代器。
- RAII(资源获取即初始化)
- 通过栈对象的构造/析构管理资源(文件、锁、内存),保证异常安全。
- 异常处理
- try/catch/throw 提供统一的错误处理机制。
- 现代语法糖(C++11 及以后)
- Lambda、智能指针(unique_ptr/shared_ptr)、右值引用 (T&&)、constexpr、enum class 等。
3.struct 的用法,以及为何用 struct 而不是 class?
在 C++ 中,struct 和 class 唯一的语法区别是默认的成员访问权限不同:
- struct:默认公有,即不加访问说明符的成员都是 public。
- class:默认私有,即不加访问说明符的成员都是 private。
用法上它们功能完全相同,都可以定义成员变量、成员函数、继承、多态等。
常见习惯:
- 简单的数据聚合(Plain-Old Data)或只包数据、少逻辑的类型常用 struct;
- 需要封装、接口与实现分离、强访问控制的类常用 class。
struct S {
int x; // 等价于 public: int x;
};
class C {
int x; // 等价于 private: int x;
public:
void set(int v) { x = v; }
};
4.如何在同一个项目中执行不同的main?除了把之前写的代码注释掉之外还有什么办法吗?
在一个 C++ 项目里,编译、链接阶段只能有一个有效的 main,否则会报“重定义 entry point”之类的错误。除了“注释掉”不想跑的那段 main,常用的几种做法是:
1. 把不同的 main 放在不同的 .cpp 里,按需“排除”/“包含”文件
-
实现方式
-
每个
main写在独立的源文件里:src/ main1.cpp // 包含 int main() { … } main2.cpp // 包含 int main() { … } utils.cpp …在 Visual Studio 里右键某个 .cpp → 属性 → 排除生成(Exclude From Build),就可以在不同配置下只编译你想跑的那个 main。 优点: 不改代码,只改项目属性; 各个 main 之间互不干扰; 缺点:多了几个配置管理。
-
2. 用预处理器宏控制哪段 main 生效
// 在 project Settings → C/C++ → Preprocessor → Preprocessor Definitions
// 为不同的 Configuration 定义 RUN_MAIN1 或 RUN_MAIN2
#if defined(RUN_MAIN1)
int main() {
// … main1 的逻辑 …
return 0;
}
#elif defined(RUN_MAIN2)
int main() {
// … main2 的逻辑 …
return 0;
}
#endif
-
实现方式
-
给不同的 Debug/Release 配置分别定义宏
RUN_MAIN1、RUN_MAIN2。 -
编译时只有对应宏那段代码会被编译。
-
-
优点:不用改文件排除设置,全部源文件都在;
-
缺点:要手动切换预处理宏。
3. 统一一个 “真” main,把其他入口做成普通函数
// entrypoints.h
int main1();
int main2();
// main1.cpp
#include "entrypoints.h"
int main1() {
// …
return 0;
}
// main2.cpp
#include "entrypoints.h"
int main2() {
// …
return 0;
}
// main.cpp
#include "entrypoints.h"
int main() {
#ifdef RUN_MAIN1
return main1();
#elif defined(RUN_MAIN2)
return main2();
#else
// 默认或报错
return 0;
#endif
}
-
优点:
-
源文件都编译,只改
main.cpp的切换逻辑; -
非常灵活,可在运行时或编译时切换。
-
-
缺点:有个总
main,其它入口变成子函数,略微改动逻辑。
4. 用 VS Solution 里多个 Project
-
做法:
-
把每个
main放到不同的 Project(比如Proj_Main1、Proj_Main2),都放在同一个 Solution 里。 -
切换启动项目(右键 Project → Set as Startup Project)。
-
-
优点:管理清晰,每个 exe 独立;
-
缺点:项目数量多,维护稍繁琐。
推荐
-
如果只是偶尔切换,方法①“排除/包含文件” 最直观——不改代码,只在文件属性里勾选。
-
如果需要在同一套代码里频繁切换入口,方法②“预处理宏+多配置” 或 方法③“统一 main 调度” 比较灵活。
-
而将每个入口做成独立 Project(方法④)适合长期并行维护多个可执行文件的场景。
5.什么是“语法糖”?
-
语法糖(syntactic sugar) 指编程语言中用来让代码更易读、更简洁的语法,它本质上并不增加新能力,而是由编译器转换成更底层、更冗长的等价代码。
-
这里的
ptr->member就是对(*ptr).member的语法糖:ptr->name // 等价于 (*ptr).name ptr->func() // 等价于 (*ptr).func()
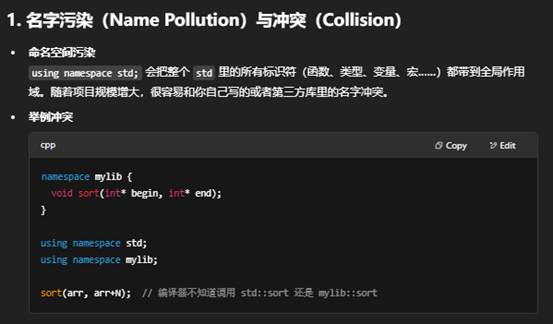
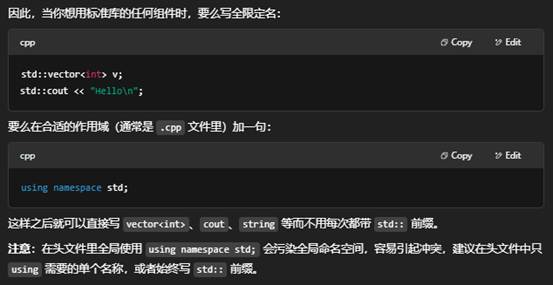
6.using namespace std; 什么时候不适用?
在 C++ 里,using namespace std; 的确可以让你在后面写代码时不用每次都敲 std::,比如

其背后有几个主要原因和注意事项:
2. 可读性与维护性
- 显式来源更清晰
当你在代码里看到 std::string、std::move、std::map,立刻就能知道这是标准库的类型或函数;如果都省掉了前缀,读者必须去猜它们来自哪个命名空间。 - 大规模团队协作
在多人或跨模块协作时,大家更倾向于显式地写 std::,以防某人无意间引入了同名的自定义类型或函数,导致别处编译出奇怪的错误。
3. 头文件(.h/.hpp)绝对忌用
千万不要在头文件里写 using namespace std;,因为:
- 它会“传染”所有包含这个头文件的源文件。
- 你难以预料在别的源文件里会因此引入哪些名字冲突。
如果真的想让头文件里少写几次 std::,也只能用更局部的 using std::string; 这样的 using 声明,并且也要非常小心只引入少量标识符。
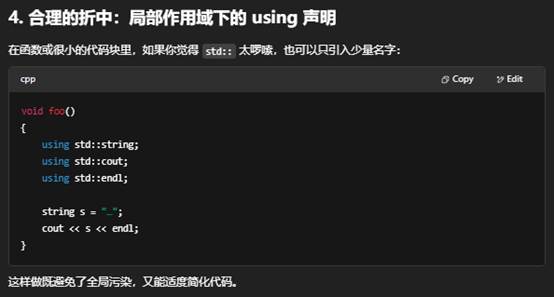
何时不该用 using namespace std;
- 任何头文件 —— 都不要写。
- 大型项目的全局或命名空间顶层 —— 会影响所有代码。
- 当你的工程里有多个命名空间,且有可能重名时 —— 绝对不要。
总结
- 小型、临时的示例代码(教学、Demo、快速原型)可以用 using namespace std;,让示例更简洁;
- 生产级代码、库/框架、头文件 则应显式地用 std:: 或者局部 using std::xxx;,以提升可读性、可维护性并防止名字冲突。
7.什么是自定义Node?
“自定义 Node”就是自己用 struct 或 class 定义一个“节点”类型,用来在链表、树、图等数据结构里串联各个元素。它不是标准库里提供的,而是程序员根据需求手写的。
1. 为什么要自定义 Node?
标准库里有像 std::list 这样封装好的链表容器,但如果你想自己实现一个链表学习原理,或者要在一个特殊场景下改造链表,就需要自己定义节点类型。
2. 常见的单向链表 Node 例子
// 一个简单的单向链表节点
template<typename T>
struct Node {
T val; // 节点保存的数据
Node* next; // 指向下一个节点的指针
// 构造函数:初始化 val,并让 next 指向空
Node(const T& v)
: val(v), next(nullptr)
{}
};
val:存放用户关心的数据,比如 int、string、或自定义对象。
next:指向链表中下一个节点,或为 nullptr 表示到达链表尾部。
3. 如何用自定义 Node 搭建链表?
#include <iostream>
int main() {
// 1) 创建三个节点
Node<int>* n1 = new Node<int>(10);
Node<int>* n2 = new Node<int>(20);
Node<int>* n3 = new Node<int>(30);
// 2) 串联它们
n1->next = n2;
n2->next = n3;
// 3) 遍历并打印
for (Node<int>* p = n1; p != nullptr; p = p->next) {
std::cout << p->val << ' ';
}
// 输出:10 20 30
// 4) 记得释放内存
delete n1;
delete n2;
delete n3;
}
4. 扩展:双向链表节点
如果要在链表中双向遍历,就再加一个 prev 指针:
template<typename T>
struct DNode {
T val;
DNode* prev; // 指向前一个节点
DNode* next; // 指向下一个节点
DNode(const T& v)
: val(v), prev(nullptr), next(nullptr)
{}
};
5. 小结
- “自定义 Node”:自己写 struct Node{…}; 来描述“节点”是什么。
- 用途广泛:学习链表原理、实现各种链式或树形数据结构。
- 与 STL 区别:STL 已经封装好,你只要直接用;自定义则可完全控制底层逻辑。
8.std是什么意思?
在 C++ 中,std 是“standard”(标准)的缩写,用来表示标准库所定义的命名空间(namespace)。
- 命名空间的作用是把一组相关的名字(类、函数、常量、对象等)组织在一起,避免与其他库或用户定义的名字冲突。
- C++ 标准库里的所有内容都放在 std 命名空间下,比如:
- 容器:std::vector、std::map
- 输入输出:std::cout、std::cin
- 字符串:std::string
- 算法:std::sort、std::find
- 智能指针:std::unique_ptr、std::shared_ptr
- …等等
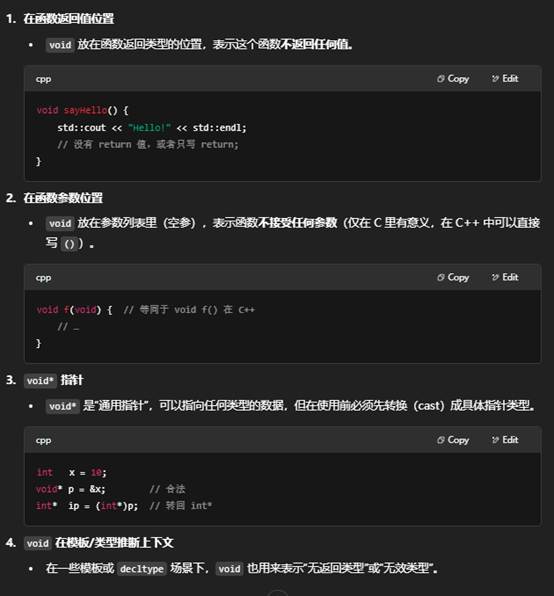
9.所有void开头的都是属于函数?
不是的,并非凡是以 void 开头的语句都是函数。在 C++ 中,void 本身只是一个“无类型”(no-type)的标识符,常见用法有几种,不同用法对应不同的声明:
| 形式 | 含义 | 示例 |
|---|---|---|
void f(); | 函数声明:返回类型是 void 的函数 f | cpp<br>void sayHello(); // 声明一个不返回值的函数<br> |
void* p; | 指针声明:指向任意类型的通用指针 p | cpp<br>void* buffer = malloc(1024);<br> |
static_cast<void>(expr); | 丢弃值:把 expr 的结果转换成 void | cpp<br>static_cast<void>(someFunction());<br> |
在参数列表中 void | 无参函数(C 风格):表示此函数不接受任何参数 | cpp<br>void foo(void); // 在 C++ 中写成 void foo() 等价<br> |
template<typename T> using void_t = void; | 类型别名:元编程中占位用 | 见 <type_traits> 中的 void_t |
怎么区分函数声明?
只有“标识符后紧跟圆括号”的,才是函数(或函数指针):
函数声明/定义:
void f(); // 声明
void f() { … } // 定义
函数指针:
void (*fp)(); // 指向无参无返回函数的指针
而像 void* p;、void* foo(int);(返回 void* 的函数)就不是“无返回值的函数”,要注意 void* 与 void 的区分。
小结
- void 单独 出现在函数名前,才表示“这是个不返回任何值的函数”。
- 如果是 void*,那是“指向任意类型的指针”。
- 而且函数声明/定义能被识别的关键在于——名字后面有 ()。
基础问题提问 Part 2
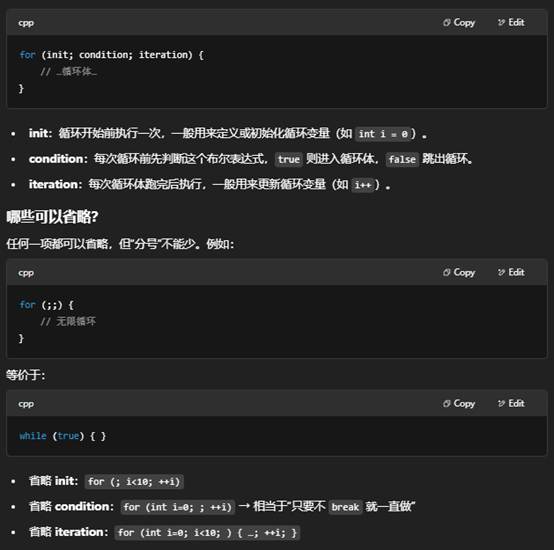
1.for 语句的三个“部分”是否都必须写?
2.while 和 if 的“条件”写法
- if (condition)
- while (condition)
两者的括号里都只允许出现一个能转换为 bool 的表达式(条件),不能写三段式。常见写法包括:
- 关系表达式: i < 5、ptr != nullptr
- 逻辑表达式: x>0 && x<10、!flag
- 函数返回值: if (read() > 0) …
你可以把多个判断用逻辑运算符 &&、||、! 串起来,但整个 (...) 只有一个“条件表达式”。
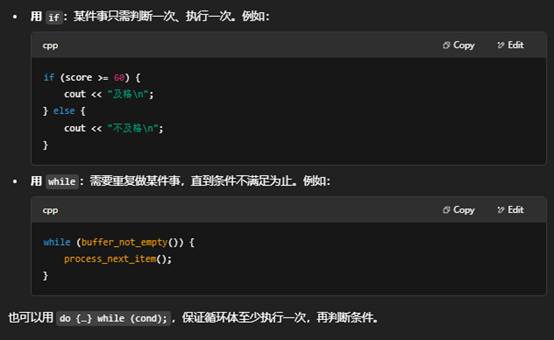
3.while vs. if,何时用哪一个?

小结
- for(...) 括号里可写三段,也可各自省略,但之间的分号不能少。
- if(...) 和 while(...) 括号内都只要一个布尔表达式(可以通过 &&/||/! 组合)。
- if 用于做一次性的条件分支;while 用于在条件为真时重复执行循环体。
4.Class和void的区别是什么?
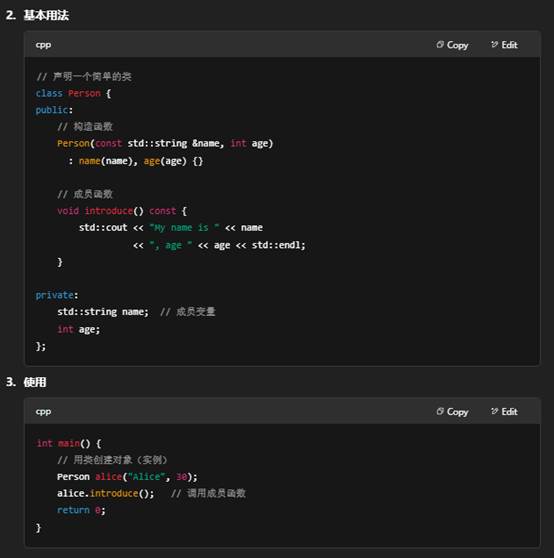
在 C++(以及大多数面向对象语言)里,class 和 void 是两个完全不同层面的关键字,分别用于类型定义和类型说明。
一、class —— 定义“类”这种用户自定义类型
- 作用
- class 用来声明一个“类”(class),它是 C++ 的核心——封装数据(成员变量)和行为(成员函数)的模板。
- 通过 class,你可以创建任意复杂度的类型,实现封装(encapsulation)、继承(inheritance)、多态(polymorphism)等面向对象特性。
二、void —— 表示“没有类型”或“空”
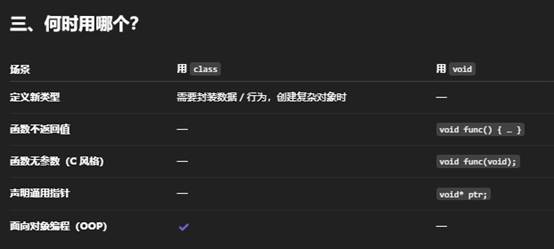
小结
- class:一种用户自定义的类型,用于封装成员变量和成员函数,是面向对象的基石。
- void:一种类型说明符,表示“没有具体类型”——常用于标记“无返回值的函数”或“通用指针”。
它们在语法上和语义上完全不冲突,经常在同一份代码里“组合”使用:用 class 定义类型,用 void 指定那些不需要返回值的成员函数。
5.介绍Json和XML
JSON(JavaScript Object Notation)
定义
- 一种轻量级的数据交换格式,以文本形式表示结构化数据。
- 源自 JavaScript,但与语言无关,支持多数编程语言。
特点
- 简洁:使用少量符号,易读易写。
- 数据模型:仅支持两种结构:
- 对象(由 {} 包围,内部是键–值对,如 {"key": value})
- 数组(由 [] 包围,内部是按顺序的值列表,如 [1,2,3])
- 数据类型:字符串、数值、布尔、空、对象、数组。
- 无模式(Schema-less):不强制定义字段类型或顺序。
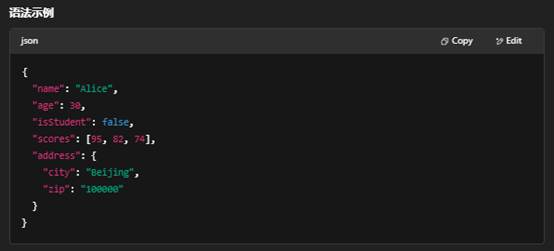
优缺点
- 优点:体积小、解析快、与现代 Web/REST API 天然契合。
- 缺点:不支持注释;对非常复杂的文档标记(如文档格式)不如 XML 灵活。
应用场景
- Web 前后端数据交换(AJAX/RESTful API)。
- 配置文件(如 .eslintrc.json、.babelrc)。
- NoSQL 数据库(MongoDB 存储的是 BSON,一种二进制 JSON 变体)。
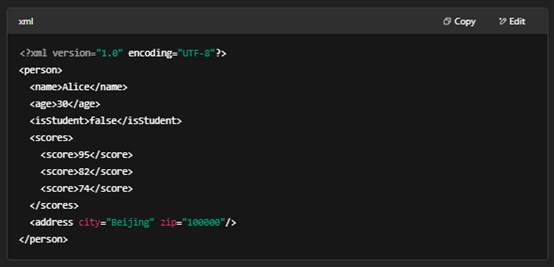
XML(eXtensible Markup Language)
定义
- 一种可扩展的、标记型的文本格式,用来表示复杂的文档和数据。
- 由 W3C 标准化,强调可读性和可验证性。
特点
- 标签(Tag)结构:数据通过开始标签 <tag> 与结束标签 </tag> 标识,支持自定义标签名。
- 层次化:天然树状结构,适合描述文档型数据(如网页、文档、配置)。
- DTD/XSD:可配合文档类型定义(DTD)或 XML Schema(XSD)进行校验,保证结构与数据类型正确。
- 可混合内容:标签内部既可含文本也可嵌套子元素。
语法示例
优缺点
- 优点:标签自描述、支持注释、标准化的校验机制(XSD)、可混合文本和子元素。
- 缺点:冗长(标签成对出现)、解析比 JSON 慢、对简单数据交换稍显臃肿。
应用场景
- 配置文件(如 Ant、Maven 的 pom.xml)。
- 文档格式(如 XHTML、SVG、Office Open XML)。
- 企业级 Web 服务(SOAP,多用 XML 构建请求与响应)。
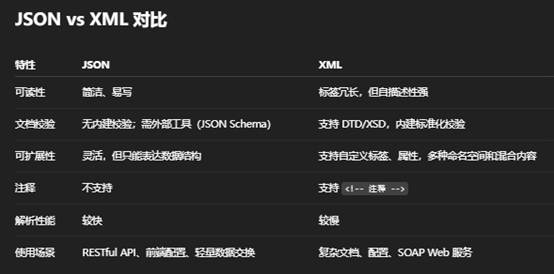
总结
- 选择 JSON:当你追求轻量、快速、与现代 Web/REST 接口无缝集成时。
- 选择 XML:当你需要严谨的结构校验、混合内容文档或标准化的企业级消息格式时。
6.Encoding, UTF-8和Unicode是什么?UTF-8属于Unicode吗?
Unicode 和 UTF-8 经常一起出现,但它们指的并不完全相同:
1. Unicode:字符集与代码点
- Unicode 是一个国际标准,定义了全球绝大多数书写系统中所有字符的“码点”(code point)。
- 每个字符被分配一个唯一的编号,记作 U+XXXX,其中 XXXX 是 16 进制数。例如:
- U+0041 → 拉丁字母大写 A
- U+4F60 → 中文“你”
- U+1F600 → 表情“😀”
- 注意:
- Unicode 本身只是一张“表”和一套规范,不规定具体在内存或文件里如何存储这些码点。
- Unicode 的范围很大,目前可用的码点超过 140 000 个,分布在多个平面(Plane 0…Plane 16)。
2. 字符编码(Encoding)
要把这些“码点”保存到磁盘或发送到网络上,必须把它们转换成字节序列,这就叫字符编码。常见的 Unicode 编码包括:
| 名称 | 描述 |
| UTF-8 | 可变长度编码:1~4 个字节表示一个码点。ASCII 范围(U+0000…U+007F)用单字节,高位字符用多字节。 |
| UTF-16 | 可变长度:2 或 4 个字节。BMP(基本多文种平面;U+0000…U+FFFF)用 2 字节,超出部分用一对代理项(surrogate pair)。 |
| UTF-32 | 固定 4 字节:每个码点都占用 4 字节。查表速度最快,但空间利用率最低。 |
3. 为什么选择 UTF-8?
- 向后兼容 ASCII:U+0000…U+007F 区间和 ASCII 完全相同,用单字节保存。
- 节省空间:对于英文文本,几乎和 ASCII 一样小;对多数字母文字也比 UTF-32 紧凑。
- 广泛支持:几乎所有 Web、Unix/Linux、现代编程语言和库都默认使用 UTF-8。
- 自同步性:从任意一个字节读取即可判断这是一个新字符的开始还是续字节,便于流式处理。
4. UTF-8 的编码规则示例
| 字节数 | 码点范围 | 编码格式(二进制) |
| 1 | U+0000 … U+007F | 0xxxxxxx |
| 2 | U+0080 … U+07FF | 110xxxxx 10xxxxxx |
| 3 | U+0800 … U+FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | U+10000 … U+10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
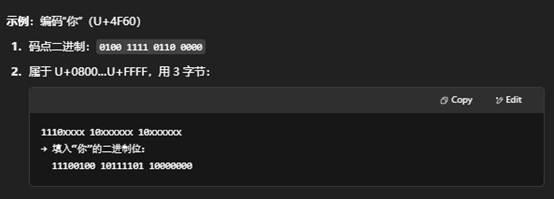
5. 小结
- Unicode:定义“字符 ↔ 码点”的映射,是字符的“编号表”。
- UTF-8:把这些码点编码成 1~4 个字节的序列,是字符的“存储/传输格式”。
在文件头看到 encoding="UTF-8",就是告诉程序:
“后面的文本内容用 UTF-8 编码,把字节流解析成 Unicode 码点,再渲染成真正的字符。”
UTF-8属于Unicode吗?
UTF-8 并不是“Unicode”本身,而是 Unicode 标准定义的一种 字符编码(Transformation Format),全称叫 UTF-8(Unicode Transformation Format – 8-bit)。
- Unicode:定义了一套“字符 ⇄ 码点”(code point)的映射表,比如 “A → U+0041”,“你 → U+4F60”。
- UTF-8:是把这些 Unicode 码点转换成 1~4 字节 的二进制序列的方式之一。
换句话说:
- Unicode 是一本“字符字典”,告诉你每个字符的编号(U+xxxx)。
- UTF-8 是把这些编号按照规则打包成字节流的“打包格式”。
除了 UTF-8,Unicode 还定义了其他几种打包格式:
- UTF-16(每个码点用 2 或 4 字节)
- UTF-32(每个码点固定用 4 字节)
所以,UTF-8 是实现 Unicode 字符集的三种主要编码之一,而不是 Unicode 本身。
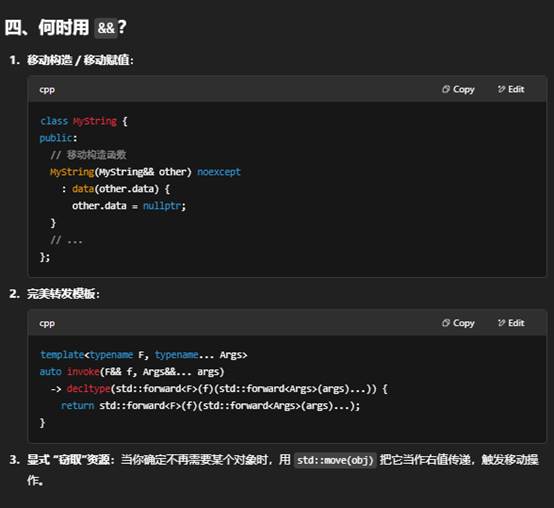
7.什么是左值引用?什么是右值引用?区别在哪
在 C++ 中,“引用”(reference)就是一个别名——它让你可以给一个已存在的对象取一个新名字。C++11 在原有“左值引用”(lvalue reference)的基础上,又引入了“右值引用”(rvalue reference),它们最大的区别就在于绑定对象类别不同,以及由此衍生出的语义用途也不一样:
一、左值引用(lvalue reference)
- 语法:T&
- 绑定规则:只能绑定到左值(lvalue),也就是具有持久存储、可取地址、有名字或能出现在赋值语句左边的表达式。
- 典型用途:
- 传参用来修改调用者的变量:
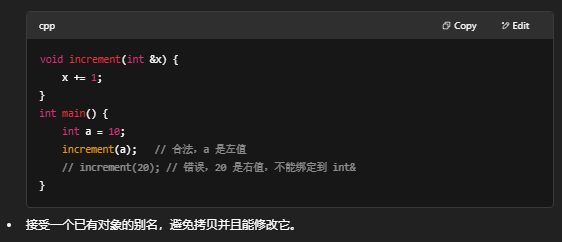
二、右值引用(rvalue reference)
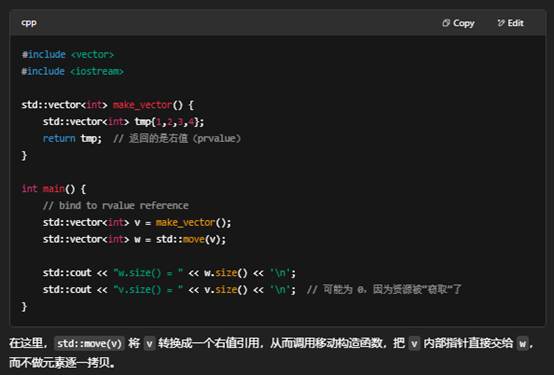
- 语法:T&&
- 绑定规则:只能绑定到右值(rvalue),也就是临时对象、字面常量(如 20)、或 std::move(a) 之后返回的“可移动”对象。
- 典型用途:
- 实现移动语义(move semantics):在拷贝代价昂贵的类型(如 std::vector)上,把资源(内存、文件句柄等)“偷走”而不是复制。
- 完美转发(perfect forwarding):模板里用 T&& 接受任意值类别,再把它原样转发给另一个函数。

小结
- 左值引用 T&:给已有、持久的左值对象取别名,可以修改它。
- 右值引用 T&&:专门用来绑定右值(临时或可移动对象),核心在于移动语义与完美转发,让资源管理更高效。
8.什么是完美转发?
“完美转发”(Perfect Forwarding)是 C++11 引入的一种技术,允许函数模板把参数“完完全全”、“原封不动”地转发给另一个函数——既保持左值/右值的语义,也保留 const/volatile 限定。它的核心要素是:
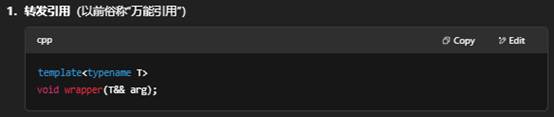
- 当模板参数 T 用于 T&& 时,参数 arg 会根据调用时传入的是左值还是右值推导出不同类型:
- 传入左值:T 推导为 引用类型(如 int&),此时 T&& 变成 int& &&,根据引用合成规则折叠为 int&。
- 传入右值:T 推导为 非引用类型(如 int),此时 T&& 即 int&&。
- std::forward
通过 std::forward<T>(arg),编译器会根据 T 的类型决定是把 arg 当作左值传递,还是把它当作右值移动传递。
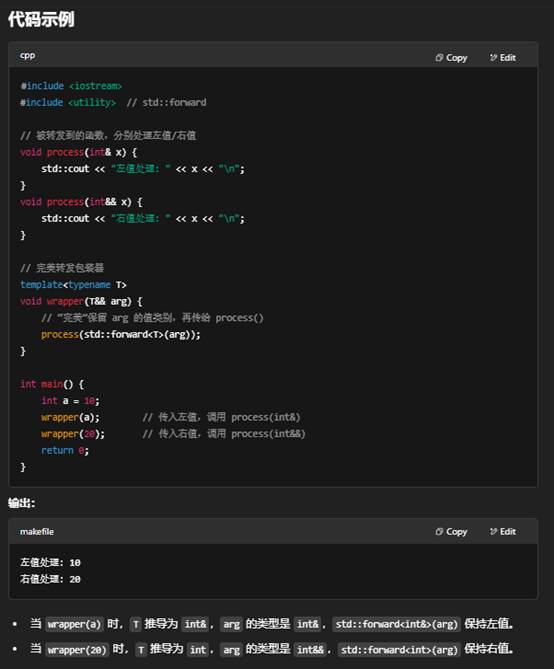
为什么需要完美转发?
- 避免不必要的拷贝/移动:传统地将所有参数都当作左值或右值传递,可能引发多余的拷贝或移动。
- 保留调用者本意:如果调用者传入的是右值(临时对象),你往往希望把它当作右值“移动”进去;如果传入的是左值,就应当保持左值语义。
- 通用代码库:在编写通用的模板库(比如工厂函数、容器、算法等)时,完美转发可让内部调用尽可能高效、语义正确。
小结
- 函数模板参数 用 T&& 来接收任意值类别的实参。
- 调用时 用 std::forward<T>(arg) 保持实参的左值/右值属性。
- 结果:被包装的函数(如 process)就能针对左值或右值各自优化或重载,达成“完美”转发。
9.什么是同一个作用域?
在 C++ 中,**作用域(scope)**就是一个名字(变量名、函数名、类型名……)被引入并且有效的区域。简单来说,作用域决定了“在哪儿可以访问这个名字”。
常见的几种作用域
- 全局作用域(global scope)
在所有函数和命名空间外部定义的名字,就属于全局作用域;从它被定义的点起,到整个程序结束,都可以访问。 - 命名空间作用域(namespace scope)
在某个 namespace { … } 块里定义的名字,只在该命名空间内可见(当然也可以用 using 或显式命名空间限定来访问)。 - 类作用域(class scope)
在类(或结构体)内部定义的成员函数、成员变量,都只在该类的内部或通过该类的对象/指针访问时可见。 - 函数作用域(function scope)
函数内部定义的名字(例如参数名、局部变量名),只在函数体内有效。 - 块作用域(block scope)
任何一对大括号 { … }(比如 if (...) { … }、for (…) { … })内部定义的名字,只在这一对大括号内可见。
“同一个作用域” 是什么意思?
两个名字如果是在同一对大括号(或同一个命名空间块)里声明的,就说它们处于“同一个作用域”。
- 如果你把两个函数的声明都写在全局最外层(或同一个 namespace 块里),它们就在同一个作用域,可以进行重载。
- 如果一个函数声明在全局作用域,另一个在某个命名空间里,它们不在同一个作用域;必须用 namespace::func 才能引用。
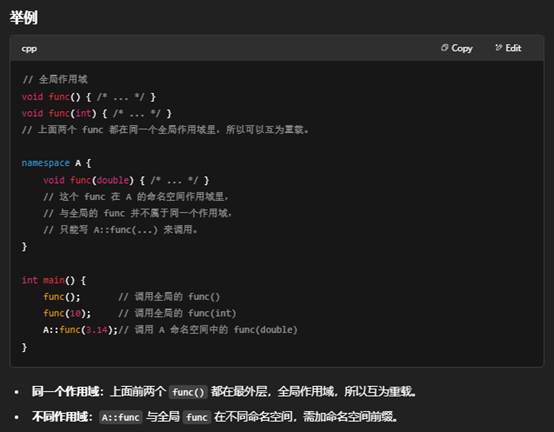
小结
- 作用域由花括号 {} 或 namespace … {} 划定。
- “同一个作用域”即“同一对 {} 或同一 namespace 块”内。
- 只有在同一个作用域中声明的名字,才互相可见、可重载(或隐藏)。
10.什么是全局作用域
在 C++ 中,全局作用域(Global Scope) 指的是在任何函数、类或命名空间之外的那块最外层区域。在全局作用域中声明的变量、函数或类型,具有以下特点:
- 可见性
- 在同一翻译单元(单个 .cpp 文件)里,任何地方(只要不被更内层作用域屏蔽)都能访问全局作用域中的名字。
- 如果在其他翻译单元里想使用,需要配合 extern 声明或把它放到头文件里并正确链接。
- 生命周期
- 全局变量从程序启动时就被分配,直到程序结束时才释放,生命周期覆盖整个程序执行期。
- 全局函数和类型自然“存在”于整个程序里,随时可被调用或实例化。
- 上面 g_counter、greetGlobal()、Person 都定义在全局作用域,所以无论在 main() 里,还是在其他非成员函数里,都可以直接访问它们。
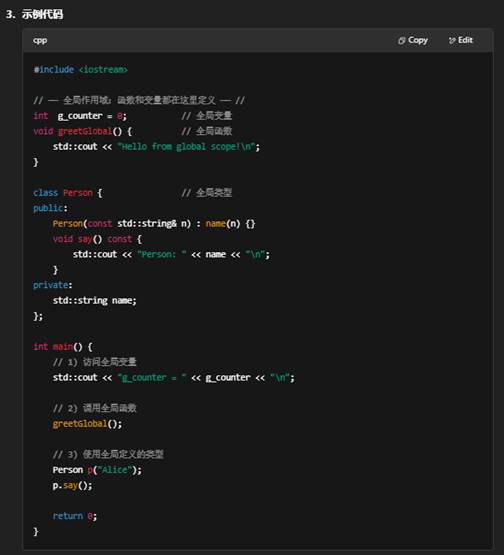
-
总结:
全局作用域 是程序中最外层的区域,放在这里的声明,对整个翻译单元(甚至多个翻译单元,经 extern)都是可见的,并且其生命周期与程序同长。
与之相对的 局部作用域 则只在小范围内可见且生存期有限。使用全局作用域时要谨慎,最好借助命名空间或文件作用域去控制可见性,避免命名冲突。
11.除了main()前面的这一块属于全局作用域,其他的任何.h或者是.cpp文件中只要在任何函数、类或命名空间之外的那块最外层区域都属于全局作用域?
对,全局作用域并不局限于 main() 前面那几行,而是指在 任何 源文件(.cpp)或头文件(.h)里,只要 该声明或定义写在:
- 任意函数(包括 main)之外
- 任意类 或结构体之外
- 任意命名空间(显式的 namespace XXX { … })之外的顶层位置(也叫文件作用域/file scope),它就属于全局作用域,也就是全局命名空间(global namespace)。
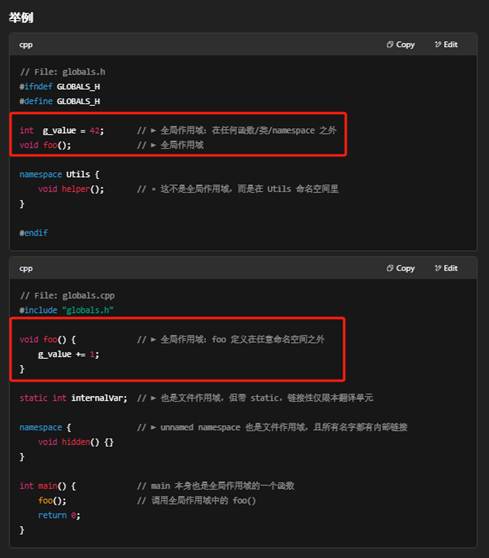
- g_value、foo()、main() 都是在全局作用域中声明/定义的。
- Utils::helper() 在显式命名空间里,不属于全局作用域。
- internalVar 虽然也是顶层声明,但因为加了 static,它的链接性(linkage)被限制在本 .cpp 文件;它仍然是文件作用域。
- namespace { … }(unnamed namespace)里声明的名字也只在本文件可见,但依然是顶层作用域。
小结
- “文件作用域”=顶层作用域=全局作用域,只要不在任何函数、类或(显式)命名空间内部。
- 放在头文件或源文件的最外层部分,都算全局作用域。
12.黑箱白箱/黑盒白盒
“黑箱”原本是控制论和系统工程里的术语,用在编程里也是类似的意思:把一个功能模块(比如一个函数、一个类或一个库)当成“黑箱”使用,意味着:
- 不关心内部实现
- 你只知道它的输入是什么、输出是什么,而不需要了解它内部是如何一步步运算、做分支、管理内存的。
- 这样做可以减少认知负担,让你专注在整体架构和流程上。
- 只看接口
- “黑箱”对外暴露的就是函数签名(参数列表和返回类型)、文档里描述的行为和副作用(比如修改了哪些状态、是否会抛异常)。
- 调用者只要按照接口传入正确参数,就能得到正确结果。
- 好处:封装与复用
- 封装:隐藏细节,内部可以随时优化或改写,只要保证接口兼容,调用它的代码不用修改。
- 复用:当你习惯把某段逻辑封装成黑箱后,下次直接调用,避免重复造轮子。
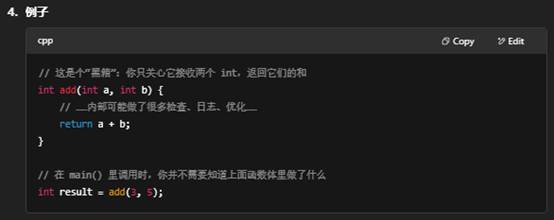
相对的,如果你打开这个“黑箱”——阅读甚至修改它的源码,理解其每行细节,就叫做“白箱”(White-box)或“透明箱”式使用。黑箱思想是软件工程里常用的抽象与封装原则,有助于降低系统复杂度。
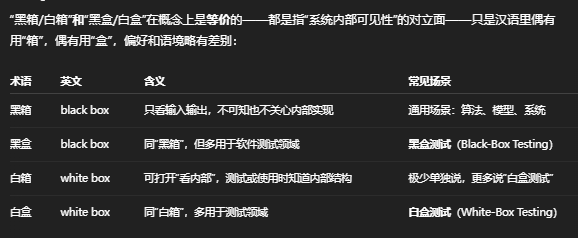
- 为什么两套说法都存在?
- “箱”字稍显抽象,更常用在“黑箱操作”“黑箱算法”等泛化场景;
- “盒”字则沿自“Black-box”直译,更常见于“黑盒测试/白盒测试”这类标准术语中。
- 实际工程中怎么选?
- 提到测试时,建议用 黑盒测试/白盒测试;
- 要表达“内部实现全然不露”的系统或组件,写成 黑箱系统/黑箱模型 更自然。
总之,四个词汇指向的是同一对立概念,只是“盒”“箱”二字在不同语境下的偏好而已。
核心概念提问
函数提高
1. 什么是重载?
在 C++ 中,“重载”(Overloading)指的是在同一作用域内,同名的函数或运算符可以根据参数类型或参数个数的不同,绑定到不同的实现上。编译器在看到调用时,会根据传入实参的类型和数量,选择最合适的那个版本。
一、重载函数/函数重载(Function Overloading)
- 定义
同一个作用域里,允许多个同名函数只要它们的参数列表(类型、顺序、个数或顶层 const/引用修饰)不同,就构成重载。 - 规则
- 重载函数的 返回类型 可以相同,也可以不同;但不能仅凭返回类型来区分重载。
- 参数列表必须至少在一个参数的类型、顺序或个数上与其他重载版本有所区别。
- 默认参数会参与匹配,但可能导致二义;一般尽量避免让默认参数引起调用歧义。
- 示例:
// 版本 ①:两个 int 相加 int add(int a, int b) { return a + b; } // 版本 ②:两个 double 相加 double add(double a, double b) { return a + b; } // 版本 ③:三个 int 相加 int add(int a, int b, int c) { return a + b + c; } // 使用 int i = add(1, 2); // 调用① double d = add(1.2, 3.4); // 调用② int j = add(1, 2, 3); // 调用③
二、运算符重载(Operator Overloading)
- 定义
通过给类提供特别的成员函数或全局函数,让内置运算符(如 +, -, [], ())作用于自定义类型时也能表现出自然语义。 - 语法
// 作为成员函数 ReturnType operatorOpSymbol(参数列表) { /*…*/ } // 或者作为全局(非成员)函数 ReturnType operatorOpSymbol(LeftType lhs, RightType rhs) { /*…*/ } -
示例
struct Point { int x, y; Point(int x, int y): x(x), y(y) {} // 重载 “+” 运算符,绑定到成员函数 Point operator+(const Point& rhs) const { return Point(x + rhs.x, y + rhs.y); } // 重载 “==” 运算符,绑定到全局函数 friend bool operator==(const Point& a, const Point& b) { return a.x == b.x && a.y == b.y; } }; // 使用 Point p1(1,2), p2(3,4); Point sum = p1 + p2; // 调用 operator+ bool eq = (p1 == p2); // 调用 operator==
三、为什么要重载?
- 接口统一
同一个功能(比如 “加法”)对不同类型或不同参数个数,用同一个名字就能搞定,调用处更直观。 - 可读性强
例如 a + b 比 add(a, b) 更像数学表达式,代码自然易懂。 - 可维护性
当新增一种类型或参数变化时,只需要添加一个重载版本,无需修改调用处。
四、注意事项
- 不要过度重载,以免让调用者难以判断到底执行哪个版本;
- 避免二义调用,尤其在存在默认参数和类型隐式转换时;
- 不要仅靠返回类型重载,编译器无法区分;
- 运算符重载要遵循“自然语义”:别让 + 做“删除”操作,否则容易造成使用混淆。
通过函数重载和运算符重载,C++ 实现了编译时多态,让同一个接口在不同上下文下“表现不同”,提高了语言的灵活性和可读性。
2. 重载函数里面的代码可以不一样吗?
可以的,从语法和编译器的角度来看,重载函数的各个版本只要签名(参数列表)不冲突,函数体里做什么事情都是你自己的自由。把其中一个版本的实现改成乘法操作是完全合法的:
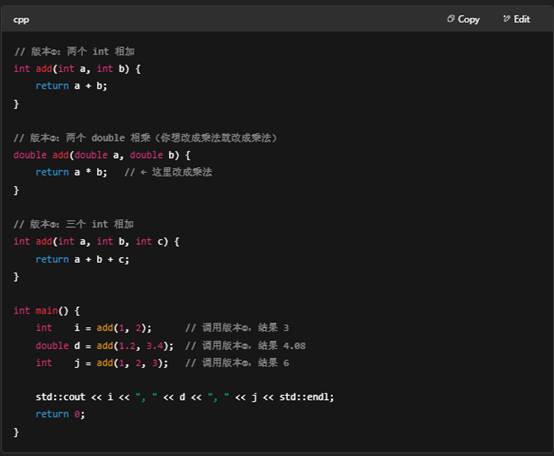
注意事项
- 语义一致性
虽然编译器允许你这样做,但如果把名为 add 的函数改为做乘法,调用者就会感到困惑——建议保持函数名和实现逻辑的一致性,或者给乘法版本取个更恰当的名字(比如 mul)。 - 重载解析
重载解析只关心函数名和参数列表(签名),绝不看函数体。因此修改 return a + b → return a * b 不会影响编译器如何选择调用哪个版本。
问:是不是函数的参数列表不冲突就行,多了也可以,比如一个有int a,另一个是int a, b ,c
对,只要重载函数的“形参列表”互不冲突,编译器就能区分它们,无论是参数个数不同,还是参数类型不同,都可以构成重载。参数的名字并不影响重载,只看:
- 参数个数
- 参数类型(包括引用/指针、顶层 const/volatile)
- 参数顺序
例如,你可以这样写:
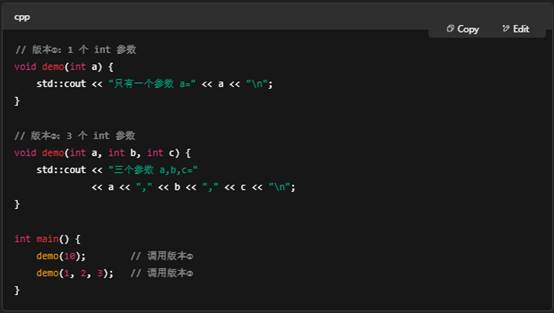
需要注意的地方
- 返回类型不参与重载:你不能仅靠改变返回值类型来重载。
- 默认参数可能引起二义:如果两个重载版本通过默认值能够互相匹配,就会变得模糊不清,编译器会报二义调用错误。
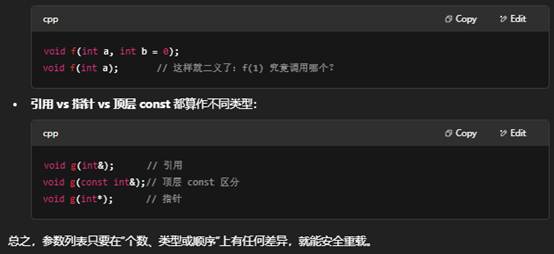
3.示例中函数重载,如果把func(10)改为func(int a)会报错吗?
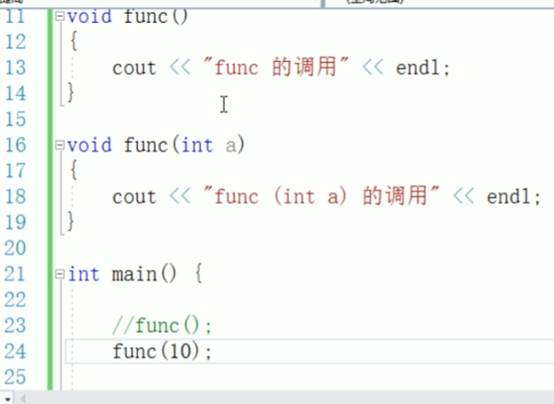
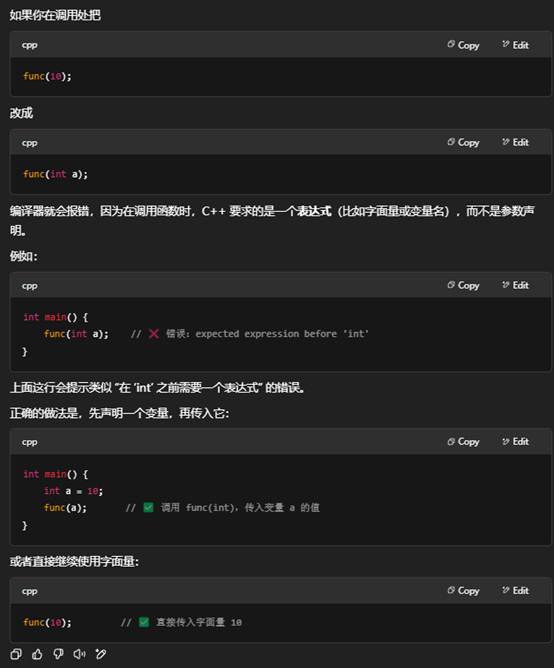
封装
1. 在封装类中使用void setName(std::string name),void setID(int StudentID),和我直接在类中直接使用std::string name和int StudentID有什么区别?
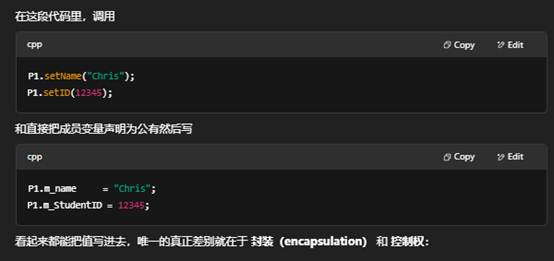
1. 封装/信息隐藏
- 用 setName()、setID()
这些方法是类对外暴露的“接口”。类的内部(包括成员名字、类型、将来如何存储名字、ID)对使用者是隐藏的。如果你以后要- 在设置名字时做长度检查、过滤敏感字符
- 或者把名字改成 wstring、ID 从 int 改成 long long
你只需要改 setName()、setID() 的实现,调用者的代码不用改。
- 直接用公有成员
任何地方都可以直接写入、读出,完全没法在写入前或写入后做校验或额外操作,也没法在以后悄悄地更改成员类型或内部存储而不影响外部代码。
解释:
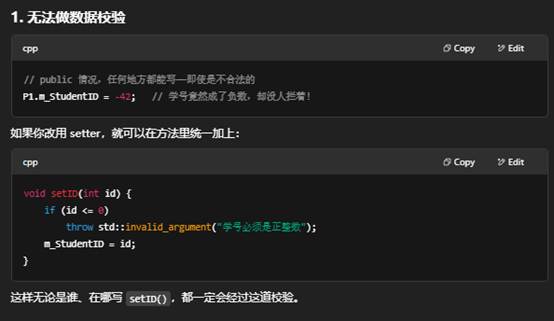
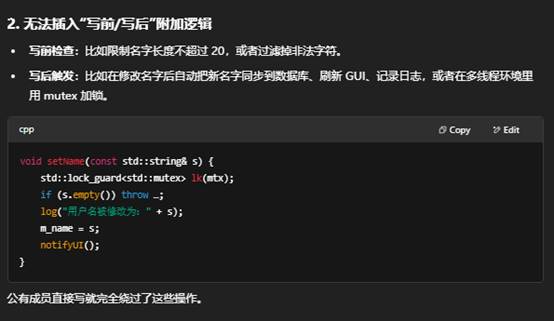

3. 日志、线程安全、二次加工
- 日志:你可以在 setName() 里顺便打个日志,或通知 UI 刷新。
- 锁(mutex):多线程环境下,加一把锁也只要在这两个方法里做。
如果直接给成员设为公有,这些额外动作就无法集中管理。
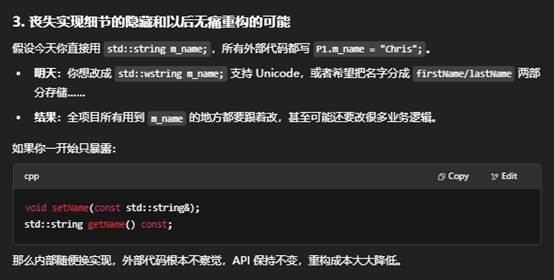
4. 接口稳定性
把成员暴露出去,一旦它的名字或类型变了,所有直接访问它的代码都要改——极不利于后期维护。通过 setXXX()/getXXX(),你至少保留了“方法名”这个不变的接口层。
小结
- Setter/Getter 方法:✔ 良好封装、✔ 可控可验证、✔ 未来易扩展/重构
- 公有成员直接访问:✘ 无校验、✘ 内外耦合、✘ 维护困难
因此,推荐把成员变量设为 private,把真正对外的读写操作都放到 setXXX()/getXXX() 里。这样你的类才是真正符合面向对象设计原则的“黑盒”──使用者只能通过你提供的接口跟它打交道。
2. 访问权限:public,protected,private这三个都是围绕类来展开的吗,但是如果在全局作用域下面写这三个是不是就没有什么区别了?
是的,public、protected、private 这三大访问说明符只在 类(class/struct/union)内部 有意义,用来控制 成员 对外的可见性/可访问性。
为什么全局作用域下写它们没用(甚至会报错)
- 在 命名空间(包括全局命名空间) 或者函数外的顶层作用域,根本不存在「成员」的概念,只有自由(free)函数和全局变量。
- C++ 标准并没有规定在类定义之外允许写访问说明符,绝大多数编译器都会直接报:
vbnet
error: access specifier ‘public’ not allowed here
- 即使极端情况下某些编译器仅把它当成“标签”(类似 goto 标签),也对访问权限 一丁点 影响都没有——它不会拦截谁能访问哪个符号。
全局/命名空间作用域下的可见性控制
- 默认:全局函数和全局变量都是 外部链接(external linkage),任意翻译单元都能看到。
- 想限制“只在本文件可见”,要用
- static 关键字(C 风格)
- 或者更现代的 匿名命名空间:
cpp
namespace {
void helper() { /* ... */ } // helper 只在本 .cpp 文件可见
}
- 公有/私有/保护这些概念,只在 继承、对象封装、成员访问 的场景下才派得上用场。
小结:
- public/protected/private 只能写在类/结构体/联合体的定义体内部,控制类的成员的访问。
- 在全局(命名空间)作用域下写它们,要么编译错,要么被当成无意义的标签,并不会限制任何东西。
- 若要在全局层面隐藏符号,用 static 或匿名命名空间来管理可见性。
C++进阶概念
1.什么是序列化?
Thought for a few seconds
序列化(Serialization)指的是将程序运行时内存中的数据结构或对象,转换成可存储或传输的格式(如二进制流、JSON、XML 等)的过程;与之相对的“反序列化”(Deserialization)则是把这些存储/传输格式还原回原始的数据结构或对象。
1. 为什么要序列化?
- 持久化存储:将对象状态保存到硬盘(文件、数据库),下次运行时读取还原。
- 网络传输:在不同机器或进程间传输对象,需要把内存结构打包成字节流。
- 跨语言/跨平台:不同语言或平台间交换数据,通过标准格式(JSON、Protocol Buffers)保证兼容。

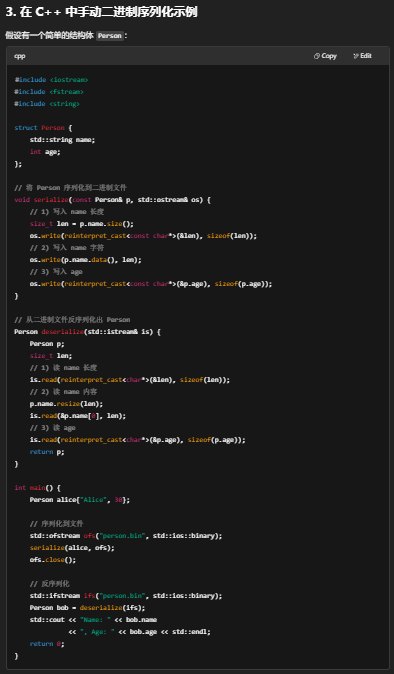

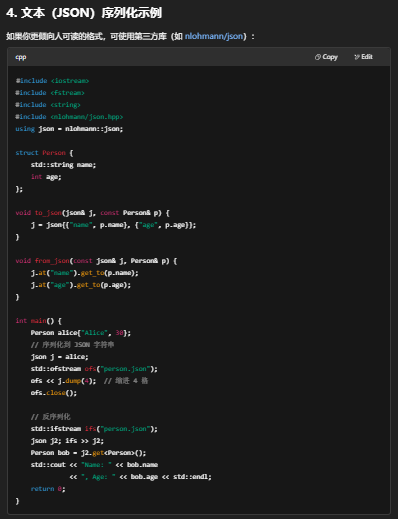
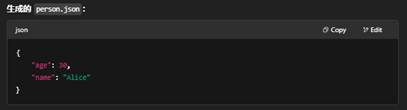
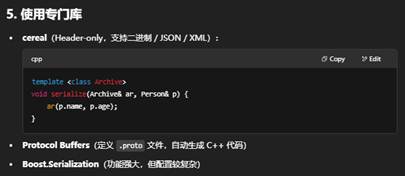
小结
- 序列化 = 对象 → 字节流/文本
- 反序列化 = 字节流/文本 → 对象
- 选择合适的格式和库,既能保证性能,也能兼顾可维护性和跨平台兼容。
2.C++11 到 C++20 各版本的主要差异
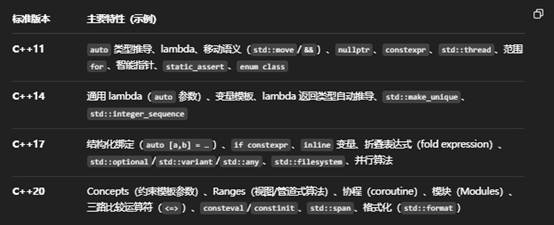
建议:
- 从 C++11 的核心特性(lambda、移动语义、智能指针)入手;
- 依次学习 C++14/17 的增强;
- 最后重点掌握 C++20 的 Concepts、Ranges 和协程,这些是现代高质量库和框架(如 ranges-v3、asio)的基石。
3.C++ STL 容器(Container)概述
- 序列式容器 Sequence Containers
- std::vector:动态数组,连续内存,随机访问高效。
- std::deque:双端队列,支持头尾高效插入/删除。
- std::list:双向链表,中间插入/删除高效,但不支持随机访问。
- std::array<T,N>:定长数组,编译期大小,栈上分配。
- 关联式容器 Associative Containers
- std::set / std::multiset:基于红黑树的有序集合,元素唯一(或可重复)。
- std::map / std::multimap:基于红黑树的有序键值对映射。
- 无序关联容器 Unordered Containers
- std::unordered_set、std::unordered_map:基于哈希表,平均常数时间查找。
- 容器适配器 Container Adapters
- std::stack:默认基于 deque 或 vector,只允许栈操作(LIFO)。
- std::queue:队列(FIFO)。
- std::priority_queue:优先级队列(最大堆或最小堆)。
- 算法与迭代器
- <algorithm> 提供 sort、find、transform、accumulate 等通用算法,可与任何符合迭代器要求的容器配合使用。
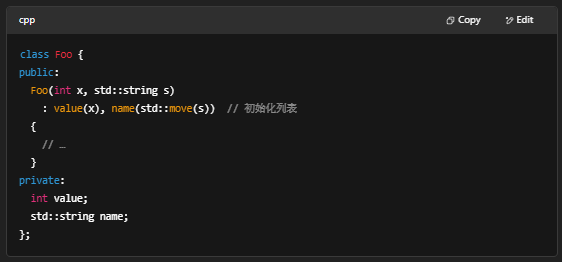
4.构造函数(Constructor)与析构函数(Destructor)
构造函数(Constructor)
- 作用:在对象创建时初始化成员、分配资源。
- 类型:
- 默认构造 MyClass() { … }
- 参数化构造 MyClass(int x, std::string s) { … }
- 拷贝构造 MyClass(const MyClass& other)
- 移动构造 MyClass(MyClass&& other)(C++11)
- 委托构造(一个构造函数调用另一个)
- 初始化列表:在冒号后初始化成员,比在函数体中赋值更高效。
析构函数(Destructor)
- 作用:在对象生命周期结束时释放资源(delete、文件句柄、网络连接等)。
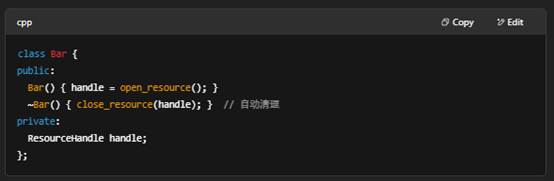
- 语法:~MyClass() { … },无参数,无返回值,不可重载或带参数。
- 自动调用时机:
- 对象离开作用域时(栈对象)。
- delete 一个 new 出来的对象时。
- 智能指针析构时(unique_ptr/shared_ptr 引用计数为 0)。
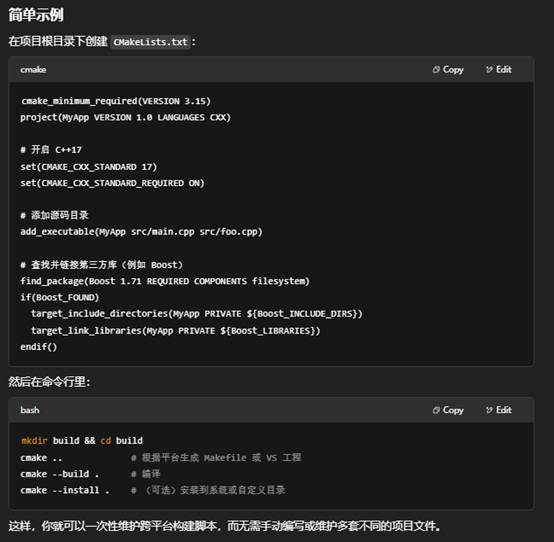
5.构建工具:CMake的作用是什么
CMake 是一个跨平台的开源构建系统生成器,其核心作用包括:
- 生成平台/编译器无关的构建脚本
- 在不同操作系统(Windows、Linux、macOS)和不同编译器(MSVC、GCC、Clang)之间,只需编写一套 CMakeLists.txt,CMake 就能生成对应平台下的原生工程文件(如 Visual Studio solution、Makefile、Xcode 工程等)。
- 统一管理项目结构与依赖
- 通过 find_package()、find_library()、find_path() 等指令搜索并配置第三方库和头文件路径。
- 使用 target_link_libraries()、target_include_directories() 等命令将依赖显式关联到目标(可执行文件或库)。
- 简化多模块/多平台编译流程
- 支持按目录递归添加子项目(add_subdirectory()),轻松组织大型工程。
- 提供配置选项(option())和变量缓存,方便打开/关闭不同功能(如启用测试、启用优化、切换后端库)。
- 自动化生成安装与打包规则
- 内置 install() 命令可自动生成安装脚本,把编译产物、头文件和资源拷贝到指定目录结构。
- 配合 CPack,可进一步自动创建 .zip、.tar.gz、.deb、.rpm、.msi 等打包文件。
- 支持编译器特性检测与条件编译
- 通过 check_cxx_compiler_flag()、check_symbol_exists() 等检测目标编译器/平台支持哪些语言特性和库函数,动态设置编译选项或启用兼容性补丁。
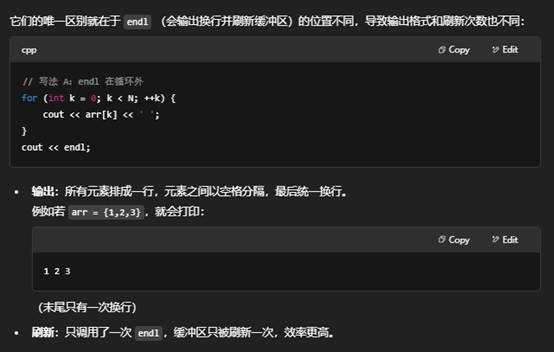
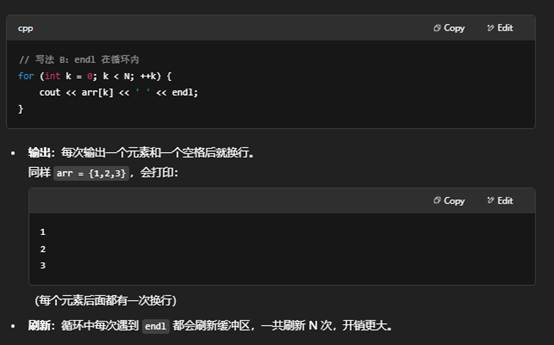
6.for (int k = 0; k < N; ++k) { cout << arr[k] << ' '; } cout << endl;和 for (int k = 0; k < N; ++k) { cout << arr[k] << ' '<<endl; } 有什么区别?
总结:
- 如果想把数组元素都打印在一行,用写法 A,把 endl 放在循环外。
- 如果要每打印一个元素就换行,用写法 B,把 endl 放在循环内。
- 尽量少用 endl,必要时用 '\n' 替代('\n' 只是换行,不刷新缓冲区),以提高性能。
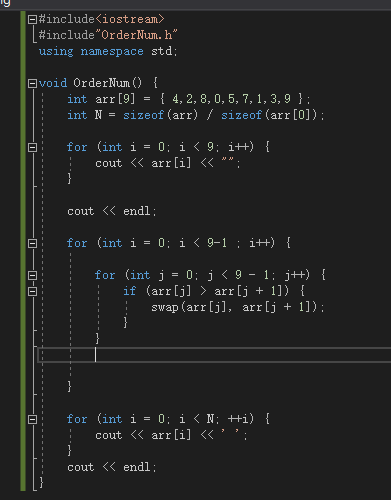
7.冒泡排序中,两层for中的原理(即外层for和里层for)
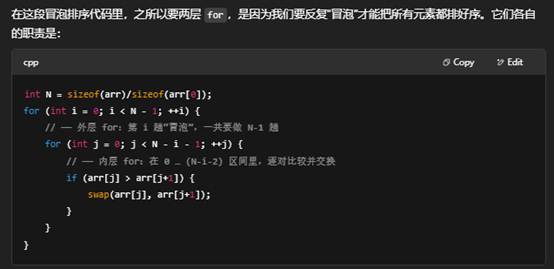
1. 外层 for (int i = 0; i < N-1; ++i)
- 控制“趟数”:每一趟都要把当前「未排序部分」里最大的元素“冒”到它该去的尾部位置。
- 共需要做 N-1 趟才能保证整个数组有序——最后一趟剩下两个元素比完就一定对了。
经过第 i 趟冒泡之后,数组的末尾 i+1 个元素已经是最终排好序的最大元素了,所以下一趟就不必再碰它们。
2. 内层 for (int j = 0; j < N-i-1; ++j)
- 遍历未排序区域:下标从 0 比到 N-i-2,每次比较 arr[j] 和 arr[j+1]。
- 交换逻辑:如果前面的元素更大,就和后面的交换——这样「大」的元素就往右跑了一格。
- 这一趟跑完以后,最大的那个元素就会“冒泡”到 N-i-1 这个位置。
举个小例子
假设 arr = {5, 2, 7, 3},N=4:
- 第 0 趟(i=0),j 从 0 到 2:
- 比较 (5,2) → 交换 → {2,5,7,3}
- 比较 (5,7) → 不交换 → {2,5,7,3}
- 比较 (7,3) → 交换 → {2,5,3,7}
⇒ 最大的 7 跑到末尾(索引 3)。
- 第 1 趟(i=1),j 从 0 到 1(N-i-1=2):
- 比较 (2,5) → 不交换 → {2,5,3,7}
- 比较 (5,3) → 交换 → {2,3,5,7}
⇒ 第二大的 5 跑到索引 2。
- 第 2 趟(i=2),j 只到 0(N-i-1=1):
- 比较 (2,3) → 不交换 → {2,3,5,7}
⇒ 剩下的也都在正确位置。
- 比较 (2,3) → 不交换 → {2,3,5,7}
这样三趟过后(N-1 = 3),整个数组就变成 {2,3,5,7},排序完成。
小结
- 外层 控制「要做几趟冒泡」,每做完一趟,未排序区域就少一个元素。
- 内层 在每趟里「不断比较—交换」,把当前未排序区里的最大值一步步推到右边。
这种「一趟确定一个最大值、总共做 N-1 趟」的思路,就是冒泡排序的精髓。
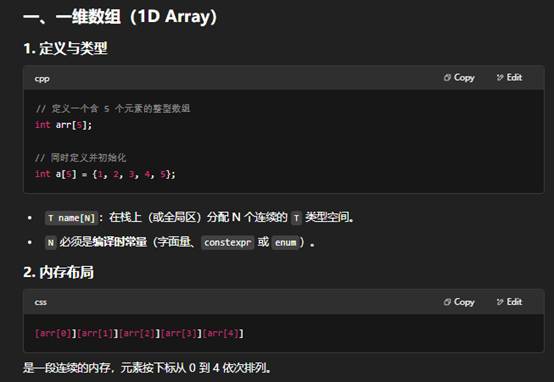
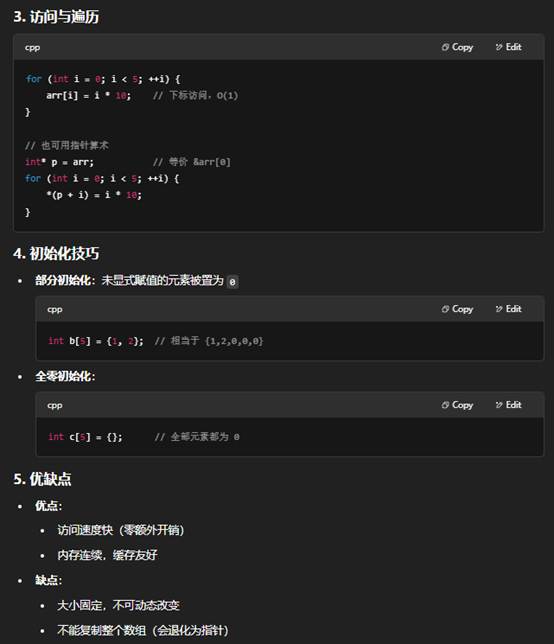
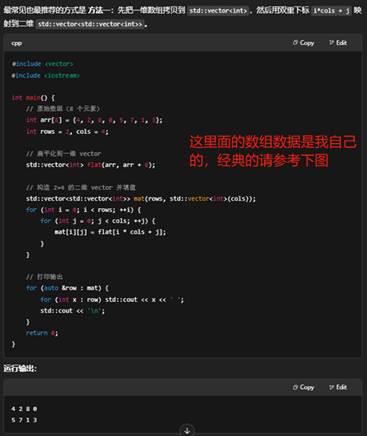
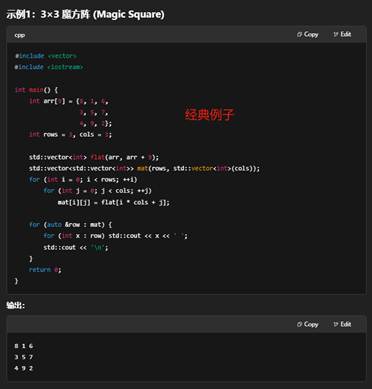
8.C++中一维数组和二维数组的介绍
下面从定义语法、内存布局、初始化与访问以及动态/STL 方式四个方面,分别介绍一维数组和二维数组。
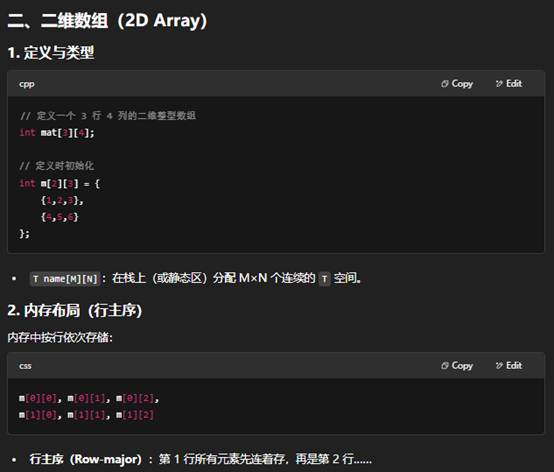
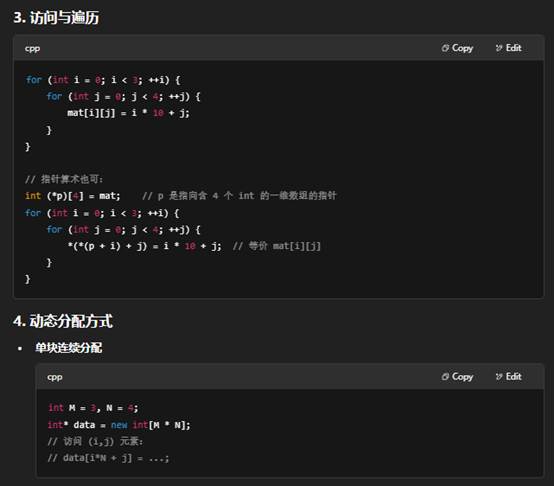
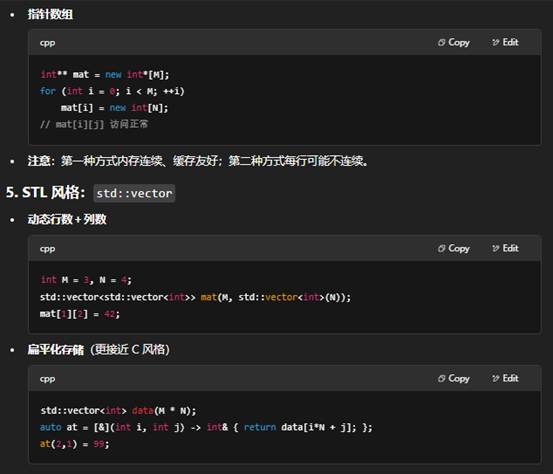 原生静态
原生静态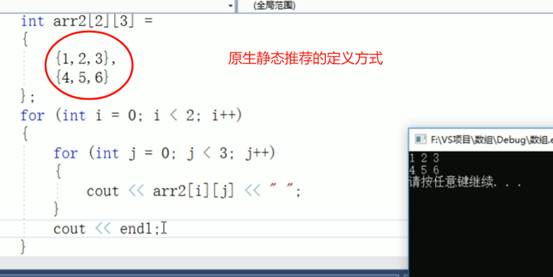
STL
 小结
小结
- 一维数组:T a[N],连续内存,随下标或指针算术访问。
- 二维数组:T a[M][N],也是连续内存(行主序),可用 a[i][j] 或指针算术 *(*(a+i)+j)。
- 动态需求:推荐用 std::vector 或手动 new + 扁平化方案,更灵活也可控制内存布局。
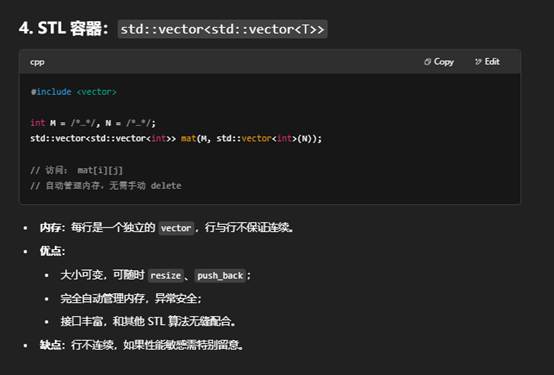
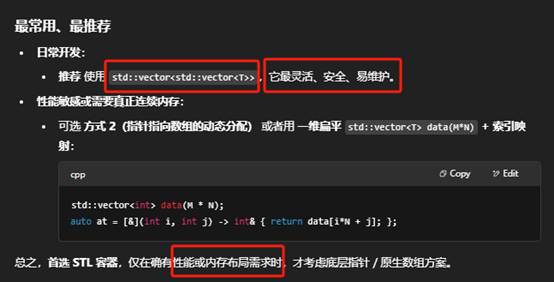
9.使用STL容器表达二维数组(推荐)
你可以先把一维数组包装成一个 std::vector<int>,然后按行切分成若干个 std::vector<int>,最后收集到一个二维 std::vector<std::vector<int>>。下面给出两种常见写法:
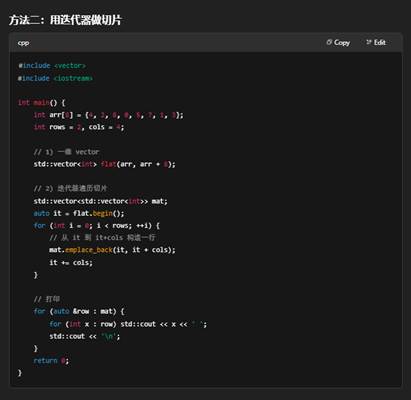
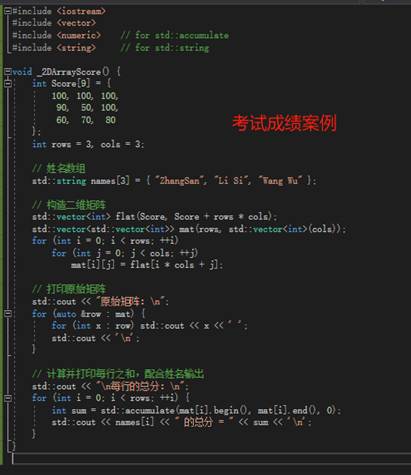
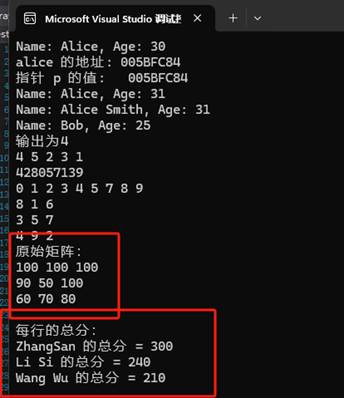


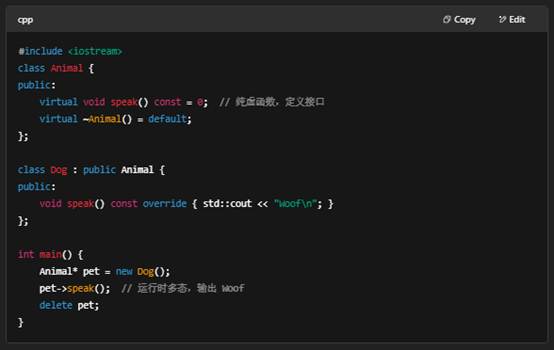
10.什么是C++的多态?
C++ 的多态(Polymorphism)指同一个接口在不同上下文下、表现出不同行为的能力。通俗地说,就是“同样的操作作用于不同的对象,可以产生不同的效果”。
一、多态的两大分类
| 类型 | 特点 | 实现机制 |
| 编译时多态 | 在编译阶段就能确定调用哪个函数;也称为 静态多态(Static Polymorphism) | - 函数重载 |
| 运行时多态 | 在运行时根据对象的实际类型选择调用;也称为 动态多态(Dynamic Polymorphism) | - 虚函数(virtual)与虚表(vtable) |
1. 函数重载(Function Overloading)
#include <iostream>
int add(int a, int b) {
return a + b;
}
double add(double a, double b) {
return a + b;
}
int main() {
std::cout << add(1, 2) << "\n"; // 调用 add(int,int)
std::cout << add(1.5, 2.3) << "\n"; // 调用 add(double,double)
return 0;
}
2. 运算符重载(Operator Overloading)
#include <iostream>
struct Point {
int x, y;
Point(int x,int y):x(x),y(y){}
// 重载 “+” 运算符,使 Point 相加语义更自然
Point operator+(const Point& rhs) const {
return Point(x + rhs.x, y + rhs.y);
}
};
int main() {
Point p1(1,2), p2(3,4);
Point sum = p1 + p2; // 等价于 p1.operator+(p2)
std::cout << sum.x << "," << sum.y << "\n"; // 输出 4,6
return 0;
}
3. 模板(Template)
#include <iostream>
// 泛型函数模板:支持任意加法操作
template<typename T>
T add(T a, T b) {
return a + b;
}
int main() {
std::cout << add<int>(1, 2) << "\n"; // 3
std::cout << add<double>(1.1, 2.2) << "\n"; // 3.3
return 0;
}
三、运行时多态示例
1. 基类和派生类 + 虚函数
#include <iostream>
// 抽象基类(也可不纯抽象)
class Shape {
public:
virtual ~Shape() {} // 虚析构保证派生类资源正确释放
virtual void draw() const { // 虚函数:允许派生类重写
std::cout << "Drawing Shape\n";
}
};
class Circle : public Shape {
public:
void draw() const override { // override 可选,但推荐标明重写意图
std::cout << "Drawing Circle\n";
}
};
class Square : public Shape {
public:
void draw() const override {
std::cout << "Drawing Square\n";
}
};
int main() {
Shape* s1 = new Circle;
Shape* s2 = new Square;
s1->draw(); // 运行时根据实际类型调用 Circle::draw
s2->draw(); // 运行时根据实际类型调用 Square::draw
delete s1;
delete s2;
return 0;
}
原理:每个含虚函数的类都有一张“虚表”(vtable),对象创建时携带一张指向该表的指针(vptr);运行时通过 vptr 找到对应函数地址并调用。
四、为什么要用多态
- 可扩展性:新增派生类无需修改调用者代码,只要遵循同一接口;
- 代码复用:把共性逻辑放在基类,个性逻辑由派生类实现;
- 解耦合:调用者只与接口(基类)交互,不依赖具体实现。
五、注意事项
- 虚函数开销:运行时多态会有一次指针间接调用开销,且内存上多了 vptr;
- 析构要虚:若通过基类指针删除派生对象,基类析构函数就必须声明为 virtual,否则会导致资源泄漏;
- 不要滥用:编译时多态开销小、类型安全;运行时多态灵活但稍慢,视场景选择。
总结
- 编译时多态(重载、模板)在编译阶段决定调用,效率高;
- 运行时多态(虚函数)在运行阶段决定调用,更灵活可扩展。
两者结合使用,可以让 C++ 程序既高效又具有良好的可维护性和扩展性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









