







1.Encoder
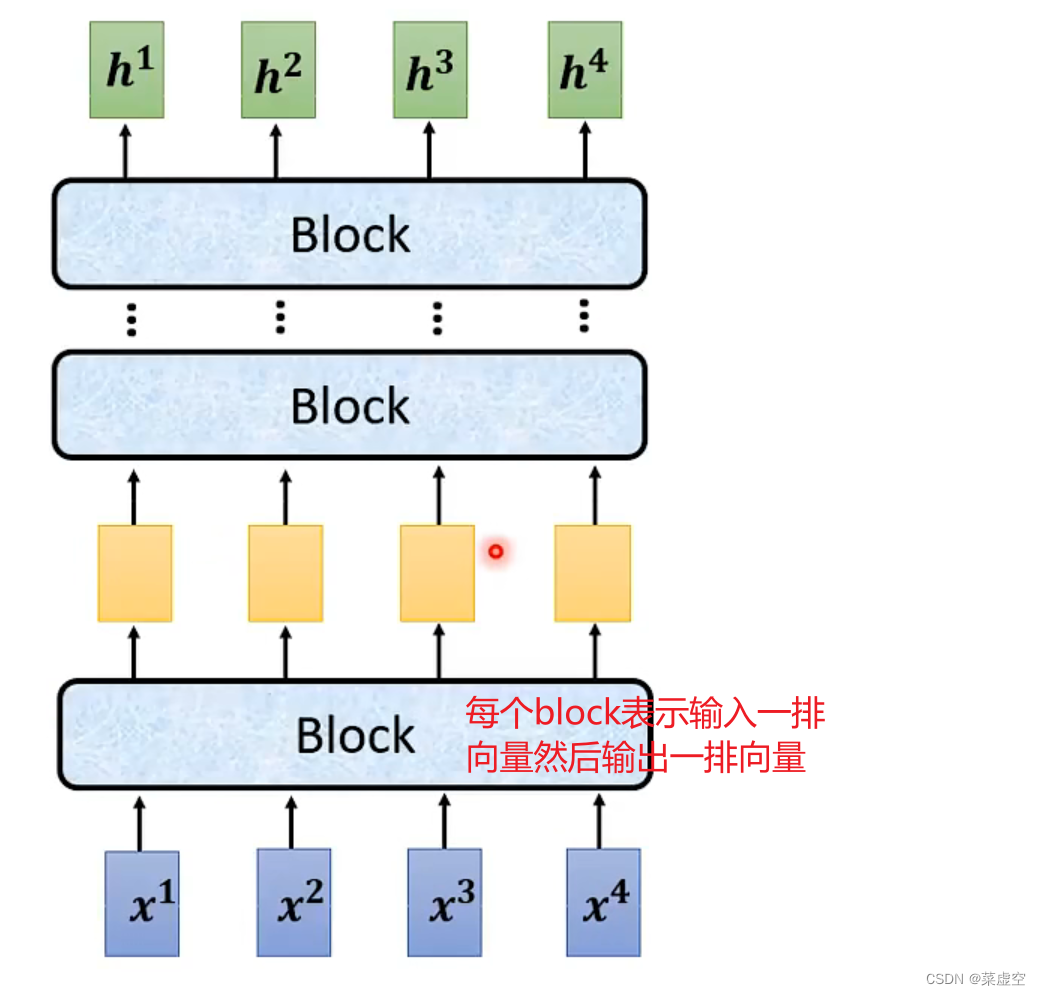
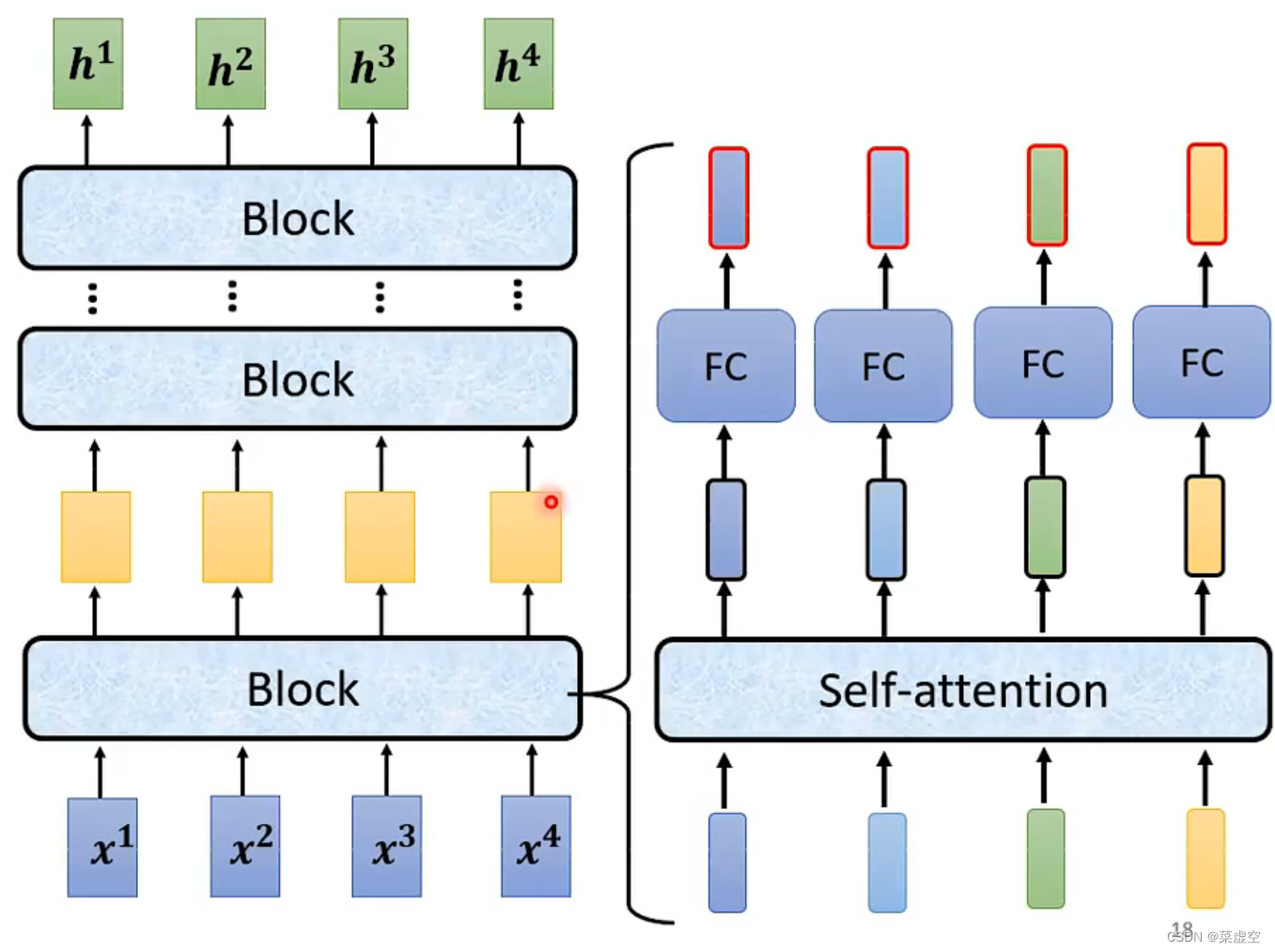
简言之:输入一排向量然后输出一排向量
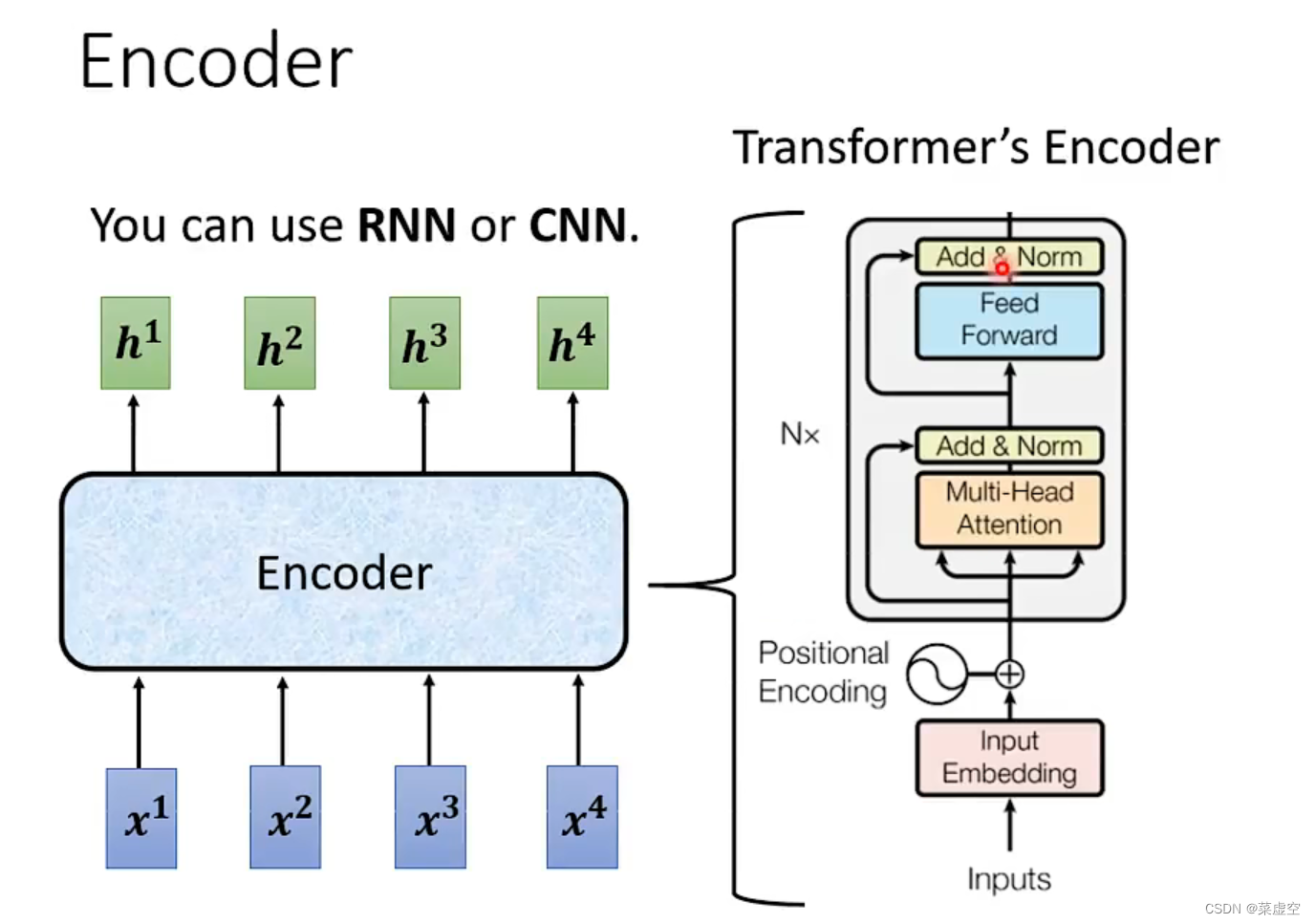
原始的transformer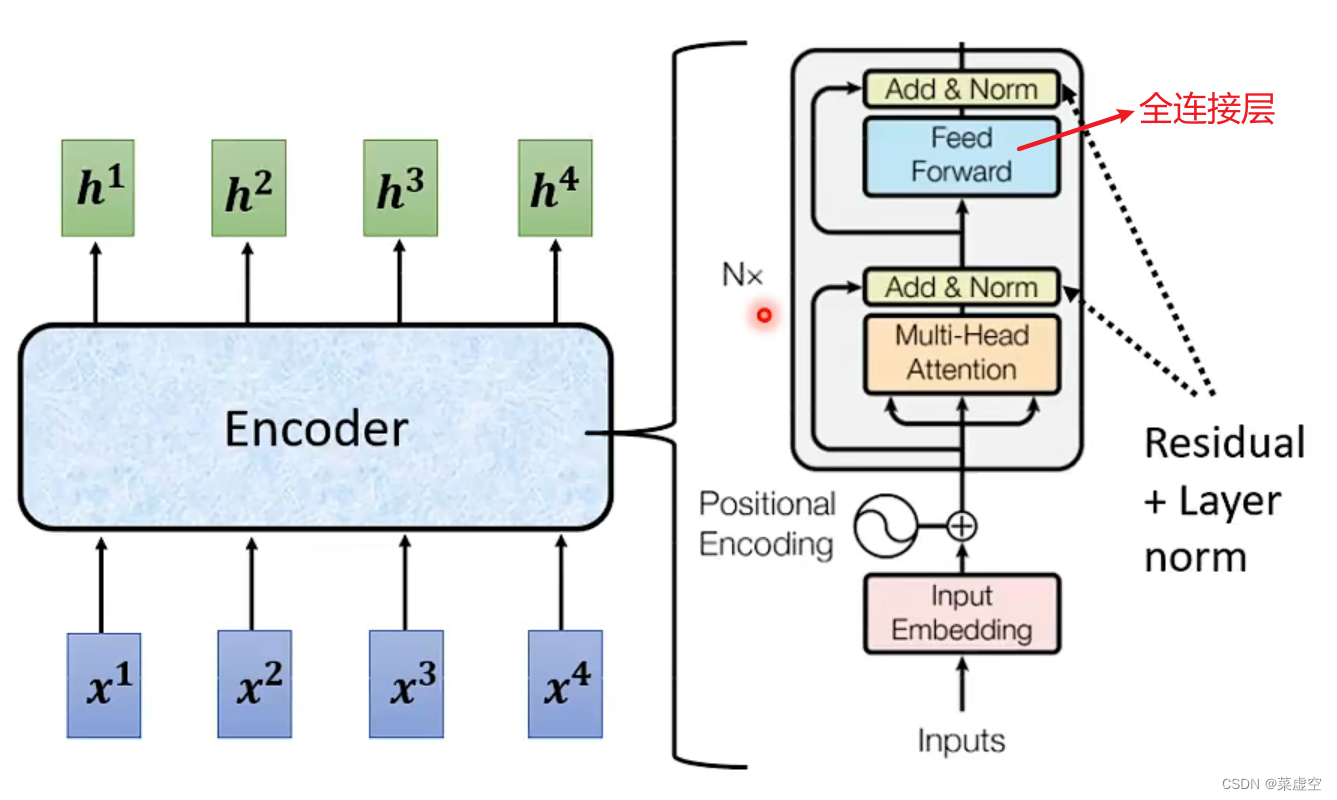
2.Decoder
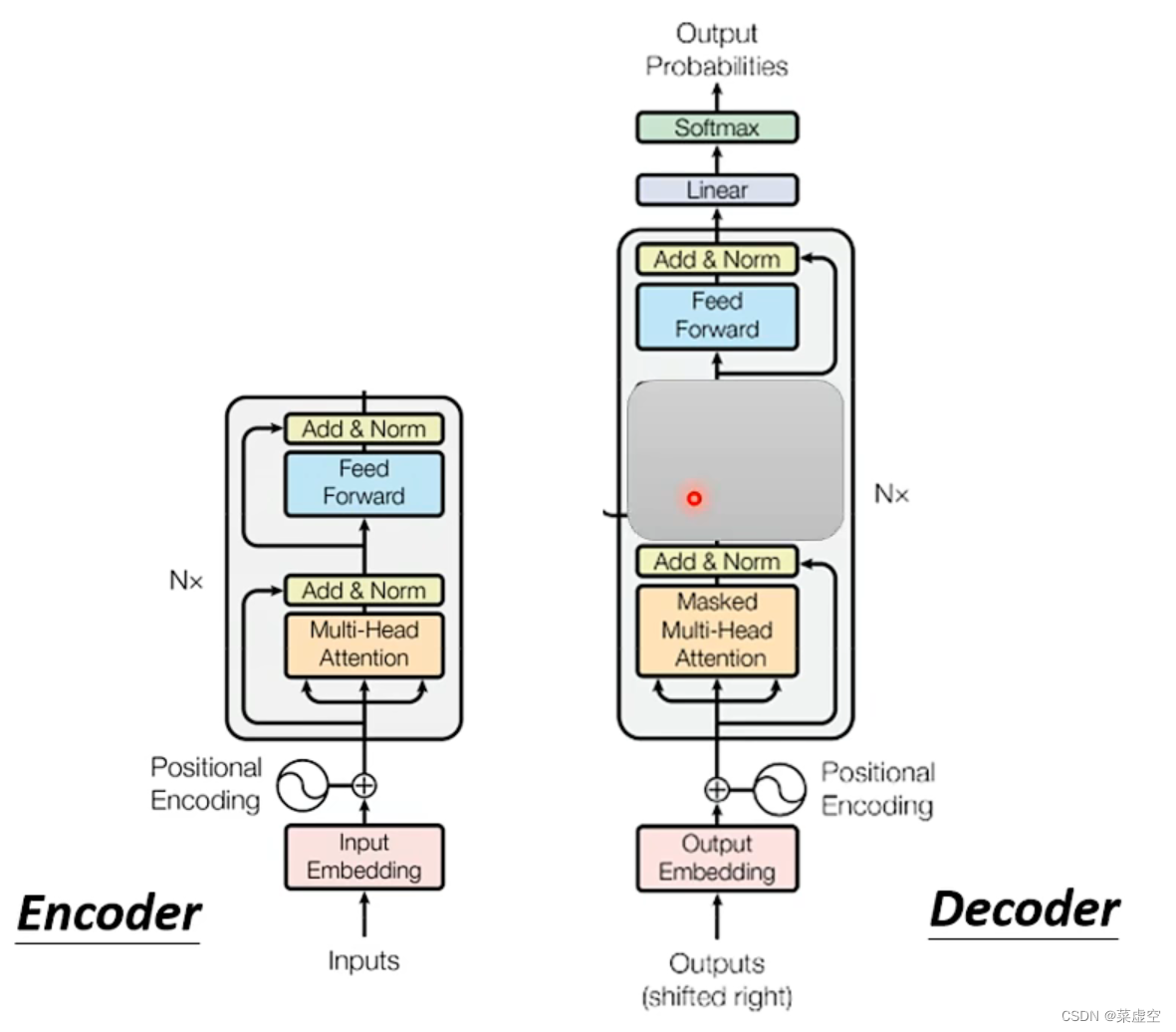
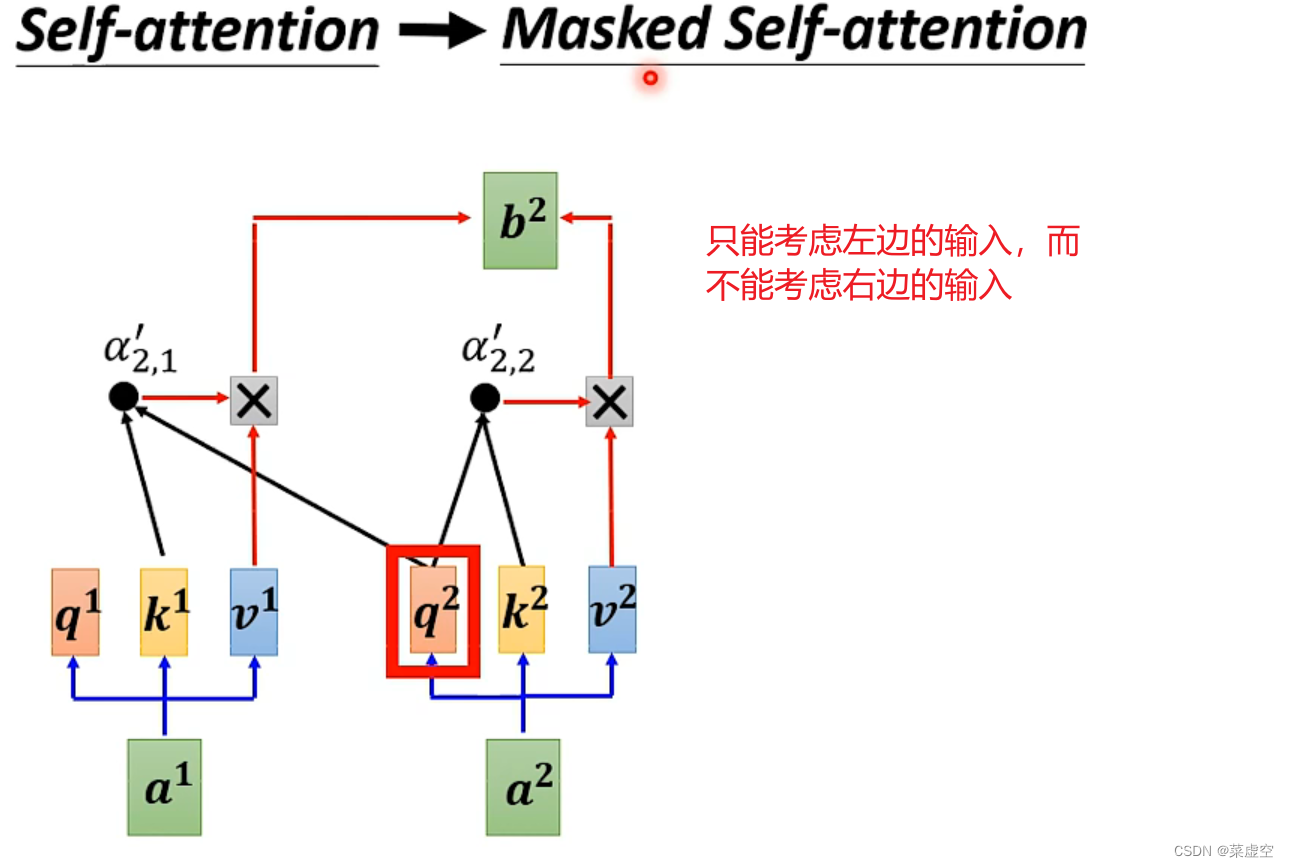
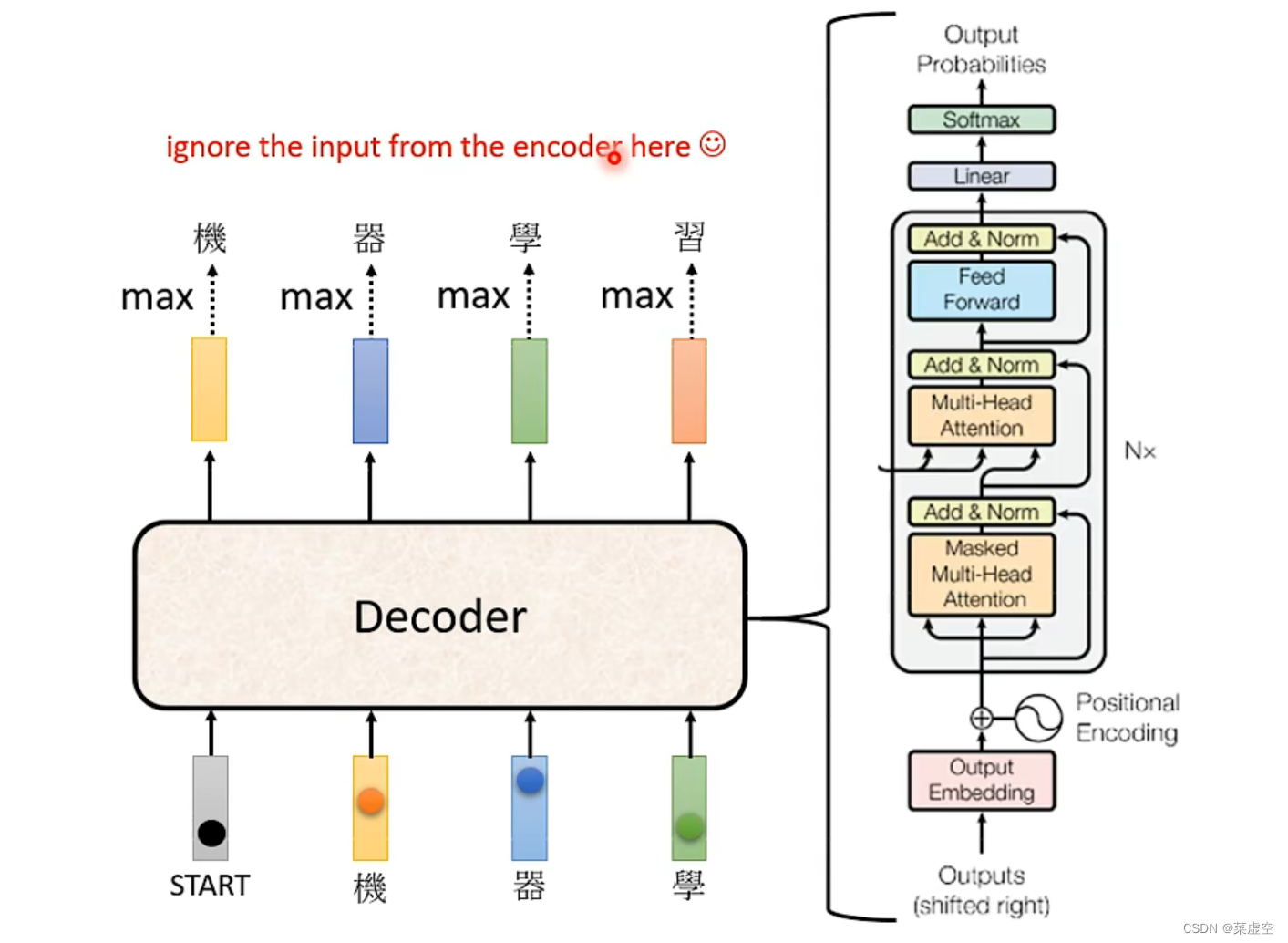
2.1引入mask_self-attention
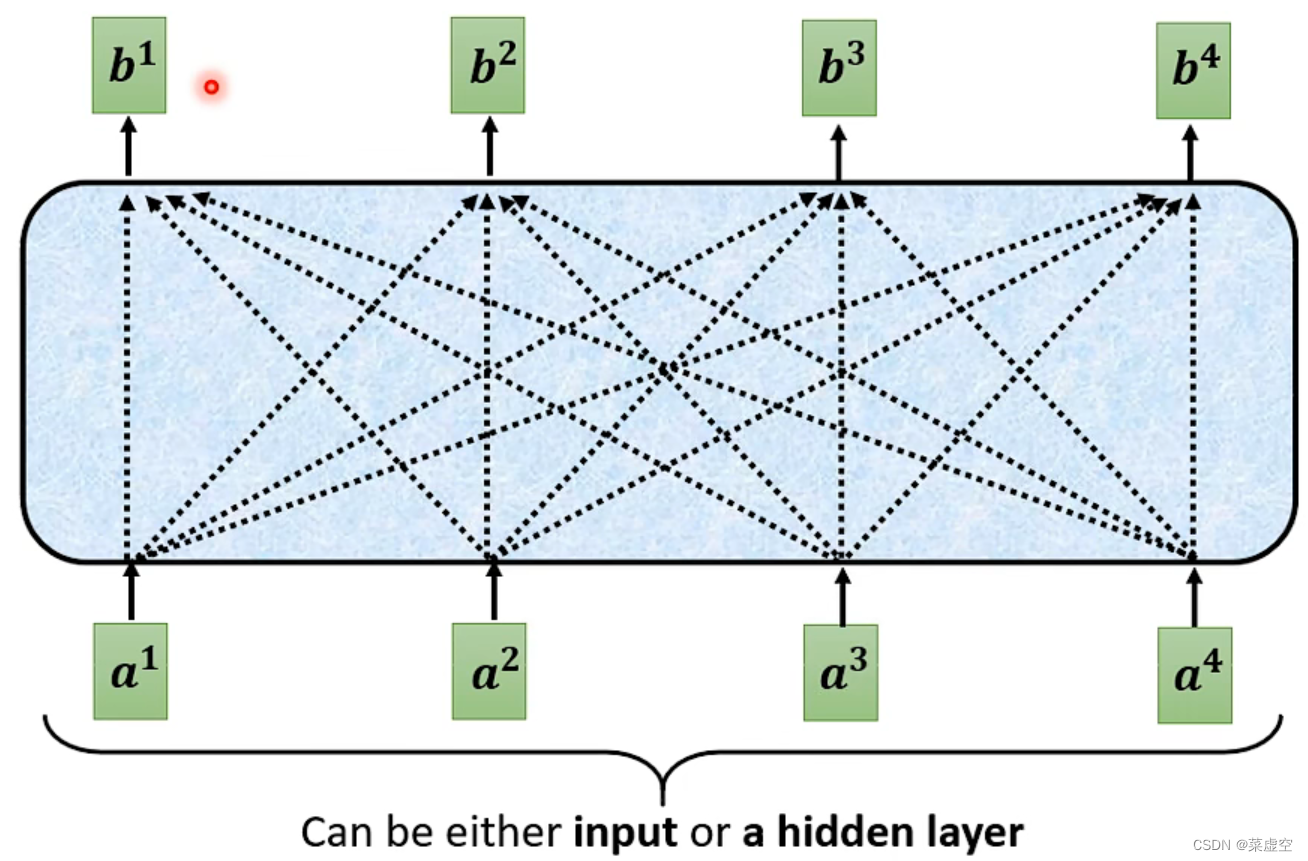
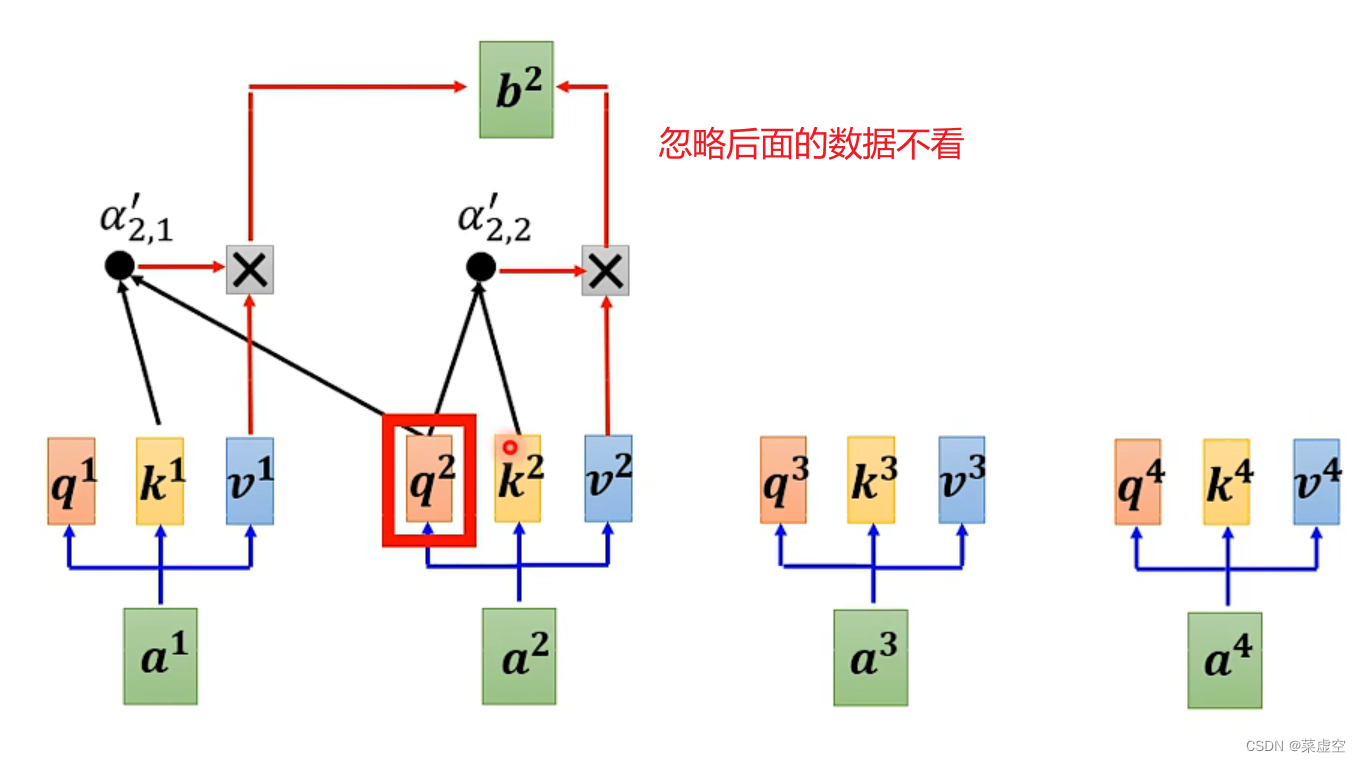
正常的self-attention
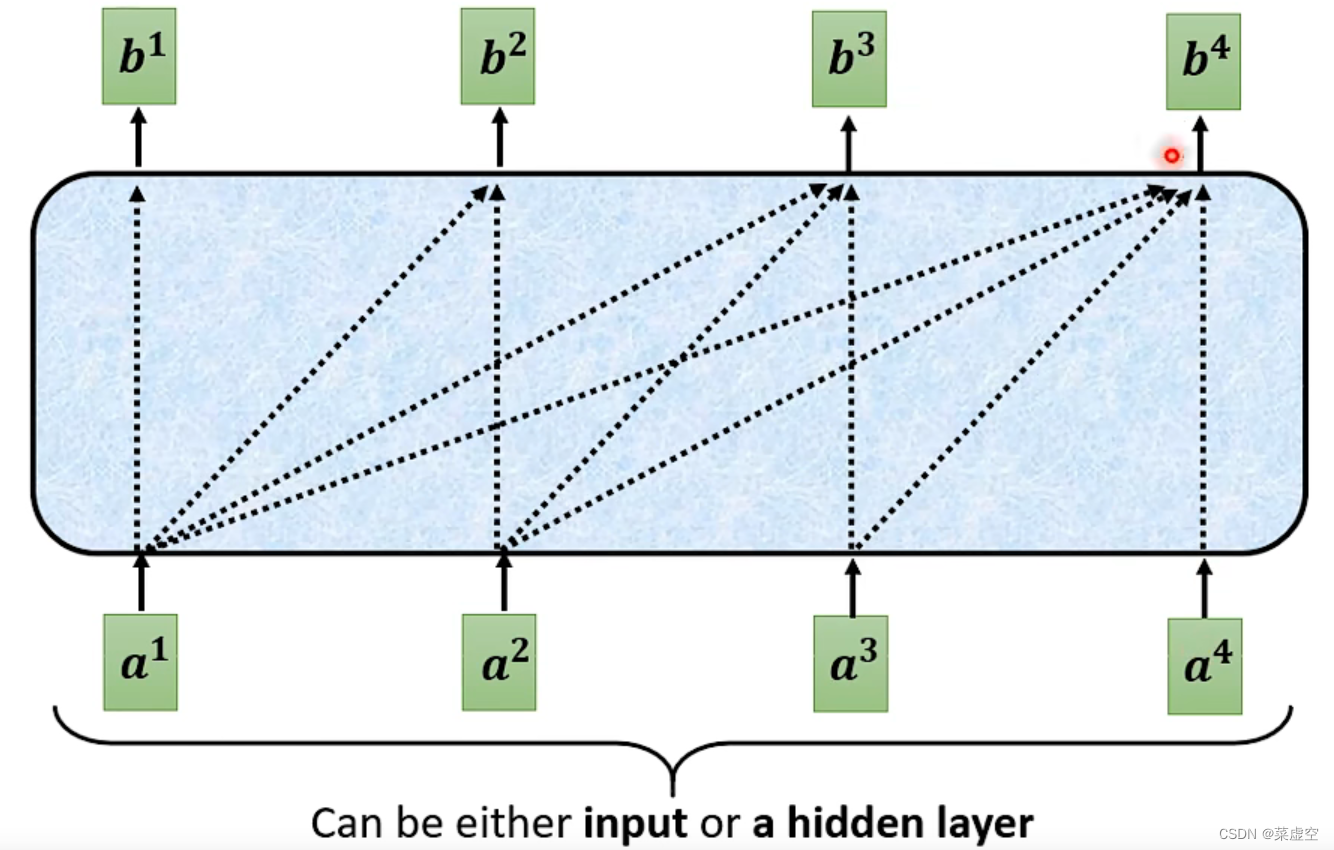
mask-self-attention
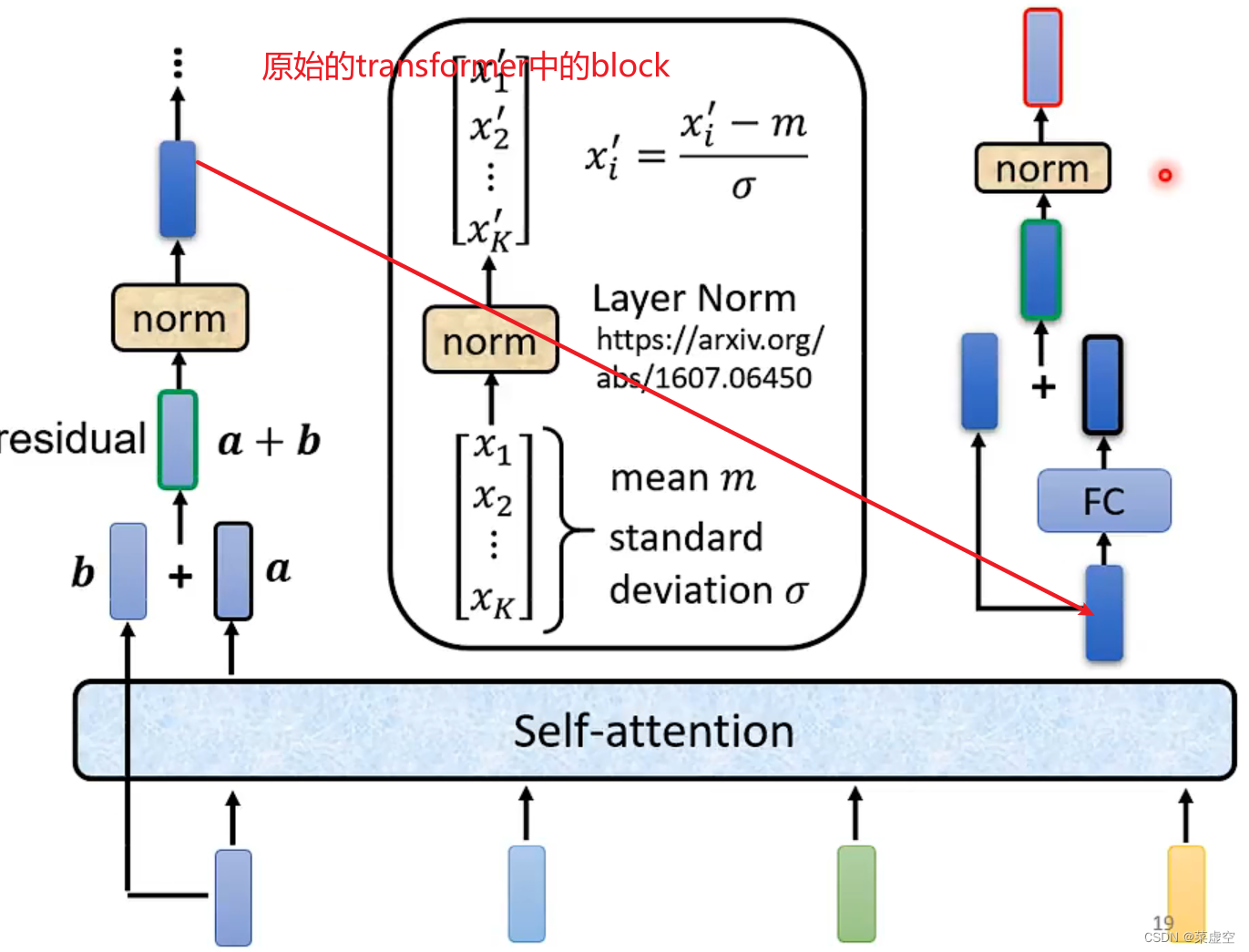
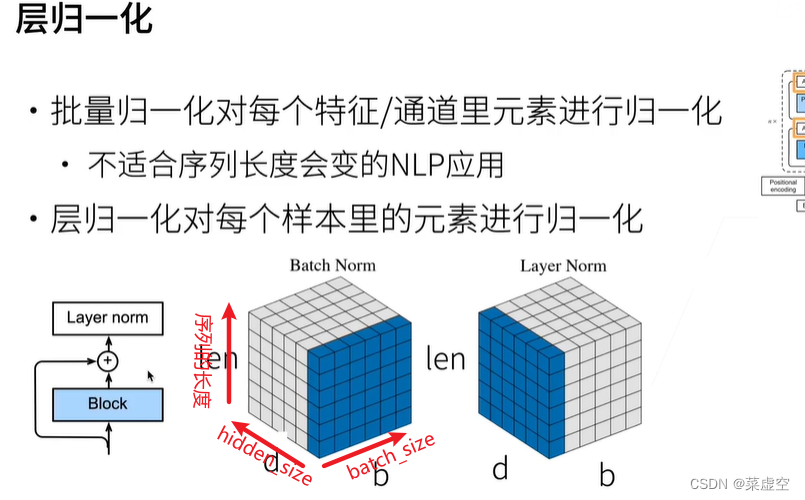
layer norm是将每个样本变为均值为0方差为1的数


简言之:输入一排向量然后输出一排向量
原始的transformer
正常的self-attention
mask-self-attention
layer norm是将每个样本变为均值为0方差为1的数
 25万+
25万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























