







常见的锁策略
在谈到"锁策略"之前.我们先要先理解线程和锁的关系,例如
你去银行办理业务,进入银行后先去取号,然后在服务区等待,过了段时间,广播加到你的号码,你走到服务窗口,由银行员工为你办理业务,并且在完成业务的过程中,员工只为你一个人服务,当你完成业务后离开,广播呼叫下一个号码.
在上述过程中,每个办理业务的人就是线程,服务窗口就是锁,服务窗口后的银行员工就是共享资源,你无法直接办理业务,需要先取号后等待的过程为阻塞,当广播叫到你的名字时,你去办理业务的提示信息为唤醒,你在窗口办理业务就是加锁,完成业务后离开为释放锁
悲观锁和乐观锁
悲观锁:
悲观锁自己去拿数据时,认为别人也去拿数据会修改数据,所以在每次拿数据时都会上锁,这样其他线程去拿数据时,会被阻挡到外面,防止数据错误.
乐观锁:
乐观锁认为在一般情况下是会发生访问冲突,所以不会上锁,只有在数据进行更新时,才会对比数据在当前线程的更新期间有没有被修改过,如果修改过,则可以尝试重新读取,选择报错,放弃修改等策略.
总结:
乐观锁和悲观锁共有各有优缺点,在面对不同的应用场景,采取合适的策略,能够大大的提高系统的效率,比如:当系统冲突次数多,适用于悲观锁,虽然由于频繁上锁,系统资源消耗大,但是能够减少冲突,提高系统的稳定性.当冲突次数少,使用乐观锁就可以减少上锁时消耗的资源,所以悲观锁阻塞事务,乐观锁回滚重试.
Synchronized 初始使用乐观锁策略. 当发现锁竞争比较频繁的时候, 就会自动切换成悲观锁策略 ,而乐观锁的在进程数据是否冲突时所采用的一个策略就是使用"版本号".
读写锁
对于Synchronized属于普通的互斥锁,对于不同线程自己对同一个代码块的上锁是互斥的,而读写锁是对其进行细分,分为"读锁"和"写锁".在多线程之间,对于读操作是安全的,但是边读边写,多个线程写这是线程不安全的,使用读写锁就可以提高多个线程读的效率,还可以保证写操作的安全.
读写锁规则:
- 线程A占用读锁,线程B申请读锁,申请成功
- 线程A占用读锁,线程B申请写锁,线程B会开始等待,直到线程A释放写锁才能申请成功
- 线程A占用写锁,线程B申请写锁或者写锁,线程B开始等待,因为读写操作不能同时进行
标准库的ReentrantReadWriteLock类:
Java标准库中使用ReentrantReadWriteLock 类中的readLock对象获取读锁,writeLock对象获取写锁,两个对象都提供lock/unlock来实现加锁/解锁操作.
//定义读写锁
private static final ReentrantReadWriteLock reentrantReadWriteLock = new ReentrantReadWriteLock();
//读锁对象
private static final ReentrantReadWriteLock.ReadLock readLock = reentrantReadWriteLock.readLock();
//写锁对象
private static final ReentrantReadWriteLock.WriteLock writeLock = reentrantReadWriteLock.writeLock();
//读操作
public static void read() {
readLock.lock();
try {
System.out.println(Thread.currentThread().getName() + "得到读锁,正在读取...");
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
readLock.unlock();
System.out.println(Thread.currentThread().getName()+"读取完毕,释放读锁");
}
}
//写操作
public static void write() {
writeLock.lock();
try {
System.out.println(Thread.currentThread().getName() + "得到写锁,正在写入...");
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
writeLock.unlock();
System.out.println(Thread.currentThread().getName() + "释放写锁");
}
}
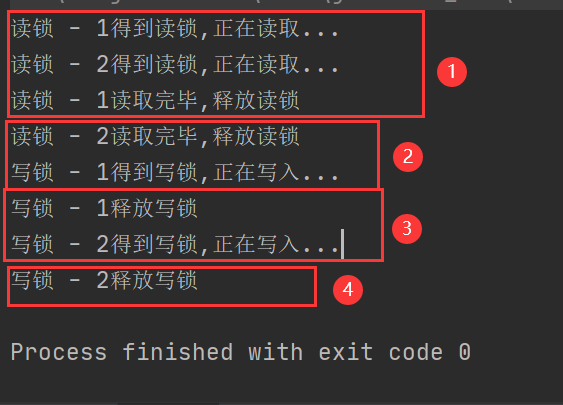
public static void main(String[] args) {
new Thread(() -> read(), "读锁 - 1").start();
new Thread(() -> read(), "读锁 - 2").start();
new Thread(() -> write(), "写锁 - 1").start();
new Thread(() -> write(), "写锁 - 2").start();
}
由显示结果及其执行次序知:读写锁支持并发读,而写操作是单独进行的.
轻量级锁和重量级锁
二者涉及到用户态和内核态的转变,所以先了解锁的核心"原子性",及CPU是如何提供操作指令.
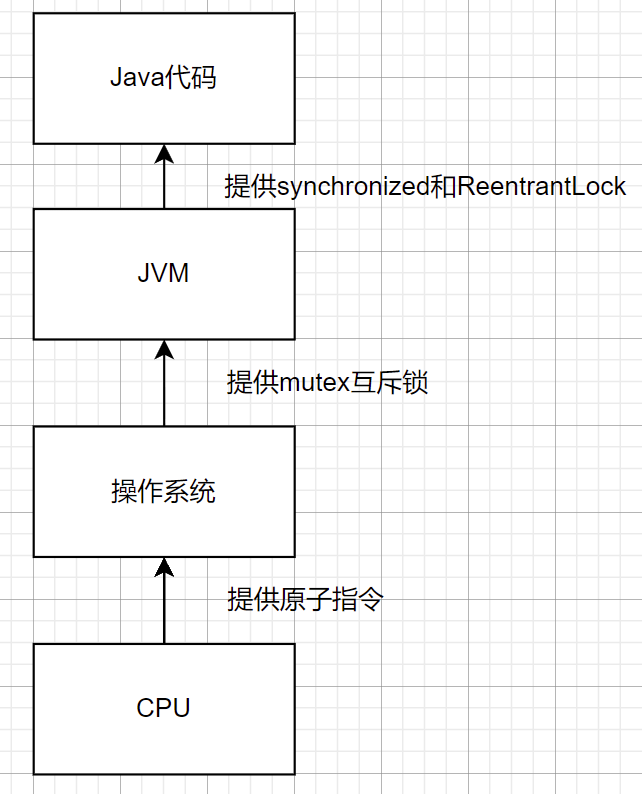
重量级锁:依赖于操作系统提供的锁
- 大量的用户态内核态的转化,导致所需时间和成本的提高
- 很容易引发线程的调度
轻量级锁: 避免使用操作系统提供的锁,尽量在用户态完成任务
- 少量的转化为内核态
- 不太容易引发线程调度
简而言之就是:轻量级锁任务少,锁开销小,重量级锁任务多,锁开销大.
synchronized是自适应锁,根据锁冲突情况切换,冲突不高:轻量级锁,冲突很高:重量级锁
自旋锁和挂起等待锁
自旋锁: 当发现锁冲突时,对于抢锁失败的线程,立即尝试重新获取锁,并且循环多次(状态不会改变).所以当其他线程释放锁时,就会第一时间获取到锁
挂起等待锁(阻塞锁): 当发现锁冲突时,会挂起等待(进入阻塞队列),所以当锁被释放时,不会第一时间获得锁.
比如去银行取钱,你有两种选择,一个是去柜台取钱,这就是阻塞锁,另一个是去取款机取钱,这就是自旋锁.在柜台取钱时你会先取号,然后开始等待被叫号,这个等待过程就是进入阻塞队列,被叫号就是被唤醒,而在取款机取钱是,没有广播提醒下一个是谁,即没有唤醒操作,你必须一直关注是否到自己取钱了.
二者都是等待获取共享资源,最大的区别是要不要放弃CPU的执行时间.
自旋锁是轻量级锁的实现:
- 优点:是一种乐观锁,没有放弃CPU,不涉及线程阻塞和调度(因为一直在尝试获取锁),一旦得到的锁被释放,会第一时间获取
- 缺点:如果等待的锁迟迟没有释放,就会一直占用CPU,消耗系统资源
挂起等待锁是重量级锁的实现:
- 优点:是一种悲观锁,在挂起等待的时候不会消耗CPU,等待锁释放后被唤醒.
- 缺点: 由于自身是挂起等待,所以不会第一时间获取到锁
在JVM中,synchronized 锁只能按照偏向锁、轻量级锁、重量级锁的顺序逐渐升级(被称为锁膨胀的过程),不允许降级,在后面会讲解,三者之间的转化过程.
公平锁和非公平锁
假设现在有三个线程A,B,C尝试获得锁,A先尝试获取到锁,获取成功,随后B,C都去尝试获取,如果按照顺序是B,C这个顺序阻塞等待.
在线程A释放锁后,在公平锁和非公平锁的规则下,那个线程能够获得到锁是不同的

公平锁:遵守"先来后到",因为B比C先来,所以B先获取锁.
非公平锁: 不遵守"先来后到",每个锁获取锁的概率是相同的,这TM才是公平🤡
对ReentrantLock 类来说,通过构造函数可以指定该锁是否是公平锁,默认是非公平锁.因为在大多数情况下,非公平锁的吞吐量比公平锁的大,如果没有特殊要求,优先考虑使用非公平锁.
而对于 synchronized 锁而言,它只能是一种非公平锁,没有任何方式使其变成公平锁。这也是 ReentrantLock 相对于 synchronized 锁的一个 优点,更加的灵活。
为什么设置非公平锁:
这是因为在公平锁的规则下,上一个线程释放锁后,需要先唤醒下一个线程,然后该线程获取锁后去执行代码,在非公平锁的规则下,上一个线程释放锁后,不需要唤醒下一个线程,下一个线程直接就可以拿到锁后执行,相比较下,减少了唤醒成本,提高系统的运行效率,
可重入锁和不可重入锁
可重入锁从字面意思上看就是"可以重复进入的锁",可以**允许同一个线程多次获取同一把锁,**最通透的一个例子是在递归函数中存在加锁操作,如果在递归函数中这个锁把自己阻塞了,即不可重入锁,反之,则为可重入锁(所以也叫做递归锁).
在Java中以Reentrant开头命名的锁,Lock的实现类,包括sychronized都是可重入锁.而Linux中的mutex是不可重入锁.
相关面试题
- 如何理解乐观锁和悲观锁,具体是怎么实现的?
乐观锁认为多线程访问同一个共享变量发生冲突的概率低,所以不会真正的加锁,而是直接尝试访问共享数据,在访问数据时检测当前是否发生访问冲突.乐观锁可以通过引入"版本号"来辨别是否访问冲突.
悲观锁认为多线程访问同一个共享变量发生冲突概率高,所以在每一次访问共享数据时会去加锁,悲观锁是在访问数据前就必须要获取锁,如果获取失败,则会等待.
- 介绍下读写锁
首先读写锁是把读操作和写操作分别开来,从而保证线程安全.其中读锁和读锁之间可以并发,而读锁和写锁,写锁和写锁之间是互斥的.
它适用于"读频繁,写不频繁"的场景
- 什么是自旋锁,为什么要使用自旋锁策略,缺点是什么?
一个线程尝试获取锁,如果获取失败,会一直循环尝试获取锁,当锁被释放后,就可以第一时间获取到锁.
由于自旋锁只是将当前线程不停地执行循环体,不进行线程状态的改变,响应速度更快,所以能够在锁被释放的第一时间获取到锁,因此在锁持有时间比较短的场景下十分高效.
缺点是当线程数不断增加时,性能下降明显,因为每个线程都需要执行,占用CPU资源,
- synchronized 是可重入锁么 ?
是可重入锁,实现方式是在锁中记录锁持有的线程身份,以及一个计数器(记录加锁次数),如果发现当前锁的线程是持有锁,计数器自增,
释放锁时,计数器自减,最后为0时,清除锁记录中的线程身份.
CAS
什么是CAS
CAS: 全称为Compare and swap, 即比较并交换,它是由CPU提供的一个特殊指令(原子的)
一个完整的CAS操作为:
假设内存中的原数据为V,旧数据为A,新数据为B
- 比较 - 比较V和A是否相等(检查是否在此之前有没有被其他线程修改过)
- 交换 - 如果相等,则把B写入V
- 返回操作是否成功
CAS伪代码:
下面的代码并不是原子的,而是方便大家理解CAS的运行流程
/**
* address 内存地址
* expectValue 存放在寄存器A中的比较值A
* swapValue 存放在寄存器B中用于交换的值B
* 这里的比较 - 指的是比较内存和寄存器A中的值,如果相等则把寄存器B的值写入寄存器A
*/
boolean CAS(address, expectValue, swapValue) {
if (&address == expectedValue) {
&address = swapValue;
return true;
}
return false;
}
注意: 当多个线程尝试对同一共享资源修改,只有一个线程会成功,但是并不会阻塞其他线程,其他线程只会收到失败的信号,这也是乐观锁策略的实现实例,并没有涉及到加锁和释放锁,所以乐观锁策略也被称为无锁编程
CAS的应用
1) 实现原子类
Java标准库中的java.util.concurrent.atomic包下的类都是基于这样的方法来实现的.
| 类型名称 | 代表类 |
|---|---|
| 基本类型 | AtomicInteger、AtomicLong、AtomicBoolean |
| 引用类型 | AtomicReference、AtomicStampedRerence、AtomicMarkableReference |
| 数组类型 | AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray |
| 对象属性原子修改器 | AtomicIntegerFieldUpdater、AtomicLongFieldUpdater、 AtomicReferenceFieldUpdater |
| 原子类型累计器(JDK 1.8新增) | DoubleAccumulator、DoubleAdder、LongAccumulator、LongAdder、Striped64 |
下面先介绍AtomicInteger 类的常用方法
| 方法原型 | 解释 |
|---|---|
| int getAndIncrement() | 以原子方法使实例值加一,返回自增前的旧值 |
| int getAndIncrement() | 将实例中的值更新为新值,并返回旧值 |
| int incrementAndGet() | 以原子方法使实例值加一,返回自增后的新值 |
| int addAndGet(int delta) | 以原子方法使实例值加上输入的值,返回的相加后的值 |
getAndIncrement()伪代码:
class AtomicInteger {
private int value;
public int getAndIncrement() {
int oldValue = value;
while ( CAS(value, oldValue, oldValue+1) != true) {
oldValue = value;
}
return oldValue;
}
}
两个线程调用getAndIncrement()的具体步骤
public static AtomicInteger count = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 5000; i++) {
count.getAndIncrement();
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 5000; i++) {
count.getAndIncrement();
}
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("count = " + count);
}
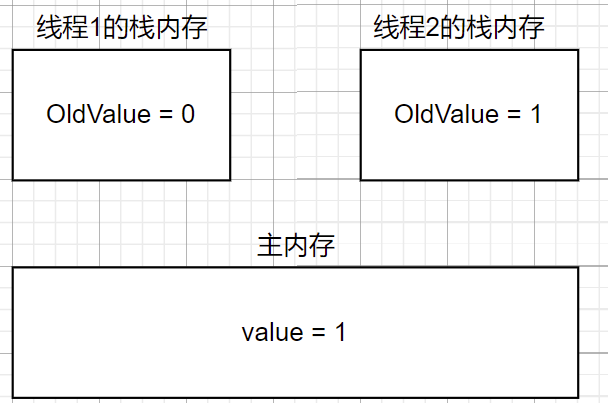
- 线程1和线程2把主内存中的值读到自己的栈内存中.
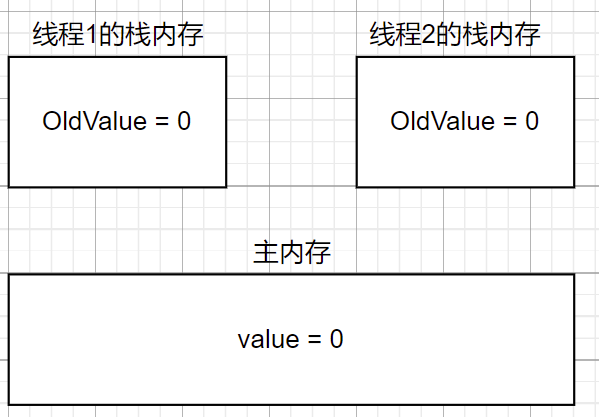
- 线程1先执行CAS操作,先比较,由于oldvalue和value相同,随后自增后赋值
注: CAS使直接读内存,而不是操作寄存器.
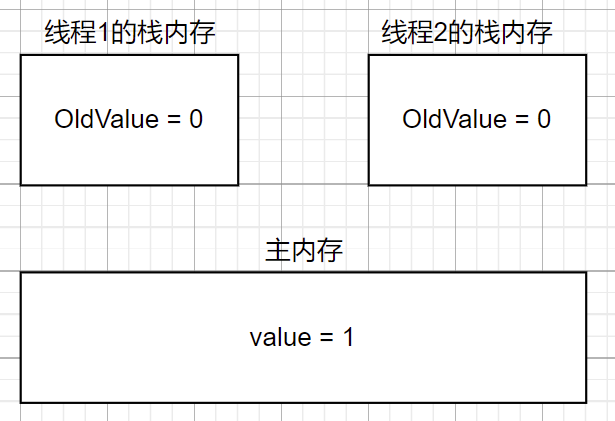
- 然后线程2执行CAS操作,先比较,由于oldvalue和value不同,因此不能直接赋值,因此进入循环把oldvalue赋值给value
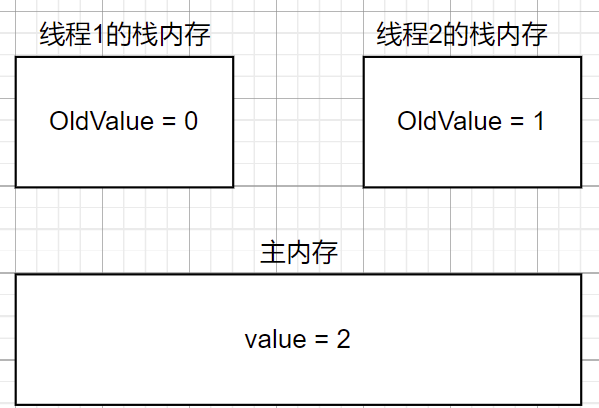
- 接下来线程2第二次执行CAS,先比较,oldvalue和value相同,然后自增后赋值
- 循环上述操作.
注: 上述操作中的check and set虽然不是原子的,但是在硬件层面上可以使一条指令完成这些操作,也就变成原子的了.
2) 实现自旋锁
基于CAS实现的自旋锁.
自旋锁伪代码:
public class SpinLock {
private Thread owner = null;
public void lock(){
while(!CAS(this.owner, null, Thread.currentThread())){
}
}
public void unlock (){
this.owner = null;
}
}
- CAS检查当前锁是否被某个线程持有
- 当ower == null 时CAS才能成功,循环结束,否则说明当前锁被其他线程持有,所以一直自旋等待.
CAS的ABA问题
1) 什么是ABA问题
假设存在t1,t2两个线程,有一个共享变量n.初始值为A
接下来,线程t1使用CAS把变量n修改为B,那么就需要
- 读取变量n,赋值给oldvalue.
- 判断oldvalue是否等于A,如果时,则修改为B
然而,在t1执行这两个操作的时候,t2线程可能把n值从A修改为B,然后又把B修改为A.
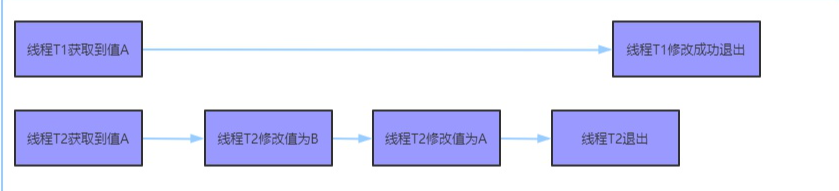
但是这个变量n值还是原来的A,不是原来的A,虽然对结果似乎没有什么影响,这就好比,我们去买手机,对于外行的我们不知道该手机是刚出场的手机,还是翻新机.
2) ABA引发的BUG
虽然对于上面的修改结果是没有影响的,但是在一些特殊情况下又不同的效果
假设鸡哥有100存款,鸡哥想从ATM中取50元,取款机会创建两个线程,并发地线程执行-50.
我们期望一个线程执行-50成功,另一个线程 -50 失败
如果使用 CAS 的方式来完成这个扣款过程就可能出现问题.
正常的过程:
- 存款 100. 线程1 获取到当前存款值为 100, 期望更新为 50; 线程2 获取到当前存款值为 100, 期望更新为 50.
- 线程1 执行扣款成功, 存款被改成 50. 线程2 阻塞等待中
- 线程2 执行了, 发现当前存款为 50, 和之前读到的 100 不相同, 执行失败
异常的过程;
- 存款 100. 线程1 获取到当前存款值为 100, 期望更新为 50; 线程2 获取到当前存款值为 100, 期望更新为 50
- 线程1 执行扣款成功, 存款被改成 50. 线程2 阻塞等待中
- 在线程2 执行之前, 鸡哥的朋友正好给鸡哥转账 50, 账户余额变成 100
- 轮到线程2 执行了, 发现当前存款为 100, 和之前读到的 100 相同, 再次执行扣款操作
于是扣款操作执行了两次!!
解决方案:
在修改之前,添加一个版本号,用来标记当前值是否被CAS修改过.
所以在读取时: 由CAS读取旧数据值时同时读取版本号,二者都相同才能修改
在修改时:如果版本号和数据是相同的,则修改成功,内存的版本号+1,如果有一个不同,则修改失败
类比到刚才的买手机,对于不同新机和翻新机,它们的序列号是不同的.
在对比理解转账过程:
我们给主内存中的余额添加一个版本号,初始为1
- 存款 100. 线程1 获取到 存款值为 100, 版本号为 1, 期望更新为 50; 线程2 获取到存款值为 100,版本号为 1, 期望更新为 50
- 线程1 执行扣款成功, 存款被改成 50, 版本号改为2. 线程2 阻塞等待中.
- 在线程2 执行之前, 鸡哥的朋友正好给鸡哥转账 50, 账户余额变成 100,版本号变成3
- 轮到线程2 执行了, 发现当前存款为 100, 和之前读到的 100 相同, 但是当前版本号为 3, 之前读到的版本号为 1, 版本小于当前版本, 认为操作失败
Synchronized 原理
加锁的工作流程
在对象头中的Mark word字段中存在下面的4种锁状态: 无锁态 -> 偏向锁 -> 轻量级锁(自旋锁) -> 重量级锁
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CF101QZd-1659615800647)(C:\Users\a\AppData\Roaming\Typora\typora-user-images\image-20220801205948295.png)]](https://img-blog.csdnimg.cn/48a7cb093798438e948c7934aef6aaa6.png)
1) 偏向锁:
偏向锁的字面意思就是"偏向第一个获取它线程的锁",但是它并不是真正的上锁,通过上图知道是对象头中对比特位进行标记,表明这个"锁"是属于当前线程的,当执行当前代码块后,并不会"释放锁",而是在有其他线程竞争该锁时,才会"释放锁",进入轻量锁状态,可以发现,如果没有第二个线程来竞争,那么它的效率是很高的,几乎没有什么开销.
2) 轻量级锁:
当有其他线程进入去竞争锁时,偏向锁状态被清除,进而转变为轻量级锁(自旋锁)
而此处的自旋锁就是CAS实现的.
- 通过CAS操作修改对象头的锁标志位,先比较当前锁标志位是否为释放状态
- 如果是,则修改其为锁定状态,
- 如果不是,则循环等待,直到锁被释放.
如果我们获取锁时间长,那么其他在等待的线程会进入长时间的循环等待,这个过程是十分消耗资源的,相当于当前只有一个线程在工作,其他等待线程都在占用CPU,这种现象称为"忙等",但是Synchronized 的实现并不会让他一直循环,即允许短时间的忙等,可以换取线程在用户态和内核态自己切换所需的开销(因为等待的线程并没有进入阻塞,而是占用CPU等待释放锁,所有就没有唤醒操作,而唤醒操作就需要切换状态),
3) 重量级锁:
如果锁竞争严重,达到某个最大自旋次数的线程(JVM 有一个计数器记录自旋次数,默认允许循环 10 次,可以通过虚拟机参数更改)会将轻量级锁升级为重量级锁,当后续线程尝试获取锁时,发现被占用的锁是重量级锁,则直接将自己挂起(是上面的挂起等待锁),等待释放锁的线程去唤醒.
其他的优化操作
锁消除
锁消除: 在编译器和JVM共同判断锁是否可以消除.
StringBuffer sb = new StringBuffer(); sb.append("a"); sb.append("b"); sb.append("c"); sb.append("d"); //append方法自带锁 @Override public synchronized StringBuffer append(String str) { toStringCache = null; super.append(str); return this; }
由于每次调用append方法都会加锁和解锁,在单线程场景下,没有锁也不会有线程安全问题,所以为了优化就会"锁消除"
在举个例子,你去银行取钱,在没有人办理业务时,你不需要等待(不需要阻塞),直接去办理业务.
锁粗化
锁消除: 在代码块中存在多次加锁解锁操作,编译器会对其优化,进行锁的粗化
我们再用去银行办业务的例子讲解锁的粒度:
当我们去银行办理业务时,在窗口前完成业务的过程是最高效的,如果这时候你忘记带身份证了,你就打电话叫家人给你带来,这样就很浪费时间,最高效的方法是:在办理业务前准备好相关资料.
对于加锁也一样,把无关工作放到锁外面,锁内部只处理并发的内容,减少锁的粒度,提高了效率
但是有时候我们又需要锁粗化的优化,
比如你去银行办理业务,为了减少办理业务的时间,你把任务分为5份,其实这增加任务完成的时间,因为你会多次的排队,取号,等待.
对于加锁也一样,在一段代码块中反复的对同一对象加锁解锁,这是十分浪费资源的,最好的解决方案是:适当放宽锁的范围,以减少资源消耗.
如下面的代码:
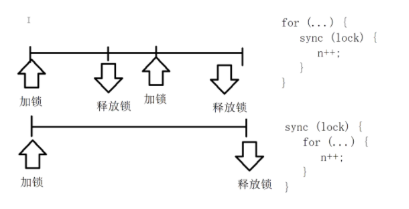
for(int i=0;i<10000;i++){ synchronized(this){ do(); }就会被粗化为:
synchronized(this){ for(int i=0;i<10000;i++){ do(); }
在设计开发中我们提倡减少锁的粒度,也就是避免不必要的加锁,避免不必要的阻塞等待.这也是很多程序员使用同步代码块来代替同步方法的原因.
JUC(java.util.concurrent) 中的常见类和接口
java.util.concurrent包下相关开发工具是针对并发环境开发的重要工具,下面介绍一些常用的工具
可返回线程:Callable接口
Callable与Runnable的异同点
callable接口类似于Runnable接口,它们都可以表示由单独的线程并发执行任务.
不同点是callable接口的call()方法有返回值,而Runnable接口的run()方法没有返回值.
Runnable 最初设计用于长时间运行的并发任务,例如同时运行的网络服务器.Callable 接口更适用于返回单个结果的一次性任务。
Callable的使用
public static void main(String[] args) throws ExecutionException, InterruptedException {
//1. 创建匿名内部类,明确任务,泛型参数为接口返回值
Callable<Integer> callable = new Callable<Integer>() {
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 1; i <= 100; i++) {
sum += i;
}
return sum;
}
};
//2.接受返回结果
FutureTask<Integer> futureTask = new FutureTask<>(callable);
Thread t = new Thread(futureTask);
t.start();
//3. futureTask.get()可以阻塞等待t线程执行完毕
int res = futureTask.get();
System.out.println(res);
}
Callable 通常需要搭配 FutureTask 来使用. FutureTask 用来保存 Callable 的返回结果. 因为Callable 往往是在另一个线程中执行的, 啥时候执行完并不确定.而FutureTask 就可以负责这个等待结果出来的工作.
线程执行结果:Future接口
Future接口
Future是用来获取异步执行的结果.下面是它的常用方法
| 方法名 | 解释 |
|---|---|
| boolean cancel(boolean mayInterruptIfRunning) | 取消异步任务,并且该任务是已实现且正在执行的,否则调用无效 |
| boolean isCancelled() | 检查异步任务是否被取消 |
| boolean isDone() | 检查异步任务是否完成 |
| V get() throws InterruptedException, ExecutionException | 返回异步任务的结果 |
| V get(long timeout, TimeUnit unit) | 在指定时间结束后返回任务结果 |
public static void main(String[] args) throws ExecutionException, InterruptedException, TimeoutException {
ExecutorService executorService = Executors.newFixedThreadPool(10);
Future<String> future = executorService.submit(() -> {
return "Hello world";
});
//取消任务
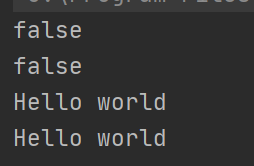
System.out.println(future.cancel(true));
//任务是否被取消
System.out.println(future.isCancelled());
//任务是否结束
System.out.println(future.isDone());
//获取结果
String s = future.get();
System.out.println(s);
//在指定时间结束后返回结果
s = future.get(1000,TimeUnit.MILLISECONDS);
System.out.println(s);
}
执行结果:
抛出异常的原因是get()方法必须是任务没有被取消.
不取消任务后,就没有异常了
/>

FutureTask类
FutureTask类实现RunnableFuture接口, 而RunnableFuture接口继承于Runnable, Future接口,
构造方法:
| 构造方法 | 解释 |
|---|---|
| public FutureTask(Callable callable) | 通过Callable对象构造,此时FutureTask的返回值就是Callable的返回值 |
| public FutureTask(Runnable runnable, V result) | 提供Ruunable对象和一个泛型变量,然后把Runnable对象伪装成Callable对象,同时其返回值就是我们传入的泛型变量 |
源码:
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW; // ensure visibility of callable
}
public FutureTask(Runnable runnable, V result) {
//装饰者模式
this.callable = Executors.callable(runnable, result);
this.state = NEW; // ensure visibility of callable
}
成员变量:
// 当前任务状态
private volatile int state;
// 新创建的任务,还未开始执行
private static final int NEW = 0;
// 当前任务正在结束中,但是任务还未完全结束,比如返回值还未写入
private static final int COMPLETING = 1;
// 当前任务是正常结束的(未发生异常,中断,取消)
private static final int NORMAL = 2;
// 当前任务因异常而中断
private static final int EXCEPTIONAL = 3;
// 当前任务因调用cancel方法而被取消执行
private static final int CANCELLED = 4;
// 当前任务处于中断状态,未完全中断,比如有些代码还在执行
private static final int INTERRUPTING = 5;
// 当前任务已完全中断
private static final int INTERRUPTED = 6;
// 用于接受传入的Callable对象或者成为Runnable对象的伪装
private Callable<V> callable;
// 存储返回值 任务正常结束保存任务的返回结果,否则,保存异常信息
private Object outcome;
// 当前执行的线程
private volatile Thread runner;
// 因为有很多线程去调用get()来获取结果,使用堆栈中记录等待线程的简单链表节点
private volatile WaitNode waiters;
static final class WaitNode {
// 线程对象
volatile Thread thread;
// 下一个WaitNode节点
volatile WaitNode next;
// 获取当前线程来初始化当前线程
WaitNode() { thread = Thread.currentThread(); }
}
常用方法:
| 方法名 | 解释 |
|---|---|
| public void run() | 执行当前任务 |
| public boolean isCancelled() | 任务是否被取消 |
| public boolean isDone() | 任务是否结束 |
| public boolean cancel(boolean mayInterruptIfRunning) | 设置当前任务是否取消 |
| public V get() | 获取任务结果 |
| public V get(long timeout, TimeUnit unit) | 在设定时间后获取任务结果 |
总结:
- FutureTask是异步执行方式
- FutureTask使用get()方法返回的结果时,如果任务未完成,则调用get()的线程会陷入阻塞,直到任务执行结束
锁: Lock接口
Lock是一个接口,ReentrantLock是其实现类,下面简单康康其使用方法
Lock lock = new ReentrantLock();
lock.lock();
//Operation...
lock.unlock();
- 创建lock对象
- 某个线程调用lock对象的lock方法,该实例对象就被锁住了,其他线程想要调用lock方法就会被阻塞.
- 调用unlock()方法,其他线程就可以对其锁定了
下面介绍Lock接口的实现类: ReentrantLock
ReentrantLock使用方法:
| 方法名 | 解释 |
|---|---|
| public void lock() | 上锁,如果获取不到锁就进入阻塞队列 |
| public void unlock() | 解锁 |
| public boolean tryLock(long timeout, TimeUnit unit) | 加锁, 如果获取不到锁, 等待一定的时间之后就放弃加锁 |
public static void main(String[] args) {
ReentrantLock lock = new ReentrantLock(true);
try {
lock.lock();
//code...
} finally {
lock.unlock();
}
}
ReentrantLock 和 synchronized 的区别 :
- Synchronized是对代码块或者方法块上锁,而ReentrantLock类是对其使用lock()上锁,使用unlock()解锁,可以在不同的方法块中,还容易遗忘
- Synchronized只能是"非公平锁",而ReentrantLock可以是公平锁和非公平锁,通过构造方法设置
public ReentrantLock(boolean fair) { // true -> 公平 false -> 非公平 sync = fair ? new FairSync() : new NonfairSync(); }
- ReentrantLock 的lock方法失败则进入阻塞队列,而tryLock方法失败后,返回false,然后向下执行
- 更强大的唤醒机制. synchronized 是通过 Object 的 wait / notify 实现等待-唤醒. 每次唤醒的是一个随机等待的线程. ReentrantLock 搭配 Condition 类实现等待-唤醒, 可以更精确控制唤醒某个指定的线程
使用场景:
- 锁竞争不激烈的时候, 使用 synchronized, 效率更高, 自动释放更方便
- 锁竞争激烈的时候, 使用 ReentrantLock, 搭配 trylock 更灵活控制加锁的行为, 而不是死等.
- 如果需要使用公平锁, 使用 ReentrantLock
线程池
在频繁创建销毁线程时效率十分低效,线程池就是解决这个频繁创建销毁问题,创建时从线程池拿或者由系统创建,销毁时放入线程池
ExecutorService 和 Executors
- ExecutorService 表示一个线程池实例
- Executors 是一个工厂类, 能够创建出几种不同风格的线程池
Executors 创建线程池的几种方式
| 构造方法 | 解释 |
|---|---|
| newFixedThreadPool(int nThreads) | 创建固定线程数的线程池 |
| newCachedThreadPool() | 创建线程数目动态增长的线程池 |
| newSingleThreadExecutor() | 创建只包含单个线程的线程池. |
| newScheduledThreadPool(int corePoolSize, ThreadFactory threadFactory) | 设定 延迟时间后执行命令,或者定期执行命令. 是进阶版的 Timer. |
ThreadPoolExecutor
构造方法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7TPw8a21-1659615800648)(C:\Users\a\AppData\Roaming\Typora\typora-user-images\image-20220803210311734.png)]](https://img-blog.csdnimg.cn/4698ed1d7896461492aaaa3edf81d085.png)
理解 ThreadPoolExecutor 构造方法的参数
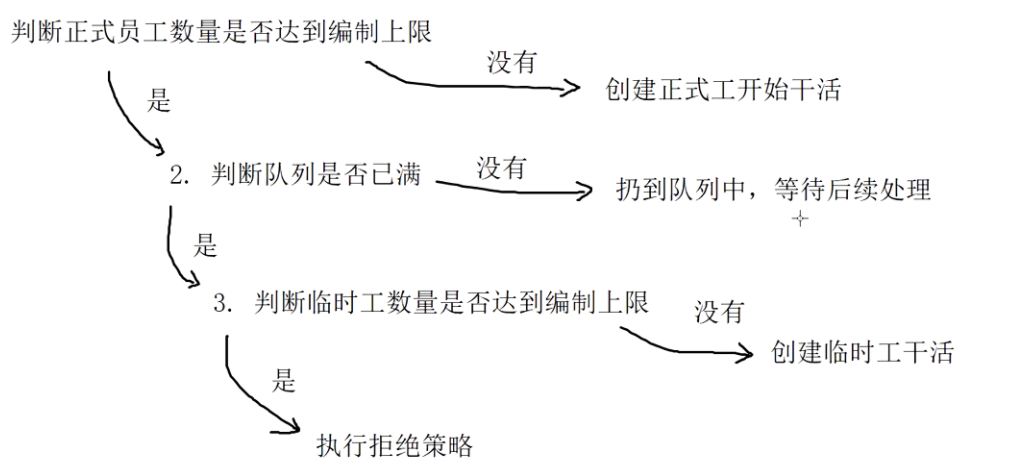
把创建一个线程池想象成开个公司. 每个员工相当于一个线程.
- corePoolSize: 核心线程数,线程是否空闲,始终都存在,正式员工的数量. (正式员工, 一旦录用, 永不辞退)
- maximumPoolSize: 最大线程数 = 临时线程数(繁忙时创建,空闲时销毁)+核心线程数
- keepAliveTime: 临时工允许的空闲时间
- unit: keepaliveTime 的时间单位, 是秒, 分钟, 还是其他值
- workQueue: 传递任务的阻塞队列
- threadFactory: 创建线程的工厂, 参与具体的创建线程工作
- RejectedExecutionHandler: 拒绝策略, 如果任务量超出公司的负荷了接下来怎么处理
- AbortPolicy(): 超过负荷, 直接抛出异常
- CallerRunsPolicy(): 调用者负责处理
- DiscardOldestPolicy(): 丢弃队列中最老的任务
- DiscardPolicy(): 丢弃新来的任务.
线程池是如何执行的
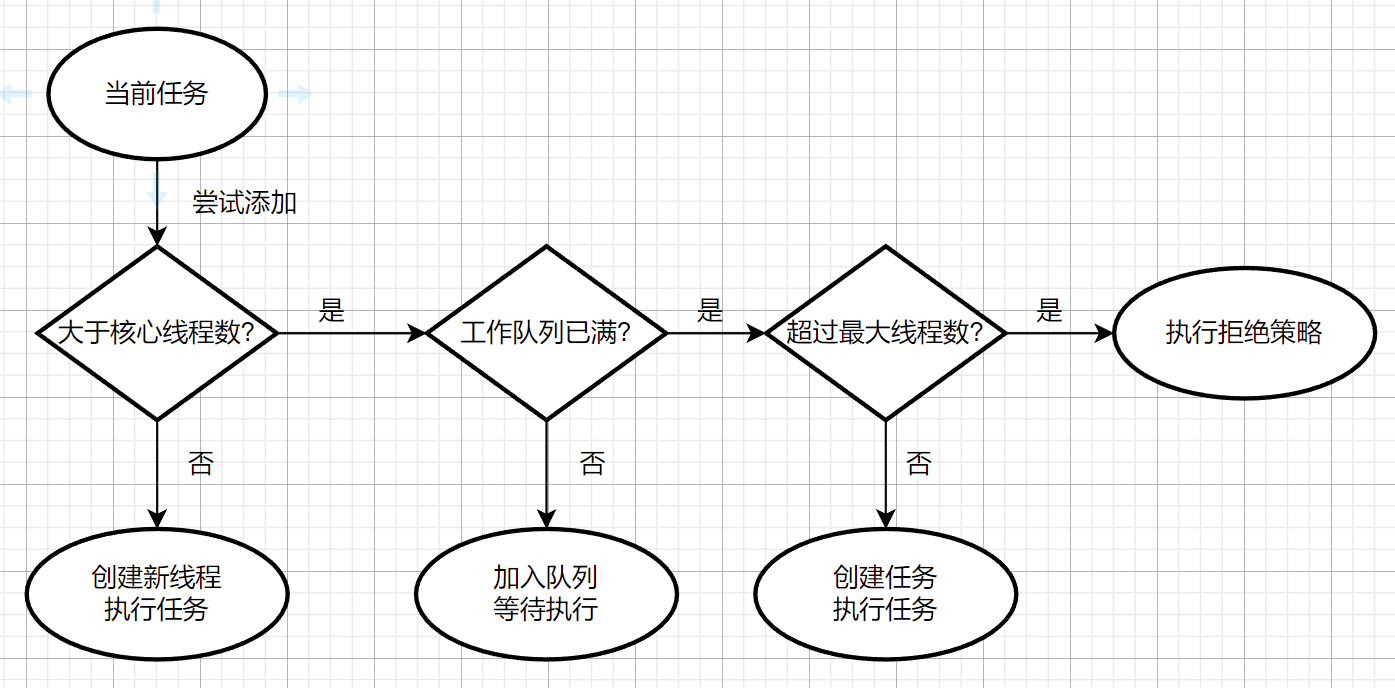
在谈到其是如何执行的,就不得不康康其execute方法,下面是官方源码,
public void execute(Runnable command) {
// 任务为空, 抛出异常
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
// 当前工作的线程数小于核心线程数
if (workerCountOf(c) < corePoolSize) {
// 创建新的线程执行此任务
if (addWorker(command, true))
return;
c = ctl.get();
}
// 当前任务正在运行并且可以加入工作队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 再次检线程池是否处于运行状态,防止在第一次校验通过后线程池关闭
if (! isRunning(recheck) && remove(command))
// 次检线程池是否处于运行状态,防止在第一次校验通过后线程池关闭
reject(command);
// 如果线程池的线程数为 0 时
else if (workerCountOf(recheck) == 0)
// 启动一个新线程
addWorker(null, false);
}
// 核心线程都在忙且队列都已满,尝试新启动一个线程执行失败
else if (!addWorker(command, false))
// 执行拒绝策略
reject(command);
}
概述其3个if判断步骤:
如果正在运行的线程少于corePoolSize,尝试用给定的命令启动一个新线程作为它的第一个任务。对addWorker的调用自动地检查runState和workerCount,因此通过返回false来防止在不应该添加线程的时候添加线程的错误警报。
如果一个任务可以成功地排队,那么我们仍然需要再次检查是否应该添加一个线程(因为自上次检查以来已有的线程已经死亡),或者自进入该方法以来池已经关闭。因此,我们重新检查状态,如果需要,则回滚排队停止,如果没有线程,则启动一个新线程。
如果我们不能对任务进行队列,那么我们尝试添加一个新线程。如果它失败了,我们知道我们被关闭或饱和,因此拒绝任务。
如图:
线程池的拒绝策略
当任务过多且线程池的任务队列已满时,此时就会执行线程池的拒绝策略,线程池的拒绝策略默认有以下 4 种:
| 策略名 | 解释 |
|---|---|
| AbortPolicy | 中止策略,线程池会抛出异常并中止执行此任务(默认策略) |
| CallerRunsPolicy | 把任务交给添加此任务的(main)线程来执行 |
| DiscardPolicy | 忽略最新的一个任务 |
| DiscardOldestPolicy | 忽略最早的任务,即最先加入队列的任务。 |
DiscardPolicy拒绝策略
设置最大核心线程数为1,那么当第一个任务执行,大于核心线程数,由于该拒绝策略会忽视最新的任务,所以最终结果应该只有两个任务执行
public static void main(String[] args) {
// 任务的具体方法
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("当前任务被执行,执行时间:" + new Date() +
" 执行线程:" + Thread.currentThread().getName());
try {
// 等待 1s
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
// 创建线程,线程的任务队列的长度为 1
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1,
1,
100,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1),
new ThreadPoolExecutor.DiscardPolicy());
// 添加并执行 4 个任务
threadPool.execute(runnable);
threadPool.execute(runnable);
threadPool.execute(runnable);
threadPool.execute(runnable);
// 线程池执行完任务,关闭线程池
threadPool.shutdown();
}
执行结果:

AbortPolicy拒绝策略
public static void main(String[] args) {
// 任务的具体方法
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("当前任务被执行,执行时间:" + new Date() +
" 执行线程:" + Thread.currentThread().getName());
try {
// 等待 1s
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
// 创建线程,线程的任务队列的长度为 1
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1,
1,
100,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1),
new ThreadPoolExecutor.AbortPolicy()); //默认拒绝策略,可以显示指出
// 添加并执行 4 个任务
threadPool.execute(runnable);
threadPool.execute(runnable);
threadPool.execute(runnable);
threadPool.execute(runnable);
// 线程池执行完任务,关闭线程池
threadPool.shutdown();
}
默认的拒绝策略为,大于核心线程数后就抛出异常
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Xbg5u1HH-1659631265484)(C:\Users\a\AppData\Roaming\Typora\typora-user-images\image-20220805002853621.png)]](https://img-blog.csdnimg.cn/1724bc44b6454fc2bb4341d2ce1fc2d7.png)
CallerRunsPolicy拒绝策略:
public static void main(String[] args) {
// 任务的具体方法
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("当前任务被执行,执行时间:" + new Date() +
" 执行线程:" + Thread.currentThread().getName());
try {
// 等待 1s
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
// 创建线程,线程的任务队列的长度为 1
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1,
1,
100,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1),
new ThreadPoolExecutor.CallerRunsPolicy()); //默认拒绝策略,可以显示指出
// 添加并执行 4 个任务
threadPool.execute(runnable);
threadPool.execute(runnable);
threadPool.execute(runnable);
threadPool.execute(runnable);
// 线程池执行完任务,关闭线程池
threadPool.shutdown();
}
大于最大核心线程数后就由main线程执行.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wCr32eb2-1659631265500)(C:\Users\a\AppData\Roaming\Typora\typora-user-images\image-20220805003217006.png)]](https://img-blog.csdnimg.cn/f27a00239abf41948136710ea04be9d8.png)
DiscardOldestPolicy拒绝策略
public static void main(String[] args) {
// 任务的具体方法
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("当前任务1被执行,执行时间:" + new Date() +
" 执行线程:" + Thread.currentThread().getName());
try {
// 等待 1s
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
Runnable runnable1 = new Runnable() {
@Override
public void run() {
System.out.println("当前任务2被执行,执行时间:" + new Date() +
" 执行线程:" + Thread.currentThread().getName());
try {
// 等待 1s
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
Runnable runnable2 = new Runnable() {
@Override
public void run() {
System.out.println("当前任务3被执行,执行时间:" + new Date() +
" 执行线程:" + Thread.currentThread().getName());
try {
// 等待 1s
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
Runnable runnable3 = new Runnable() {
@Override
public void run() {
System.out.println("当前任务4被执行,执行时间:" + new Date() +
" 执行线程:" + Thread.currentThread().getName());
try {
// 等待 1s
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
// 创建线程,线程的任务队列的长度为 1
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1,
1,
100,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1),
new ThreadPoolExecutor.DiscardOldestPolicy());
// 添加并执行 4 个任务
threadPool.execute(runnable);
threadPool.execute(runnable1);
threadPool.execute(runnable2);
threadPool.execute(runnable3);
// 线程池执行完任务,关闭线程池
threadPool.shutdown();
}
任务1进入,创建新线程来执行,任务2进入,队列和临时线程已满,执行拒绝策略,任务2被丢弃,任务3也是如此,在任务1执行完后,任务4执行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fVTD9ISb-1659631265500)(C:\Users\a\AppData\Roaming\Typora\typora-user-images\image-20220805003711276.png)]](https://img-blog.csdnimg.cn/dfcff2cad78e4383bd388eeb1b5f83d2.png)
线程池的工作流程
面试题
使用线程池时,线程数目设置为多少比较合适
不能回答具体设置,但可以回答找到合适线程的方法->压测(性能测试)针对当前的程序进行性能测试,分别设置不同的线程数目,分别进行测试,在测试过程中,会记录程序的时间, CPU占用,内存占用…根据压测结果,来选择咱们觉得最适合当前场景的数目.
信号量: Semaphore
信号量, 用来表示 “可用资源的个数”. 本质上就是一个计数器
可以把信号量想象成是停车场的展示牌: 当前有车位N个. 表示有 N个可用资源
- 当有车开进去的时候, 就相当于申请一个可用资源, 可用车位就 -1 (这个称为信号量的 P 操作)
- 当有车开出来的时候, 就相当于释放一个可用资源, 可用车位就 +1 (这个称为信号量的 V 操作)
- 如果计数器的值已经为 0 了, 还尝试申请资源, 就会阻塞等待, 直到有其他线程释放资源
Semaphore 的 PV 操作中的加减计数器操作都是原子的, 可以在多线程环境下直接使用.
示例:
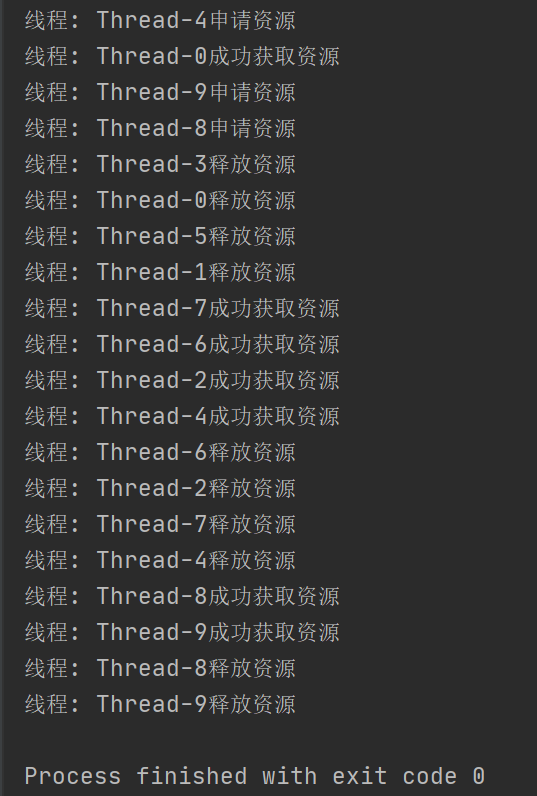
public static void main(String[] args) {
//创建 Semaphore 示例, 初始化为 4, 表示有4个可用资源
Semaphore semaphore = new Semaphore(4);
//创建10个线程,每个线程都尝试申请资源,休眠1s后,释放资源
for (int i = 0; i < 10; i++) {
Thread t = new Thread(new Runnable() {
@Override
public void run() {
try {
System.out.println("线程" + Thread.currentThread().getName() + "申请资源");
semaphore.acquire();
System.out.println("线程" + Thread.currentThread().getName()+ "成功获取资源");
Thread.sleep(10000);
System.out.println("线程" + Thread.currentThread().getName()+ "释放资源");
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
}
}
申请和释放资源都是随机的,
任务执行结束: CountDownLatch
同时等待 N 个任务执行结束
例如跑步比赛,10个选手依次就位,哨声响才同时出发;所有选手都通过终点,才能公布成绩
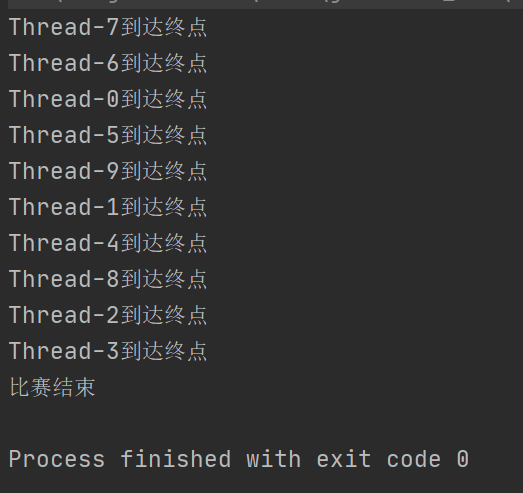
public static void main(String[] args) throws InterruptedException {
// 构造方法传入10.代表有10名选手
CountDownLatch latch = new CountDownLatch(10);
for (int i = 0; i < 10; i++) {
Thread t = new Thread(new Runnable() {
@Override
public void run() {
try {
//随机休眠时间
Thread.sleep((long) (1000 *Math.random()));
System.out.println(Thread.currentThread().getName() + "到达终点");
//相当于撞线
latch.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
}
// await 在等待所有的线程 "撞线"
// 当调用 countDown 的次数达到初始化的时候设定的值,wait 就返回,否则 await 就阻塞等待
latch.await();
System.out.println("比赛结束");
}
面试问题
- 线程同步的方式有哪些?
synchronized, ReentrantLock, Semaphore 等都可以用于线程同步.
- 为什么有了 synchronized 还需要 juc 下的 lock?
- Synchronized是对代码块或者方法块上锁,而ReentrantLock类是对其使用lock()上锁,使用unlock()解锁,可以在不同的方法块中,还容易遗忘
- Synchronized只能是"非公平锁",而ReentrantLock可以是公平锁和非公平锁,可以在构造方法中设置true
- synchronized 在申请锁失败时, 会死等. ReentrantLock 可以通过 trylock 的方式等待一段时间就放弃
- synchronized 是通过 Object 的 wait / notify 实现等待-唤醒. 每次唤醒的是一个随机等待的线程. ReentrantLock 搭配 Condition 类实现等待-唤醒, 可以更精确控制唤醒某个指定的线程
- 信号量听说过么?之前都用在过哪些场景下?
信号量, 用来表示 “可用资源的个数”. 本质上就是一个计数器.
使用信号量可以实现 “共享锁”, 比如某个资源允许 3 个线程同时使用, 那么就可以使用 P 操作作为加锁, V 操作作为解锁, 前三个线程的 P 操作都能顺利返回, 后续线程再进行 P 操作就会阻塞等待,直到前面的线程执行了 V 操作
线程安全的集合类
我们之前学习的List.Map,Set中的实现类大部分都是不安全的.
多线程环境使用 ArrayList
- 使用同步机制 (synchronized 或者 ReentrantLock)
- Collections.synchronizedList(new ArrayList)
synchronizedList 是标准库提供的一个基于 synchronized 进行线程同步的 List.
synchronizedList 的关键操作上都带有 synchronized
- 使用 CopyOnWriteArrayList
CopyOnWrite容器即写时复制的容器
- 当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素
- 添加完元素之后,再将原容器的引用指向新的容器
这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素
所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器
优点: 在读多写少的场景下, 性能很高, 不需要加锁竞争
缺点: 占用内存较多,新写的数据不能被第一时间读取到
多线程环境使用队列
- 阻塞队列 BlockingQueue
BlockingQueue 通常用于一个线程生产对象,而另外一个线程消费这些对象的场景
- 数组阻塞队列 ArrayBlockingQueue
ArrayBlockingQueue 是一个有界的阻塞队列,其内部实现是将对象放到一个数组里, 内部以 FIFO(先进先出)的顺序对元素进行存储。队列中的头元素在所有元素之中是放入时间最久的那个,而尾元素则是最短的那个。
- 延迟队列 DelayQueue
elayQueue 实现了 BlockingQueue 接口,DelayQueue 对元素进行持有直到一个特定的延迟到期.注入其中的元素必须实现 java.util.concurrent.Delayed 接口
- 链阻塞队列 LinkedBlockingQueue
LinkedBlockingQueue 类实现了 BlockingQueue 接口,LinkedBlockingQueue 内部以一个链式结构(链接节点)对其元素进行存储。
- 具有优先级的阻塞队列: PriorityBlockingQueue
PriorityBlockingQueue 的元素必须实现 java.lang.Comparable 接口。因此该队列中元素的排序就取决于你自己的 Comparable 实现。
- 同步队列: SynchronousQueue
它的内部同时只能够容纳单个元素。如果该队列已有一元素的话,试图向队列中插入一个新元素的线程将会阻塞,直到另一个线程将该元素从队列中抽走
多线程环境使用哈希表
HashMap 本身不是线程安全的 ,而Hashtable,ConcurrentHashMap 使用Collections.synchronizedMap(Map)创建线程安全的map集合 是线程安全的,
synchronizedMap
实现线程安全的方式:
SynchronizedMap内部维护了一个普通对象Map,排斥锁mutex
其构造方法首先需要传入一个Map,如果你传入了mutex参数,则将对象排斥锁赋值为传入的对象.如果没有,则将对象排斥锁赋值为this,即调用synchronizedMap的对象,就是上面的Map
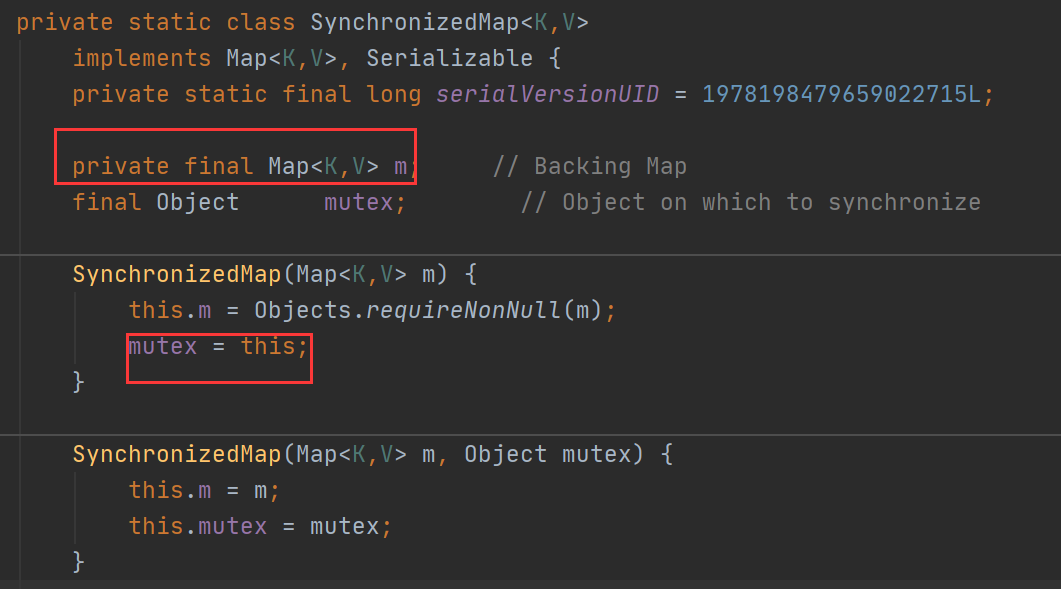
创建出synchronizedMap之后,其实例方法全部都是🔒
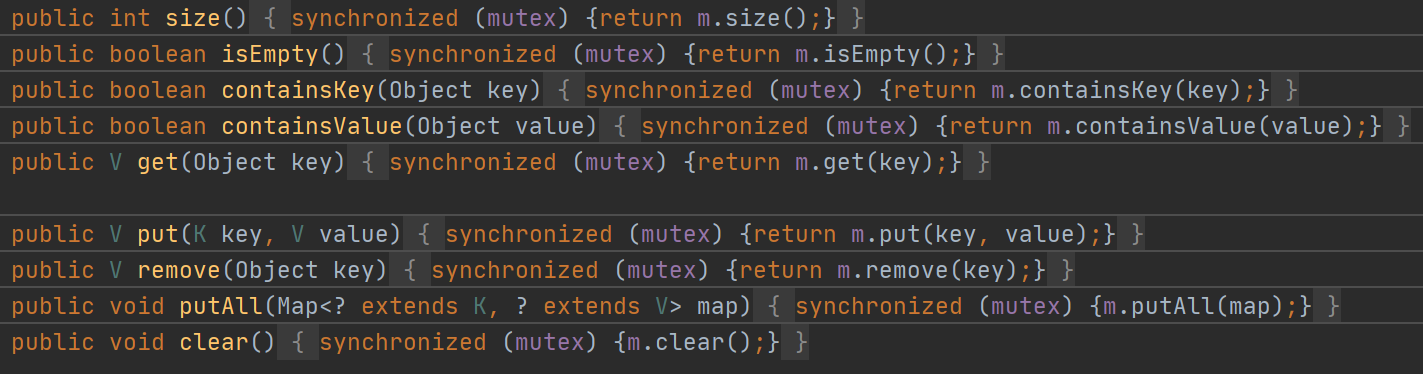
Hashtable
它在对数据操作的时候都会上锁,导致效率比较低下。
public synchronized int size() public synchronized boolean isEmpty() public synchronized boolean contains(Object value) public synchronized V get(Object key) public synchronized V put(K key, V value) ...
- 如果多线程访问同一个 Hashtable 就会直接造成锁冲突
- 一旦触发扩容, 就由该线程完成整个扩容过程. 这个过程会涉及到大量的元素拷贝, 效率会非常低
ConcurrentHashMap
ConcurrentHashMap 底层是基于 数组 + 链表 组成的,在JDK1.7中采用了分段锁技术
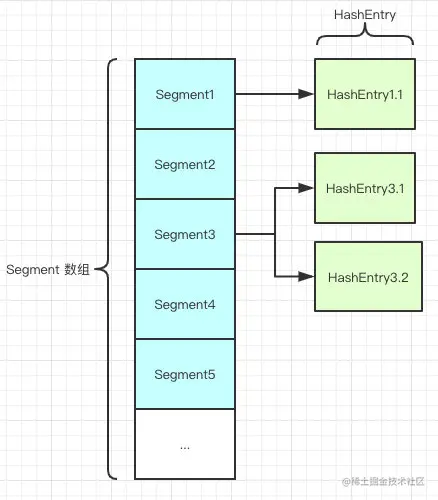
在put和get操作时,不同线程占用锁访问一个 Segment 时,不会影响到其他的 Segment
而在JDK1.8后,抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性,并且也引入了红黑树,在链表大于一定值(8)的时候会转换
- 读操作没有加锁(但是使用了 volatile 保证从内存读取结果), 只对写操作进行加锁. 加锁的方式仍然是用 synchronized, 但是不是锁整个对象, 而是 “锁桶” (用每个链表的头结点作为锁对象), 大大降低了锁冲突的概率
- 充分利用 CAS 特性. 比如 size 属性通过 CAS 来更新. 避免出现重量级锁的情况
- 优化了扩容方式: 化整为零
- 发现需要扩容的线程, 只需要创建一个新的数组, 同时只搬几个元素过去
- 扩容期间, 新老数组同时存在
- 后续每个来操作 ConcurrentHashMap 的线程, 都会参与搬家的过程. 每个操作负责搬运一小部分元素
- 搬完最后一个元素再把老数组删掉.
- 这个期间, 插入只往新数组加.
- 这个期间, 查找需要同时查新数组和老数组
在JDK1.8中的BugConcurrentHashMap里面也有死循环
面试题
- Hashtable 跟HashMap有那些不一样
- Hashtable 是线程安全的,HashMap是线程不安全的
- Hashtable 是不允许键或值为 null 的,HashMap 的键值则都可以为 null,这是因为Hashtable在我们put 空值的时候会直接抛空指针异常,Hashtable使用的是安全失败机制(fail-safe),这种机制会使你此次读到的数据不一定是最新的数据,如果你使用null值,就会使得其无法判断对应的key是不存在还是为空,因为你无法再调用一次contain(key)来对key是否存在进行判断,但是HashMap却做了特殊处理.
- 实现方式不同: Hashtable 继承了 Dictionary类,而 HashMap 继承的是 AbstractMap 类
- 初始化容量不同: HashMap 的初始容量为:16,Hashtable 初始容量为:11,两者的负载因子默认都是:0.75.
- 扩容机制不同:当现有容量大于总容量 * 负载因子时,HashMap 扩容规则为当前容量翻倍,Hashtable 扩容规则为当前容量翻倍 + 1。
- 迭代器不同:HashMap 中的 Iterator 迭代器是 fail-fast 的,而 Hashtable 的 Enumerator 不是 fail-fast 的.所以,当其他线程改变了HashMap 的结构,如:增加,删除元素,将会抛出ConcurrentModificationException 异常,而 Hashtable 则不会.
- **快速失败(fail—fast)**是java集合中的一种机制,,在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception。
- 介绍下 ConcurrentHashMap的锁分段技术 ?
这个是 Java1.7 中采取的技术. Java1.8 中已经不再使用了. 简单的说就是把若干个哈希桶分成一个"段" (Segment), 针对每个段分别加锁.
目的也是为了降低锁竞争的概率. 当两个线程访问的数据恰好在同一个段上的时候, 才触发锁竞争.
- ConcurrentHashMap在jdk1.8做了哪些优化?
- 取消了分段锁, 直接给每个哈希桶(每个链表)分配了一个锁(就是以每个链表的头结点对象作为锁对象)
- 将原来 数组 + 链表 的实现方式改进成 数组 + 链表 / 红黑树 的方式. 当链表较长的时候(大于等于8 个元素)就转换成红黑树.
- Hashtable和HashMap、ConcurrentHashMap 之间的区别?
- HashMap: 线程不安全. key 允许为 null
- Hashtable: 线程安全. 使用 synchronized 锁 Hashtable 对象, 效率较低. key 不允许为 null ,使用的是一把大锁,锁冲突率很高,
- ConcurrentHashMap: 线程安全. 使用 synchronized 锁每个链表头结点, 锁冲突概率低, 充分利用CAS 机制. 优化了扩容方式. key 不允许为 null
死锁
什么是死锁
死锁是指两个及两个以上的线程被无限的阻塞,这些线程在相互等待所需资源.若无外力作用,它们无法获取到资源.
代码示例:
两线程两把锁:现有线程t1和线程t2,锁A和锁B.
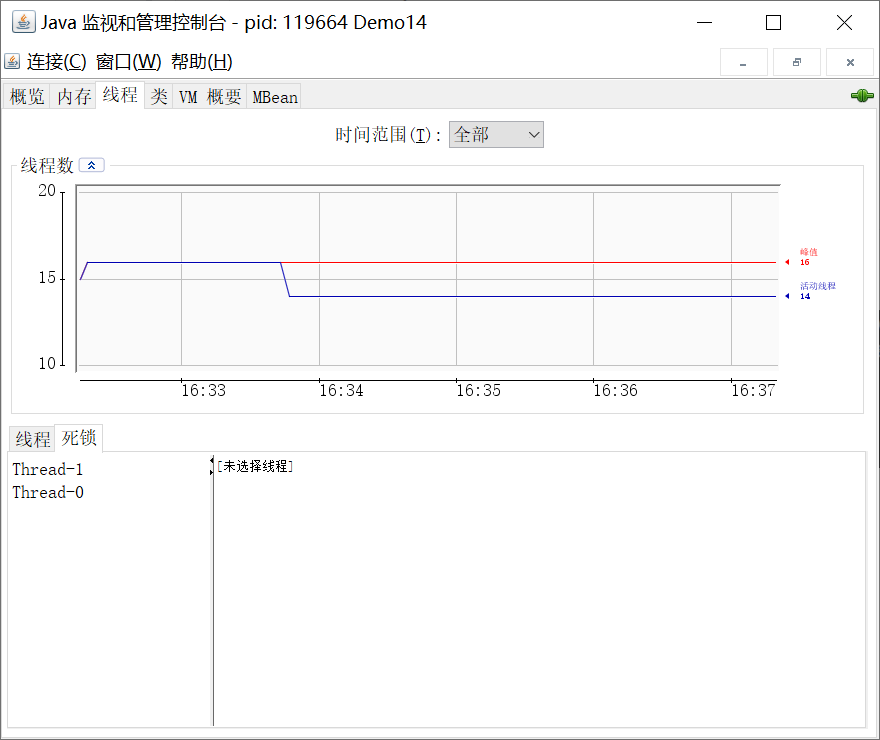
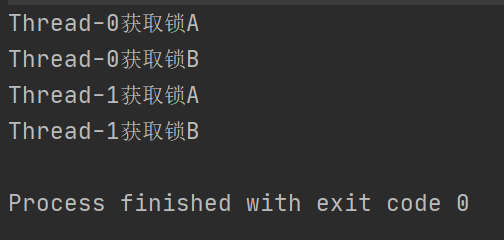
public class Demo14 { // 锁A private static final Object lock_A = new Object(); // 锁B private static final Object lock_B = new Object(); // 先拿锁A, 后拿锁B private static void method1() throws InterruptedException { synchronized (lock_A) { System.out.println(Thread.currentThread().getName() + "获取锁A"); Thread.sleep(1000); synchronized (lock_B) { System.out.println(Thread.currentThread().getName() + "获取锁B"); } } } // 先拿锁B, 后拿锁A private static void method2() throws InterruptedException { synchronized (lock_B) { System.out.println(Thread.currentThread().getName() + "获取锁B"); Thread.sleep(1000); synchronized (lock_A) { System.out.println(Thread.currentThread().getName() + "获取锁A"); } } } public static void main(String[] args) { Thread t1 = new Thread(new Runnable() { @Override public void run() { try { method1(); } catch (InterruptedException e) { e.printStackTrace(); } } }); Thread t2 = new Thread(new Runnable() { @Override public void run() { try { method2(); } catch (InterruptedException e) { e.printStackTrace(); } } }); t1.start(); t2.start(); } }输出结果中没有输出 Process finished with exit code 0,说明线程没有结束
利用jconsole观察死锁
可见产生了死锁
那产生的原因:
- 线程t1获取到锁A
- 线程t2获取到锁B
- 线程t1尝试获取锁B
- 线程t2尝试获取锁A
在最后两步t1,t2线程尝试获取锁A,B,而因为获取资源而陷入无限循环.

哲学家就餐问题 :对于N个线程,M把锁场景(N >= 2, M >= 2, N >= M)

死锁产生的必要条件
- 互斥使用: 在一段时间内某个资源只能由一个线程独占,如果有其他线程申请使用,就会陷入等待,直到该线程释放资源
- 不可抢占: 资源请求者不能向资源占有者抢夺资源,只能由资源占有者主动释放后,才能获得
- 请求和保持: 指线程已经拥有至少一个资源,但又提出了新的资源请求,而该资源已被其它线程占有,此时请求线程被阻塞,但又对自己已获得的资源保持不会释放。
- 循环等待: 即存在一个等待队列, 存在线程{t1, t2, t3,},t1等待t2的锁释放,t2等待t3的锁释放,t3等待t1的锁释放,最终-形成资源的环形链,
满足上述4个必要条件之一,就会产生死锁,那么我们只需要打破这些条件就可以解开死锁
- 破坏互斥作用: 无法破坏,因为锁之间本来就是互斥的
- 破坏不可抢占: 如果资源请求者在请求其他资源时,如果申请失败,就释放自己的资源
- 破坏请求和保持: 一开始就申请好所需资源
- 破坏循环等待: 对多把锁进行编号,并且约定在使用锁时,按照从小到大的顺序来获取.
避免死锁常见的算法有有序资源分配法、银行家算法。
解决方案:
按照锁顺序来获取锁
// 先拿锁A, 后拿锁B private static void method1() throws InterruptedException { synchronized (lock_A) { System.out.println(Thread.currentThread().getName() + "获取锁A"); Thread.sleep(1000); synchronized (lock_B) { System.out.println(Thread.currentThread().getName() + "获取锁B"); } } } // 先拿锁A, 后拿锁B private static void method2() throws InterruptedException { synchronized (lock_A) { System.out.println(Thread.currentThread().getName() + "获取锁A"); Thread.sleep(1000); synchronized (lock_B) { System.out.println(Thread.currentThread().getName() + "获取锁B"); } } }
活锁
两个线程在尝试拿锁的机制中,发生多个线程之间互相谦让,不断发生同一个线程总是拿到同一把锁,在尝试拿另一把锁时因为拿不到,而将本来已经持有的锁释放的过程。
解决办法:每个线程休眠随机数,错开拿锁的时间.
面试题
- 谈谈 volatile关键字的用法?
volatile 能够保证内存可见性. 当从主内存中读取数据. 此时如果有其他线程修改被 volatile 修饰的变量, 可以第一时间读取到最新的值
- Java多线程是如何实现数据共享的?
JVM 把内存分成了这几个区域: 方法区, 堆区, 栈区, 程序计数器 ;其中堆区这个内存区域是多个线程之间共享的 ,所以只要把某个数据放到堆内存中, 就可以让多个线程都能访问到
- Java创建线程池的接口是什么?参数 LinkedBlockingQueue 的作用是什么?
创建线程池主要有两种方式:
- 通过 Executors 工厂类创建. 创建方式比较简单, 但是定制能力有限.
- 通过 ThreadPoolExecutor 创建. 创建方式比较复杂, 但是定制能力强
LinkedBlockingQueue 表示线程池的任务队列. 用户通过 submit / execute 向这个任务队列中添加任务, 再由线程池中的工作线程来执行任务
- Java线程共有几种状态?状态之间怎么切换的?
- NEW: 安排了工作, 还未开始行动. 新创建的线程, 还没有调用 start 方法时处在这个状态.
- RUNNABLE: 可工作的. 又可以分成正在工作中和即将开始工作. 调用 start 方法之后, 并正在CPU 上运行/在即将准备运行 的状态.
- BLOCKED: 使用 synchronized 的时候, 如果锁被其他线程占用, 就会阻塞等待, 从而进入该状态.
- WAITING: 调用 wait 方法会进入该状态.
- TIMED_WAITING: 调用 sleep 方法或者 wait(超时时间) 会进入该状态.
- TERMINATED: 工作完成了. 当线程 run 方法执行完毕后, 会处于这个状态.
- 在多线程下,如果对一个数进行叠加,该怎么做?
- 使用 synchronized / ReentrantLock 加锁
- 使用 AtomInteger 原子操作
- Servlet是否是线程安全的?
如果在 Servlet 中创建了某个成员变量, 此时如果有多个请求到达服务器, 服务器就会多线程进行操作, 是可能出现线程不安全的情况的.
- Thread和Runnable的区别和联系?
Thread 类描述了一个线程.
Runnable 描述了一个任务.
在创建线程的时候需要指定线程完成的任务, 可以直接重写 Thread 的 run 方法, 也可以使用 Runnable 来描述这个任务
- 多次start一个线程会怎么样
第一次调用 start 可以成功调用. 后续再调用 start 会抛出 java.lang.IllegalThreadStateException 异常
- 有synchronized两个方法,两个线程分别同时用这个方法,请问会发生什么?
synchronized 加在非静态方法上, 相当于针对当前对象加锁
- 如果这两个方法属于同一个实例:
- 线程1 能够获取到锁, 并执行方法. 线程2 会阻塞等待, 直到线程1 执行完毕, 释放锁, 线程2 获取到锁之后才能执行方法内容
- 如果这两个方法属于不同实例:
- 两者能并发执行, 互不干扰
- 进程和线程的区别?
- 进程是包含线程的. 每个进程至少有一个线程存在,即主线程。
- 进程和进程之间不共享内存空间. 同一个进程的线程之间共享同一个内存空间.
- 进程是系统分配资源的最小单位,线程是系统调度的最小单位
Queue 表示线程池的任务队列. 用户通过 submit / execute 向这个任务队列中添加任务, 再由线程池中的工作线程来执行任务
- Java线程共有几种状态?状态之间怎么切换的?
- NEW: 安排了工作, 还未开始行动. 新创建的线程, 还没有调用 start 方法时处在这个状态.
- RUNNABLE: 可工作的. 又可以分成正在工作中和即将开始工作. 调用 start 方法之后, 并正在CPU 上运行/在即将准备运行 的状态.
- BLOCKED: 使用 synchronized 的时候, 如果锁被其他线程占用, 就会阻塞等待, 从而进入该状态.
- WAITING: 调用 wait 方法会进入该状态.
- TIMED_WAITING: 调用 sleep 方法或者 wait(超时时间) 会进入该状态.
- TERMINATED: 工作完成了. 当线程 run 方法执行完毕后, 会处于这个状态.
- 在多线程下,如果对一个数进行叠加,该怎么做?
- 使用 synchronized / ReentrantLock 加锁
- 使用 AtomInteger 原子操作
- Servlet是否是线程安全的?
如果在 Servlet 中创建了某个成员变量, 此时如果有多个请求到达服务器, 服务器就会多线程进行操作, 是可能出现线程不安全的情况的.
- Thread和Runnable的区别和联系?
Thread 类描述了一个线程.
Runnable 描述了一个任务.
在创建线程的时候需要指定线程完成的任务, 可以直接重写 Thread 的 run 方法, 也可以使用 Runnable 来描述这个任务
- 多次start一个线程会怎么样
第一次调用 start 可以成功调用. 后续再调用 start 会抛出 java.lang.IllegalThreadStateException 异常
- 有synchronized两个方法,两个线程分别同时用这个方法,请问会发生什么?
synchronized 加在非静态方法上, 相当于针对当前对象加锁
- 如果这两个方法属于同一个实例:
- 线程1 能够获取到锁, 并执行方法. 线程2 会阻塞等待, 直到线程1 执行完毕, 释放锁, 线程2 获取到锁之后才能执行方法内容
- 如果这两个方法属于不同实例:
- 两者能并发执行, 互不干扰
- 进程和线程的区别?
- 进程是包含线程的. 每个进程至少有一个线程存在,即主线程。
- 进程和进程之间不共享内存空间. 同一个进程的线程之间共享同一个内存空间.
- 进程是系统分配资源的最小单位,线程是系统调度的最小单位
















 476
476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











