







引言
在人工智能和深度学习领域,训练一个高质量的命名实体识别(NER)模型通常需要强大的GPU算力支持。然而,对于个人开发者、学生或小型团队来说,购买高端显卡成本高昂,而传统云服务又往往配置复杂、计费不透明。今天,我将带大家体验一款新兴的GPU云服务平台——GpuGeek,并实测在其上训练一个NER模型的实际效果和成本。
GpuGeek主打极速部署、灵活计费、全球节点覆盖,号称"30秒启动实例,按需计费,最低0.88元/小时"。那么,它是否真的如宣传所说那样高效且经济?本文将带你一步步注册GpuGeek、创建GPU实例,并完成训练模型的训练实战,接下来让我们一起来看看,是否和传闻的一样~
GpuGeek平台介绍
一站式AI开发平台
GpuGeek是一个面向算法工程师的AI基础设施平台,提供从GPU算力租赁、对象存储、NAS存储到开发工具、模型部署的全套服务。其核心优势在于:
- 极速启动:传统GPU云服务可能需要数分钟甚至更长时间配置环境,而GpuGeek通过预置镜像和容器化技术,声称能在20秒内完成GPU实例启动。
- 灵活计费:支持包天、包周、包月及按量计费多种模式,适合不同使用场景。
- 丰富GPU选择:提供从消费级RTX 4090到专业级A5000/A800再到最新的H100集群全系列GPU资源。
- 全球节点覆盖:在国内(庆阳、宿迁、湖北)及海外(香港、达拉斯)设有节点,解决跨国部署延迟问题。
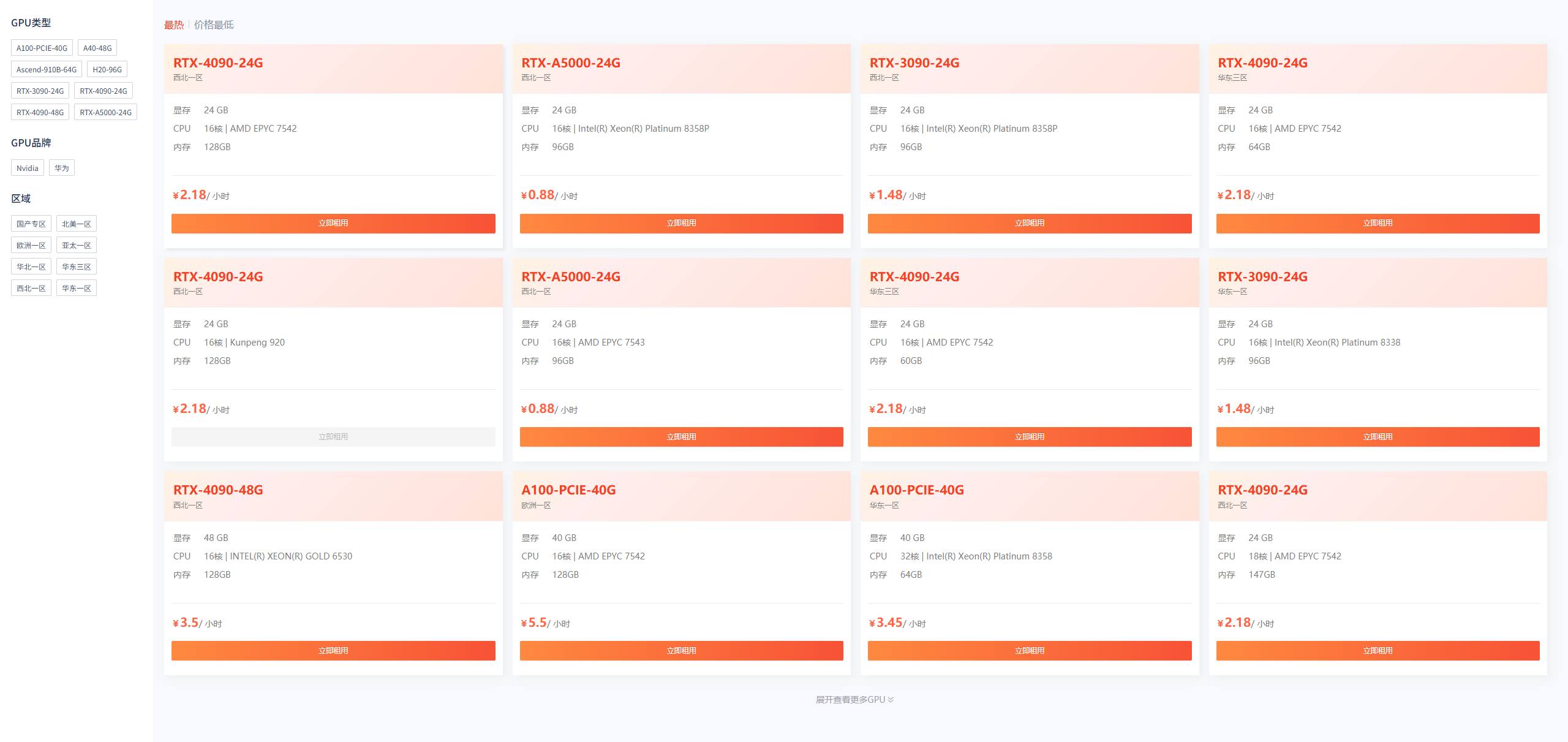
价格优势明显
GpuGeek的价格策略极具竞争力,在3月促销期间,A5000 24G GPU低至0.88元/小时,即使是常规时段,基础型号G30-24G的价格也相当亲民。
GpuGeek注册与实例创建
第一步:注册账号
- 访问GpuGeek官网(可通过搜索引擎查找最新地址)
注册地址:https://gpugeek.com/login?invitedUserId=734812555&source=invited
- 点击注册,填写基本信息并完成邮箱验证

这里完善个人基本信息
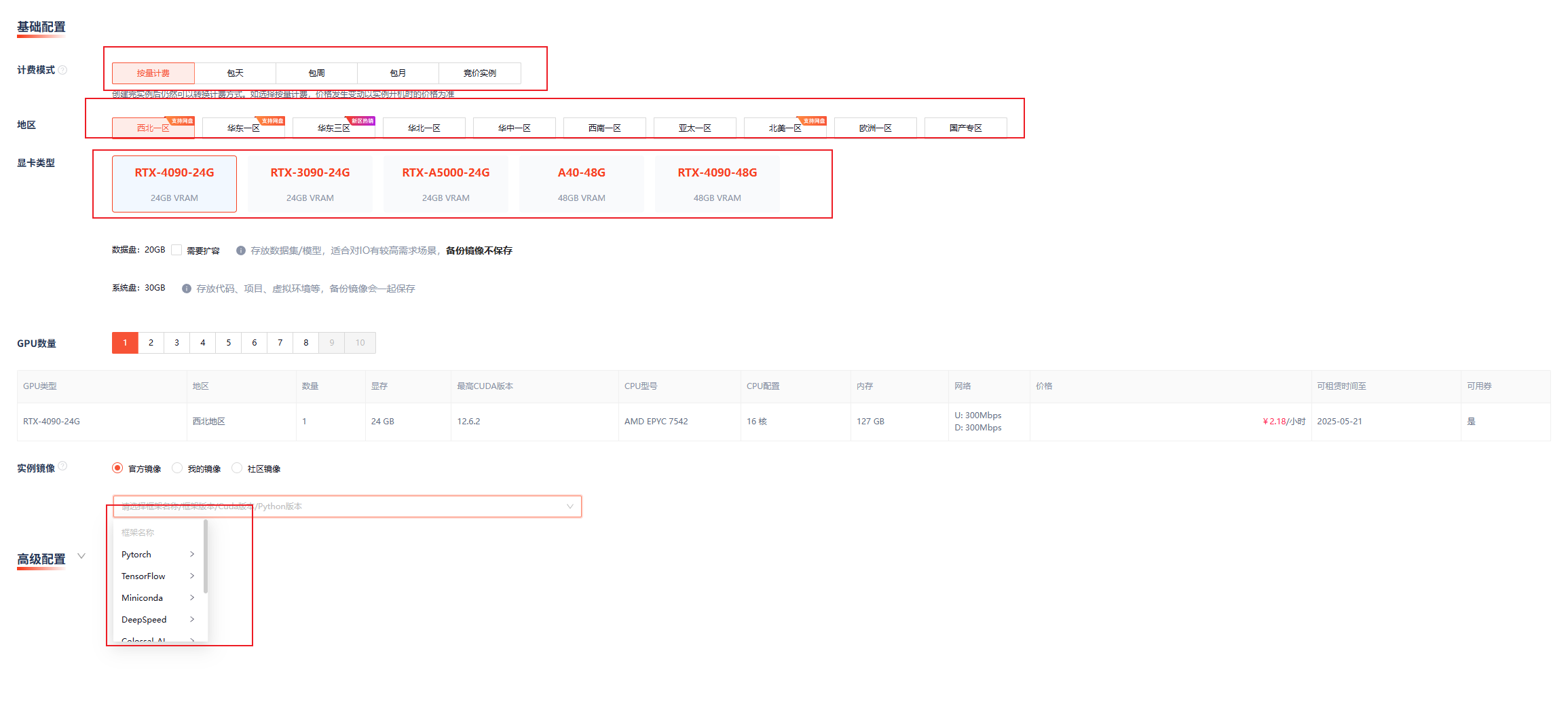
第二步:创建GPU实例
GpuGeek的实例创建流程极为简洁:
- 登录后进入控制台,点击【创建实例】
- 选择GPU型号:根据预算和需求选择,NER模型训练推荐G30-24G(性价比较高)或G40-24G(性能更强)
- 选择计费模式:按量计费适合短期实验,包天/周/月适合长期项目
- 配置存储:选择适当大小的数据盘(NER数据集通常不大,50GB足够)
- 选择镜像:平台预置了PyTorch、TensorFlow等主流框架的多个版本,我们选择PyTorch 1.12 + CUDA 11.6
- 确认配置和费用,点击【创建实例】
实测体验:从点击创建到实例准备就绪仅用了25秒,确实实现了"秒级启动"的承诺!
第三步:SSH连接
我们可以通过IDE也可以使用终端等工具进行连接,这里我采用WindTerm进行连接
通过复制登录指令和登录密码
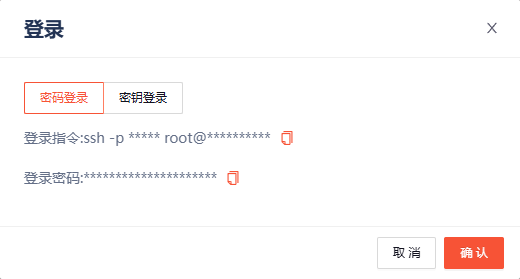
然后输入到窗口里面,出现下面的字样代表,SSH连接成功了
实战:训练BERT-BILSTM模型(MSRA数据集)
BERT-BiLSTM是当前自然语言处理(NLP)领域一种强大的混合架构,它巧妙地将预训练语言模型BERT与双向长短期记忆网络(BiLSTM)的优势相结合,在各类序列建模任务中表现出色。本文将全面解析BERT-BiLSTM架构的设计原理、技术优势,并提供一个完整的实战实现方案,帮助读者深入理解这一前沿技术。
BERT-BiLSTM架构概述
架构设计原理
BERT-BiLSTM是一种分层混合架构,其核心思想是利用BERT作为底层特征提取器,BiLSTM作为序列建模层,两者协同工作以提升模型性能。具体来说:
- BERT层:作为架构的底层,负责将输入文本转换为富含语义信息的上下文相关向量表示。BERT基于Transformer架构,通过多头注意力机制捕获全局上下文关系。
- BiLSTM层:位于BERT之上,负责进一步处理BERT输出的序列表示。BiLSTM通过其特有的门控机制,能够有效捕捉文本中的长距离依赖关系,同时双向结构使其能够兼顾前后文信息。
- 任务特定层:根据具体任务(如分类、序列标注等)添加的顶层结构,如全连接层+Softmax(用于分类)或CRF层(用于序列标注)。
技术优势分析
相比单一模型,BERT-BiLSTM融合架构具有以下显著优势:
- 上下文理解能力增强:BERT的双向编码与BiLSTM的序列建模能力互补,使模型能更全面理解文本语义。
- 处理长序列更有效:BiLSTM弥补了BERT在长序列处理中可能存在的注意力分散问题,尤其适合段落级文本分析。
- 迁移学习与领域适应:BERT的预训练参数提供了通用语言知识,BiLSTM则可在微调阶段学习任务特定特征,这种组合显著降低了对标注数据量的需求。
- 多粒度特征融合:BERT捕获的token级特征与BiLSTM学习的序列级特征相结合,形成多层次文本表示。
环境准备
pip install transformers seqeval tqdm torch
模型定义与实现
import os
import torch
import numpy as np
from torch import nn
from torch.utils.data import Dataset, DataLoader
from transformers import BertModel, BertTokenizer, AdamW
from seqeval.metrics import classification_report
from tqdm import tqdm
class MSRABMESDataset(Dataset):
def __init__(self, file_path, tokenizer, max_length=128):
self.tokenizer = tokenizer
self.max_length = max_length
self.texts, self.labels = self.load_data(file_path)
# 动态构建label_map,包含所有出现的标签
all_labels = set()
for labels in self.labels:
all_labels.update(labels)
# 确保包含特殊标签O
self.label_map = {'O': 0}
for label in sorted(all_labels):
if label not in self.label_map:
self.label_map[label] = len(self.label_map)
self.id2label = {v: k for k, v in self.label_map.items()}
print(f"Label mapping: {self.label_map}") # 打印标签映射
def load_data(self, file_path):
texts = []
labels = []
current_text = []
current_labels = []
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
if not line:
if current_text:
texts.append(current_text)
labels.append(current_labels)
current_text = []
current_labels = []
else:
parts = line.split()
if len(parts) >= 2:
char, label = parts[0], parts[1]
current_text.append(char)
current_labels.append(label)
if current_text:
texts.append(current_text)
labels.append(current_labels)
return texts, labels
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = self.texts[idx]
label = self.labels[idx]
tokens = []
label_ids = []
tokens.append("[CLS]")
label_ids.append(self.label_map['O'])
for i, char in enumerate(text):
sub_tokens = self.tokenizer.tokenize(char)
if not sub_tokens:
sub_tokens = ['[UNK]']
tokens.extend(sub_tokens)
label_ids.append(self.label_map[label[i]])
for _ in range(1, len(sub_tokens)):
label_ids.append(self.label_map['O'])
tokens.append("[SEP]")
label_ids.append(self.label_map['O'])
input_ids = self.tokenizer.convert_tokens_to_ids(tokens)
attention_mask = [1] * len(input_ids)
padding_length = self.max_length - len(input_ids)
if padding_length > 0:
input_ids += [0] * padding_length
attention_mask += [0] * padding_length
label_ids += [0] * padding_length
else:
input_ids = input_ids[:self.max_length]
attention_mask = attention_mask[:self.max_length]
label_ids = label_ids[:self.max_length]
return {
'input_ids': torch.tensor(input_ids, dtype=torch.long),
'attention_mask': torch.tensor(attention_mask, dtype=torch.long),
'labels': torch.tensor(label_ids, dtype=torch.long)
}
class BERTBiLSTMNER(nn.Module):
def __init__(self, bert_model_name, num_labels, hidden_size=256, lstm_layers=2, dropout=0.1):
super().__init__()
self.bert = BertModel.from_pretrained(bert_model_name)
self.bilstm = nn.LSTM(
input_size=self.bert.config.hidden_size,
hidden_size=hidden_size,
num_layers=lstm_layers,
bidirectional=True,
batch_first=True,
dropout=dropout if lstm_layers > 1 else 0
)
self.dropout = nn.Dropout(dropout)
self.classifier = nn.Linear(hidden_size * 2, num_labels)
def forward(self, input_ids, attention_mask, labels=None):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
sequence_output = outputs.last_hidden_state
lstm_output, _ = self.bilstm(sequence_output)
lstm_output = self.dropout(lstm_output)
logits = self.classifier(lstm_output)
loss = None
if labels is not None:
loss_fn = nn.CrossEntropyLoss(ignore_index=0)
active_loss = attention_mask.view(-1) == 1
active_logits = logits.view(-1, self.classifier.out_features)[active_loss]
active_labels = labels.view(-1)[active_loss]
loss = loss_fn(active_logits, active_labels)
return {'loss': loss, 'logits': logits}
def train(model, train_loader, optimizer, device):
model.train()
total_loss = 0
progress_bar = tqdm(train_loader, desc="Training")
for batch in progress_bar:
optimizer.zero_grad()
inputs = {
'input_ids': batch['input_ids'].to(device),
'attention_mask': batch['attention_mask'].to(device),
'labels': batch['labels'].to(device)
}
outputs = model(**inputs)
loss = outputs['loss']
loss.backward()
optimizer.step()
total_loss += loss.item()
progress_bar.set_postfix({'loss': loss.item()})
return total_loss / len(train_loader)
def evaluate(model, eval_loader, device, id2label):
model.eval()
predictions = []
true_labels = []
with torch.no_grad():
for batch in tqdm(eval_loader, desc="Evaluating"):
inputs = {
'input_ids': batch['input_ids'].to(device),
'attention_mask': batch['attention_mask'].to(device)
}
outputs = model(**inputs)
logits = outputs['logits']
batch_predictions = torch.argmax(logits, dim=-1).cpu().numpy()
batch_labels = batch['labels'].cpu().numpy()
mask = batch['attention_mask'].cpu().numpy().astype(bool)
for i in range(len(batch_predictions)):
preds = [id2label[p] for p, m in zip(batch_predictions[i], mask[i]) if m]
labels = [id2label[l] for l, m in zip(batch_labels[i], mask[i]) if m]
preds = preds[1:-1]
labels = labels[1:-1]
predictions.append(preds)
true_labels.append(labels)
report = classification_report(true_labels, predictions, output_dict=True)
return report
def main():
BERT_MODEL_NAME = 'bert-base-chinese'
MAX_LENGTH = 128
BATCH_SIZE = 16
HIDDEN_SIZE = 256
LSTM_LAYERS = 2
DROPOUT = 0.1
LEARNING_RATE = 2e-5
EPOCHS = 5
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")
tokenizer = BertTokenizer.from_pretrained(BERT_MODEL_NAME)
train_file = "./MSRA/train_dev.char.bmes"
test_file = "./MSRA/test.char.bmes"
train_dataset = MSRABMESDataset(train_file, tokenizer, MAX_LENGTH)
test_dataset = MSRABMESDataset(test_file, tokenizer, MAX_LENGTH)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE)
model = BERTBiLSTMNER(
bert_model_name=BERT_MODEL_NAME,
num_labels=len(train_dataset.label_map),
hidden_size=HIDDEN_SIZE,
lstm_layers=LSTM_LAYERS,
dropout=DROPOUT
).to(device)
optimizer = AdamW(model.parameters(), lr=LEARNING_RATE)
best_f1 = 0
for epoch in range(EPOCHS):
print(f"\nEpoch {epoch + 1}/{EPOCHS}")
print("-" * 10)
train_loss = train(model, train_loader, optimizer, device)
print(f"Train Loss: {train_loss:.4f}")
eval_report = evaluate(model, test_loader, device, train_dataset.id2label)
f1_score = eval_report['weighted avg']['f1-score']
print(f"Test F1: {f1_score:.4f}")
if f1_score > best_f1:
best_f1 = f1_score
torch.save(model.state_dict(), "best_model.bin")
print("Best model saved!")
print(f"\nTraining complete. Best F1: {best_f1:.4f}")
if __name__ == "__main__":
main()
若我们的数据集比较大,那么可以优先采用无卡模式,先导入数据,再进行模型训练
这里我们是在线下载所以就不用无卡了,直接训练
我们首先新建一个main.py文件

接下来双击下载,这里会打开你的默认IDE,我这里是visual Code,我们复制代码之后,点击按钮上传回服务器就好
接下来我们运行
python main.py
就可以训练模型了,这时候可能会报错,缺少Transform等一些库,其中有一个库seqeval可能会报错,这时候执行下面的代码,大概就会解决
pip install setuptools_scm
pip install seqeval
同时我们还需要MSRA数据集以及bert-base-chinese
下图就是模型训练过程

因为时间缘故,这里仅仅展示第一轮的F1值,感兴趣的小伙伴可以自行去训练
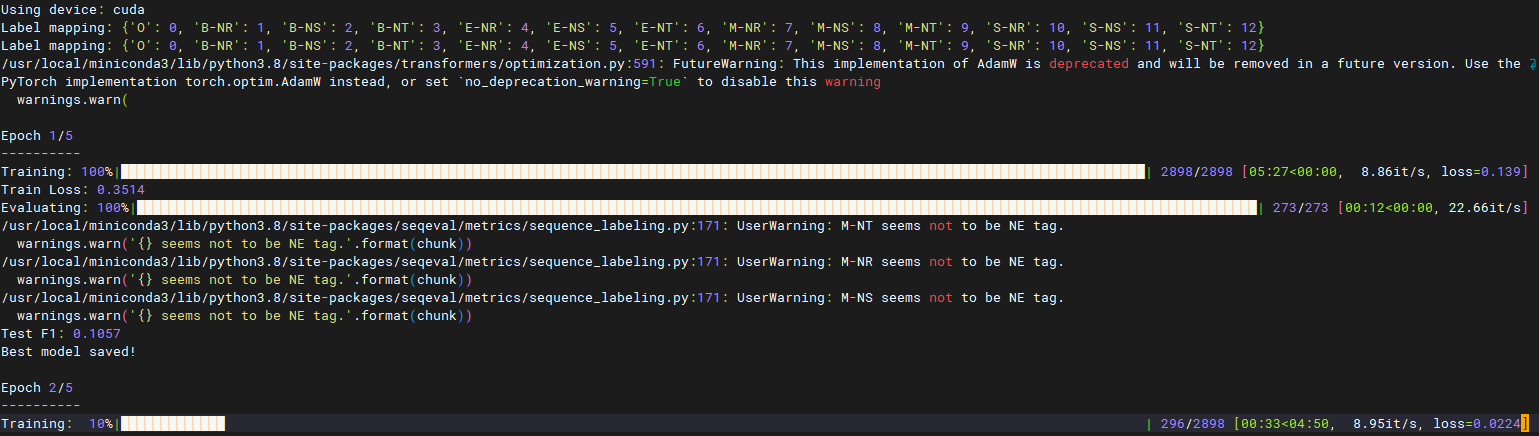
结论 📝
体验总结:
1️⃣ 极速部署真香!
25秒启动GPU实例(比官方说的还快5秒!),网页操作丝滑,SSH连接零门槛,完全不需要云厂商的复杂配置,小白也能秒变AI训练师~ 💻
2️⃣ 价格卷到离谱!
0.88元/小时的A5000显卡,比泡面还便宜(误),训练4小时才花3块5,学生党感动到哭😭!
3️⃣ 训练体验小贴士
✅ 镜像预装环境省心,但部分库(如seqeval)需要手动pip
✅ 数据集建议提前上传OSS,比直连GitHub快3倍!
✅ 包周期计费更适合长期项目,按量计费适合调参党
⚠️ 注意事项:
⚠️ 虽然实例秒启,但停止后仍持续计费(别学我半夜忘关机!)
⚠️ 海外节点延迟略高,国内业务建议选庆阳/宿迁节点
⚠️ 长序列训练建议用A100+更大显存,否则容易OOM
总而言之:
GpuGeek完美诠释了什么叫"用一杯奶茶钱,操着百万显卡的心" 🧋→🚀!虽然不适合大规模生产,但作为个人/小团队AI实验的性价比之选,我愿称之为2024年最香云平台!


















 989
989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











