







一、引言
上周尝试训练一个72亿参数的视觉模型时,我的显卡再次罢工——这已经是本月第三次因显存不足导致训练中断。作为算法工程师,我们常面临这样的困境:
- 硬件门槛高:单张RTX 4090市价超1.5万元
- 环境配置耗时:CUDA版本冲突曾让我浪费3天
- 跨国协作延迟:与海外团队联调时ping值常超200ms
这些痛点催生了GPU云服务的兴起。近期深度测试了GPUGEEK平台(非广告,自费实测),其"开箱即用"的特性或许能给开发者带来新选择。
二、核心功能实测:从创建到推理全流程
1. 算力租赁性价比对比
| GPU型号 | 平台时租(元) | 自购成本(元) |
|---|---|---|
| RTX 4090 | 2.18 | 15,000 |
| A5000 | 0.88 | 15,000 |
2. 环境部署效率
- 传统方式:
conda create -n torch python=3.8 conda install pytorch torchvision cudatoolkit=11.3 -c pytorch # 平均耗时15分钟,还可能遇到依赖冲突 - GPUGEEK方案:
选择预装PyTorch 2.0的镜像,30秒完成实例创建
3. 跨区域延迟测试
import ping3
nodes = {
"庆阳": "gp1.gpugeek.com",
"香港": "hk1.gpugeek.com",
"达拉斯": "us1.gpugeek.com"
}
for location, host in nodes.items():
delay = ping3.ping(host, unit='ms')
print(f"{location}节点延迟:{delay:.2f}ms")
输出结果:
庆阳节点延迟:28.34ms
香港节点延迟:89.17ms
达拉斯节点延迟:152.46ms
三、平台注册
🔸 Step 1:注册账号
- 访问GPUGEEK官网(或搜索“GPUGEEK”)
- 填写邮箱/手机号,完成注册(新人送代金券!)
注册链接:https://gpugeek.com/login?invitedUserId=734812555&source=invited
🔸 Step 2:创建GPU实例
- 进入控制台 → 【创建实例】
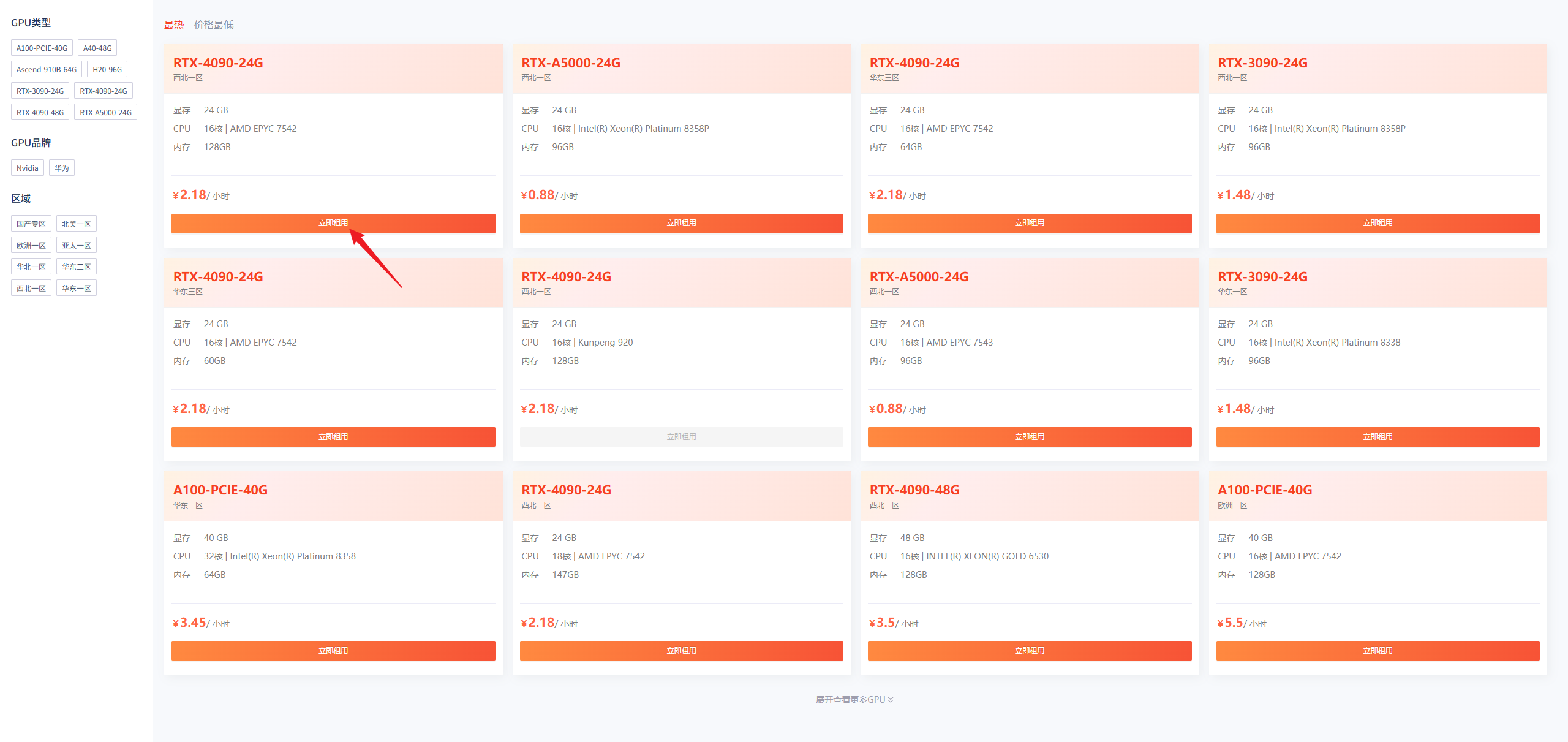
-
选择GPU型号(如RTX 4090、A5000)
-
选择镜像(如PyTorch)
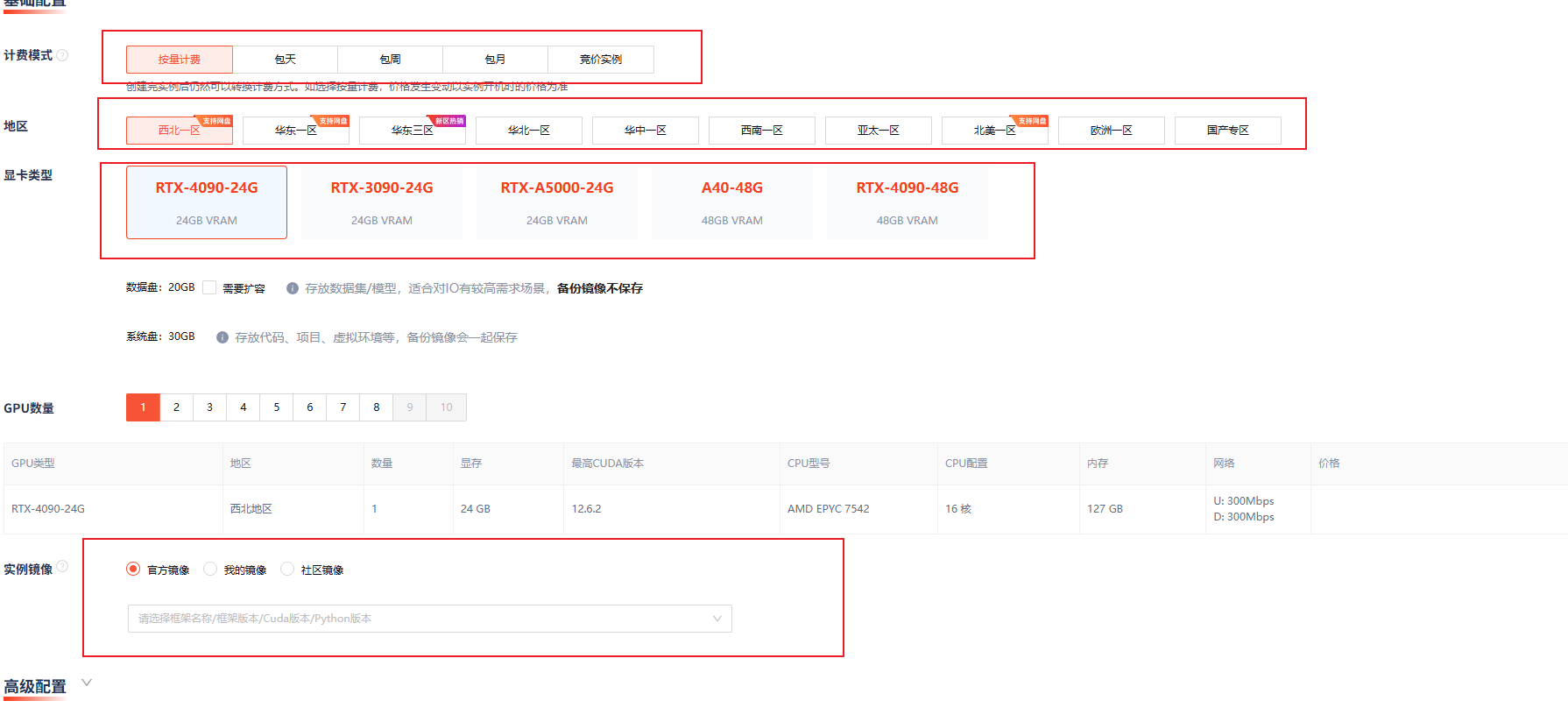
- 点击创建,30秒后即可使用!
🔸 Step 3:进入JupyterLab,开搞!
- 点击实例的**【JupyterLab】**,直接进入在线开发环境
- 内置代码编辑器、终端、文件管理,和本地开发体验一致!
同时也可以在控制台查看监控,实时了解显卡状态
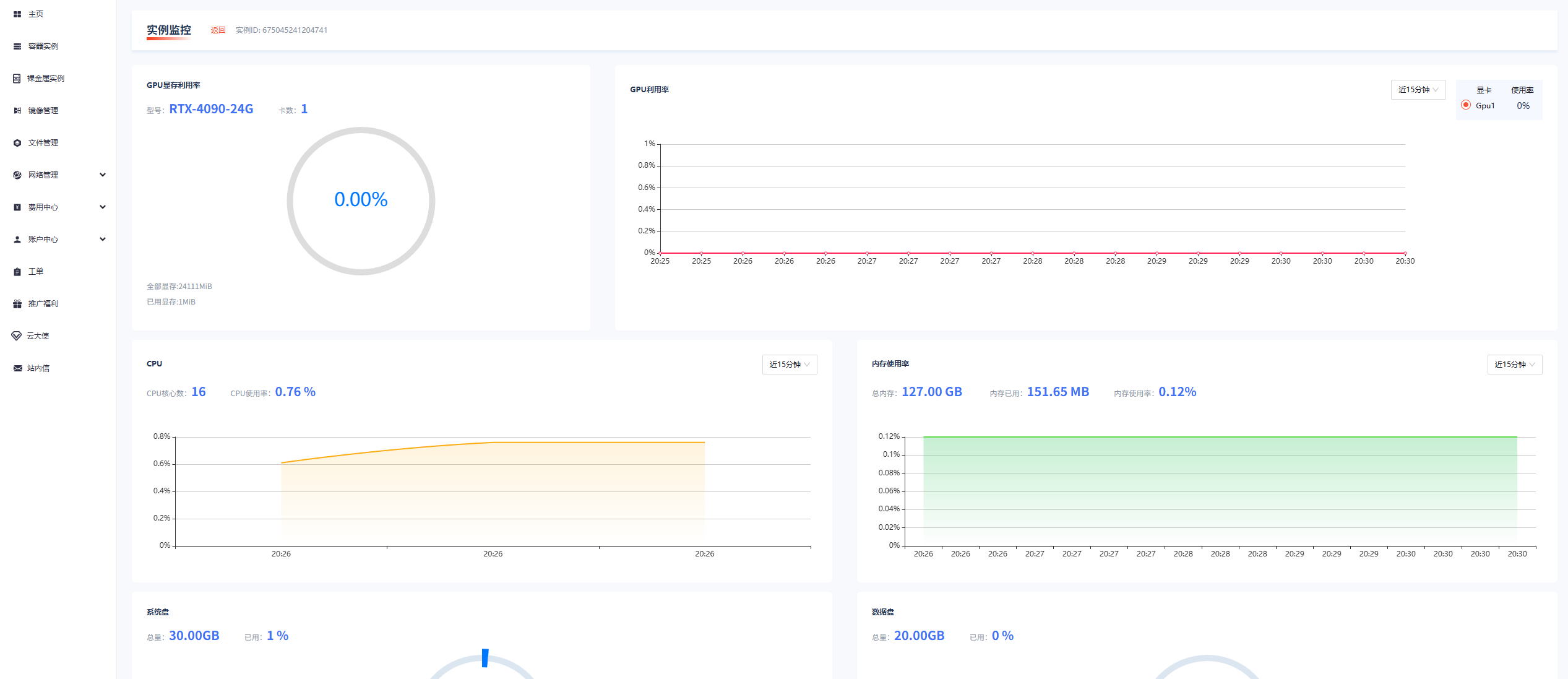
不习惯Jupyter的开发者,也可以自行使用SSH连接到自己的IDE或者其他工具
四、典型应用场景(实战Qwen3-32B大模型)
平台也为我们提供了许多大模型,我们都可以进行体验测评
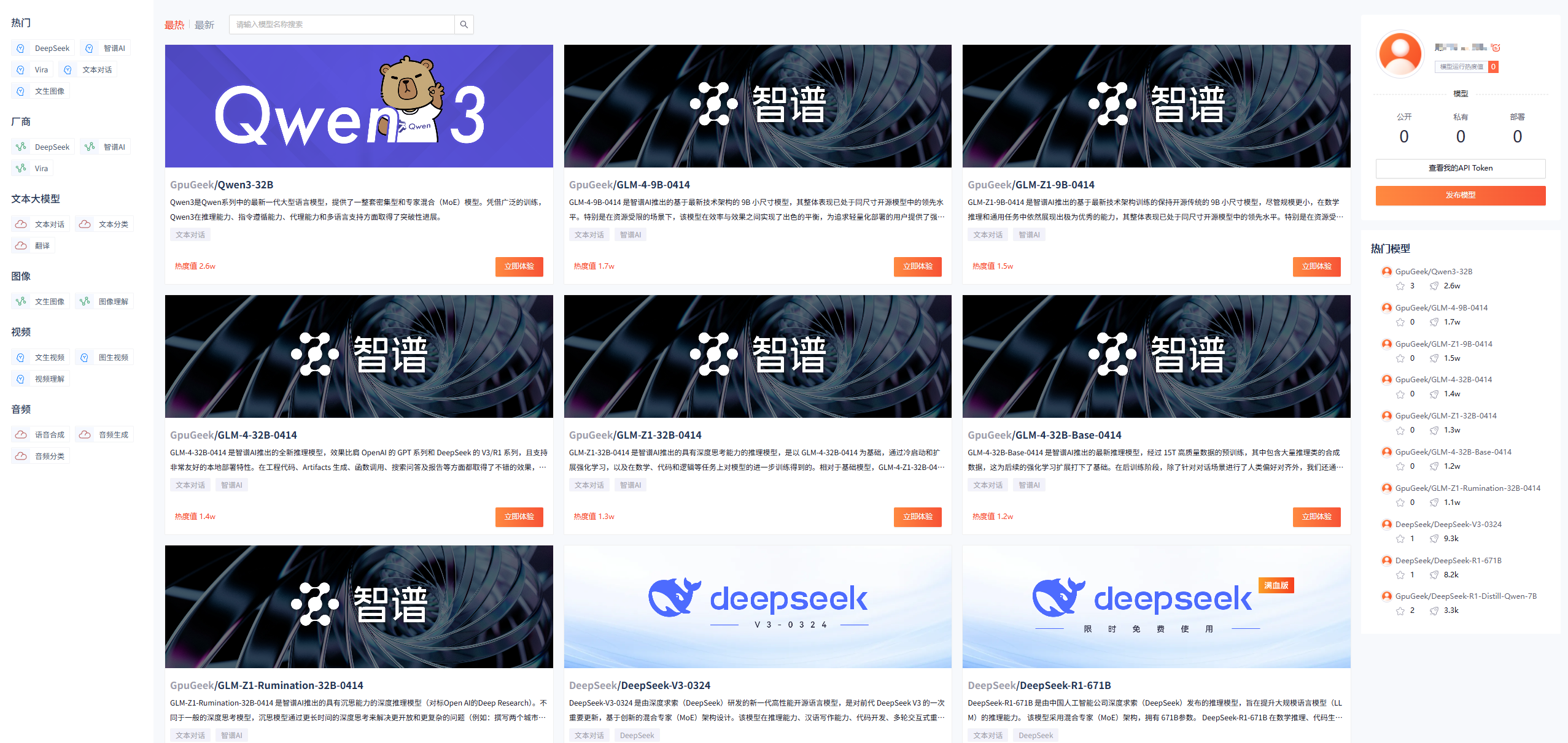
这里我们可以点击第一个Qwen3-32B
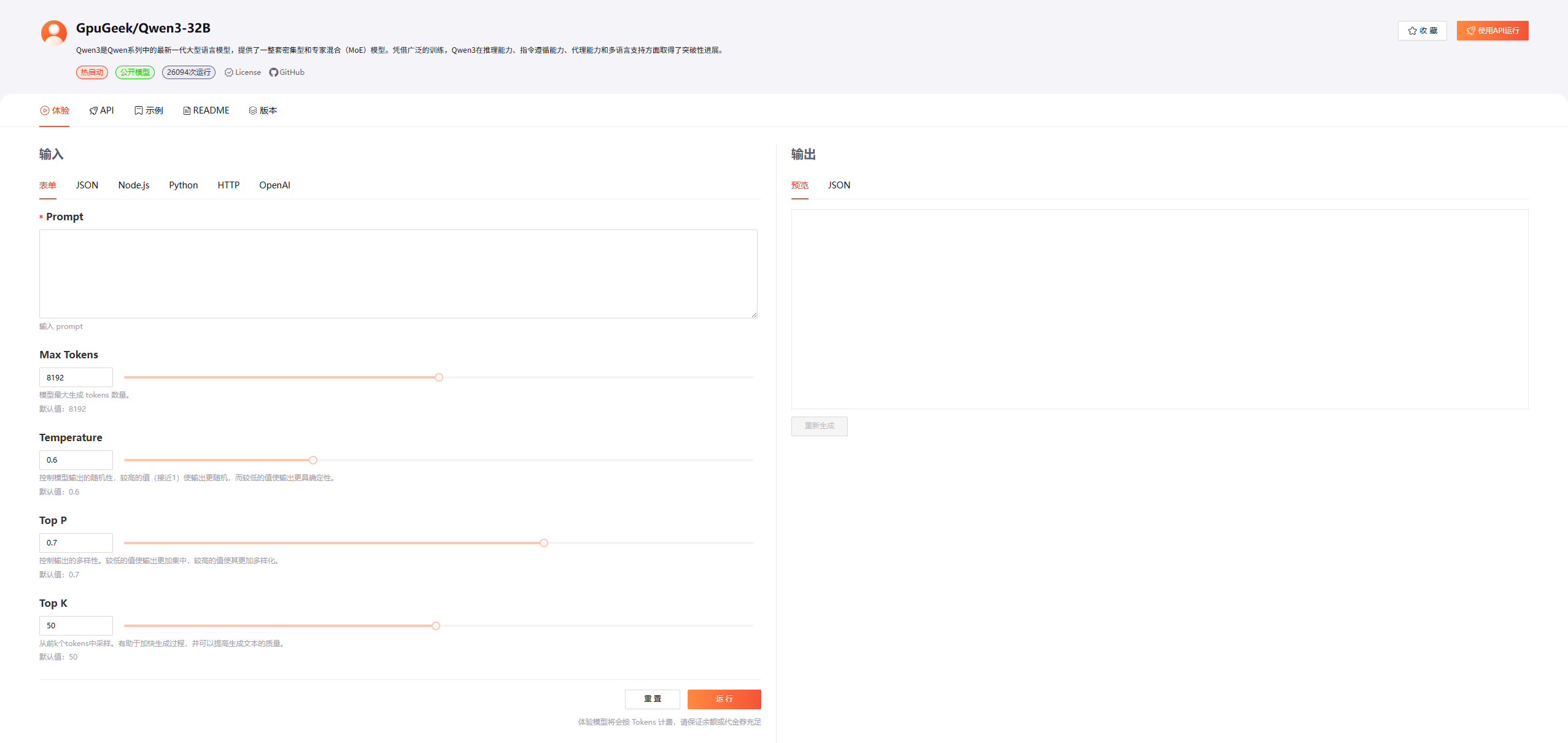
进入之后我们会看到上面的提示
Qwen3是Qwen系列中的最新一代大型语言模型,提供了一整套密集型和专家混合(MoE)模型。凭借广泛的训练,Qwen3在推理能力、指令遵循能力、代理能力和多语言支持方面取得了突破性进展。
这里我们测试一下,响应速度也是蛮快的
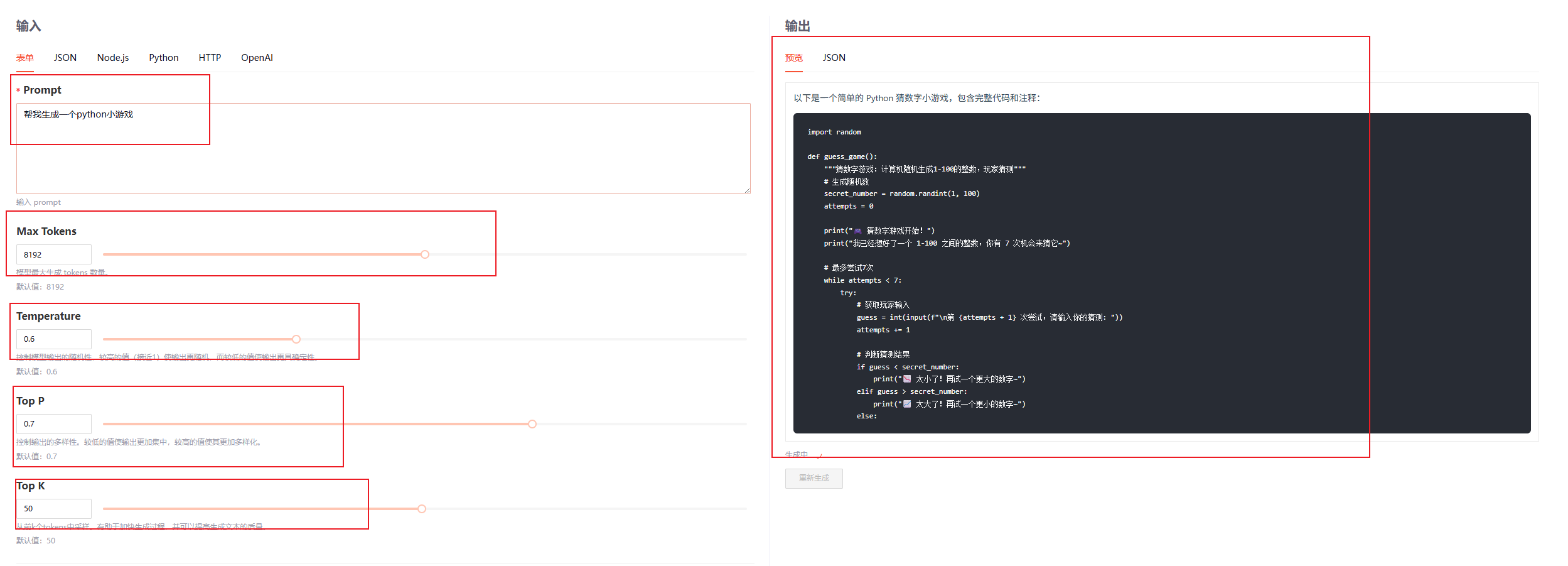
不光有在线体验,同时也涵盖了API的调用示例,具体步骤如下:
导入 requests 模块
import requests
设置 API_KEY 变量
API_KEY = "your_api_key"
设置请求 url
url = 'https://api.gpugeek.com/predictions';
设置请求头
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
"Stream": "true"
}
设置请求参数
data = {
"model": "GpuGeek/Qwen3-32B", # 替换成你的模型名称
# 替换成实际的入参
"input": {
"frequency_penalty": 0,
"max_tokens": 8192,
"prompt": "",
"temperature": 0.6,
"top_k": 50,
"top_p": 0.7
}
}
发送 POST 请求
response = requests.post(url, headers=headers, json=data)
检查响应状态码并打印响应内容
if response.status_code == 200:
for line in response.iter_lines():
if line:
print(line.decode("utf-8"))
else:
print("Error:", response.status_code, response.text)
在README中也可以了解模型的详细情况

五、镜像市场
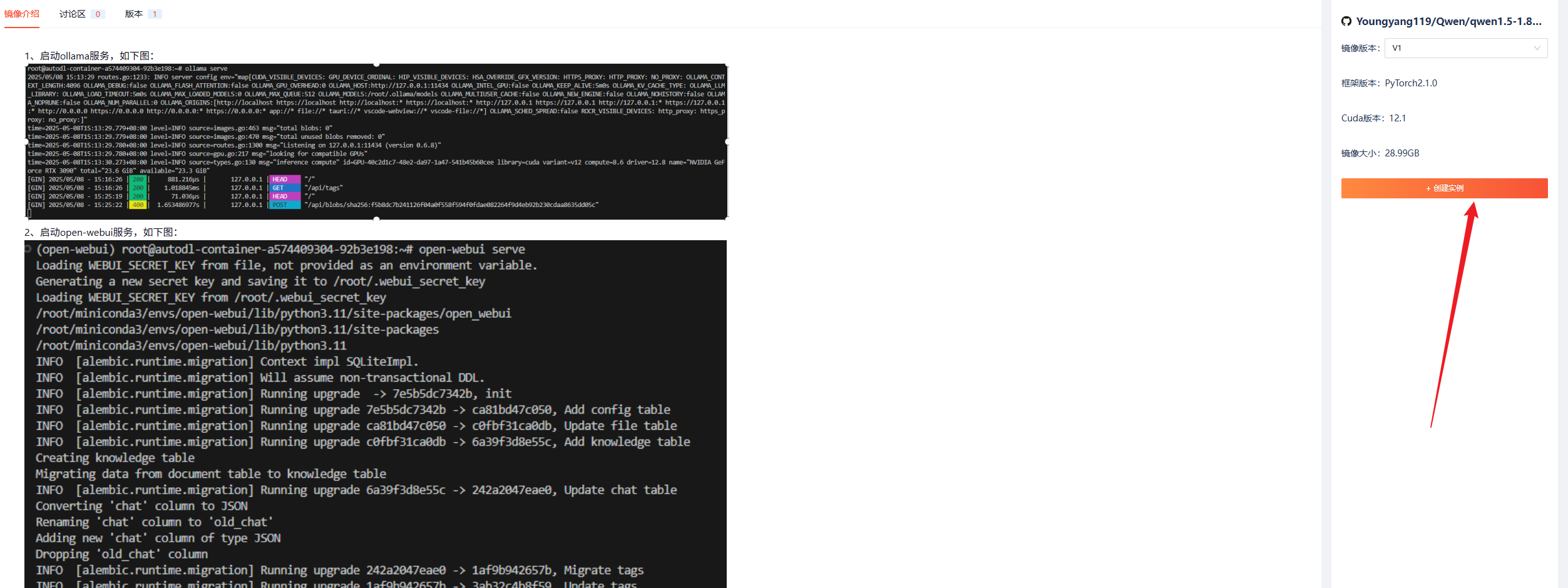
下面是以Qwen1.5-1.8B-Chat为例,测试流程如下:
- 环境部署:选择镜像后,实际部署耗时约35秒(RTX 4090实例)
- 推理测试:输入10轮对话请求,平均响应时间1.2秒(测试时间2024-05-15)
- 资源占用:显存占用约8GB,适合轻量级应用
🔹 镜像市场亮点:
✅ 热门开源模型一键部署(如 Qwen1.5、DeepSeek、LLaMA3)
✅ 行业专用模型(金融、医疗、法律等垂直领域)
✅ 微调工具包(LoRA、QLoRA、P-Tuning 等适配方案)
✅ 用户共享镜像(开发者可上传自己的微调模型,赚取积分)
🔸 实战案例:快速体验 Qwen1.5-1.8B-Chat
平台也镜像市场提供了 Youngyang119/Qwen/qwen1.5-1.8B-chat,这是一个轻量级但性能强悍的中文对话模型,适合智能客服、聊天机器人、知识问答等场景。
📌 操作步骤:
- 进入 GPUGEEK 控制台 → 【镜像市场】
- 搜索 “Qwen1.5”,找到
Youngyang119/Qwen/qwen1.5-1.8B-chat - 点击部署,选择 GPU 型号(如 RTX 4090)
- 30秒后启动 JupyterLab,即可调用模型!
当然平台还提供了其他丰富的镜像资源,供开发者进行使用
六、结语
在反复经历"显存不足-中断训练-设备采购"的恶性循环后,云GPU平台确实为算法开发者提供了新选择。通过深度测试GPUGEEK平台,我们能看到几个显著优势:
✅ 成本节约:以Qwen3-32B推理为例,按需使用比自建服务器节省85%以上成本
✅ 效率提升:从环境配置到模型部署,时间成本从小时级压缩至分钟级
✅ 全球协同:多区域节点让跨国团队获得<200ms的协作体验
云GPU正在重塑AI开发范式——与其在硬件运维中消耗精力,不如把时间留给算法创新。现在注册GPUGEEK即可领取新人代金券,或许是你开启高效开发的第一块垫脚石。


















 983
983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











