







前向传播(Forward)
为什么要有激活函数
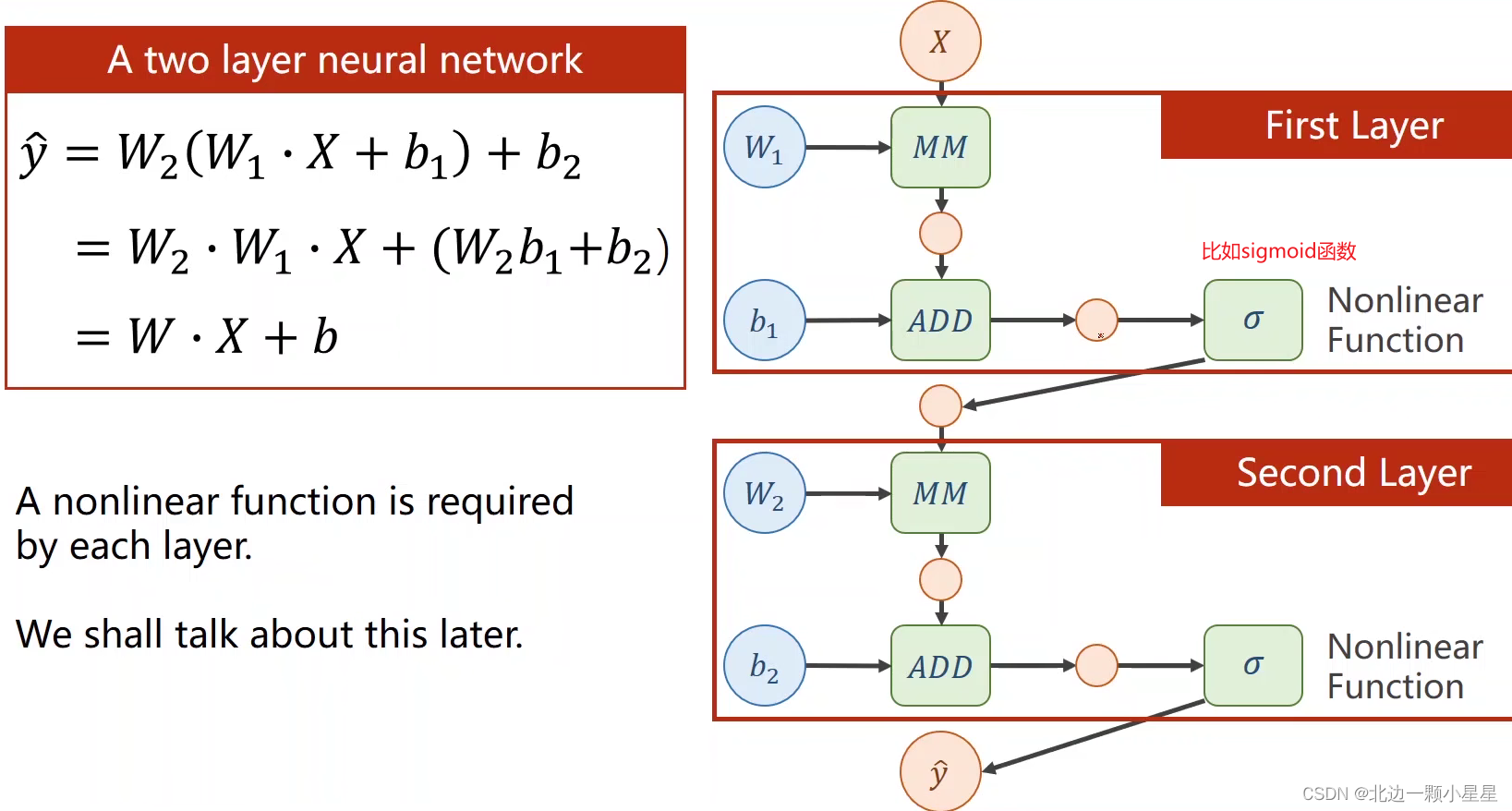
这里用两层来代表多层的神经网络举例:第一层的输出是第二层的输入,其中MM的W*X矩阵乘法,ADD是向量加法即加上偏置,如果每一层都只有线性变换,那么最终无论多少层都可以化简成一层(见上图左边的公式),这样多层数就没有意义了,所以要在每一层都加上非线性函数即激活函数,才能保证每一层都有它独特的作用。
链式法则
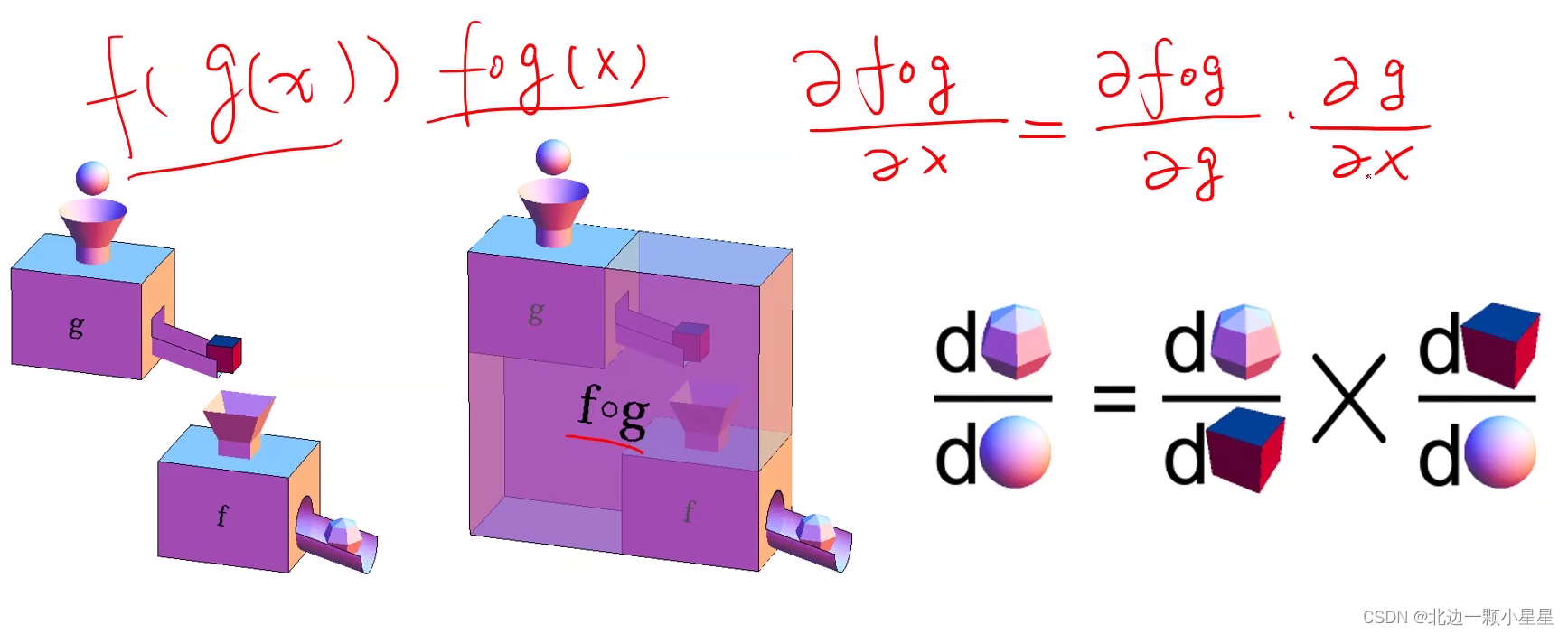

反向传播(Backward)

当x是上一层的输出时也需要算,它这时就相当于是上一层的输出z一样。
损失L对z的偏导是从后面反向传播时传过来的,z对x的偏导是前面做前向传播时计算f这个函数时算出来的局部梯度。
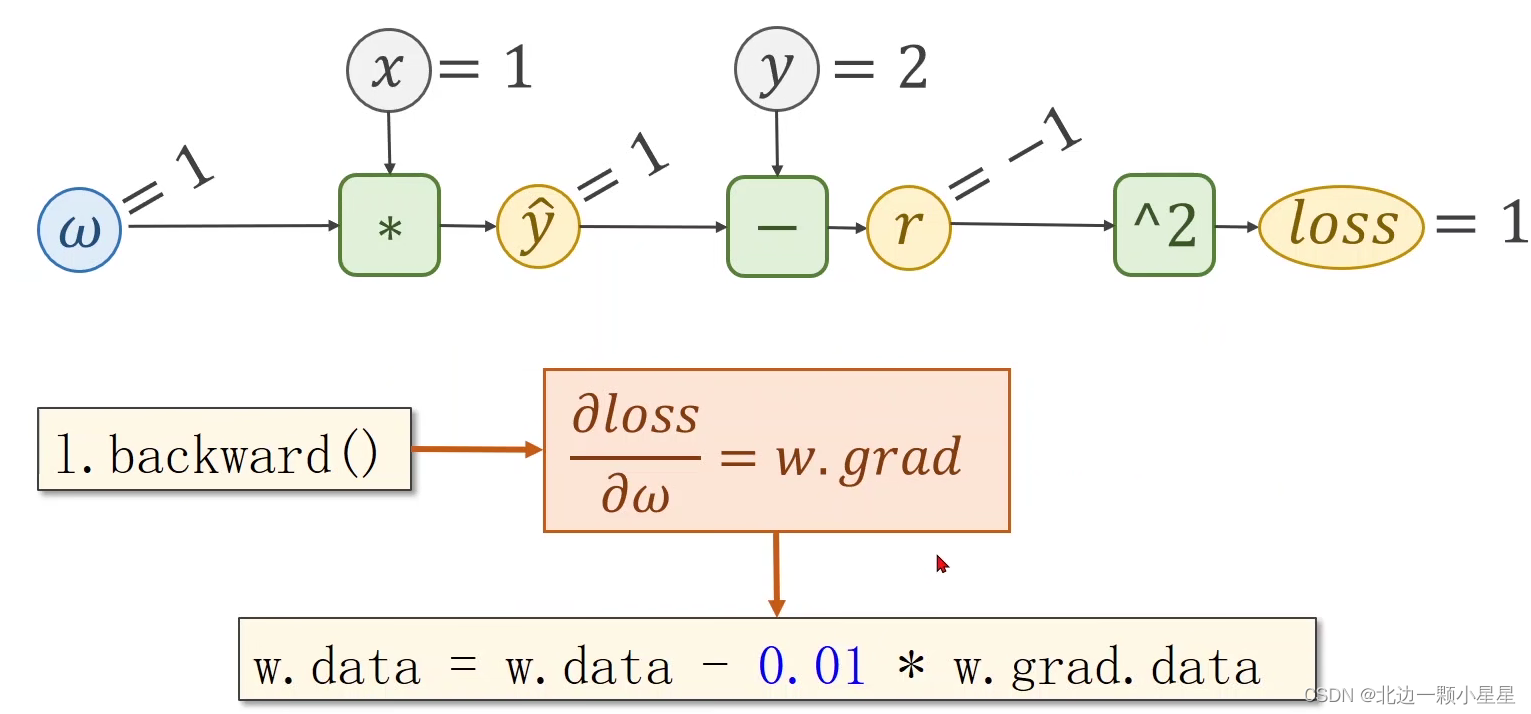
下面举个具体例子:

比如在前向传播中,函数f=x*w,那么z对x的偏导为w,z对w的偏导为x,当传入的x=2,w=3时,输出z=x*w=6。

然后在反向传播中,我们拿到损失Loss,计算出L对z的偏导为5,接着计算出L对x的偏导为5*w即5*3=15,同理L对w的偏导为10,然后L对x的偏导的结果再继续往上一层传,这样每一层都通过对w的偏导就可以由此做权重w的更新了。

上面是前向和反向的整体流程,计算出loss对w的偏导就可以用梯度下降算法对w进行更新了。

上面是梯度下降算法的公式推导。
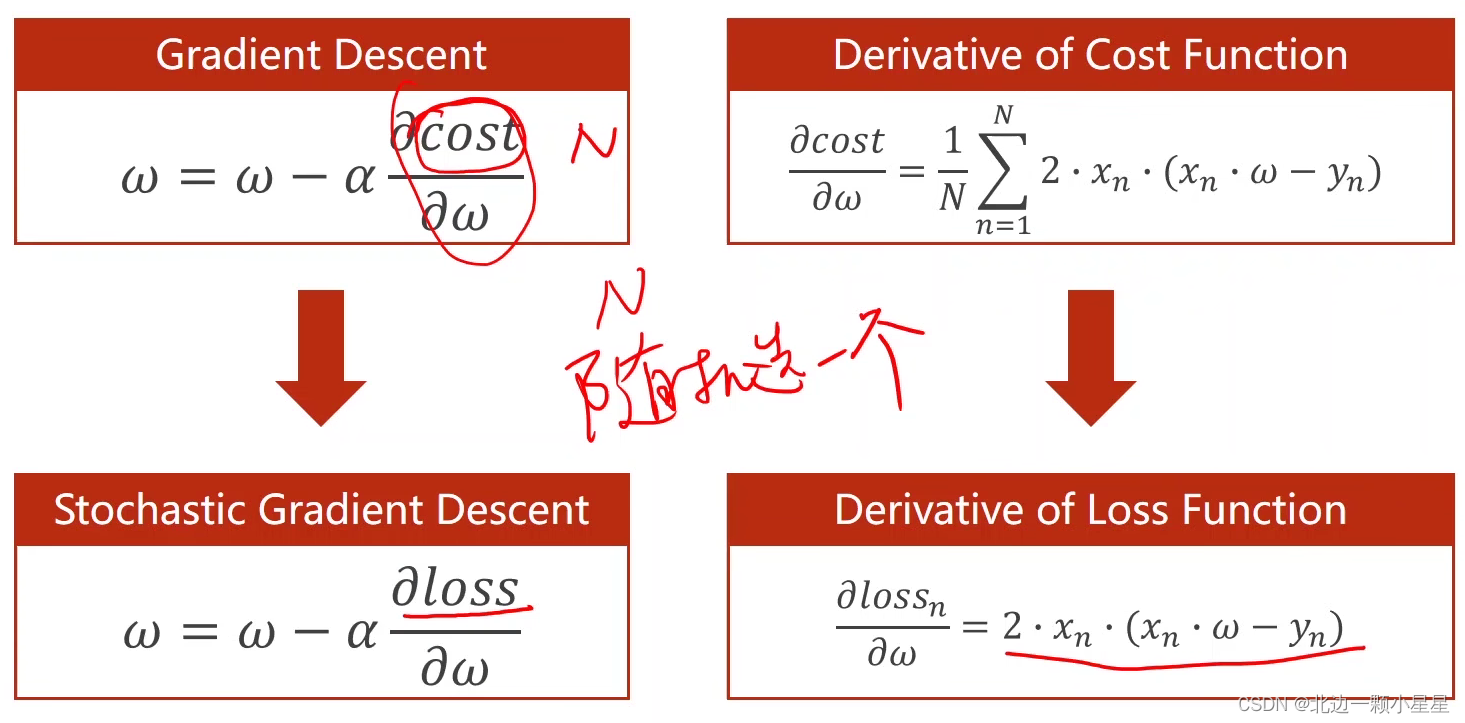
上面这个是随机梯度下降算法的公式。
代码演示:



循环神经网络(RNN)
一般神经网络不能处理具有序列关系的数据,比如给一张图片用卷积神经网络然后输出该图片的类别,这个输出只跟该输入的图片有关,和之前输入了什么图片无关,这种就是没有序列关系的数据。而比如像自然语言,字词、语句之间存在明显的前后关系,这时就要用循环神经网络处理了。
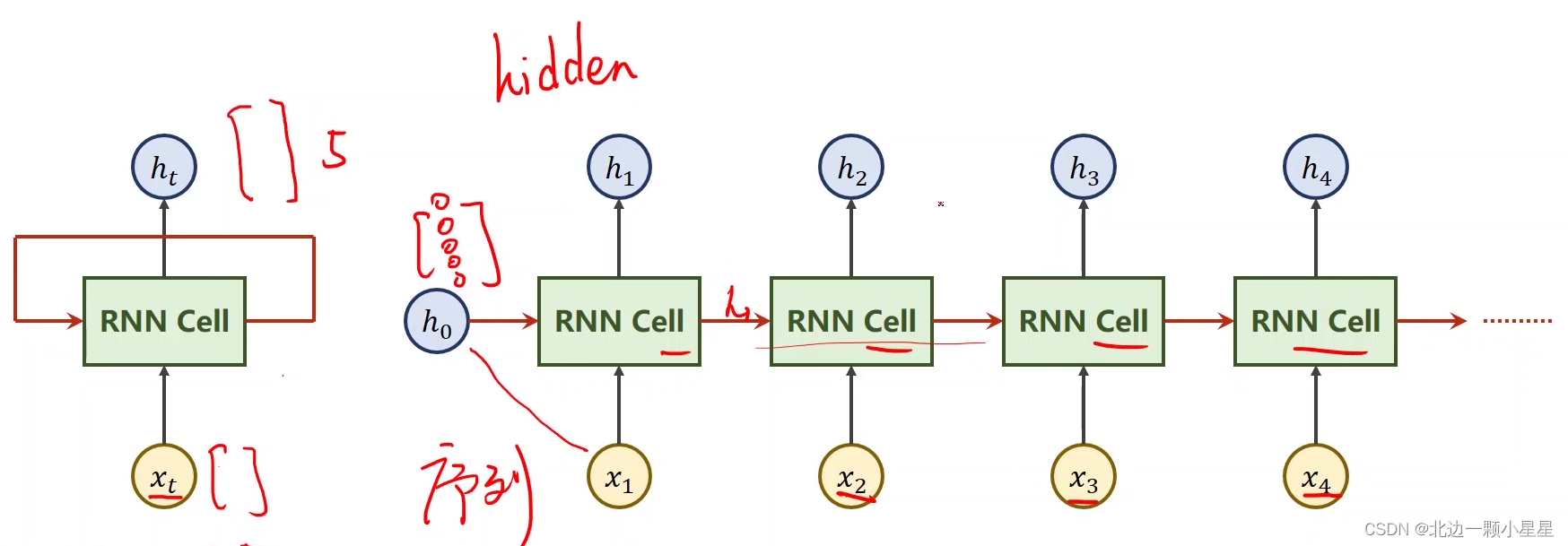

RNN Cell就是一个线性变换层,上图右边的四个RNN Cell都是指同一个RNN Cell,其中h又叫hidden, 每次输入都是与上一次的输出
一起放到RNN Cell里得出
,然后到下一个序列的数据
又会与
一起得出
,就这样循环往复,这样每次的输入都结合了上个序列的结果,体现了数据间的序列关系。
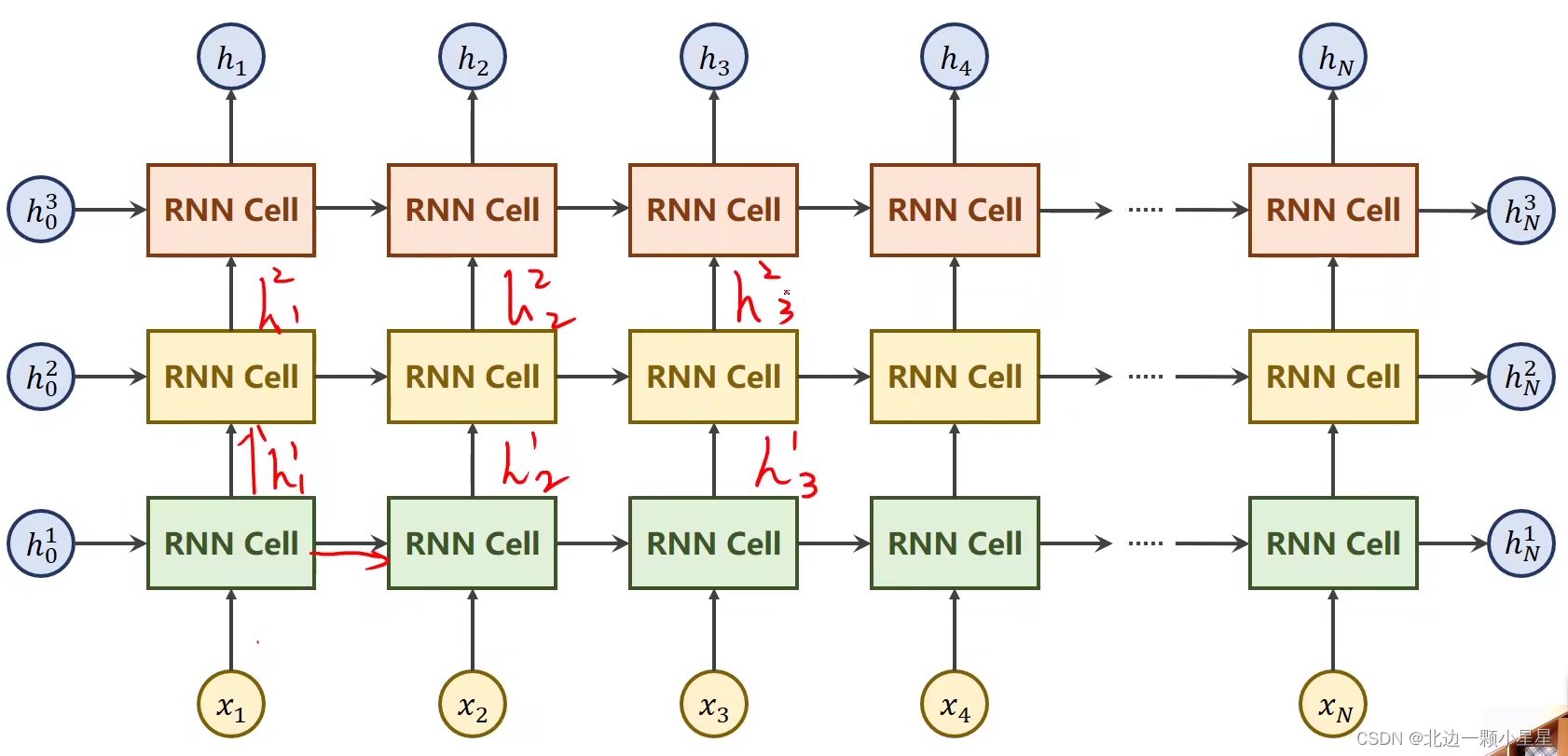
比如上图中有三层,第一层的RNN Cell接收的是原始的数据x和上个序列的输出h,第二层的RNN Cell接收的是上一层该序列的输出h和上个序列的输出h,第三层与第二层同理,以此类推。
实践举例

这里要求学习hello->ohlol的规律,其中Seq是序列的缩写。

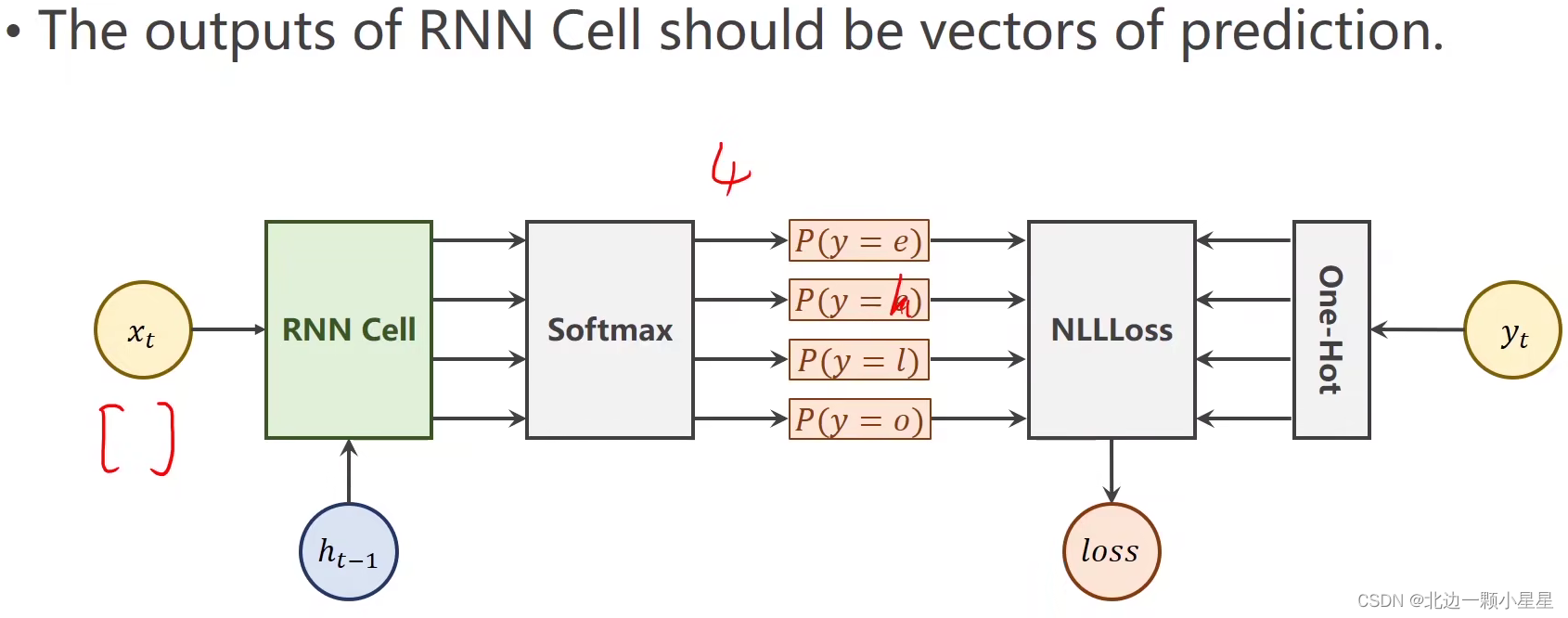
具体实现代码
import torch
input_size = 4
hidden_size = 3
batch_size = 1
#构建输入输出字典
idx2char_1 = ['e', 'h', 'l', 'o']
idx2char_2 = ['h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [2, 0, 1, 2, 1]
# y_data = [3, 1, 2, 2, 3]
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
#构造独热向量,此时向量维度为(SeqLen*InputSize)
x_one_hot = [one_hot_lookup[x] for x in x_data]
#view(-1……)保留原始SeqLen,并添加batch_size,input_size两个维度
inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size)
#将labels转换为(SeqLen*1)的维度
labels = torch.LongTensor(y_data).view(-1, 1)
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size):
super(Model, self).__init__()
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnncell = torch.nn.RNNCell(input_size = self.input_size,
hidden_size = self.hidden_size)
def forward(self, input, hidden):
# RNNCell input = (batchsize*inputsize)
# RNNCell hidden = (batchsize*hiddensize)
hidden = self.rnncell(input, hidden)
return hidden
#初始化零向量作为h0,只有此处用到batch_size
def init_hidden(self):
return torch.zeros(self.batch_size, self.hidden_size)
net = Model(input_size, hidden_size, batch_size)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.1)
for epoch in range(15):
#损失及梯度置0,创建前置条件h0
loss = 0
optimizer.zero_grad()
hidden = net.init_hidden()
print("Predicted string: ",end="")
#inputs=(seqLen*batchsize*input_size) labels = (seqLen*1)
#input是按序列取的inputs元素(batchsize*inputsize)
#label是按序列去的labels元素(1)
for input, label in zip(inputs, labels):
hidden = net(input, hidden)
#序列的每一项损失都需要累加
loss += criterion(hidden, label)
#多分类取最大
_, idx = hidden.max(dim=1)
print(idx2char_2[idx.item()], end='')
loss.backward()
optimizer.step()
print(", Epoch [%d/15] loss = %.4f" % (epoch+1, loss.item()))
















 3396
3396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











