






系列文章目录
【第一章原理】(109条消息) 【学习笔记】机器学习基础--线性回归_一无是处le的博客-CSDN博客
【第二章原理】(2条消息) 【学习笔记】机器学习基础--逻辑回归_一无是处le的博客-CSDN博客
【第三章】传统机器学习【先不写】
【第四章】聚类算法【先不写】
【第五章原理】【学习笔记】深度学习基础----DNN_一无是处le的博客-CSDN博客
【第五章代码实现】【学习笔记】手写神经网络之word2vec_一无是处le的博客-CSDN博客
前言
本章是关于我前一篇学习笔记的代码实现,即根据上一篇的线性回归原理,仅使用numpy自己实现简单的线性回归--波士顿房价预测
一、结构总览
要实现一个完整的机器学习项目,需要具备以下几个要点:1.获取数据 2.数据预处理 3.构建训练模型 4.训练模型 5.模型评估 6.模型的保存
而这里我由于我们是仅对上篇文章的代码实现,故而这里的代码会比较简陋,重点内容在于构建训练模型,其他方面则是从简。
二、使用步骤
1.引入库
代码如下:
import numpy as np
from matplotlib import pyplot as plt
from sklearn.datasets import load_boston2.数据预处理
代码如下:
class StandardScaler:
def fit(self, X):
self.mean_ = np.mean(X, axis=0)
self.std_ = np.std(X, axis=0)
def transform(self, X):
return (X - self.mean_) / self.std_
def fit_transform(self, X):
self.fit(X)
return self.transform(X)数据预处理这里只是简单的使用了数据标准化,如果有需要的话,可以分批并行训练(分batch和epochs)。而标准化则遵循公式: (
这里) 表示平均值,就是代码中的mean;
表示方差,就是代码中的std
3.构建训练模型
训练模型主要包括损失函数和梯度下降,代码如下:
class GradientDescent:
def __init__(self, X, y, alpha, epochs):
self.X = X
self.y = y
self.alpha = alpha
self.epochs = epochs
self.n = len(y)
self.theta = np.zeros((X.shape[1], 1))
def compute_cost(self):
# @表示矩阵的乘法运算
predictions = self.X @ self.theta
# 计算均值误差
cost = np.sum((predictions - self.y) ** 2) / (2 * self.n)
return cost
def gradient_descent(self):
# 将所有的损失值储存起来,便于做可视化,可以直观的看到损失函数的变化
cost_history = np.zeros(self.epochs)
for epoch in range(self.epochs):
predictions = self.X @ self.theta
errors = predictions - self.y
# 计算梯度
gradient = (self.X.T @ errors) / self.n
# 更新参数
self.theta = self.theta - self.alpha * gradient
cost_history[epoch] = self.compute_cost()
return self.theta, cost_history 这段代码是需要我们重点去理解学习的,如果对这些公式不理解的话可以看我的上一篇博客。
首先是参数(alpha 表示学习率, epoch 表示需要迭代的次数, theta 表示各个特征的权重),至于这里的theta为什么要写成 theta = np.zeros((X.shape[1], 1) ,因为我们需要对数据集的各个特征进行加权进行训练拟合。如果还不能理解的话直接看官方的参数也能知道我们应该怎么做。这里我们可以看下图数据集的参数量,和使用官方库中训练得出的参数做对比:
我们可以看到,训练集用的数据中第一个维度的数量为13,再官方库中训练得到的theta参数量,如下图:
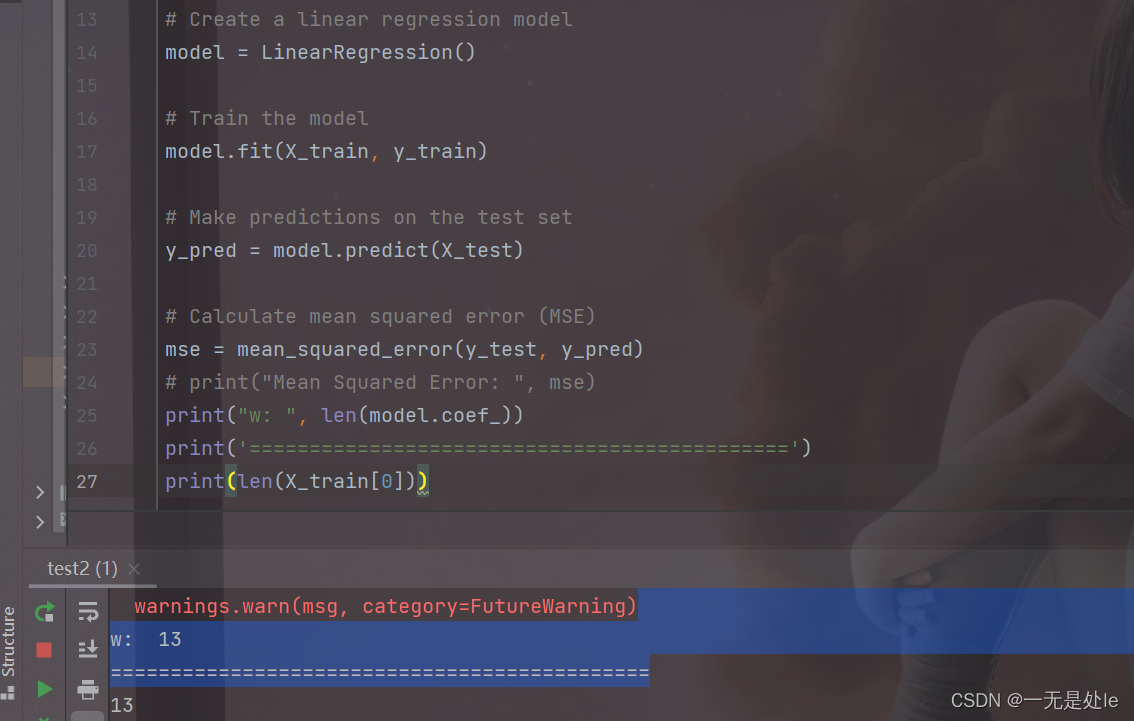
可以看到,官方库中的线性回归中的theta的len跟训练集中的第一个维度(也就是特征数)的数量一致,这也就是为什么我们需要这么来设置theta。
接下来我们再看下一个难点,也就是我们最需要理解的东西----梯度下降。一般的公式就不多赘述,这里就说说如何求导,也就是为什么 gradient = (self.X.T @ errors) / self.n 。我们先看损失函数微分公式,而我我们这里设置的error就是θ*x,因此这里self.X.T @ errors(内积)的结果就是
,有人可能会发现这里多了一个 2 ,这个 2 我将他放在了cost中消除,cost = np.sum((predictions - self.y) ** 2) / (2 * self.n) 原本的损失函数应该是 “/ self.n” 这里这个2就是为了消除微分的影响。
4.训练模型
代码如下:
boston = load_boston()
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(boston.data)
alpha = 0.01
epochs = 1000
X_train, X_test, y_train, y_test = train_test_split(X_train_scaled, boston.target, test_size=0.2, random_state=42)
X_test_scaled = scaler.transform(X_test)
model = GradientDescent(X_train, y_train, alpha, epochs)
final_theta, cost_history = model.gradient_descent()这段代码很常规,就不做解释。
5.查看结果,评估模型
代码如下:
# 只看最终的theta值
print('final_theta = ', final_theta[-1])
print('===========================================')
# 只看最后20个损失值
print('cost_history = ', cost_history[-20:])
# 绘图
plt.plot(range(epochs), cost_history)
plt.xlabel('Iterations')
plt.ylabel('Cost')
plt.title('Gradient Descent Convergence')
plt.show()
结果如下:


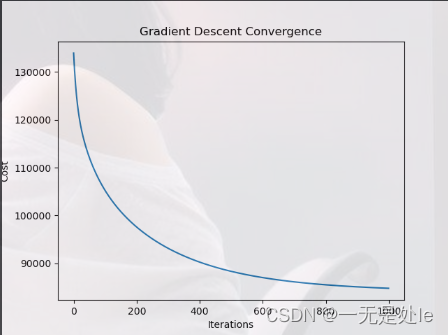
接下来我们再看看使用官方库来进行波士顿房价预测的结果:
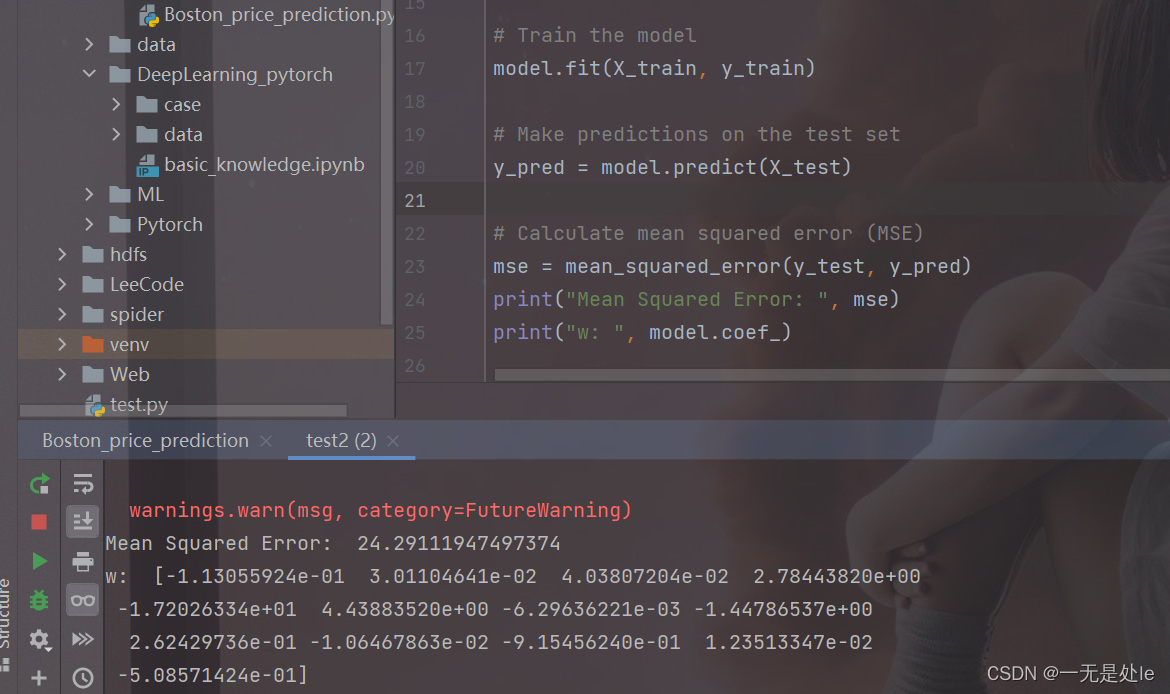
从打印出的结果我们可以看出,我们这次的损失值很大,也就是对模型的拟合性很弱,并且我们可以看到最终训练出来theta有很多很多的数,这其中有绝大多数的是冗余的,或者是噪声之类的,这是由于我没有使用正则化导致的结果,因为我们本篇博客只是对于我上一篇博客的代码解释,而上篇博客中我并没有介绍到相关的正则化(这个在我的下一篇博客中会写出【逻辑回归】),因此我们这里不需要看损失值,我们只看最终的绘图,我们可以看到我们的梯度下降是起到了很好的作用,因此我们就可以认为我们较好的完成了我们此次的任务。
总结
本片博客只是对我上一篇博客的代码解释,有很多方面没有顾及到,因此最终的结果可能会不理想,但是我们还是顺利的完成了我们的基本要求,代码解释,并且其重点梯度下降还是较好的完成了,O(∩_∩)O
完整代码
import numpy as np
from matplotlib import pyplot as plt
from sklearn.datasets import load_boston
class GradientDescent:
def __init__(self, X, y, alpha, epochs):
self.X = X
self.y = y
self.alpha = alpha
self.epochs = epochs
self.n = len(y)
self.theta = np.zeros((X.shape[1], 1))
def compute_cost(self):
predictions = self.X @ self.theta
cost = np.sum((predictions - self.y) ** 2) / (2 * self.n)
return cost
def gradient_descent(self):
cost_history = np.zeros(self.epochs)
for epoch in range(self.epochs):
predictions = self.X @ self.theta
errors = predictions - self.y
gradient = (self.X.T @ errors) / self.n
self.theta = self.theta - self.alpha * gradient
cost_history[epoch] = self.compute_cost()
return self.theta, cost_history
class StandardScaler:
def fit(self, X):
self.mean_ = np.mean(X, axis=0)
self.std_ = np.std(X, axis=0)
def transform(self, X):
return (X - self.mean_) / self.std_
def fit_transform(self, X):
self.fit(X)
return self.transform(X)
def train_test_split(data, target, test_size, random_state):
if random_state is not None:
np.random.seed(random_state)
n = data.shape[0]
limit = int(n * test_size)
X_train = data[:-limit]
X_test = data[-limit:]
y_train = target[:-limit]
y_test = target[-limit:]
return X_train, X_test, y_train, y_test
boston = load_boston()
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(boston.data)
alpha = 0.01
epochs = 1000
X_train, X_test, y_train, y_test = train_test_split(X_train_scaled, boston.target, test_size=0.2, random_state=42)
X_test_scaled = scaler.transform(X_test)
model = GradientDescent(X_train, y_train, alpha, epochs)
final_theta, cost_history = model.gradient_descent()
print('final_theta = ', final_theta[-1])
print('===========================================')
print('cost_history = ', cost_history[-20:])
# 绘图
plt.plot(range(epochs), cost_history)
plt.xlabel('Iterations')
plt.ylabel('Cost')
plt.title('Gradient Descent Convergence')
plt.show()















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









