



 本文介绍了机器学习的基础知识,包括线性回归的用途、定义、损失函数(MSE)和梯度下降算法。讨论了训练过程中的注意事项,如MSE的含义和训练时间的控制,以及批量训练的策略。此外,文章还提及了线性回归的强拟合能力与过拟合问题,以及回归方程的学习性质和权重含义。
本文介绍了机器学习的基础知识,包括线性回归的用途、定义、损失函数(MSE)和梯度下降算法。讨论了训练过程中的注意事项,如MSE的含义和训练时间的控制,以及批量训练的策略。此外,文章还提及了线性回归的强拟合能力与过拟合问题,以及回归方程的学习性质和权重含义。
系列文章目录
【第一章代码解释】【线性回归】原生numpy实现波士顿房价预测_一无是处le的博客-CSDN博客
【第二章原理】(2条消息) 【学习笔记】机器学习基础--逻辑回归_一无是处le的博客-CSDN博客
【第三章】传统机器学习【先不写】
【第四章】聚类算法【先不写】
【第五章原理】【学习笔记】深度学习基础----DNN_一无是处le的博客-CSDN博客
【第五章代码实现】【学习笔记】手写神经网络之word2vec_一无是处le的博客-CSDN博客
前言
【学习笔记】机器学习基础--线性回归学习笔记,由浅入深理解线性回归,以下都是我自己个人的理解,如有错误欢迎指出啦!(●ˇ∀ˇ●)
建议本章于第二章-逻辑回归原理一起学习
一、【引入】机器如何进行学习
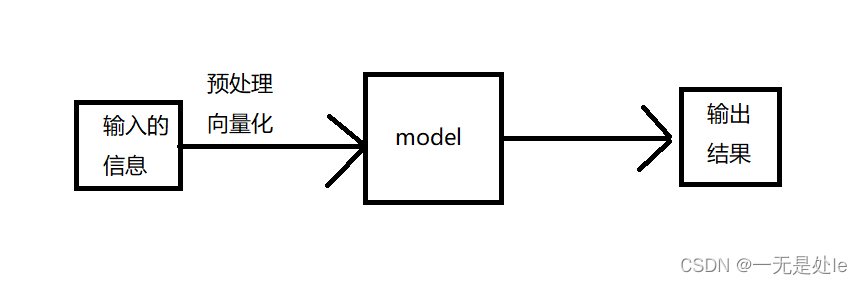
机器如果要做到到像是图像识别,语音识别,文本语义分析,文本情感分析等,要做的第一步就是需要将输入的例如图像文本等通过向量化转化成机器能够识别的信息,这也叫特征提取,之后将这些数据输入到人工制作的模型当中,经过模型中的算法,最终输出一个我们需要的结果【如下图,最简单的流程】,这就是机器学习。而我们这里要记录的线性回归,就是机器学习当中最简单的一种模型。
二、线性回归介绍
1.用处
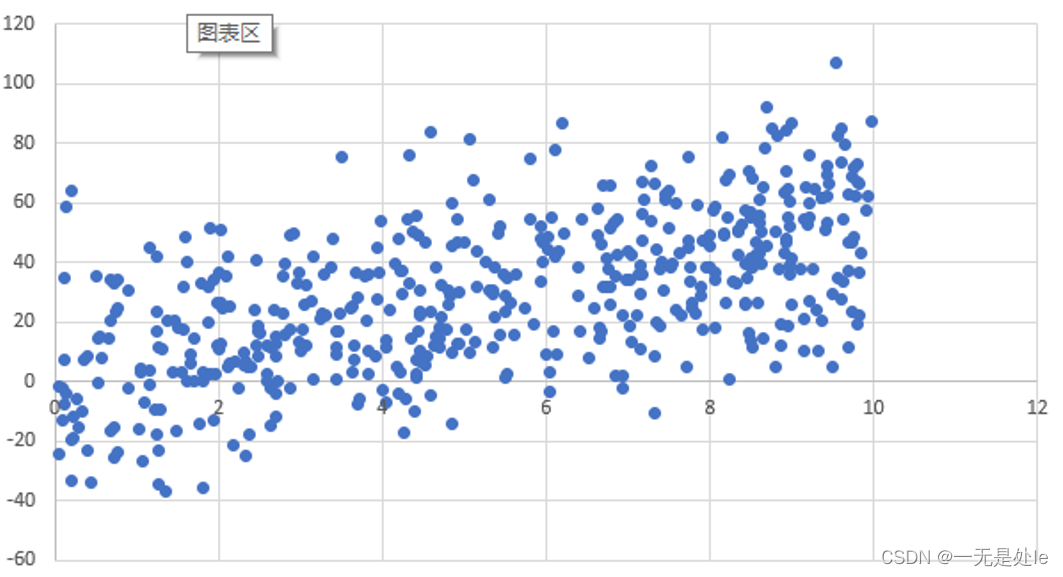
线性回归一般多用于预测和预测分析,如房价预测。下图是一些散点,我们现在需要找出一条最合适的线(线性)来拟合这些散点,使我们的能够做出最正确的结果预测。而我们就可以使用线性回归的方式来找出这条线。
2.定义与公式
线性回归(Linear regression)是利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式。
- 特点:只有一个自变量的情况称为单变量回归,多于一个自变量情况的叫做多元回归
因此线性回归公式一般会用矩阵的方式表示,写成
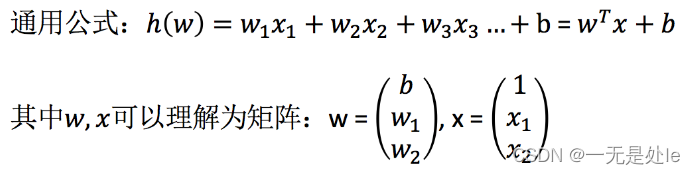
为了便于理解,下面的记录都是使用一维的单变量回归公式,f(x)=wx+b来表示
三、损失函数
1.引入
我们在使用上面的线性回归公式对散点进行拟合的时候,我们一般使让机器随机定义一个w和b进行训练,不停的调整w和b直到达到最优解。那么机器怎么知道什么时候达到最优值然后停止训练呢?这就需要我们构造一个损失函数,当损失函数达到最小的时候,机器便停止训练。
2.推导
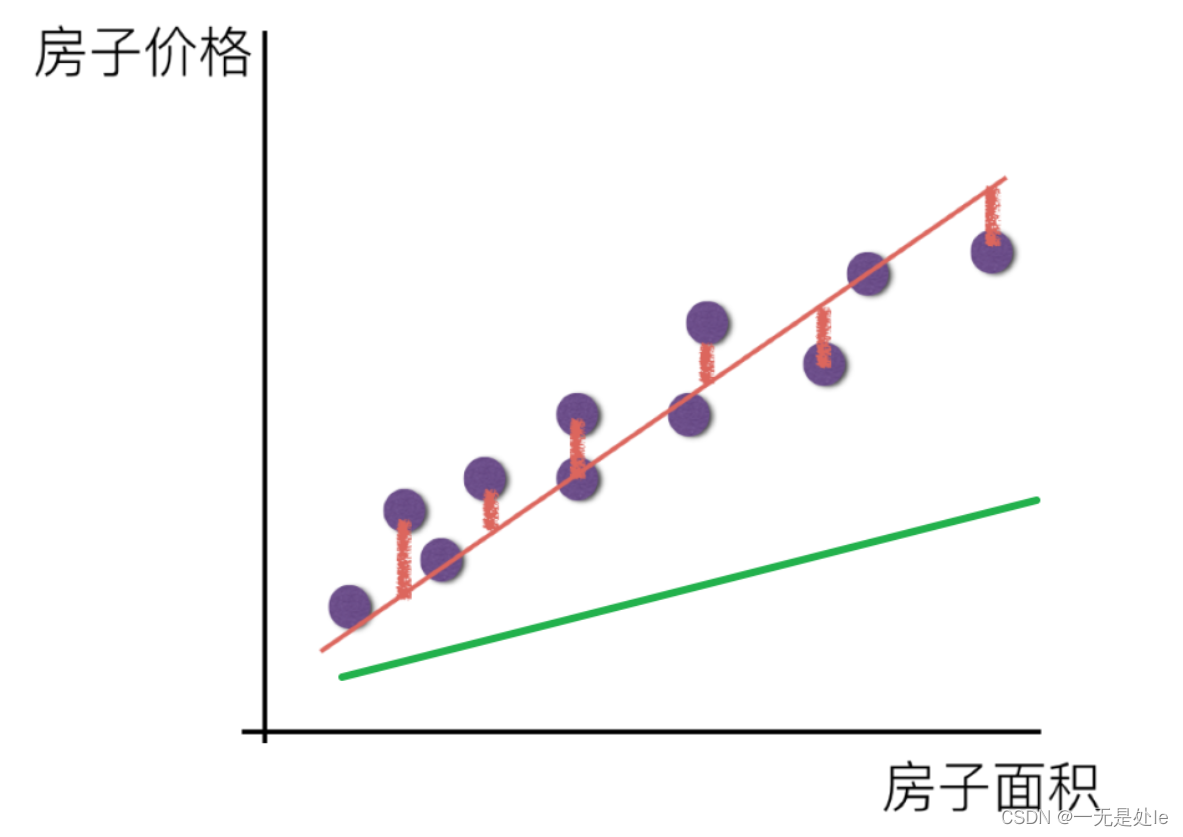
我们怎么构造一个损失函数?看上图,最直接的就是
【这里的fi是预测的结果,y是真实值】,但是如果我们直接就是用这个函数当作损失函数的话,会出现一些问题,例如在机器学习的过程当中,我们是只取出全量数据当中的一部分数据拿来训练,那么这些训练的数据当中就会存在一些容易拟合的点和一些难以拟合的点,一般来说,这些数据点只要不是噪声,我们是都需要去拟合的,但是如果我们使用
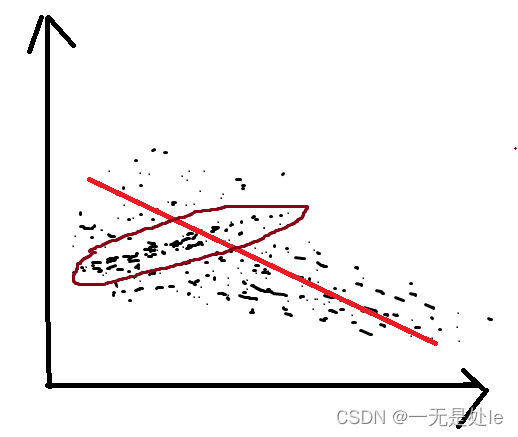
假如这个图就是我们的数据点,我们需要对这些点进行拟合,如果我们训练时遇到棕色圈住的点,那么计算机就会不停的去拟合棕色圈内的那些容易拟合且密集的点,而忽略掉其他不容易拟合的点或者说距离比较远的点,因此会得到一条不理想的线,最终只能是局部损失函数很低,但是拟合的效果却不理想,总体损失函数还是偏高。
【补充】并且下面的梯度下降中需要微分,而具有绝对值的函数并不是处处可微的,这也是他的一个弊端
因此我们可以改进上面的损失函数, ,这叫【均方误差(MSE)】这个损失函数就不会有上面的问题了比如【fi - y = 5】则【(fi - y)²= 25】,计算机进行调整w之后假如【fi - y = 4】则【(fi - y)² = 16】则这个点调整过后对于损失函数的贡献为9,之后每次调整w降低损失,都会使贡献值降低,因此当这些点的对损失函数的贡献变得很小的时候,计算机就会优先去拟合其他贡献值高的点,就不会出现上面的问题,这就类似于给计算机增加了一个奖励机制,使得计算机的注意力遍布所有数据点。
如果需要从理论上理解这个问题可以参考文章(108条消息) 线性回归损失函数为什么要用平方形式_线性回归的损失函数是什么_saltriver的博客-CSDN博客
四、梯度下降
1.引入
由上可知,目前为止我们已经有了训练模型,损失函数,那么接下来就是要探寻训练方法,我们的目的是让我们定义的损失函数达到最小值,那么就需要用到优化算法,一般来说,如果我们需要求得一个函数的最小值,那么我们可以通过求解方程组直接获取到最优参数,这个方法叫做正规方程。但实际上,在需要用到机器学习的情况下,往往是由于数据量太大,特征太多,维度太高导致人工计算难以实施,在实际训练的过程中,可能需要训练的数据有上百万,维度有上百维,因此如果使用正规方程直接计算的话,哪怕是使用高性能计算机也是需要很长时间,因此,我们需要用其他的优化算法来求得损失函数的最小值-----梯度下降
如果想了解正规方程的求解和推导,可以参考下面文章:多元线性回归方程正规方程解(Normal Equation)公式推导详细过程_多元线性回归方程求解_iioSnail的博客-CSDN博客
2.定义与公式
梯度下降是一种常用的优化算法,用于最小化目标函数。它的基本思想是通过迭代的方式,沿着目标函数的梯度方向逐步更新模型参数,以达到最优解。
梯度下降的公式如下: θ_new = θ_old - α * ∇J(θ_old)
其中,
- θ_new 是更新后的参数向量(包括多个参数)
- θ_old 是上一轮迭代的参数向量
- α(alpha)是学习率(也称为步长或者学习速率),控制每次迭代的步幅
- ∇J(θ_old) 是目标函数 J 关于参数向量 θ_old 的梯度向量
梯度(∇J(θ_old))是目标函数关于参数向量的偏导数向量。对于具有多个参数的目标函数,梯度是一个向量,每个分量表示相应参数的偏导数。
算法步骤如下:
- 初始化参数向量 θ_old。
- 计算目标函数 J 关于参数向量 θ_old 的梯度 ∇J(θ_old)。
- 更新参数向量:θ_new = θ_old - α * ∇J(θ_old)。
- 重复步骤 2 和步骤 3,直到达到停止条件(如达到最大迭代次数或梯度收敛到足够小的值【一般是导数为0的时候】)。
梯度下降的目标是找到目标函数的局部最优解或全局最优解,具体取决于目标函数的性质和初始参数值。学习率 α 的选择也非常重要,过大的学习率可能导致震荡或发散,而过小的学习率可能导致收敛速度过慢。因此,需要进行适当的调节和实验选择。
3.公式推导
这里我们用最开始给的散点图为例,其损失函数图像如下:
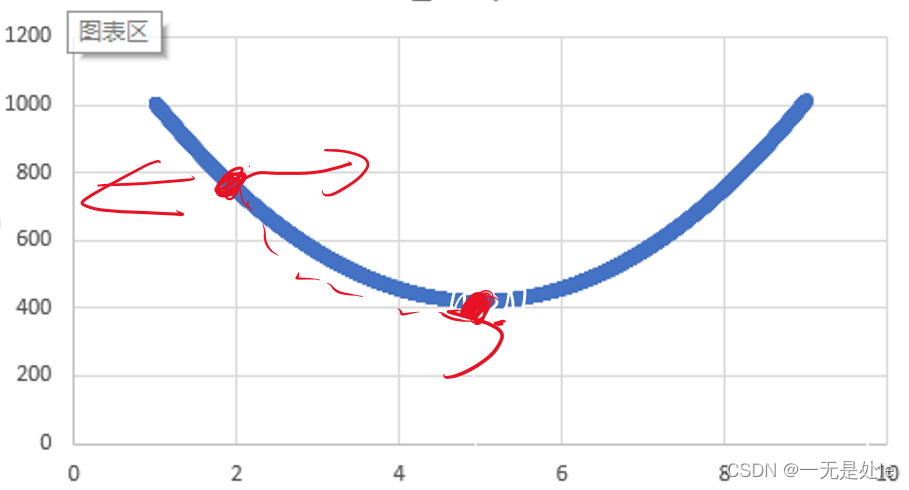
我们需要从开始的最高点通过优化w一步步使损失函数到达最低点。而为了能够最快的下降(达到损失函数最低点)我们就可以让w每步都减去其切线方向(微分)的步长。
【这里有一个误区,我开始的时候就理解有问题,我开始以为模型训练是使用梯度下降让损失函数减小,以到达其最小值,因此我一直不理解为什么θ_new = θ_old - α * ∇J(θ_old)公式当中要减去其导数的步长(- α * ∇J(θ_old))。因为我之前认为,如上图,前面这一半函数的导数是负数,那么减去损失函数的导数的步长只会让损失函数变大而不是减小,因此我之前一直在这个“-”号附近兜圈子,不理解。事实上,模型训练只是去改变w(权重)来使得损失函数达到最小,这样理解就没有问题】我们这里为了便于理解,我们使用一维单变量回归公式进行求导。
因此我们现在要对
求解
求导得:
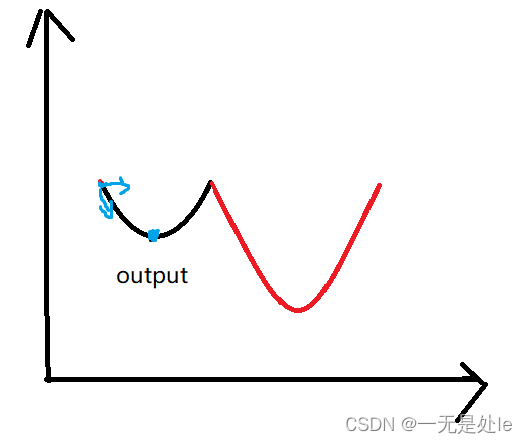
这样带入迭代求解慢慢的就可以得到最优解【注意这里的α是人工定义的,一般定义在0.001左右,大了容易振荡取不到最优解,小了则会拖慢训练速度】。这里可能有人会想为什么这里经过梯度下降一定是损失函数的最小值而不是极小值(如下图),有没有可能只是一个极小值,而取不到最优解?事实上一般来说都是能取到损失函数的最小值的,原因如下:
线性模型的性质:在线性回归中,我们假设自变量和因变量之间存在一个线性关系。线性关系意味着目标函数(损失函数)是参数的二次函数。对于二次函数,其形状是凸的。
损失函数的定义:均方误差(MSE)损失函数是通过计算预测值与真实值之间的差的平方来度量模型的误差。这是一个连续可导的函数,并且是参数的二次函数。因此,MSE损失函数也是一个凸函数,而凸函数一定是只有一个全局最小值点,这是凸函数的性质。
4.注意事项
在实际的使用过程中,或者说在工程项目中,往往有成百上千万的数据,如果每个数据都需要这样求梯度,会很耗时,大大增加训练时间,因此,在实际的使用当中,我们往往不会求所有的梯度【全梯度下降法】,而是会采用像是随机梯度下降算法,小批量梯度下降算法和随机平均梯度下降算法等等并且可以加以梯度下降优化算法,具体想了解的可以参考:
--------------------------------------分割线---------------------------------------
至此,我们基本已经对行线性回归有了一定程度的理解,因此,下面继续分享一些线性回归的性质
五、补充/注意事项
1.MSE越低越好?训练越久越好?
在工程项目当中,数据中往往会存在一定数量的脏数据(异常,错误数据或者缺失数据等),这些脏数据或许一开始不会被学到,但是在训练的后期,当模型训练的差不多的时候如果不停止训练的话或许就会开始学习脏数据,导致损失变大,如下图:
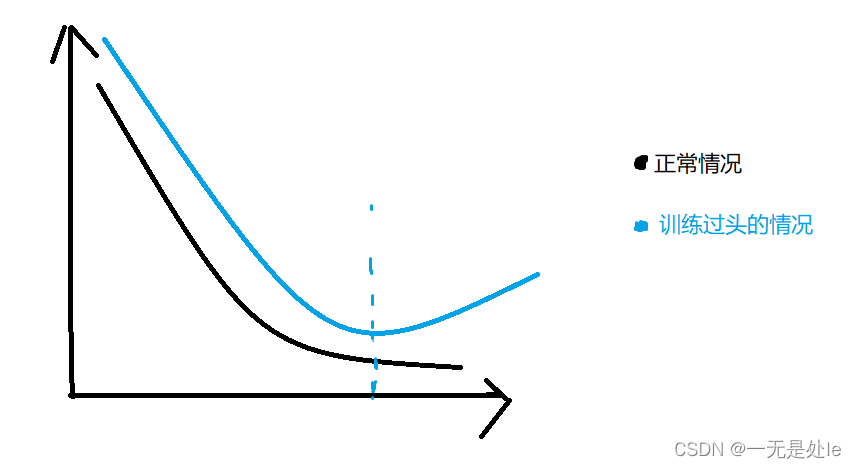
因此我们不能无休止的训练模型 。并且如果mse过低也会出现一系列的问题,例如出现过拟合的情况(训练集的mse小,拟合程度高,但是在测试集中效果不理想),泛化程度低。
那我们该如何避免上述这些情况呢?
1.我们可以在训练集中再分训练集和有效集,在训练过程中,每隔一段时间或者一些批次(epoch)就使用训练集中的有效集来测试mse如果发现mse有上升的趋势或者长期变化不明显的时候就需要停止训练。
2.可以设置一定批次(epoch)过后,就降低学习率或者其他一些超参数来达到进一步的拟合。
2.批量训练注意事项
在实际训练中,我们往往会对数据集进行分批分次迭代训练,这样的做的原因是可以并行训练,提高训练的效率,再一个是可以一定程度提高训练的效果。在训练中mse的方差
(m表示批量的抽取的batch)
【记住结论就好,推导我也不知道】,因此我们采取小批次大量迭代的方式来训练会获得更高的性价比(花费时间少,效果相对好),即小batch大epoch(更大的batch并发只会提高训练速度,但是需要更强的性能,更大的内存,训练效果也不会好多少),之后的模型中也可以使用这种思想。
3.回归方程强拟合能力的利弊
先说结论,在训练集上,回归方程拥有可以说是最强的拟合,无论是什么样的线,他都能拟合,直线可以用线性回归来拟合,曲线(无论是什么线)都可以通过多项式回归方程来拟合,这个结论的理论依据就是泰勒展开,有兴趣的可以自己去学习。而这多项式回归方程其本质和上面的线性回归是一样的,也就是说,机器学习需要做的任何有关于拟合函数预测的工程都可以使用回归,并且准确率不会低,只是对于项数多次数高的需要计算的时间要更多。
例如
这条曲线可以使用
这个方程来拟合。
而对于
这种不规则的曲线则可以使用
这种回归方程,可以让机器自动学习,当需要更高次的时候自动加入更高次来进行拟合。
但是这样的强拟合能力也会带来很大的问题,就是过拟合问题,这也就是为什么要强调在训练集上的原因,因为我们用来训练的数据集不可能是所有的数据,更不可能包括了一些我们需要预测的未知数据,因此,这样的强拟合能力只能在训练集上发挥出作用,在测试集上效果会变得很差(
因为模型会学习到很多不具备泛化能力的特征,也就是所谓的噪声)。因此拟合性越强的回归方程,可以说其泛化能力越差,这也就是为什么在工程上我们一般都是使用线性回归来进行拟合函数,预测结果,而不是用多项式回归。
4.回归方程的学习性质
回归方程相比于其他的模型有着很多的优势,接着上面说的强拟合能力,我们知道,回归方程会自动的去根据输入数据不断修改w降低损失函数直至拟合出一条最优的线,这个过程中,如果我们没有赋予机器自动添加项数的能力的情况下,人工预设的回归方程的项数多,次数高的模型,其拟合能力一定是大于等于比其项数少,次数低的模型。因为我们预设的模型中如果有的项对于拟合输入数据没有贡献,那么在模型训练中就会不断的削减对应项的w直至接近0或者为0,也就是变为了比其项数少,次数低的模型。由此我们也可以知道,不管是线性回归还是多项式回归,都有着很强的抗噪声干扰能力
(当然并不是免疫噪声,当训练过度的时候依然会收到噪声的干扰,所谓的噪声其实就是训练集中特有的特征,机器学习到了这些噪声就会噪声过拟合的现象)。
5.线性回归的权重
在线性回归中,
这个线性回归方程中的各个w能表示其所在的特征的权重吗?答案是否定的。因为在工程上或者说日常生活中,我们给出的代表不同特征的数据,可能会有很大的交叉性(冗余性),例如一个方程
,根据上面提到的回归的学习能力,我们完全可以将该方程变换为
, 将
拆分成权重相同的特征x1和x2,这两个方程在拟合能力和预测效果上几乎完全没有差别(
可以自己写代码测试一下 ,这里只记录要点)。因此,在线性回归中,得到的各个w的值不能看作是各个特征于总体训练集中的权重占比,只有在各个特征完全线性无关,没有冗余的情况下才能看成权重。【注意】
总结
这是我自己对于机器学习学习笔记系列的第一章,也是最简单的线性回归,这里我只列出了我学习之后对于线性回归的自己的理解(要点),而代码可以自己根据理解,不使用别人封装好的库,自己来实现线性回归的各种公式,自己模拟实现一遍使用线性回归的机器学习项目。这样对于理解线性回归有着很大的帮助。还是那句话,这些都是我个人学习过后的理解,如有错误的地方欢迎指出。

















 3836
3836




 到【灌水乐园】发言
到【灌水乐园】发言







