







目录
-
栈及其基本运算
- 栈的定义
- 栈的相关概念
- 逻辑结构 :与同线性表相同,仍为一对一的关系
- 存储结构:用顺序栈或链栈存储均可,但以顺序栈更常见
- 运算规则:只能在栈顶运算,且访问结点时依照 (LIFO)的原则
- 实现方式,关键是遍写入栈和出栈的函数,具体实现依顺序栈或链栈的不同而不同
- 栈(stack):一种只允许在表达一段进行插入或者删除操作的特殊的线性表
- 栈顶(top)允许进行插入和删除操作的一段an
- 栈底(bottom):不允许插入和删除的操作a1
- 先进后出(FILO)或者后进先出(Last In First Out 简称LIFO)的线性表
- “入“=压入=push(x) ”出“=弹出=pop(y)


- 例如:依次将ABCDEF入栈,再进行出栈的操作依次输出FEDCBA符合先进后出的模型
- 栈的顺序存储和运算
- top=0:栈空 top=m:栈满
栈的基本运算(核心)
- 入栈操作(观察是否满栈)判满
- 退栈操作(观察是否空栈)判空
- 读栈顶元素
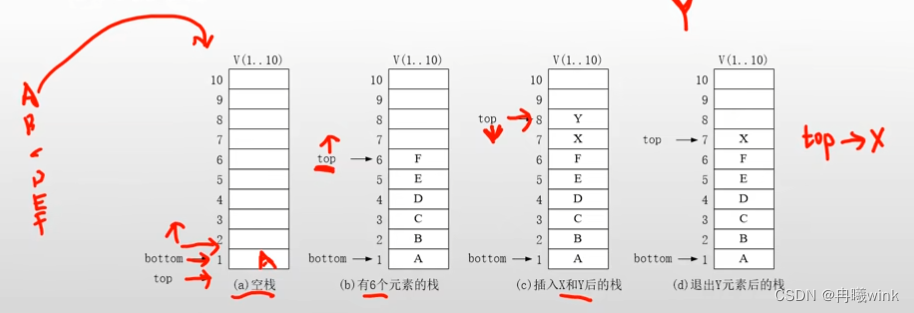
- 栈与一般的线性表有什么不同
- 栈与一般的线性表的区别:仅在于运算规则不同
- 一般线性表
- 逻辑结构:一对一
- 存储结构:顺序表,链表
- 运算规则:随机存取
- 栈
- 逻辑结构:一对一
- 存储结构:顺序栈,链栈
- 运算规则:后进后出(LIFO)原则
- 栈的表示和操作的实现
- 栈的抽象数据类型的类型定义
- InitStack(&s)初始化操作;操作结果:构造一个空栈
- DestroyStack(&s)销毁栈操作;初始条件:栈s已经存在;操作结果:栈s被销毁
- StackEmpty(s)判断s是否为空栈;初始条件:栈s已经存在;操作结果:若栈s为空栈,则返回TRUE,否则FALSE
- StackLength(s)求栈的长度;初始条件:栈s已经存在。操作结果:返回s的元素个数,即栈的长度
- GetTop(s,&e)取栈顶元素;初始条件:栈s已经存在且非空;操作结果:用e返回s的栈顶元素
- ClearStack(&s)栈置空操作;初始条件:栈s已经存在;操作结果:将s清为空栈
- Push(&s,e)入栈操作;初始条件:栈s已经存在;操作结果:插入元素e为新的栈顶元素
- Pop(&s,&e)出栈操作;初始条件:栈s已经存在且非空。操作结果:删除s的栈顶元素an,并用e返回其值
- 栈的表示和实现
- 由于栈本身就是线性表,于是栈也有顺序存储和链式存储两种实现方式
- 栈的顺序存储--顺序栈
- 栈的链式存储--链栈
- 由于栈本身就是线性表,于是栈也有顺序存储和链式存储两种实现方式
-
1.顺序栈的表示和实现
- 存储方式:同一般线性表的顺序存储结构完全相同。利用一组地址连续的存储单元依次存放自栈底到栈顶的数据元素,栈底一般在第地址端
- 附设top指针,指示栈顶元素在顺序栈的位置 an存在于数组下标为n-1的位置
- 令设base‘指针,指示栈底元素在顺序栈中的位置 a1存在于数组下标为0的位置
- 但是为了方便操作,通常top指示真正的栈顶元素之上的(也就是下一个元素位置)下标地址
- 另外,用stacksize表示栈可使用的最大容量
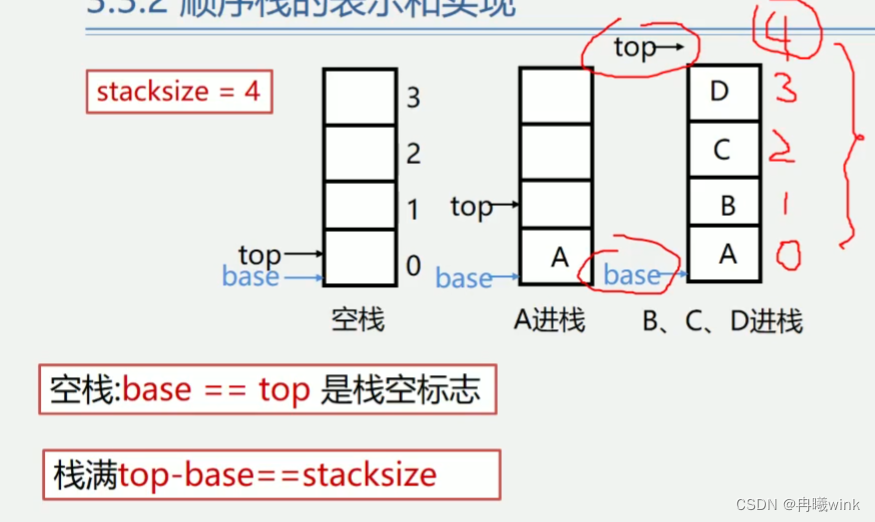
- 存储方式:同一般线性表的顺序存储结构完全相同。利用一组地址连续的存储单元依次存放自栈底到栈顶的数据元素,栈底一般在第地址端
-
栈满时的处理方法:
-
1.报错返回操作系统
-
2.分配更大的空间,作为栈的存储空间,将原栈的内容移入新栈
-
使用数组作为顺序栈存储方式的特点:简单,方便,但易产生溢出(数组大小固定)
- 上溢(overflow):栈已经满,又要压入元素
- 下溢(underflow):栈已经空,还要弹出元素
- 注意:上溢是一种错误,使问题的处理无法进行;而下溢一般认为是一种结束条件,即问题处理结束
-
顺序栈的表示
#define MAXSIZE 100 typedef struct{ SElenType *base;//栈底指针 SElenType *top;//栈顶指针 int stacksize;//栈的可用最大容量 }SqStack
-
1.1顺序栈的初始化
//初始化栈
Status InitStack(SqStack &S){//构造一个空栈
S.base=new SElemType[MAXSIZE];//或
S.base=(SElemType *)malloc(MAXSIZE*sizeof(SElemType));
if(!S.base)exit(OVERFLOW)//存储分配失败
S.top=S.base;//栈顶指针等于栈底指针
S.stacksize=MAXSIZE;
return OK;
}-
1.2顺序栈判断栈是否为空
Status StackEmpty(SqStack S){
//若栈为空,返回TRUE否则返回FALSE
if(S.top==S.base)
return TRUE;
else
return FALSE;
}-
1.3求顺序栈的长度
int StackLength(SqStack S)
{
return S.top-S.base;
}-
1.4清空顺序栈
Status ClearStack(SqStack S)
{
if(S.base)S.top=S.base;
return OK;
}-
1.5销毁顺序栈
status DestroyStack(Sqstack &S){
if(S.base)
{
delete S.base;
S.stacksize=0;
S.base=S.top=NULL;
}
return OK;
}-
顺序栈的入栈

- (1)判断是否栈满,若满则出错(上溢)
- (2)元素e压入栈顶
- (3)栈顶指针加1
Status Push(SqStack &S,SElemType e){
if(S.top-S.base==S.stacksize)//栈满
return ERROR;
*S.top++=e;//或者*S.top=e;// S.top++;
return OK;
}- 顺序栈的出栈

- (1)判断是否栈空,若空则出错(下溢)
- (2)获取栈顶元素e
- (3)栈顶指针减1
Status Pop(SqStack &S,SElemType &e)
{//若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK否则返回error
if(S.top==S.base)//等价于if(StackEmpty(S))
return ERROR;
e=*--S.top;//相当于--S.top;e=*S.top
return OK;
}2.链栈的表示和实现
- 链栈的表示
- 链栈是运算受限的单链表,只能在链表头部进行操作
typededf struct StackNode(
SElemType data;
struct StackNode*next;
)StackNode,*LinkStack;
LinkStack S; 
- 链表的头指针就是栈顶
- 不需要头结点
- 基本不存在栈满的情况
- 空栈相当于头指针指向空
- 插入和删除仅在栈顶处执行
-
2.1链栈的初始化
void InitStack(LinkStack &S)
{
//构造一个空栈,栈顶指针置为空
S=NULL;
return OK;
}-
2.2判断链栈是否为空
Status StackEmpty(LinkStack S)
{
if(S==NULL)
return TRUE;
else
return FALSE;
}-
2.3链栈的入栈
-
Status Push(LinkStack &S,SElemType e){ p=new StackNode;//生成新结点p p->data=e;//将新节点数据域置为e p->next=S;//将新节点插入栈顶 S=p;//修改栈顶指针 return OK; } -
2.4链栈的出栈
Status Pop(LinkStack &S,SElemType &e){
if(S==NULL) return ERROR;
e=S->data;
p=S;
S=S->next;
delete p;
return OK;
}-
2.5取栈顶元素
SElemType GetTop(LinkStack S){
if(S!=NULL)
return S->data;
}栈与递归
- 若一个对象部分地包含着他自己,或者他自己给自己定义,则称这个对象是递归的
- 若依个过程直接或者间接的调用自己,则称这个过程是递归的过程
- 例如:递归求n的阶乘
-
long Fact(long n) { if(n==0)return 1; else return n*Fact(n-1); }以下三种情况常常用到递归方法
-
递归定义的数学函数
-
具有递归特性的数据结构
-
可递归求解的问题
1.递归定义的数学函数
- 阶乘函数
- 2阶斐波那契数列
2.具有递归特性的数据结构
-
队列及其基本运算
-
队列的定义
- 限列(queue)只能在表的一端(表尾)进行插入和在另一端(表头)进行删除操作的线性表
- 队尾(rear):允许插入的一端
- 队头(front):允许删除的另一端
- 先进先出( First In First Out 简称FIFO)表或者后进后出(LILO)线性表
-
- 逻辑结构:与同线性表相同,仍为一对一关系
- 存储结构:顺序队或链队,以循环顺序队列更常见
- 运算规则:只能在队首和队尾运算,且访问结点时依照先进先出(FIFO)的原则
- 实现方式:关键是掌握入队和出队的操作,具体实现依顺序队和链队的不同而不同
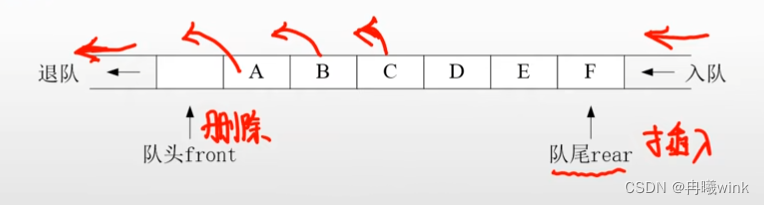
- 基本操作
- 入队运算:往队列的队尾插入一个元素,队尾指针rear的变化
- 例如:如果插入一个数据x,那么队尾指针rear则就指向新插入的元素x,以此类推为队尾指针rear的变换
- 退队运算:从队列的排头删除一个元素,队头指针front的变化
- 例如:如果删除一个数据x,那么队头指针front则就指向x的下一个元素,以此类推为队头指针front的变换
- 入队运算:往队列的队尾插入一个元素,队尾指针rear的变化
-
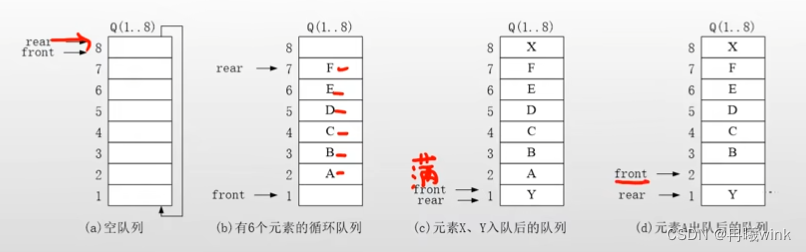
循环队列及其运算
备注:如图(b)已经插入数据ABCDEF,如果在基础上插入X和Y那么x则插入到8的位置,此时当下一个元素不能再插入时,则将rear队尾指针指向队头front的位置,构成循环队列,进行元素出队是front则由原来的地址1指向地址2并且释放空间
- 队列存储空间的最后一个位置绕到第一个位置,形成逻辑上的环状空间,供队列循环使用
- 入队运算:队尾指针加1,并当rear=m+1时置rear=1
- 出队运算:队头指针加1,并当front=m+1时置front=1
 案例引入
案例引入
- 进制转换:把十进制数159转换为八进制数

- 括号匹配的检验
- 假设表达式中允许存在两种括号:圆括号和方括号
- 其嵌套的顺序随意
例如:检验(()】)是否匹配

先入栈的后匹配,后入栈的先匹配
3.表达式求值
- 算符优先算法:运算符优先级确定运算顺序的对表达式求值算法
- 表达式的组成
- 操作符(operand):常数,变量
- 运算符(operator):算术运算符,关系运算符和逻辑运算符
- 界限符(delimiter):左右括弧和表达式结束符
- 任何一个算术表达式都又操作数(常数,变量),算术运算符(+,-,*,/)和界限符(括号,表达式结束符’#‘,虚设的表达式起始符’#‘)组成后两者统称为算符
例如:#3*(7-2)#
为了实现表达式求值。需要设置两个栈
- 一个是算符栈OPTR用于寄存运算符
- 另一个称为操作数栈OPND用于寄存运算数的运算结果
求值的处理过程是自左至右扫描表达式的每一个字符
- 当扫描到的是运算数,则将其压入栈OPND
- 当扫描到的是运算符时
- 若这个运算符比OPTR栈顶运算符的优先级高,则入栈OPTR,继续向后处理
- 若这个运算符比OPTR栈顶运算符优先级低,则从OPND栈中弹出两个运算数,从栈OPTR中弹出栈顶运算符进行运算,并将运算结果压入栈OPND
- 继续处理当前字符,直到遇到结束符为止















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









