







对应课程:Transformer简明教程, 从理论到代码实现到项目实战, NLP进阶必知必会._哔哩哔哩_bilibili
1.初识transformer结构
transformer的结构: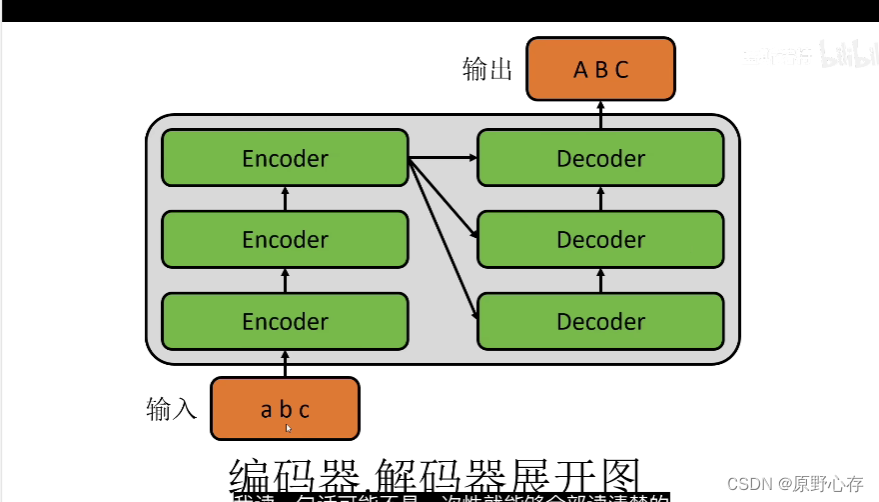
编码器解码器的内部结构:
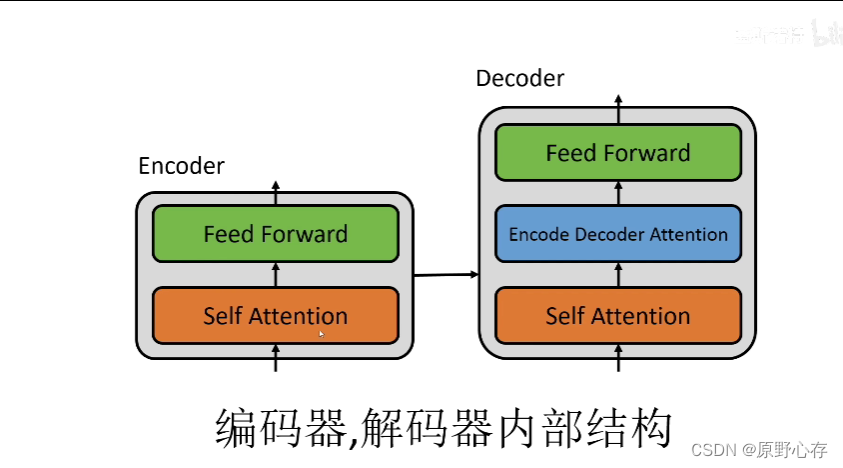
Self Attention 表示自注意力机制
Feed Forward 表示全连接层
2.计算注意力过程
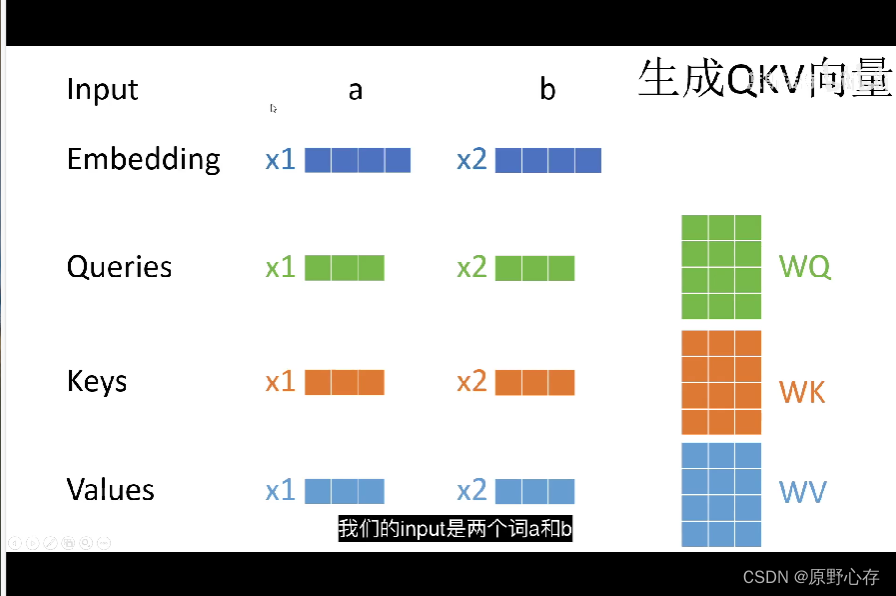
上图表示输入是两个词a,b。
Embedding表示将输入的两个词进行向量化为两个向量x1和x2。注意:通过图片的给出的向量x1和向量x2发现。两个向量都是一个一行四列的矩阵,这个结论很重要,会与后期的注意力计算机制相联系。
通过图片中的右下角位置,发现一共有三个变量WQ\WK\WV,且三个变量都是四行三列的矩阵。当输入的数据向量化得到的矩阵与之相乘的结果,就是一个一行三列的矩阵。即分别对应着:Queries\Keys\Values三个变量。计算得到的这三个变量很重要,因为将由这三个向量计算整个模型中的注意力机制。后面会将这三个向量简称为q,k,v。
3.自注意力向量形式计算的过程

上图表示的含义为:
①此时输入的Thinking 和Machines。通过将输入的词进行向量化后得到对应的向量化表示x1,x2。然后将向量化表示的变量分别乘以对应的WQ,WK,WV得到对应的q1,k1,v1。
②上图中用黑线画出的部分就是计算Thinking的自注意力。首先是计算score,计算方式是Thinking的q1,分别乘以k1和k2(这里在计算的过程中,应该涉及到聚举证的转置),得到数值分别为112和96。
③计算score完成后,然后将计算得到的数值。除以8,分别得到14和12。
除以8,详细解析?——与词向量编码相关
④然后将除以8的到的结果,通过softmax激活函数处理,得到两个小数为0.88和0.12。 ⑤然后将softmax处理后的结果,分别与输入向量的v相乘。得到两个新的v1和v2向量。
⑥最后将两个新的v1、v2向量进行相加,得到向量z1=0.88v1+0.12v2。且这个变量z就是自注意力计算的结果。
4.自注意力的矩阵形式计算过程
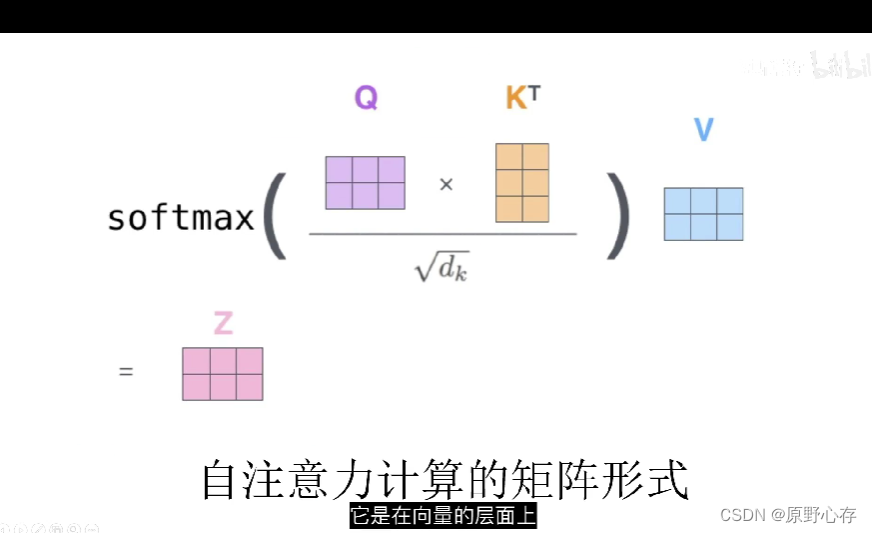
简单讲解:
即q和k的转置进行点积运算,然后除以dk的算术平方根。最后将计算的结果经过softmax函数处理,乘以v就得到z。
5.单头注意力机制和多头注意力机制
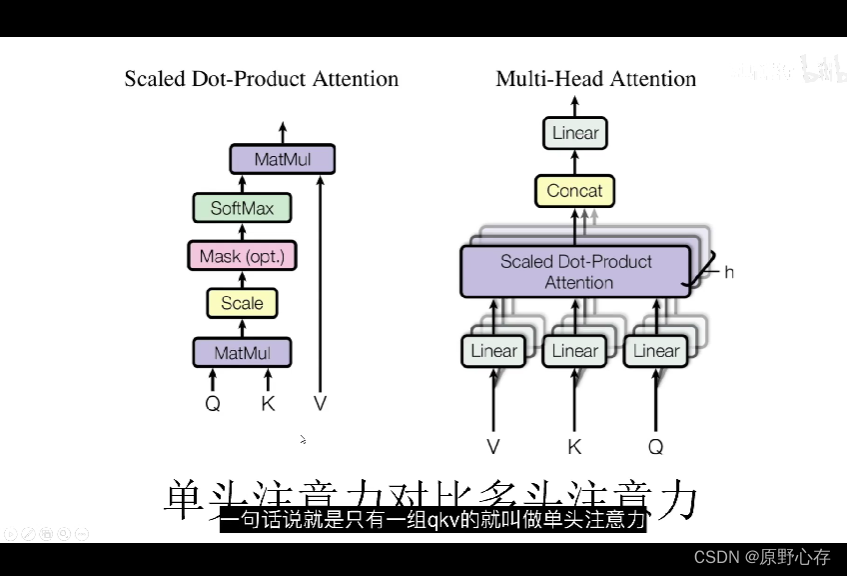
简单理解单头注意力机制和多头注意力机制:
单头注意力机制只有一组q,k,v。(q,k,v是输入数据经过向量化处理后与三个矩阵相乘后得到的向量。)
多头注意力机制有多组q,k,v。(根据多头注意力机制的定义:我们可以知道多头注意力机制,则应该对应着多组向量。且一组向量对应着三个计算qkv向量的矩阵),然后将计算得到的多个向量q,k,v通过concat组合到一起。
6.多头注意力机制的详细计算过程
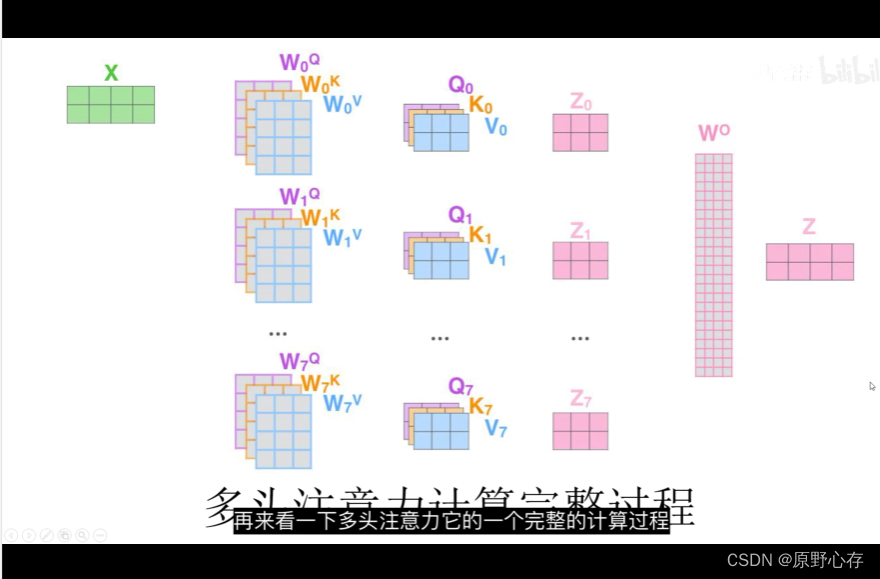
上图中第二列中我们可以发现:参与计算q,k,v的矩阵是叠加在一起的。而且有8组。所以根据前文介绍的知识,可以知道计算的结果就会对应着八个不同的q,k,v向量。也对应着八组自注意力计算结果。然后通过线性运算wo,将得到八组自注意力机制计算结果进行组合,得到最后的注意力结果z。
7.词向量编码
transformer在进行词向量编码的时候,会向数据中加入位置信息,从而使得transformer神经网络可以区分不同位置的相同数据。

上图是transformer进行词向量编码的过程:
就是现将输入的数据进行编码,然后再将输入数据的位置信息,也对应的生成一个位置向量,最后将位置编码和输入信息编码进行相加就得到了最后的输入数据编码。
8.位置编码矩阵元素计算公式

上述公式解释:
PE是一个很大的矩阵,然后pos表示是第几个词(表示矩阵的行数)。i表示词向量编码之后的第i个向量(表示矩阵的列数)。
上述两个公式区别:
第一个公式计算偶数列数据
第二个公式计算奇数类数据
9.mask相关知识点

PAD MASK不计算针对PAS的注意力。
通过上述的图片我们可以看到第一行的数据为:ab<pad> ,第1列的内容为:
ab<pad>我们将第一行和第一列的内容都看成是一句话。在实际的运算的时候是多句话一起计算的。在多句话的计算过程中,可能出现的问题是句子的长短不一。为了统一计算,我们需要将每句话的长度进行统一。具体的做法为:将短的句子进行补长。上述的例子中,我们是将一个句子的长度扩充为3。
在计算的时候每个词对pad的注意力都是mask,但是pad对其他词的注意力,正常计算。
以上就是pad mask方式计算注意力的过程。

上三角mask计算注意力的关键:不计算对未来词的注意力
解释上图:
当计算对a的注意力的时候,不关注其他的词。因为b和c是需要让a进行预测的结果。即解码器中的一个计算,需要根据a预测出b和c这个结果。如果让a关注到b这不能起到预测的作用,因为会直接得到结果。
同样在计算b的注意力的时候:不能让b关注c,因为在transformer中的阶码器阶段需要根据b预测c。

上图是整合上三角mask和padmask的计算注意力方式。
10.transformer的完整计算流程
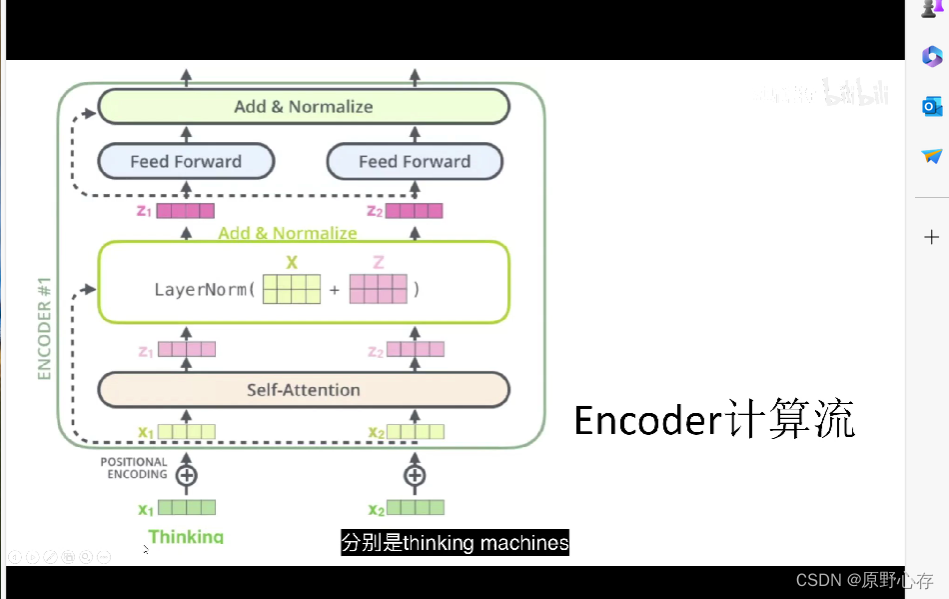
上图是transformer的encorder计算过程。
表中的计算流程前面基本已经介绍完成。
LayerNorm部分表示短接:简单的理解为将xi和zi进行相加。
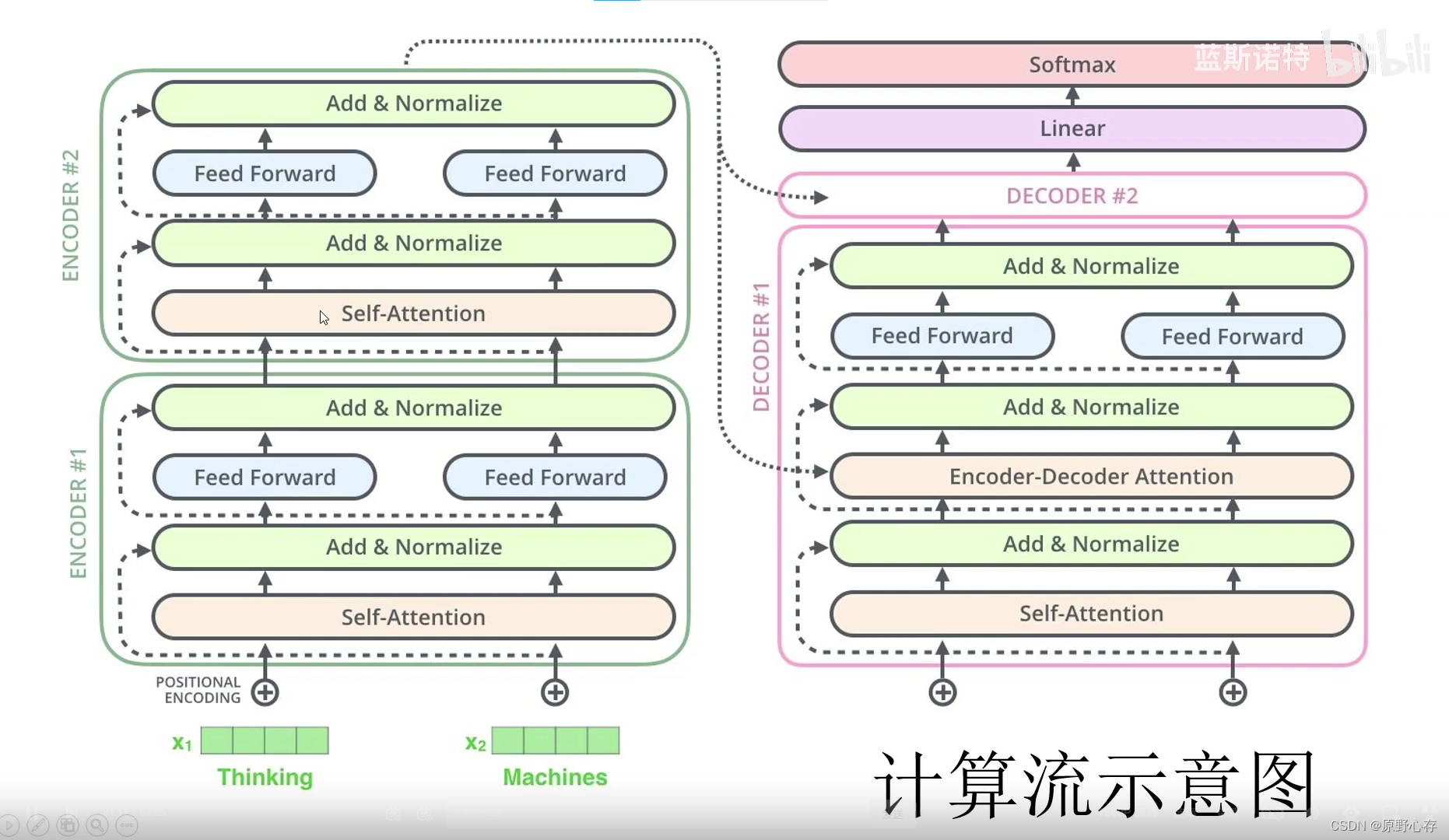
在实际的transformer网络中encoder不只一个,可能存在n个encoder,这n个encoder之间是上下串联的关系。然后将最后计算的结果输出到decoder中计算。
decoder的过程与encoder部分基本相似。不同点在于:encoder decoder attention的计算是的k,v是encode的计算结果。然后自己的encode 输出的结果作为q。然后通过短接,然后通过全连接层处理。decoder有多个,多个decoder是串联关系。将经过多个decoder计算的结果,使用线性方程(softmax)处理输出预测结果。
11.transformer实战代码
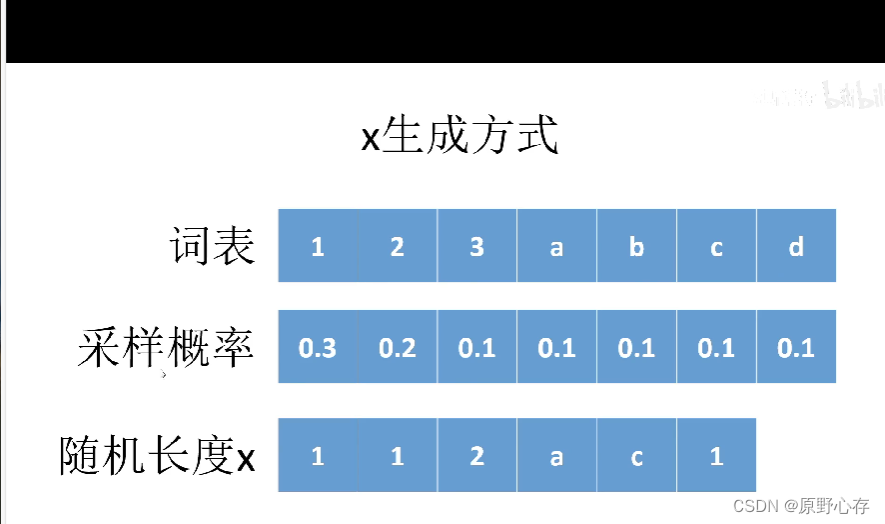
x表示一种语言,其中x语言中的所有词汇如词表中显示。结合实际生活,我们发现在生活中每个词语的使用频率是不同的,所以在x语言中每个词语对应的使用频率也是不一样的。x语言的每个词语对应的使用频率如采样频率显示一一对应。
上图中“随机长度x”表示的是用x语言组织的一句话。
在本次transformer实战中,我们需要实现的目的是:将x语言翻译成另外一种语言y。
结合生活实际:我们之所以能将中文翻译成英文,是因为两种语言之间存在某种联系。
所以在实现将x语言转换为y语言的时候,也会有着对应的关系:

通过上图展示内容:我们可以发现,y语言中是x语言逆序以后的结果,而且将x语言中的小写字母变为大写字母。且用10减去x中的数字。同时根据虚线所指的方法发现,y语言的第一位字母取决于x的最后一位。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









