







以悬崖困境为基础,构建三维网格地图环境,以agent(自主式水下潜器Autonomous Underwater Vehicle,简称AUV)为运动物。AUV的动作空间自行设置(离散运动空间、连续运动空间均可),动作空间维度自行设定,但不得小于4维(上下前后左右)。请结合运动时间、运动成本、安全风险等实际因素进行考量,设计合理的奖励函数。
完成下面问题:障碍物固定,出发、目的地固定,使用DRL方法训练agent到达目的地
目录
1、准备工作——环境设计
3.1运动环境的设计
3.1.1主要组件
(1)网格地图:三维网格地图,大小为10x10x10。每个单元格表示一个可供AUV运动的位置
(2)AUV(自主水下航行器):在网格地图中运动的代理,负责执行一系列动作以到达目标位置
(3)障碍物:固定设置在地图中的若干障碍物点,AUV不能穿越这些点
(4)起点和终点:从预定义的四个点集中随机选择的起点和终点,确保每次训练的起点和终点有所不同
(5)奖励机制:定义每个状态转移所获得的奖励,用于指导AUV的学习和决策
3.1.2环境操作
(1)初始化:在每个训练回合开始时,环境会随机选择起点和终点,并重置AUV到起点位置
(2)状态转移:根据AUV选择的动作更新其位置,如果AUV选择的动作会导致其进入障碍物或越界,则该动作无效,AUV保持原地不动
(3)动作执行:AUV可以选择六个离散动作中的一个(向上、向下、向前、向后、向左、向右),每个动作会尝试改变其在网格中的位置
(4)检测终止条件:每一步执行后,检查AUV是否到达终点,如果到达终点,则本回合结束
3.1.3奖励机制
(1)到达终点奖励:如果AUV到达终点,给予高额奖励(500分),鼓励AUV尽快到达目标
(2)碰撞惩罚:如果AUV碰到障碍物,给予一定的惩罚(-10分),使AUV学会避开障碍物
(3)移动惩罚:每次移动都给予微小惩罚(-1分),以促使AUV尽快到达终点,避免无效移动
3.2运动空间的设计
3.2.1动作空间设计——离散型:
(1)动作空间定义:动作空间由六个离散动作组成,分别为向上、向下、向前、向后、向左、向右
(2)动作表示:每个动作用一个整数表示,例如:0表示向上,1表示向下,2表示向前,3表示向后,4表示向左,5表示向右
(3)动作约束:每个动作都有边界条件和障碍物检查,确保AUV在执行动作后不会越界或穿越障碍物
3.2.2状态空间设计——连续型:
(1)状态空间定义:状态空间由AUV在网格中的位置组成,每个位置用三维坐标表示(x, y, z)
(2)状态表示:当前状态用AUV的当前位置坐标表示,例如:(x, y, z)
(3)状态转换:根据AUV执行的动作,状态会发生相应的变化,新的状态由新的坐标表示
2、算法设计
2.1网络架构
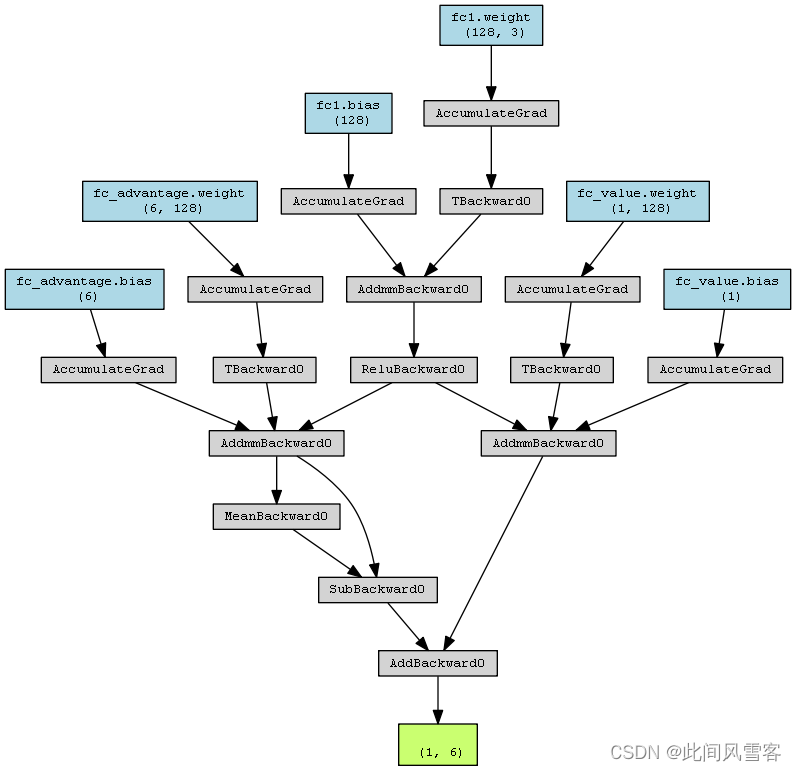
网络架构是Dueling DQN模型,用于在三维网格环境中训练AUV代理。
(1)输入和输出:
输入:三维状态(3个维度表示位置:x, y, z)
输出:六个离散动作的Q值(上下、前后、左右)
(2)网络层次:
①输入层:3个输入节点,对应状态的三个维度(x, y, z)。
②隐藏层:一个全连接层(Fully Connected Layer),包含128个神经元,激活函数为ReLU。
③分支层:
价值分支(Value Stream):全连接层,输出单一值(状态价值)。
优势分支(Advantage Stream):全连接层,输出每个动作的优势值(6个动作)
④输出层:价值分支与优势分支的组合,用于计算每个动作的Q值
2.2算法流程
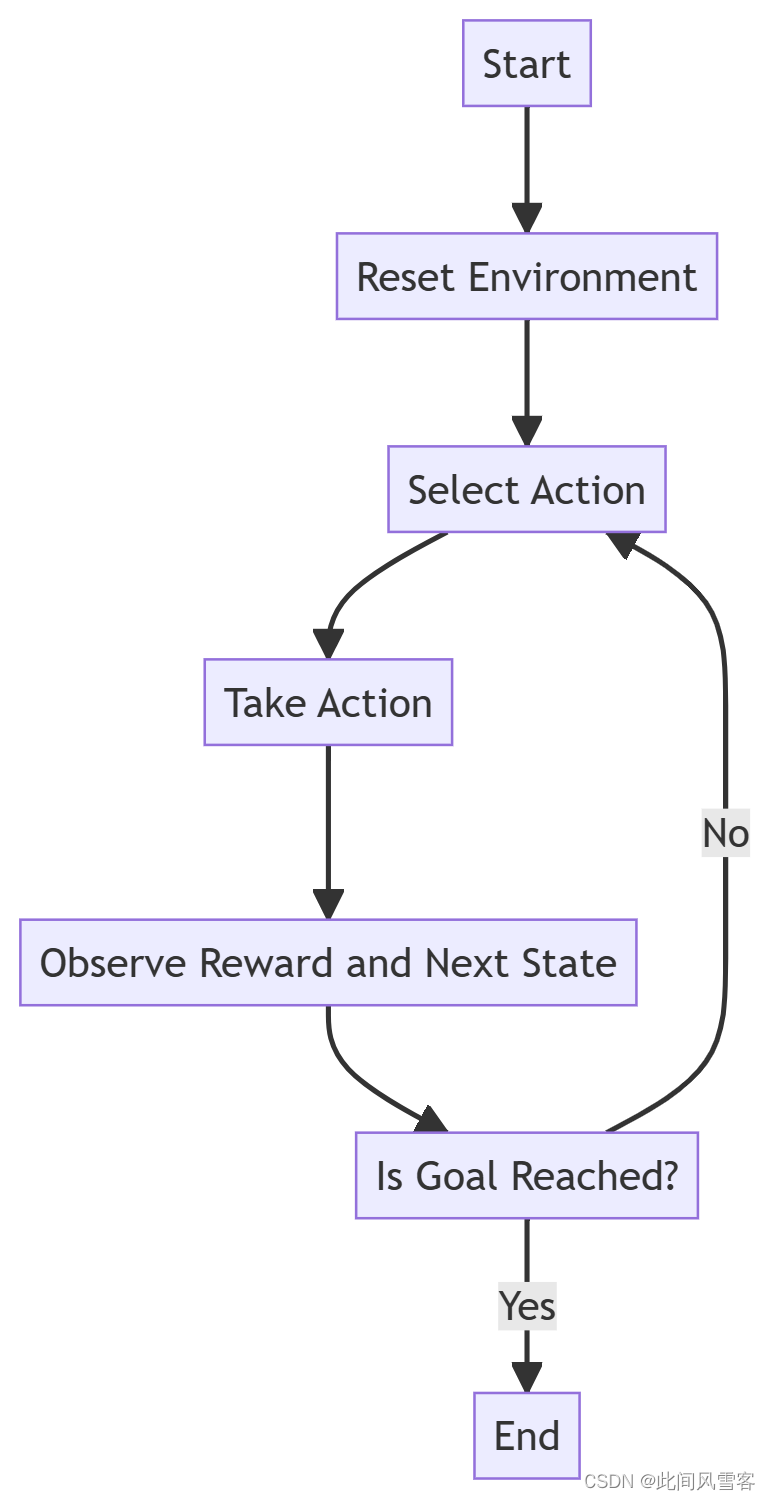
(1)环境初始化:
①定义三维网格环境,包含固定障碍物
②随机选择起点和终点,从预定义的点集中选择
(2)Dueling DQN网络:
①构建Dueling DQN网络,包括输入层、隐藏层、价值分支和优势分支
②价值分支输出单一值,优势分支输出每个动作的优势值,最终组合得到Q值
(3)经验回放:
使用Replay Memory存储经验样本,随机采样用于训练
(4)代理选择动作:
使用epsilon-greedy策略选择动作:以一定概率选择最优动作,其他情况下随机选择
(5)优化模型:
从Replay Memory中采样小批量样本,计算损失函数并反向传播优化网络
(6)训练过程:
①运行多个回合,每回合进行多个步骤
②记录每个回合的得分和步数
③每10个回合输出一次训练数据
(7)预测和绘图:
①使用训练好的模型进行路径预测
②绘制AUV从起点到终点的三维路径
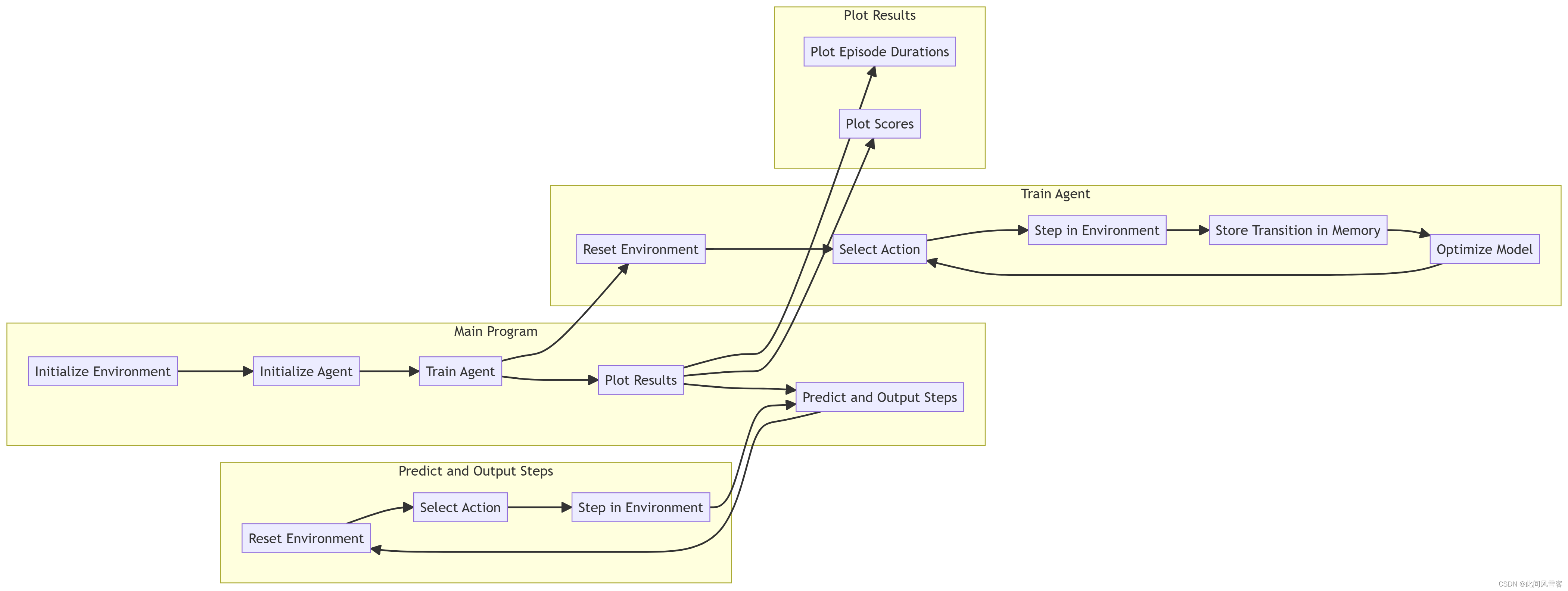
2.3算法伪代码
| Algorithm: Dueling Deep Q-Learning with Experience Replay |
| 1. Initialize the replay memory D to capacity N 2. Initialize the action-value function Q with random weights 3. Initialize the target action-value function Q- with weights θ^- = θ (identical to Q initially) 4. For episode = 1 to M do a. Initialize sequence s1 = [x1] and preprocessed sequence φ1 = φ(s1) b. For t = 1 to T do i. With probability ε, select a random action at ii. Otherwise, select at = argmaxa[Q(φ(st), a; θ)] (select action with highest Q-value) iii. Execute action at in emulator and observe reward rt and image xt+1 iv. Set st+1 = (st, at, xt+1) and preprocess φt+1 = φ(st+1) v. Store transition (φt, at, rt, φt+1) in D vi. Sample a random minibatch of transitions (φj, aj, rj, φj+1) from D vii. If episode terminates at step j+1, set yj = rj viii. Otherwise, calculate the target value: yj = rj + γ * max(Q-(φj+1, a'; θ^-) - b(φj+1)) where b(φj+1) = 1/|A| * Σ A(s, a; θ^adv) ix. Perform a gradient descent step on (yj - Q(φj, aj; θ)) with respect to the network parameters θ x. Every C steps reset Q- = Q (synchronize target network with the main network) c. End For (end of episode) 5. End For (end of all episodes) |
2.3Dueling DQN类的定义
class DuelingDQN(nn.Module):
def __init__(self, input_dim, output_dim):
super(DuelingDQN, self).__init__()
self.fc1 = nn.Linear(input_dim, NUM_HIDDEN)
self.fc_value = nn.Linear(NUM_HIDDEN, 1)
self.fc_advantage = nn.Linear(NUM_HIDDEN, output_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
value = self.fc_value(x)
advantage = self.fc_advantage(x)
return value + (advantage - advantage.mean())3、结果展示
本次训练要求起始点和终点固定,同时障碍物固定,因此并不需要非常大的训练量,但是为了能够在训练结果图上更加直观的看到收敛等相关信息,故将训练次数设置为1000,将最大运动次数设置为500;本次训练起止点分别为(0,0,0),(9,9,9)。为了更加清晰看出运动体的运动路径,这里采用不同颜色标记不同运动步,结果如下图所示;
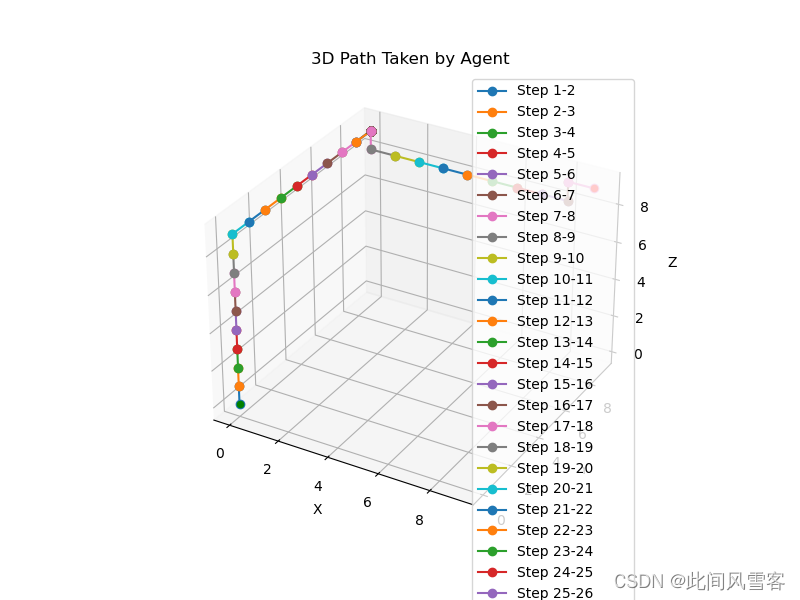
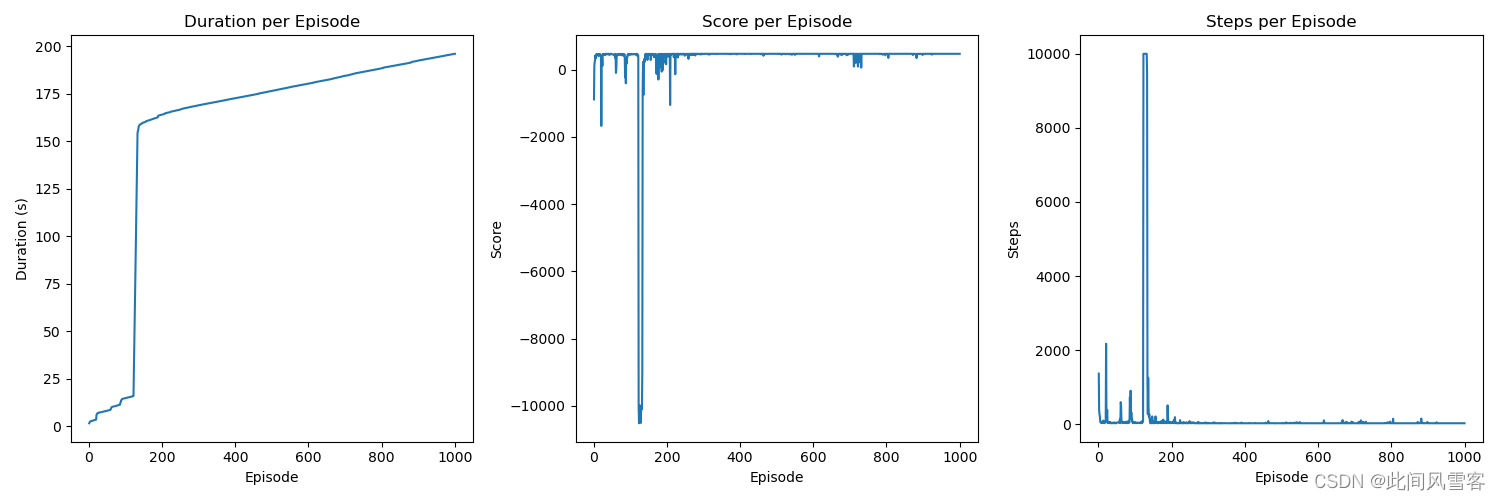
(1)持续时间(Duration per Episode):
持续时间图表显示了每个训练周期的持续时长,从图中可见,尽管存在波动,即在训练次数为200左右时,训练时间有较大波动,可能是因为程序训练达到饱和;但整体上没有明显上升或下降的趋势,表明训练的持续时间在各个周期间保持相对稳定;
(2)得分(Score per Episode):
得分图表反映了智能体在每个训练周期中的性能得分,可以看出初始得分较低,但随着训练的进行,得分逐渐提升,显示出智能体通过学习过程在不断优化其行为策略;
(3)步数(Steps per Episode):
步数图表记录了智能体在每个训练周期中所采取的步数,初期波动较大,但随着周期的增加,步数趋于稳定,这可能意味着智能体开始采取更加直接有效的路径来达到目标;
综合图表信息和训练设置,可以看出智能体在经过多次训练后,其性能在逐步提升,表现在得分的增加和步数的稳定化上,这符合强化学习中通过与环境交互不断优化行为策略的预期。
完整代码
import numpy as np
import random
import time
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
# Constants
GRID_SIZE = 10
NUM_EPISODES = 1000
MAX_STEPS = 10000
BATCH_SIZE = 32
EPSILON_START = 1.0
EPSILON_END = 0.01
EPSILON_DECAY = 0.995
GAMMA = 0.99
TARGET_UPDATE = 10
LR = 0.001
REPLAY_MEMORY_SIZE = 10000
NUM_HIDDEN = 128
# Define AUV environment
class Environment:
def __init__(self):
self.grid_size = GRID_SIZE
self.start = (0, 0, 0)
self.goal = (GRID_SIZE - 1, GRID_SIZE - 1, GRID_SIZE - 1)
self.obstacles = [(5, 5, 5), (2, 3, 4), (8, 8, 8)] # Example obstacles
def reset(self):
self.state = self.start
return self.state
def step(self, action):
x, y, z = self.state
# Determine the next state based on the action
if action == 0: # Move up
next_state = (x, y + 1, z) if y < self.grid_size - 1 else (x, y, z)
elif action == 1: # Move down
next_state = (x, y - 1, z) if y > 0 else (x, y, z)
elif action == 2: # Move forward
next_state = (x + 1, y, z) if x < self.grid_size - 1 else (x, y, z)
elif action == 3: # Move backward
next_state = (x - 1, y, z) if x > 0 else (x, y, z)
elif action == 4: # Move left
next_state = (x, y, z - 1) if z > 0 else (x, y, z)
elif action == 5: # Move right
next_state = (x, y, z + 1) if z < self.grid_size - 1 else (x, y, z)
else:
raise ValueError("Invalid action")
# Check for obstacles and adjust if needed
if next_state in self.obstacles:
reward = -10
next_state = self.state # Stay in the same place if obstacle encountered
elif next_state[0] < 0 or next_state[0] >= self.grid_size or \
next_state[1] < 0 or next_state[1] >= self.grid_size or \
next_state[2] < 0 or next_state[2] >= self.grid_size:
reward = -10 # Penalty for going out of bounds
next_state = self.state # Stay in the same place if out of bounds
else:
reward = -1
# Check if reached the goal
done = next_state == self.goal
if done:
reward = 500
self.state = next_state
return next_state, reward, done
# Dueling DQN network
class DuelingDQN(nn.Module):
def __init__(self, input_dim, output_dim):
super(DuelingDQN, self).__init__()
self.fc1 = nn.Linear(input_dim, NUM_HIDDEN)
self.fc_value = nn.Linear(NUM_HIDDEN, 1)
self.fc_advantage = nn.Linear(NUM_HIDDEN, output_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
value = self.fc_value(x)
advantage = self.fc_advantage(x)
return value + (advantage - advantage.mean())
# Replay memory
class ReplayMemory:
def __init__(self, capacity):
self.capacity = capacity
self.memory = []
def push(self, transition):
self.memory.append(transition)
if len(self.memory) > self.capacity:
del self.memory[0]
def sample(self, batch_size):
return random.sample(self.memory, batch_size)
def __len__(self):
return len(self.memory)
# Agent class
class Agent:
def __init__(self, env):
self.env = env
self.epsilon = EPSILON_START
self.policy_net = DuelingDQN(3, 6) # 3-dimensional state, 6 actions
self.target_net = DuelingDQN(3, 6)
self.target_net.load_state_dict(self.policy_net.state_dict())
self.target_net.eval()
self.optimizer = optim.Adam(self.policy_net.parameters(), lr=LR)
self.memory = ReplayMemory(REPLAY_MEMORY_SIZE)
self.steps_done = 0
def select_action(self, state):
sample = random.random()
self.epsilon = EPSILON_END + (EPSILON_START - EPSILON_END) * np.exp(-1.0 * self.steps_done / EPSILON_DECAY)
self.steps_done += 1
if sample > self.epsilon:
with torch.no_grad():
q_values = self.policy_net(torch.tensor(state, dtype=torch.float32))
action = torch.argmax(q_values).item()
else:
action = random.randint(0, 5)
return action
def optimize_model(self):
if len(self.memory) < BATCH_SIZE:
return
transitions = self.memory.sample(BATCH_SIZE)
batch = list(zip(*transitions))
state_batch = torch.tensor(batch[0], dtype=torch.float32)
action_batch = torch.tensor(batch[1], dtype=torch.long).view(-1, 1)
reward_batch = torch.tensor(batch[2], dtype=torch.float32)
next_state_batch = torch.tensor(batch[3], dtype=torch.float32)
done_batch = torch.tensor(batch[4], dtype=torch.float32) # Convert to float
state_action_values = self.policy_net(state_batch).gather(1, action_batch)
with torch.no_grad():
next_state_values = self.target_net(next_state_batch).max(1)[0].detach()
expected_state_action_values = reward_batch + (
1.0 - done_batch) * GAMMA * next_state_values # Ensure 1.0 instead of 1
loss = nn.functional.mse_loss(state_action_values, expected_state_action_values.unsqueeze(1))
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
def update_target_model(self):
if self.steps_done % TARGET_UPDATE == 0:
self.target_net.load_state_dict(self.policy_net.state_dict())
# Training function
def train(agent):
episode_durations = []
scores = []
steps_list = []
start_time = time.time()
for episode in range(NUM_EPISODES):
state = env.reset()
steps = 0
score = 0
for t in range(MAX_STEPS):
action = agent.select_action(state)
next_state, reward, done = env.step(action)
agent.memory.push((state, action, reward, next_state, done))
agent.optimize_model()
agent.update_target_model()
state = next_state
score += reward
steps += 1
if done or t == MAX_STEPS - 1:
episode_durations.append(time.time() - start_time)
scores.append(score)
steps_list.append(steps)
if (episode + 1) % 10 == 0:
print(f"Episode {episode + 1}, Steps: {steps}, Time: {episode_durations[-1]:.2f}s, Score: {score}")
break
return episode_durations, scores, steps_list
# Function to plot 3D path
def plot_3d_path(path):
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
# Unpack path into x, y, z coordinates
x, y, z = zip(*path)
# Plot path with different colors
for i in range(len(x) - 1):
ax.plot([x[i], x[i + 1]], [y[i], y[i + 1]], [z[i], z[i + 1]], marker='o', color=f'C{i}',
label=f'Step {i + 1}-{i + 2}')
# Mark start and goal points
ax.scatter(x[0], y[0], z[0], marker='o', color='g', label='Start')
ax.scatter(x[-1], y[-1], z[-1], marker='o', color='r', label='Goal')
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_zlabel('Z')
ax.legend()
ax.set_title('3D Path Taken by Agent')
plt.savefig('q1/path.png')
plt.close()
# Initialize environment and agent
env = Environment()
agent = Agent(env)
# Train the agent
episode_durations, scores, steps_list = train(agent)
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
plt.plot(range(1, NUM_EPISODES + 1), episode_durations)
plt.xlabel('Episode')
plt.ylabel('Duration (s)')
plt.title('Duration per Episode')
plt.subplot(1, 3, 2)
plt.plot(range(1, NUM_EPISODES + 1), scores)
plt.xlabel('Episode')
plt.ylabel('Score')
plt.title('Score per Episode')
plt.subplot(1, 3, 3)
plt.plot(range(1, NUM_EPISODES + 1), steps_list)
plt.xlabel('Episode')
plt.ylabel('Steps')
plt.title('Steps per Episode')
plt.tight_layout()
plt.savefig('q1/score_episodes.png')
plt.close()
'''# Predict and output movement steps
state = env.reset()
steps = 0
path = [state]
while state != env.goal:
action = agent.select_action(state)
next_state, _, _ = env.step(action)
state = next_state
path.append(state)
steps += 1
print(f"Steps taken to reach the goal: {steps}")
# Plot the 3D path
plot_3d_path(path)'''















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









