







在深度学习的训练过程中,train loss(训练损失)和val loss(验证损失)的关系是衡量模型性能的重要指标。以下是一些常见的分析和解释:
1. 训练过程中的损失趋势
- 初期阶段:在训练开始时,
train loss和val loss都会较高,随着训练的进行,它们应该逐渐下降。 - 稳定阶段:经过一段时间的训练后,
train loss和val loss会趋于平稳。如果模型训练得当,val loss应该与train loss接近,但略高于train loss。
2. 模型是否过拟合
- 过拟合:当
train loss持续下降并且非常低,但val loss却开始上升时,说明模型开始过拟合。这意味着模型在训练数据上表现很好,但在未见过的数据上泛化能力差。 - 欠拟合:如果
train loss和val loss都很高并且没有明显的下降趋势,说明模型欠拟合,可能是因为模型太简单,无法捕捉数据的复杂模式。
3. 如何判断模型的好坏
- 损失收敛:理想情况下,
train loss和val loss会同时下降并最终趋于稳定。如果两者在某个点趋于稳定,并且差距不大,说明模型训练良好。 - 过拟合的解决方法:
- 使用正则化技术(如 L2 正则化、Dropout)
- 提供更多的训练数据
- 使用数据增强技术(Data Augmentation)
4. 损失曲线分析
- 训练损失曲线:反映模型在训练数据上的表现,通常会逐渐下降并趋于稳定。
- 验证损失曲线:反映模型在验证数据上的表现,理想情况下也会逐渐下降并趋于稳定。如果验证损失曲线在一段时间后开始上升,通常意味着过拟合。
5、示例图示
假设我们有一个模型训练过程中的 train loss 和 val loss 曲线:
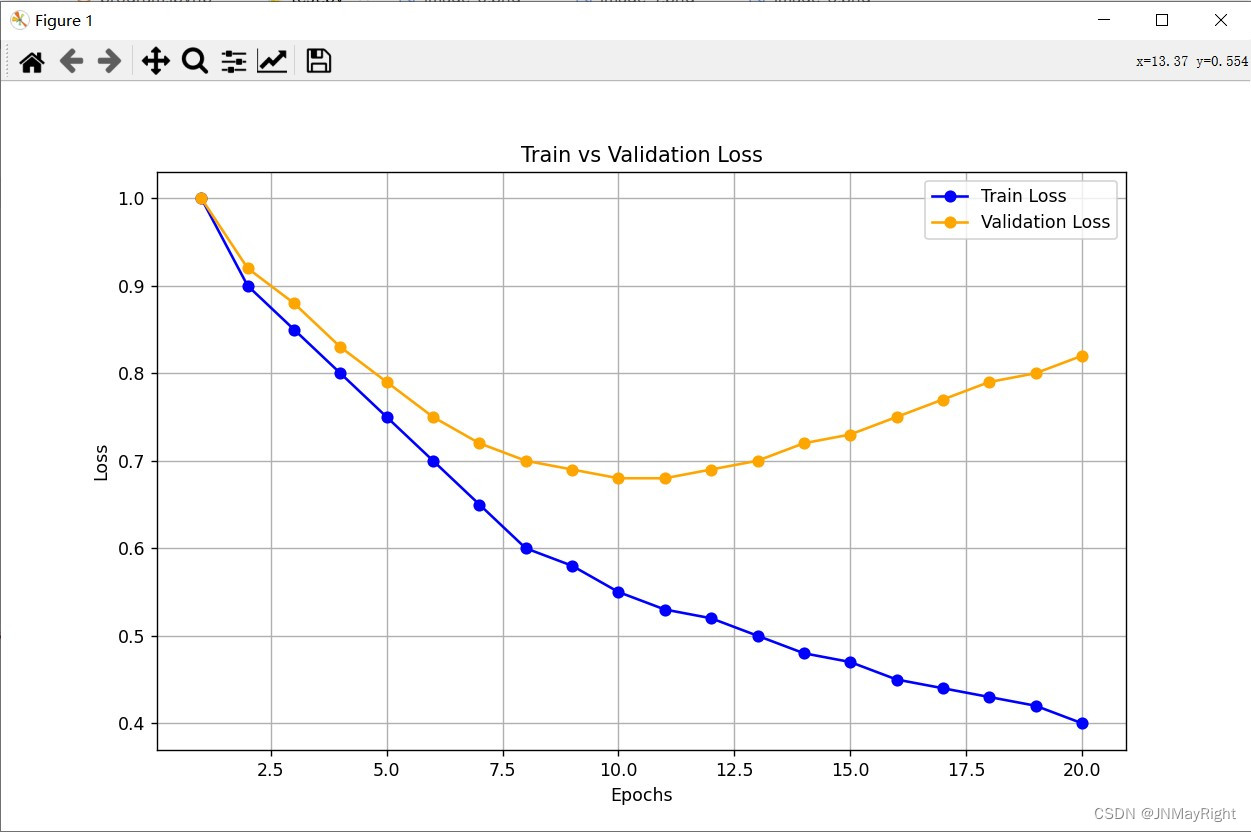
- 蓝色线(train loss):逐渐下降并趋于稳定。
- 橙色线(val loss):先下降,然后在一定程度上上升,说明模型开始过拟合。
6、总结
分析 train loss 和 val loss 的关系可以帮助我们判断模型是否训练良好、是否存在过拟合或欠拟合,并采取相应措施来改进模型的性能。通过仔细观察损失曲线的变化趋势,可以指导我们调整模型参数、优化训练过程,从而提高模型的泛化能力和整体性能。

















 6239
6239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









