







目录
一、准备工作
1.1数据集来源
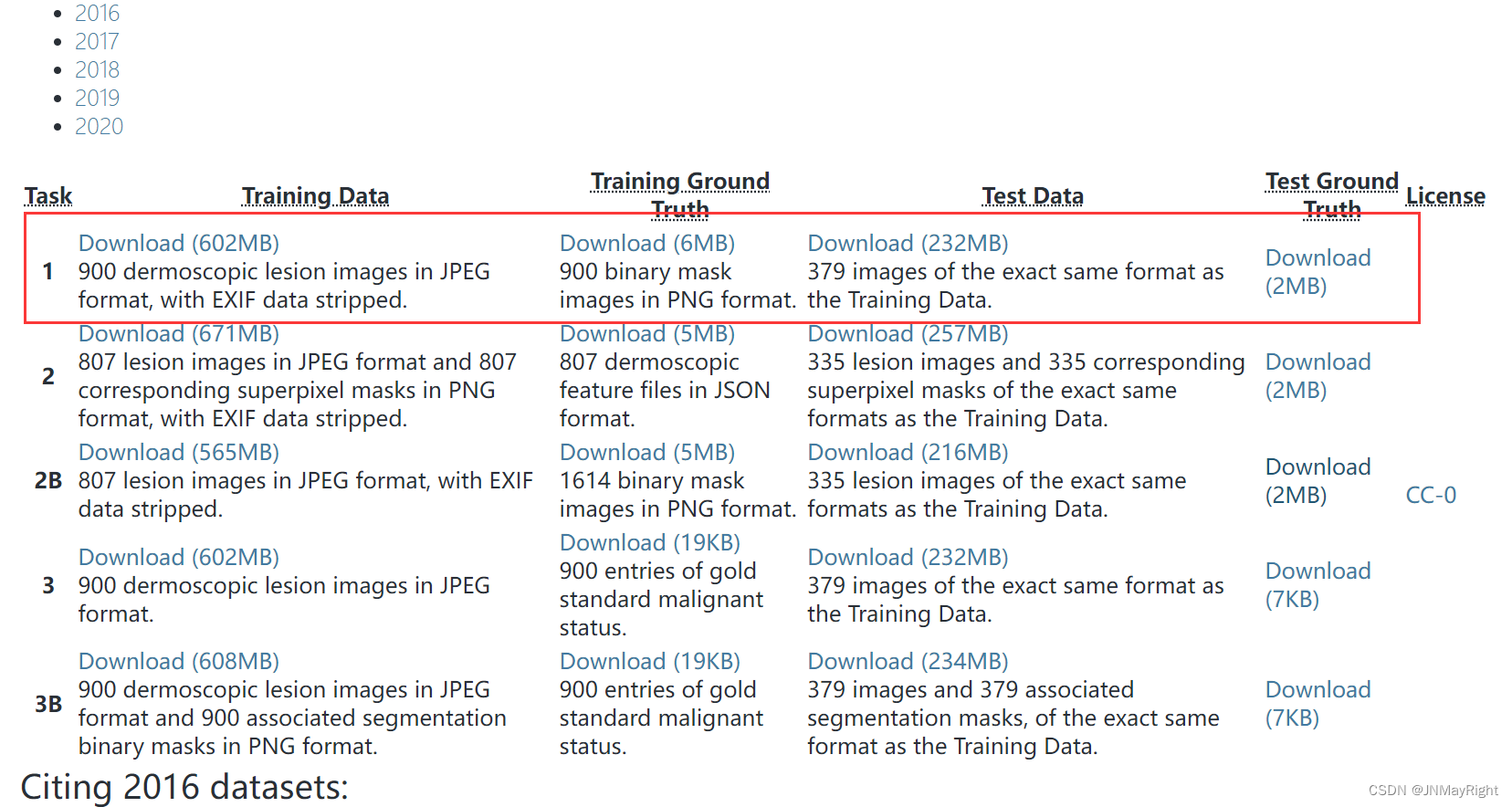
利用ISIC2016数据集挑战皮肤图像分割。官网下载数据集地址为https://challenge.isic-archive.com/data/ 的第一行,如下图所示。
 1.2模型来源
1.2模型来源
利用Pytorch的deeplabv3_resnet101模型进行图像分割;官网下载:模型下载地址为deeplabv3_resnet101 — Torchvision main documentation (pytorch.org);
百度网盘下载(包含ISIC2016数据集和预训练模型):链接:https://pan.baidu.com/s/1UqNNvv4WCnZUU7LcF14zlA
提取码:jnyy
二、模型简介
DeeplabV3+被认为是语义分割的新高峰,主要是因为这个模型的效果非常的好。DeepLabv3+主要在模型的架构上作文章,为了融合多尺度信息,其引入了语义分割常用的encoder-decoder形式。在 encoder-decoder 架构中,引入可任意控制编码器提取特征的分辨率,通过空洞卷积平衡精度和耗时。
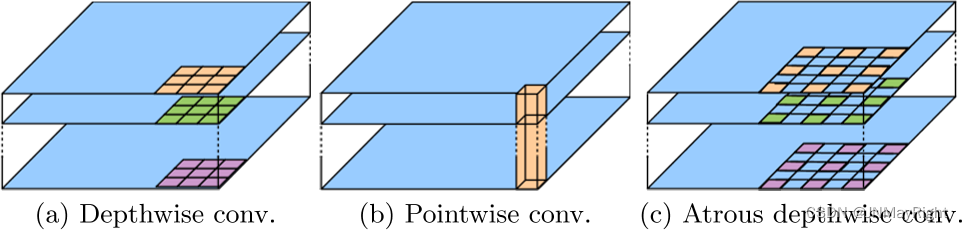
DeeplabV3+与pspnet、segnet、unet相比,其最大的特点就是引入了空洞卷积,在不损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。如下就是空洞卷积的一个示意图,所谓空洞就是特征点提取的时候会跨像素;
2.1Encoder-Decoder部分
空洞卷积(Atrous Convolution)的目的是为了在不增加参数量的情况下扩展卷积的感受野,从而提取更有效的特征,因此它位于Encoder网络中用于特征提取。在这一部分有两个核心点:
在主干DCNN(深度卷积神经网络)里使用串行的Atrous Convolution: 串行的意思是一层接一层,普通的深度卷积神经网络的结构就是串行结构。通过在主干DCNN中使用串行的Atrous Convolution,网络能够有效地扩大感受野而不增加计算成本。这样可以捕捉到更多的上下文信息,有助于更精确的特征提取。例如,传统的卷积核可能只能看到局部的小区域,而经过Atrous Convolution处理的卷积核可以看到更大的区域。
将主干DCNN输出的结果分为两部分:一部分直接传入Decoder。这样可以保证原始的特征信息不丢失,直接用于后续的分割任务。另一部分经过并行的Atrous Convolution处理。具体来说,这部分输出会通过多个不同rate(膨胀率)的Atrous Convolution进行特征提取。不同的rate可以捕捉到不同尺度的特征信息。然后将这些提取到的特征进行合并,再通过一个1x1卷积层进行特征维度的压缩。这一步的目的是整合不同尺度的信息,形成更加丰富的特征表示。
Decoder部分的输入有两部分:
DCNN的直接输出:这个部分保留了原始的特征信息,确保了分割任务所需的基本信息不丢失。
DCNN输出经过并行空洞卷积后的结果:这一部分经过不同rate的空洞卷积处理后,提供了不同尺度的上下文信息。这些信息经过整合后,可以增强分割的准确性。
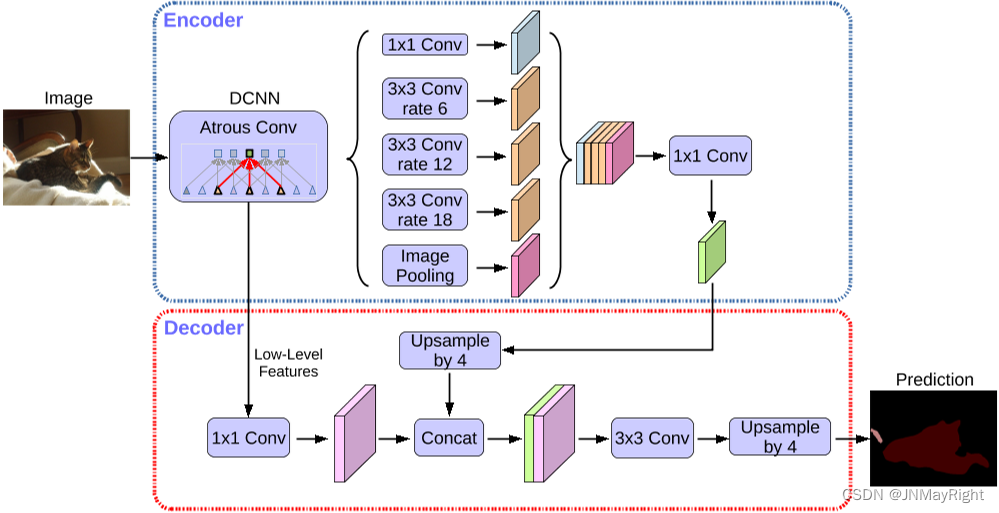
这两个部分的结果经过一定的处理后进行Concat(拼接)在一起。在DeepLabv3中,Upsample(上采样)的方式是使用双线性插值(bilinear interpolation)。双线性插值是一种常见的图像
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 959
959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









