







一、基础知识
一句话概括,K-means方法是一种非监督学习的算法,它解决的是聚类问题;
其划分方法的基本思想是:给定一个有N个元组或者记录的数据集,将数据集依据样本之间的距离进行迭代分裂,划分为K个簇,其中每个簇至少包含一条实验数据。

二、作业练习
使用protein.txt文件内数据做k-means聚类的过程验证练习,要求:
1. 在答题区提交程序脚本,并将聚类结果储存在向量(kmeans.result.学号)中;
2. 在答题区提交聚类结果和Calinski-Harabaz score值的可视化输出(贴图);
# 内容:Kmeans聚类分析的作业(使用数据protein.txt做k-means聚类的过程验证练习)
# 编写者:LWW
# step01:数据导入
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import os
os.chdir(r'd:\soft\python\PythonProject\数据科学导论\K-means\数据集')
print(os.getcwd())
# 将当前工作目录中的数据文件 protein.txt 读入(使用pd.read_table()方法)至 Pandas数据protein中
protein = pd.read_table('protein.txt', header=0)
# 查看数据
print(protein) # [25 rows x 10 columns]
# redMeat = protein['RedMeat'] # 这样的数据K-Means函数是不能进行计算的,我们需要对数据进行处理
# redMeat = [[i] for i in redMeat] # 3 #数组转换成列表并且进行遍历
p = protein[:] # 行
p = np.array(p)
X = p[:, 1:]
print(X)
# step02:数据理解
# 绘制数据分布图
plt.scatter(X[:, 0], X[:, 1], c="red", marker='o', label='RedMeat-WhiteMeat')
plt.ylabel('RedMeat')
plt.ylabel('WhiteMeat')
plt.legend(loc=2)
plt.show()
# step03:数据准备
# step04:模型训练
# k-means算法可以自动完成簇的识别工作,并且在 Scikit-Learn 中使用通用的评估器API:
estimator = KMeans(n_clusters=3) # 进行KMeans聚类,构造聚类器
# ▲ kmeans.result.学号 这里问什么改不了???
# fit: 主要用于训练算法,该方法可接收用于有监督学习的训练集及其标签两个参数,也可接收无监督学习的数据。
kmeans = estimator.fit(X) # 对聚类的数据进行聚类
label = estimator.labels_ # 获取聚类标签
y_estimator = kmeans.predict(X)
# 用带彩色标签的数据来展示聚类结果 画出簇中心点(这些簇中心点是由 k-means 评估器确定的)
plt.scatter(X[:, 0], X[:, 1], c=y_estimator, s=50, cmap='viridis')
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='black', s=200, alpha=0.5,label='center')
# step06:图像来输出最终的聚类情况
# 绘制k-means结果
x0 = X[label == 0]
x1 = X[label == 1]
x2 = X[label == 2]
plt.scatter(x0[:, 0], x0[:, 1], c="red", marker='o', label='label0')
plt.scatter(x1[:, 0], x1[:, 1], c="green", marker='*', label='label1')
plt.scatter(x2[:, 0], x2[:, 1], c="blue", marker='+', label='label2')
plt.xlabel('x')
plt.ylabel('y')
plt.legend(loc=2)
plt.show()
# step07:模型优化
num = range(1, 20)
kmeans = [KMeans(n_clusters=i)for i in num]
score = [kmeans[i].fit(X).score(X) for i in range(len(kmeans))]
plt.plot(num, score)
plt.xlabel('num')
plt.ylabel('score')
plt.show() # —— ——> k值在3左右最佳
import matplotlib.pyplot as plt
# from sklearn.datasets.samples_generator import make_blobs
from sklearn.cluster import KMeans
from sklearn import metrics
plt.scatter(X[:, 0], X[:, 1], marker='o') # 首先画出生成的样本数据的分布
plt.show()
# 下面看不同的k值下的聚类效果
score_all=[]
list1=range(2,6)
for i in range(2,6): # 其中i不能为0,也不能为1
y_pred = KMeans(n_clusters=i, random_state=9).fit_predict(X) # [2 4 4 0 2 1 4 1 4 2 2 4 2 4 1 2 3 0 3 1 4 4 2 4 0]
plt.scatter(X[:, 0], X[:, 1], c=y_pred) #画出结果的散点图
plt.show()
score = metrics.calinski_harabaz_score(X, y_pred)
score_all.append(score)
print(score) # Calinski-Harabaz score值的可视化输出
# 画出不同k值对应的聚类效果
plt.plt(list1, score_all)
plt.show()可视化输出:
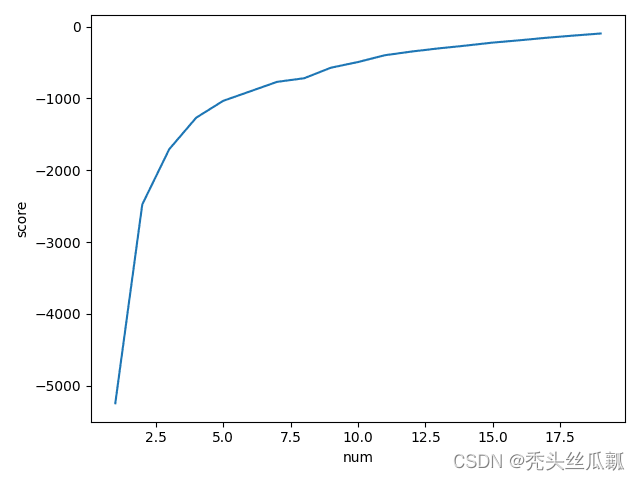 K值选取曲线图.png K值选取曲线图.png | 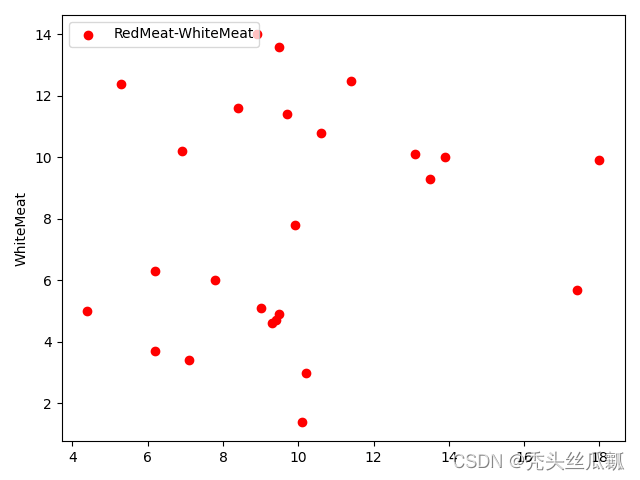 RedMeat-WhiteMeat特征 RedMeat-WhiteMeat特征 |
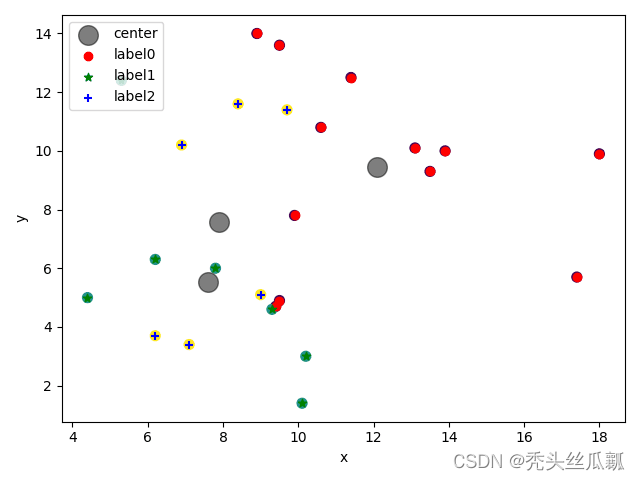 聚类结果.png 聚类结果.png | 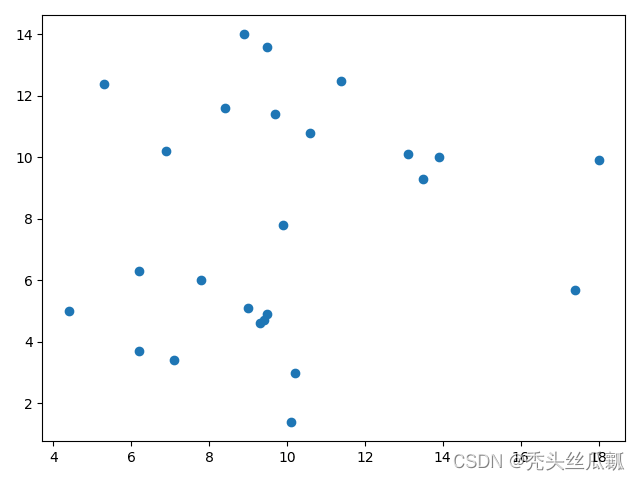 原样本数据分布.png 原样本数据分布.png |
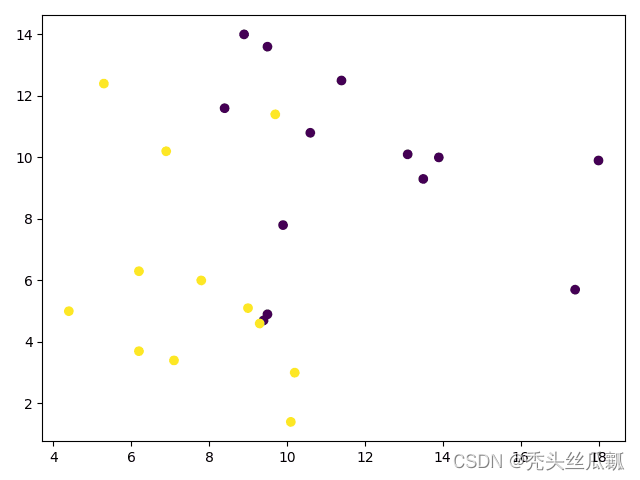 不同k值对应的聚类效果(k=2).png 不同k值对应的聚类效果(k=2).png |  不同k值对应的聚类效果(k=3).png 不同k值对应的聚类效果(k=3).png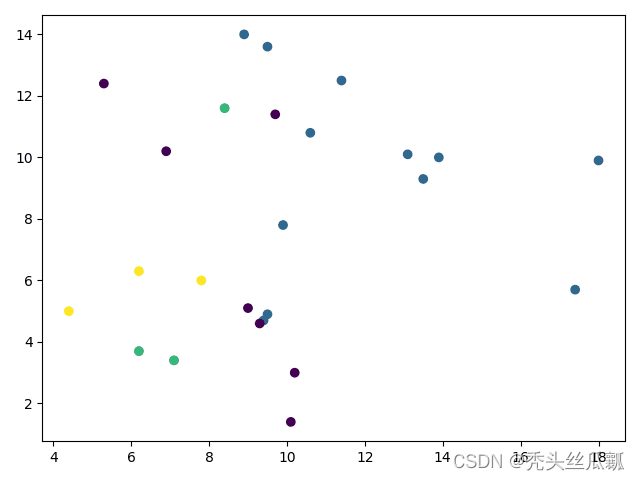 不同k值对应的聚类效果(k=4).png 不同k值对应的聚类效果(k=4).png |
三、遗留BUG
1. 聚类结果储存在向量(kmeans.result.学号)中,我在pycharm内编辑向量名字有误,而且kmeans拓展库无法导入;
2. 聚类最终结果到底是什么?仅仅通过老师讲的部分例题,仅能了解两个特征间的分布关系,这和聚类总体有关系吗?
3. 作业内calinski_harabaz_score部分会报错















 3894
3894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









