






#! https://zhuanlan.zhihu.com/p/666857207
论文代码学习
论文地址:ICCV2023_Deep Directly-Trained Spiking Neural Networks for Object Detection
代码地址:https://github.com/BICLab/EMS-YOLO
(中国科学院自动化研究所李国齐课题组,转载请注明出处)
论文提出了一个全脉冲残差块EMS-ResNet处理对象检测任务,以低功耗有效地扩展SNN的深度。实验表现以很少的时间步优于ANN-SNN的SOTA很多个时间步的表现。
训练
使用替代梯度。思考:替代梯度和TDBN的电流是怎么推导出来的。
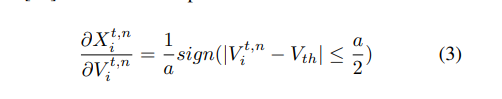
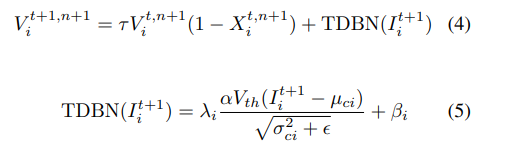
计算消耗:

代码块
现有网络:
SEW-ResNet:
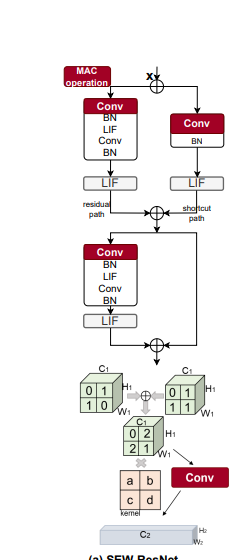
两个LIF如果都传输SPIKE会得到2,后续卷积操作会引入MAC操作造成性能损失。
MS-ResNet:
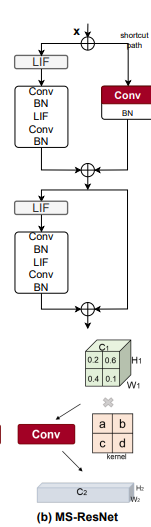
忽略了剪切路径的LIF出现MAC操作。
本文方法:
EMS-ResNet:
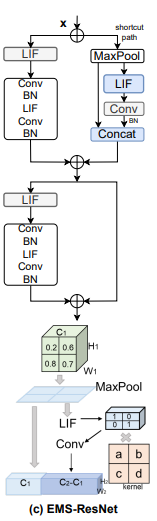
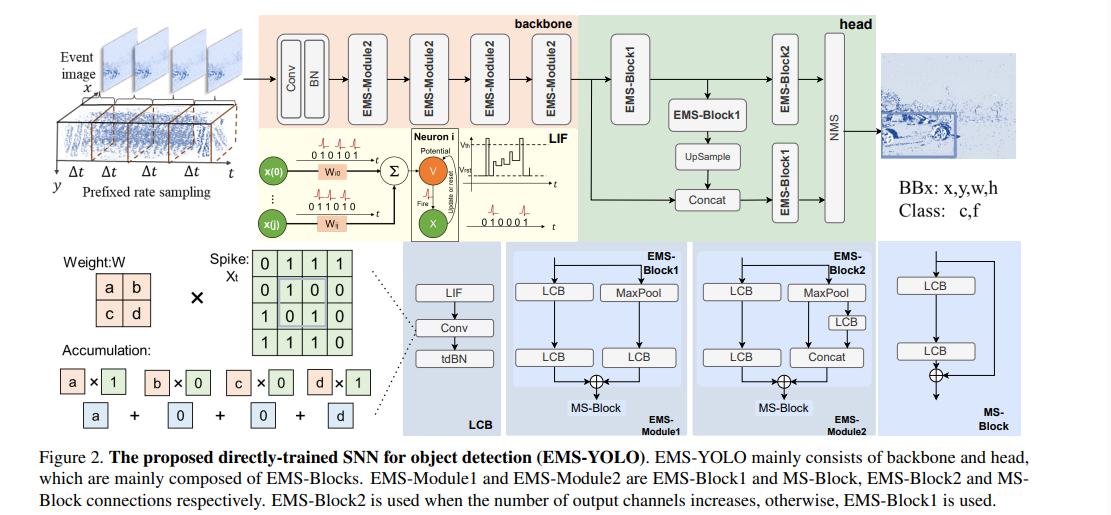
除了最初的卷积+BN操作,后续的每一次卷积操作之前都跟了一次LIF,避免了MAC。
操作包含了:snnConV,BN,LIF,tdBN,MaxPool,ConCat,NMS,UpSample
该网络在目标检测任务中使用YOLO框架,包括两个模块:backbone for feature extraction and the detection heads.
图像的模拟像素值X直接输入,在backbone中,第一个卷积层用于将输入转换为脉冲,在这里面LIF神经元对加权输入进行整合并输出脉冲序列,在膜电位超过训练的点火阈值时产生训练的输出尖峰。然后利用EMS模块从不同维度和通道数量提取对象特征,增强网络鲁棒性。EMS-Blocks的数量和通道宽度可以根据特定任务进行动态调整。
检测头直接用EMS-Blocks取代yolo的直接连接Conv,减少性能损失。
目标检测使用SNN模型进行回归任务的难点在于把脉冲训练提取的特征转换成精确的连续值表示边界框坐标。
这个网络把神经元最后的膜电位输入每个检测器,生成大小不同的锚点。经过NMS处理后,可以得到不同物体的最终类别和边界框坐标,采用交叉熵损失函数训练。
灵汐芯片部署调研
灵汐芯片完全支持float16,但float32会出现误差逐层累积的情况。
灵汐不支持5D的tensor,shape=[T,N,C,H,W],使用to_lynxi_supported_module或者to_lynxi_supported_modules转换,会把输入视作TN,*。为了得到分类结果,需要求得发放率,单独建立网络在训练后进行重置。灵汐芯片上的推理
推理的时候首先加载编译好的网络,将Pytorch的输入tensor转换为灵汐的tensor,送入网络;将输出的灵汐tensor转化成pytorch的tensor来计算正确率。
Loihi芯片部署调研
流程:SpikingJelly-> Lava DL-> Lava-> Loihi
相关模块定义在spikingjelly.activation_based.lava_exchange
Lava DL默认数据格式为shape=[N,*,T]。
SpikingJelly -> Lava 支持卷积、全连接、池化层,不支持bias,Lava只支持求和池化,相当于平均池化不做平均。
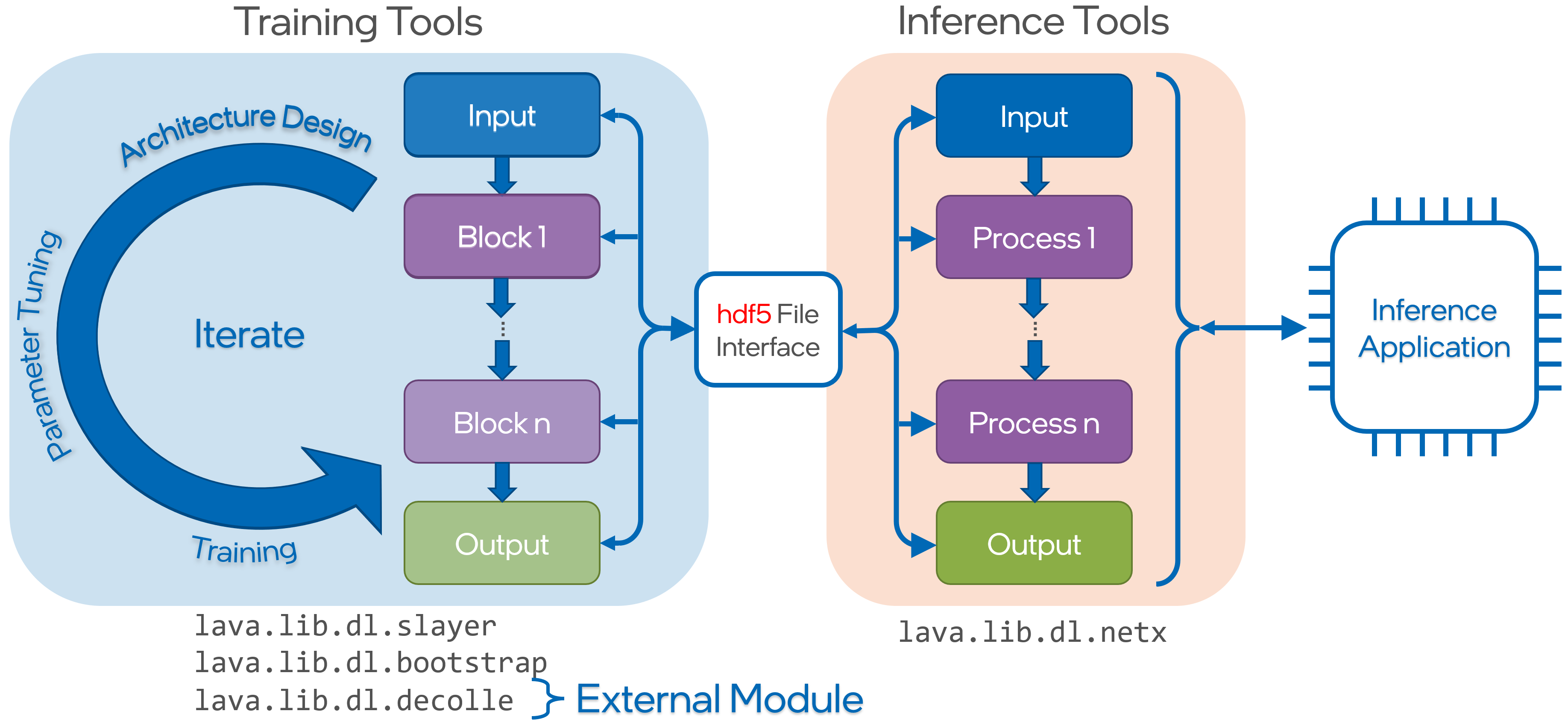
使用Lava DL的一般流程是:
- 使用Lava DL框架中的Blocks搭建并训练网络
- 将网络导出为hdf5文件
- 使用Lava框架读取hdf5文件,以Lava的格式重建网络,并使用Loihi或CPU仿真的Loihi进行推理。
SpikingJelly提供BlockContainer,支持替代梯度训练,支持lava_exchange.cubaLIFNode,支持自动将IFNode和LIFNode转换为Lava的CubaLIFNode
如果想部署在Loihi建议阅读Lava DL文档直接写,不要通过惊蛰转换。Lava DL框架的内容更全面一些。(相当全面)
工作流:

















 1857
1857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









