






abstract
这篇文章旨在研究硬件上部署SNN的障碍,在SATA和SpikeSim上做了实验,最终发现近期SNN的实际能效改进与估计值相差甚远。
关键词: SNN,Systolic-arrays,In-memory Computing,Crossbars,Energy-efficiency
Introduction
文中指出,现有的SNN论文性能评估标准大部分仅限于FLOPs等指标,没有考虑内存访问和数据通信等硬件开销。实际的systolic-array和In-memory Computing在处理稀疏脉冲数据方面并不优秀,尤其是在内存读取期间。
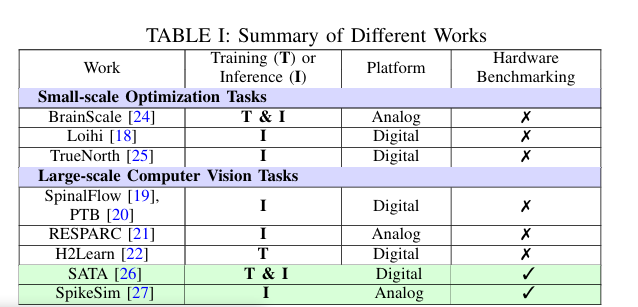
所以本文在SATA和SpikeSim上做了硬件仿真评估。最终提出并解决了三个硬件瓶颈问题:1)多时间步中的重复内存读取和计算 2)LIF神经元模块的开销 3)IMC实现的SNN在模拟交叉非理想性方面的脆弱性。激励未来的工作以高效的硬件感知SNN算法设计为目标。
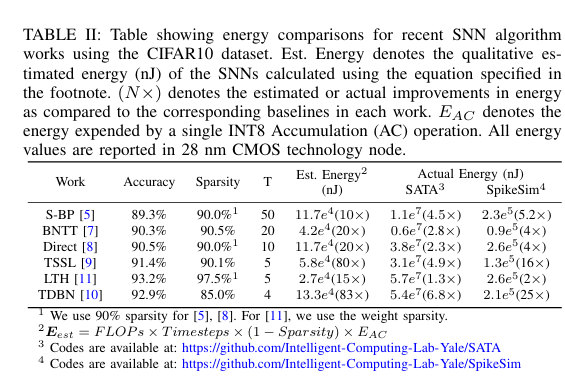
硬件平台介绍
- SATA是一种稀疏感知训练加速器,用于在全数字 von-Neumann 架构上对最先进的基于 BPTT 的 SNN 训练进行基准测试。SATA 采用了简单、可重新配置的收缩阵列设计,并具有三级内存层次结构。这使得 SNN 算法设计人员可以直接在 SATA 上部署工作负载,并估算硬件能耗成本。虽然 SATA 被设计为训练加速器,但它可以通过连接与训练相关的组件,对预训练 SNN 的推理性能进行enchmark。对 SATA 所做的分析有助于发现一些主要瓶颈,如随着时间推移不断重复的数据移动,这些瓶颈阻碍了 SNN 在硬件上实现高能效。SATA 显示,SNN 中的尖峰数据稀疏性可以在 PE 计算单元(执行加权累积和 LIF 操作)中得到充分利用。在计算单元之外,即使是稀少的输入和重量数据,也需要从片上缓冲器获取内存,从而增加了大量的能耗开销。
SATA的两大挑战:
- PE计算和从片上缓冲区移动数据的能耗成本随着时间步长的增加而增加
- LIF单元的硬件成本。
- SpikeSim是IMC-based benchmarking 加速器,将BPTT训练的SNN工作负载映射到一个基于IMC的整体式权重静态编译架构上,称为SpikeFlow,并执行硬件现实精度、能量、延迟和区域评估。SpikeFlow结合了LIF/IF神经元激活单元,用于存储中间膜电位,并在推理过程中产生脉冲输出。模拟交叉也是基于RRAM器件的。
挑战:
- SNN在模拟crossbar上极易受到当时非理想性的影响,导致点积运算中的错误在多个时间步上累积。
- SNN于ReLU-ANN不同,在SpikeSim上需要很高的LIF/IF神经元开销。(输出的时候需要很大神经元开销。)如图所示,SpikeSim上的推理能耗和延迟都随着时间步增加而急剧增加。
解决策略
动态时间步减少
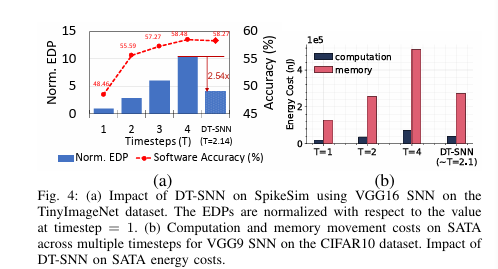
为了通过减少时间步数来提高 SNN 的能效,本文分析了一种输入感知动态时间步数 SNN(DT-SNN)方法 。DT-SNN 通过简单地在基于 SNN 的硬件加速器(SATA 或 SpikeSim)上附加数字熵计算模块,就能在预先训练的 SNN 的推理过程中,根据输入动态确定可信预测所需的最少时间步数。对于每个输入,SNN 在每个时间步结束时预测输出的熵计算值都会与定义的阈值进行比较。如果在任何给定的时间步,熵值低于设定的阈值,则会执行临近时间退出(推理终止)或预测。 在 SpikeSim 上,图 4(a) 显示,在快速标准 VGG16 SNN 对微小图像网络数据集的推理中,将时间步数从 1 增加到 4 时,能量延迟积(EDP)增加了 10.4 倍。我们发现,与对所有输入采用 4 个时间步的标准 SNN 推理相比,DT-SNN 可以在保持相同推理精度的情况下将总能量延迟积降低 2.54 倍。
降低数据移动成本
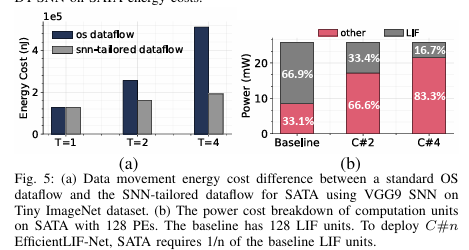
在 SATA 等数字硬件平台上部署 SNN 所面临的主要挑战之一是重复数据移动成本。本文为 SATA 设计了一种为 SNN 量身定制的数据流,可以显著降低 SNN 的重复数据移动成本。在 SATA 的数据流设计中,我们采用了 tick-batch 方法 ,通过在每个 PE 内设置刮板存储器,在整个 PE 计算过程中固定权重 ,从而最大限度地重复使用 PE 层的权重。通过利用这种数据流,SATA 只需在所有时间步中从上层存储器(DRAM 和 SRAM)向 PE 阵列读出一次数据。在图 5 (a) 中,我们比较了 SATA 的 SNN 定制数据流与 VGG9 SNN 在 Tiny ImageNet 数据集上不同时间步的标准输出静态数据流。使用 SNN 定制数据流可在时间步长为 4 时节省 62.5% 的内存移动能量。除了为硬件重新设计数据流外,量化-和剪枝等模型压缩技术也有助于降低数据移动成本。
减少LIF开支
LIF 单元是硬件上的高能耗组件,其总功耗可达计算单元的 61.6%。这意味着 LIF 运算的能耗成本比其他运算高出约 2 倍。
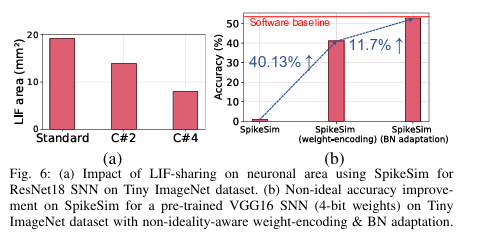
为了减轻 LIF 单元的开销,最近的研究成果 EfficientLIF-Net跨层和通道共享 LIF 神经元。本文使用C#n的符号来表示在输出通道维度上为n个突触后神经元共享1个LIF神经元的高效LIF网络。在SATA上,如图5(b)所示,共享C#4 LIF可以降低75.1%的LIF单元的电源成本。膜电位的量化也可以通过具有较小的膜电位寄存器来帮助降低LIF单位成本。LIF共享和膜电位量化方法是用于降低LIF单位成本的正交技术。在SpikeSim上,对于TinyImagenet数据集上的ResNet18 SNN,与C#2和C#4共享LIF分别导致LIF面积减少1.38倍和2.41倍(见图第6(a)段)。
crossbar非理想性减少
为了解决非理想Crossbar上SNN的准确性下降问题,图中研究了两种无训练方法。6(b):(1)SpikeSim支持RRAM Crossbar上的非理想性感知权重编码方案,以增加SNN推理过程中高阻突触的比例。先前的工作表明,随着交叉中高电阻突触的比例增加,交叉非理想性的影响会降低。因此,非理想SNN的精度提高了40.13%。(2)推理前对SNN的批模(BN)参数的非理想自适应可以减轻交叉非理想性的影响,特别是互连寄生效应。在BN自适应过程中,我们通过部署在横杆上的SNN转发了许多训练图像样本,调整了批模层相对于噪声激活的移动平均值和方差(同时保持可学习参数)
原文:Are SNNs Truly Energy-efficient? — A Hardware
Perspective[https://arxiv.org/abs/2309.03388]
Basic Information
Title: Neural inference at the frontier of energy, space, and time (能源、空间和时间前沿的神经推理)
Keywords: neural inference, energy efficiency, spatial computing, low-precision, NorthPole architecture (神经推理,能源效率,空间计算,低精度,NorthPole架构)
URLs: Paper, GitHub Code (GitHub: None)
论文简要
本研究提出了一种名为NorthPole的神经推理架构,通过消除片外存储器、在芯片上将计算与存储交织在一起,并在外部呈现为一块主动内存芯片,实现了低精度、高并行、能效高、空间计算的特点,并在ResNet50和Yolo-v4等基准测试中取得了优于其他架构的结果。
背景信息
论文背景:
过去的计算机设计中,计算和存储分离,导致了计算机内存层次结构的出现。然而,受到大脑的启发,神经推理作为一种强大的应用出现,可以使用更简单的构造实现。此外,硅技术的进步使得在芯片上实现逻辑和存储成为可能。
Motivation:
本研究的动机在于通过重新构想计算和存储之间的交互方式,提出一种新的神经推理架构和编程模型,以实现更高的能效、更高的空间计算能力,并解决现有架构中的瓶颈问题。
方法:
a. 理论背景:
NorthPole是一种神经推理架构,旨在通过消除芯片外存储器并将计算与内存集成在芯片上来模糊计算和内存之间的边界。它是一种低精度、高度并行、密集互连、能效高的空间计算架构。该架构与高利用率的编程模型进行了协同优化。
b. 技术路线:
NorthPole架构专门用于神经推理,不支持训练或科学计算。它针对低精度(8位、4位和2位)操作进行了优化,这足以在许多神经网络上实现最先进的推理准确性。
该架构由分布式、模块化的核心阵列组成,每个核心都能进行大规模并行计算。内存分布在核心之间,并且关键计算与内存交织在一起。使用两个密集的片上网络(NoCs)连接核心,并分发神经元激活和突触权重。利用可重构性,在每个层的执行过程中存储权重和程序,并对其进行重新配置。
该架构还利用数据无关分支来支持完全流水线化、无停顿、确定性控制操作。通过协同优化的训练算法和软件,可以在考虑低精度约束的同时实现最先进的推理准确性。软件会自动确定计算、内存和通信的显式编排计划,以在空间和时间上实现高计算利用率。
结果:
a. 详细的实验设置:
本文未提及具体的实验设置。
b. 详细的实验结果:
NorthPole架构相对于其他流行架构在能效、空间效率、吞吐量、延迟等方面提供了详细的实验结果和性能指标。对于ResNet50网络,它在能量、空间和时间指标上优于其他架构,每十亿个晶体管的帧率和每焦耳的帧数比当代GPU、CPU和加速器更高。文中还包括了一个表格,比较了不同处理器在各种测量指标和计算的优势指标方面的性能。
NorthPole在空间指标上通过实现更高的瞬时并行性和更低的晶体管数超越了其他架构。这些结果基于ResNet50图像分类网络,类似的比较结果也适用于Yolo-v4检测网络。
NorthPole的吞吐量和延迟在不同的批量大小下进行了报告,范围从1到32。例如,使用批量大小为32,NorthPole在延迟为753毫秒的情况下实现了高吞吐量的42,460帧每秒。使用批量大小为1,NorthPole在延迟为106毫秒的情况下以9454帧每秒的吞吐量运行。
NorthPole的芯片内存足以实现许多广泛使用的网络,包括用于分类的ResNet,用于检测的Yolo和SSD-VGG,用于分割的PSPNet,用于实例分割的RetinaMask,用于自然语言处理的BERT和用于语音识别的DeepSpeech2。
在内存允许的情况下,可以在芯片内存中存储多个网络,支持多租户。使用4位或2位精度,存储在NorthPole上的神经网络权重数量可以增加一倍或四倍。
NorthPole的发展方向包括算法、系统、模块化、封装、架构、硅缩放、硅优化和潜在的后硅技术。目标是使更大的网络适应芯片,并扩展NorthPole的功能。
原文:https://www.science.org/doi/10.1126/science.adh1174















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









