







http://arxiv.org/abs/2008.12283
目录
5.1 Entity-Guided Input Sequences
5.2 Entity-Guided Relation Extraction
5.3 Evidence Guided Relation Extraction
5.3.2 Evidence-guided Finetuning with BERT Attention Probabilities
5.3.3 Joint Training with Evidence Prediction
1 摘要
在本文中,我们提出了一个用于此任务的联合训练框架E2GRE(实体引导和证据引导的关系提取)。首先,我们引入实体引导序列作为预训练语言模型的输入。这些entity guided序列有助于预训练语言模型(LM)关注与实体相关的文档区域。其次,我们通过使用预训练语言模型的内部attention probabilities作为证据预测的附加特征来指导预训练语言模型的微调。我们的新方法鼓励预先训练的语言模型关注实体和支持/证据句子。
2 任务
本文主要解决的问题是实体对的关系预测和证据预测两个任务,并将这两个任务的联合训练,根据具体的任务,决定任务训练的强度。
3 动机
由于文档级关系抽取的实体对数量远远多于句子级的实体对数量,这样就使得文档级的预训练语言模型的attention的值更加统一,在实体信息抽取方面能力更弱。这样就限制了预训练语言模型从文档中提取实体信息的能力。为了缓解这个问题,我们就提出了E2GRE。
4 方法
提出的E2GRE中的主要的新方法是实体引导方法和证据引导方法。下面来介绍实体引导和证据引导方法的作用原理。
4.1 实体引导
在文档的开头插入实体的token,把该序列当作输入序列输入到预训练语言模型中,就可以让模型更加关注文档的开头实体,提高模型在实体信息抽取方面的能力。从而应用到实体对的关系抽取任务上。
4.2 证据引导
attention中值高的地方往往是证据句出现的地方,因此我们相信attention probabilites对证据预测这一任务是有利的,因为我们将attention作为证据预测的附加特征,即作为证据预测的引导,从而应用到证据预测的任务上。
5 模型设计
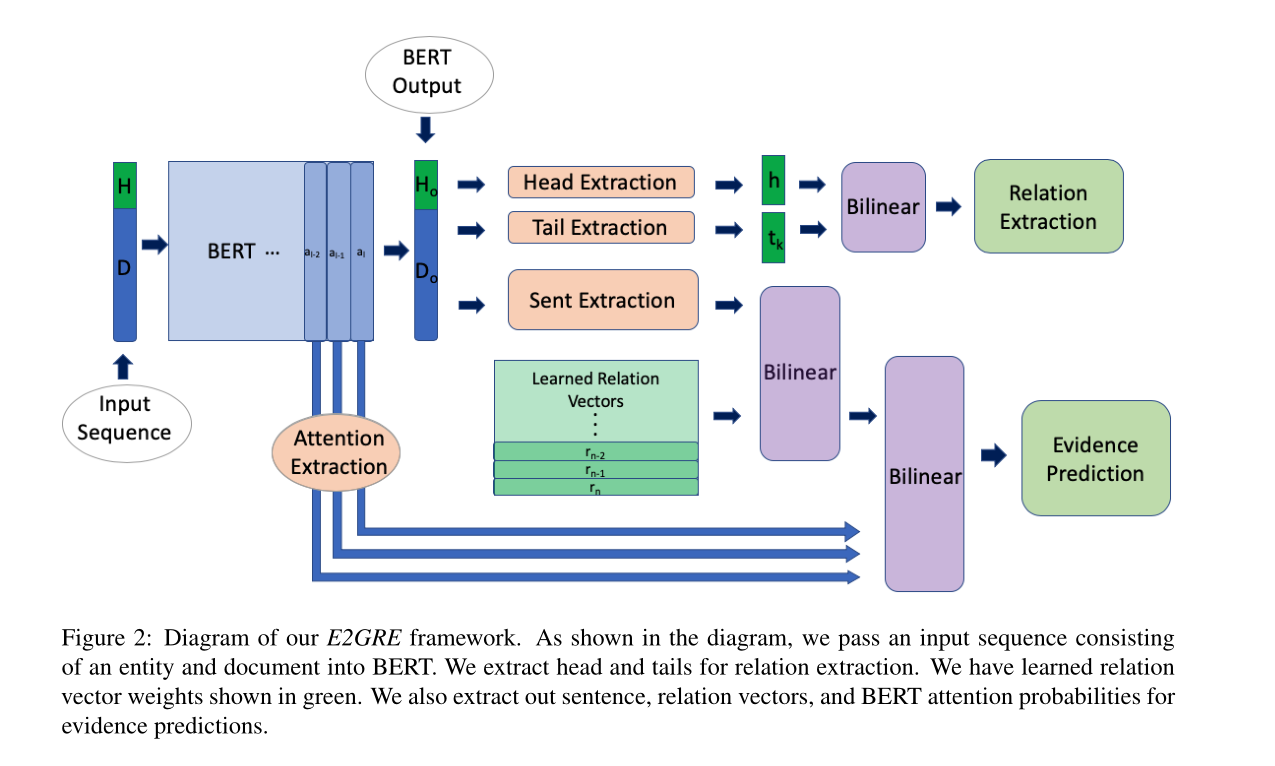
5.1 Entity-Guided Input Sequences
目的:为了获得实体引导的输入序列,作为预训练语言模型的输入
步骤:
- 把一个实体的第一个提及的token插入到该文档的前面,获得“[CLS]”+H+ “[SEP]” +D+ “[SEP]”这样的序列,H为头实体的token,D为文档的token
- 一个文档有Ne个实体,那么就会产生Ne个输入Entity-Guided Input Sequences,输入到BERT,得到embedding
- 若序列的长度>512,那么将其拆分,获得 “[CLS]”+H+ “[SEP]” +D[offset:end] + “[SEP]”,将获得的两个序列的embedding进行平均,得到该序列的embedding
- 通过上面的方法,我们就可以获得一个文档的Ne个输出序列了
5.2 Entity-Guided Relation Extraction
目的:在获得实体引导的输出序列后,继而获得头实体和尾实体的embedding,从而进行实体对的关系预测任务
步骤:
- 将“[CLS]”+H+ “[SEP]” +D+ “[SEP]”中的头实体H的所有tokens的embedding求平均,得到头实体的embedding h,同理获得
个尾实体的embedding
(1<= k<=
- 将其放入双线性层中,计算是关系
的概率(
)
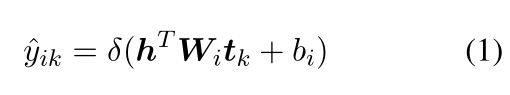
- 再利用计算的概率放入多标签交叉熵损失函数中,计算损失

5.3 Evidence Guided Relation Extraction
5.3.1 Evidence Prediction
目的:证据/支持句是用于预测头部和尾部实体之间的正确关系的包含重要支持事实的句子。那么证据预测的目的就是预测给定的句子是否是给定关系r的证据/支持句。
步骤:
- 一个文档有
个句子s,对一个句子的tokens的embedding求平均,得到一条句子的embedding,
- 计算第j条句子是否是证明

- 将计算的概率放入定义好的损失函数中

5.3.2 Evidence-guided Finetuning with BERT Attention Probabilities
目的:我们发现BERT模型的自注意力机制会集中关注于文档的某些区域。attention的值高的话的地方,通常是证据句存在的地方。因此,我们用BERT Attention Probabilities给我们上面的 Evidence Prediction 进行预测,BERT Attention Probabilities就是证据引导Evidence-guided
步骤:
- 首先获得BERT的最后几层的attention
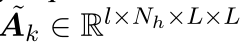
- 然后在head dimension上运用maximum pooling,再在layer dimension上运用mean pooling得到最终的一个文档的attention

- 将头实体和尾实体的tokens的embedding求平均,得到一个attention probability ten-sor,

- 最后,我们将上面的attention求平均,得到一个序列的attention,那么一个稳定的attention就是重复上面的操作,最后得到

- 将得到的文档的attention probablilites加入到证据预测中的概率计算公式中,即加入到Eq 3中,作为附加特征,提供帮助
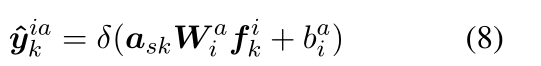
- 再将Evidence Prediction 中的损失函数重新定义为下式

5.3.3 Joint Training with Evidence Prediction
目的:将关系提取损失和注意概率引导的证据预测损失相结合,作为联合训练的最终目标函数
![]()
其中λ1>0是在两个损失之间进行权衡的权重因子,这取决于数据。
6 实验结果
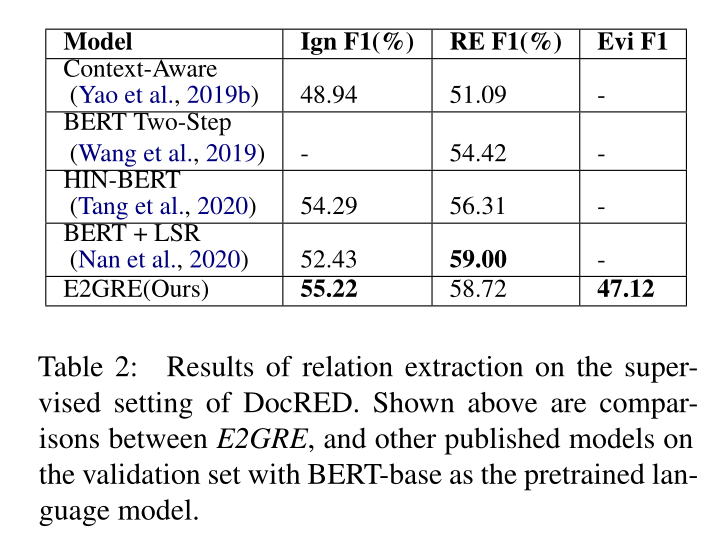
7 结论
为了更有效地利用预训练LMs进行文档级RE,我们提出了一种称为实体和证据引导的关系提取(Entity and Evidence Guided Relationship Extraction,简称DE2GRE)的新方法。我们首先生成新的entityguided序列,将其输入到LM中,将模型集中在文档中的相关区域。然后,我们利用从最后一位同事那里提取的内部注意,帮助引导LM关注文档的相关领域。我们的E2GRE方法在DocRED数据集上提高了RE和证据预测的性能,并在DocRED公共排行榜上实现了最先进的性能。
在未来的工作中,我们计划将我们关于使用注意力引导的多任务学习的想法融入到其他具有证据句的NLP任务中。将我们的方法与基于图的NLP任务模型相结合是另一个值得探索的有趣方向。














 315
315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









