






Catalog
Catalog是一种非持久性目录,设计用于由DBMS执行引擎中的执行者使用。它处理创建表、查找表、创建索引和查找索引。
主要变量成员:
[[maybe_unused]] BufferPoolManager *bpm_;//页管理器
[[maybe_unused]] LockManager *lock_manager_;
[[maybe_unused]] LogManager *log_manager_;
/**
* 映射 表的id号 -> 真实的表
*/
std::unordered_map<table_oid_t, std::unique_ptr<TableInfo>> tables_;
/** 映射 表的名字 -> 表的id号
*/
std::unordered_map<std::string, table_oid_t> table_names_;
/** 创建下一个新表分配的id号 */
std::atomic<table_oid_t> next_table_oid_{0};
/**
* 索引id号 -> 真实的索引
*/
std::unordered_map<index_oid_t, std::unique_ptr<IndexInfo>> indexes_;
/** 表名 -> 索引名 -> 索引id号 */
std::unordered_map<std::string, std::unordered_map<std::string, index_oid_t>> index_names_;
/** 下一个被分配的id号. */
std::atomic<index_oid_t> next_index_oid_{0};一个真实索引indexinfo
/** 索引键值的schema表单 */
Schema key_schema_;
/** 索引的名字 */
std::string name_;
/** 指向index的指针 */
std::unique_ptr<Index> index_;
/** index的id号 */
index_oid_t index_oid_;
/** 对应的表名 */
std::string table_name_;
/** 键值的字节数 */
const size_t key_size_;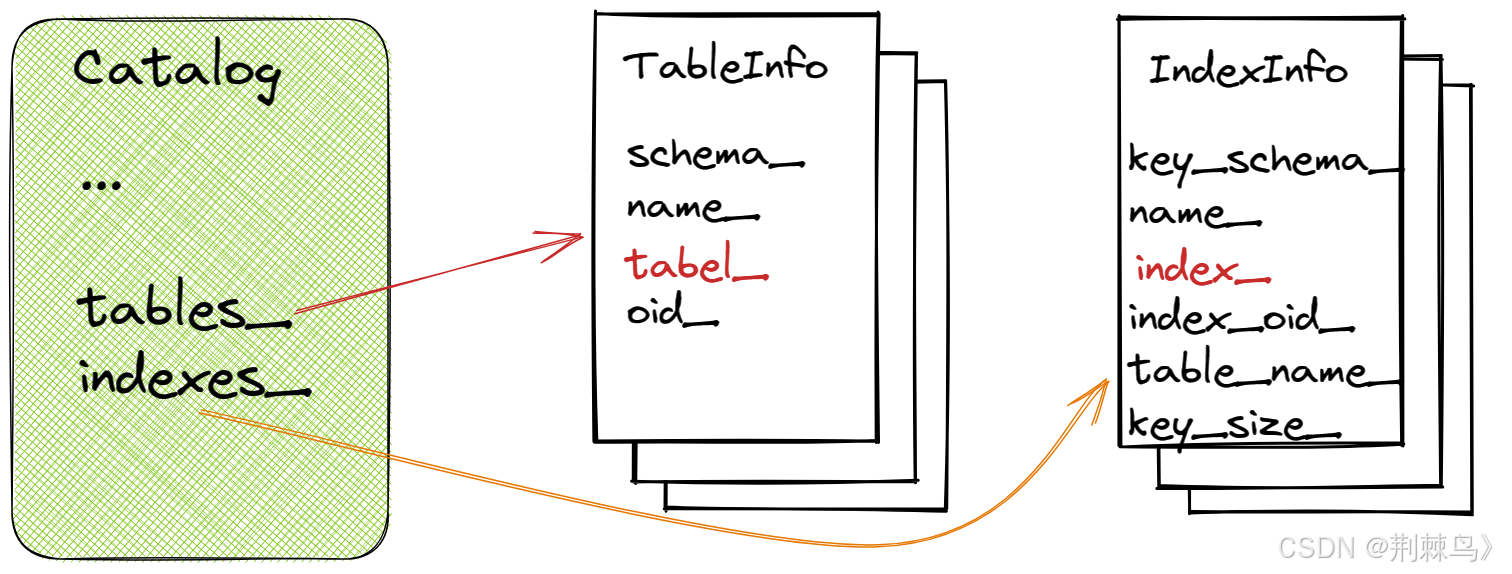
插入数据的流程
1.用catalog的GetTableIndexes函数得到索引信息indexinfo列表
2.遍历PlanNode的所有需要插入的tuple
3.tableinfo的TableHeap插入tuple
4.遍历indexinfo列表中所有indexinfo
5.将待插入的tuple提取出键值key,将key经过转化成index_key
6.index调用InsertEntry函数插入index_key
(InsertEntry函数就是ExtendibleHashTableIndex的insert(project 2)
6.1 HASH_TABLE_TYPE调用Insert
6.2 获取索引根目录所在的页dir_page
6.21 buffer_pool_manager_->FetchPage(directory_page_id_)(project1)
6.3 获取index所在的页bucket
6.31index_key所在页号是Hash(index_key) & dir_page->GetGlobalDepthMask()
6.4如果bucket满了,就拆分后再插入
6.5如果bucket没满,HASH_TABLE_BUCKET_TYPE调用Insert
6.51遍历IsOccupied和IsReadable,在第一次遇到二者同时空闲的位置插入pair<KeyType, ValueType>存储index索引的页中,pair对的第一个值是key,在测试样例中是int;第二个值是value,也就是rid——这里的rid指的是新插入的tuple在tableinfo中的id号,在测试样例中是(page id,slot id)
1个catalog中包含多个indexinfo
1个indexinfo对应1个成员变量Index
ExtendibleHashTableIndex继承Index,
ExtendibleHashTableIndex有一个成员ExtendibleHashTable(poject 2)
一个ExtendibleHashTable对应一个dir目录和很多bucket页面
ExtendibleHashTable有一个成员BufferPoolManager
BufferPoolManager有两种子类:BufferPoolManagerInstance和ParallelBufferPoolManager(poject 1)
1种table的1种key键值对应一种indexinfo
SELECT test_4.colA, test_4.colB, test_6.colA, test_6.colB FROM test_4 JOIN test_6 ON test_4.colA = test_6.colA;
详细解释逻辑计划生成的过程:
SELECT test_4.colA, test_4.colB, test_6.colA, test_6.colB FROM test_4 JOIN test_6 ON test_4.colA = test_6.colA;
1.首先生成SeqScanPlanNode的scan_plan1和scan_plan2
1.1针对属性cola,colb分别生成对应的AbstractExpression
1.11 ColumnValueExpression 变量表达式
1.12 ConstantValueExpression 常量表达式
1.13 ComparisonExpression 不等式表达式
1.14 AggregateValueExpression 聚合表达式
1.2生成代表结果scheme的out_schema1,out_schema2
2.生成HashJoinPlanNode
2.1 包含两个子节点scan_plan1和scan_plan2
2.2 test_4.colA 和test_6.colA分别作为左关键表达式和右关键表达式
---------------至此执行计划生成完毕------
3.在初始化的过程中,遍历左表(子节点scan_plan1)的所有tuple,得到一个map < 左关键表达式 , 对应的tuple >
4.执行scan_plan2的NEXT函数,得到tuple,从而得到右关键表达式,在map中查找和该右关键表达式相等的左关键表达式,以及它对应的tuple
5.将两个tuple合并values
5.5组成结果scheme的AbstractExpression分别依次EvaluateJoin
SELECT COUNT(col_a), SUM(col_a), min(col_a), max(col_a) from test_1;
SELECT count(col_a), col_b, sum(col_c) FROM test_1 Group By col_b HAVING count(col_a) > 100
第一个需要特别维护的表:unordered_map<AggregateKey, AggregateValue>
1.对表的每一项tuple转换成AggregateKey
如果是group_by,tuple获取该col的值就是AggregateKey
如果不是group_by,AggregateKey就是一个空的动态数组
2.对表的每一项tuple转换成AggregateValue
2.1 其中AggregateValue是一个数组,包含要输出的结果col的目前的值
2.11 举个例子SELECT count(col_a), col_b, sum(col_c) FROM test_1 Group By col_b
则AggregateValue就有两个项,第一个项表示count(col_a)目前的值,第二项表示sum(col_c)的值。
3.在next函数中,我们需要遍历上述表,对hash表中每一项进行条件判断,然后将结果输出
3.1 having后缀是一个筛选条件
3.2 非group_by或者满足having的筛选条件时,则next执行完毕输出tuple
project-4
获取共享锁:
获取共享锁:
1.READ_UNCOMMITTED的隔离级别下直接异常报错,此级别下不需要申请锁
2.获取该元组的申请队列request_queue
3.将该次事务访问插入申请队列request_queue中
4.使用Wound Wait死锁预防机制,优先杀死占有资源更年轻的线程,然后调用cv.notify_all();唤醒所有等待该条件变量的线程。每个线程在唤醒后会尝试重新获取互斥锁。(此步是为了死锁预防)
5.然后尝试获取锁
5.1尝试遍历申请队列request_queue
5.11当遇到排它锁且未被终止时,break跳出循环
5.12当遍历到当前事物时,说明轮到自己了,获得共享锁
5.2 当遍历一遍队列后,仍没有获得锁,则cv.wait(lk);进入休眠(等待cv.notify_all();来唤醒)
5.3 线程会检查事务状态,如果事务在等待过程中被中止(比如由于死锁),则抛出 TransactionAbortException 异常,通知调用方事务已经终止。
获取排它锁:
获取排它锁:
1.获取该元组的申请队列request_queue
2.将该次事务访问插入申请队列request_queue中
3.使用Wound Wait死锁预防机制,优先杀死占有资源更年轻的线程,然后调用cv.notify_all();唤醒所有等待该条件变量的线程。每个线程在唤醒后会尝试重新获取互斥锁。(此步是为了死锁预防)
(和共享锁的区别:共享锁会杀死占有排它锁且更年轻的线程,但排它锁会杀死所有更年轻的进程)
5.然后尝试获取锁
5.1尝试遍历申请队列request_queue
5.11跳过所有会被终止的线程
5.12当遍历到当前事物时,说明轮到自己了,获得排它锁
5.13当完成5.11但没有满足5.12时cv.wait(lk);进入休眠
5.14 线程会检查事务状态,如果事务在等待过程中被中止(比如由于死锁),则抛出 TransactionAbortException 异常,通知调用方事务已经终止。
升级锁:
1.确保此时该元组上没有升级锁
2.获取申请队列request_queue
3.使用Wound Wait死锁预防机制,优先杀死占有资源更年轻的线程,然后调用cv.notify_all();唤醒所有等待该条件变量的线程。(此步是为了死锁预防)
4.每次事务被唤醒时,先检查其是否被杀死,然后遍历锁请求队列在其前方的请求,如其优先级较低则将其杀死,如其优先级较高则将can_grant置为假,
示意其将在之后被阻塞。如杀死任意一个事务,则唤醒其他事务。如can_grant为假则阻塞事务,如为真则更新锁请求的lock_mode_并将upgrading_初始化。
5.当升级成功时,更新事务的拥有锁集合scan,insert,delete的修改:
当SeqScanExecutor从表中获取元组时,需要在以下条件下为该元组加读锁,并当加锁失败时调用Abort杀死该元组:
- 事务不拥有该元组的读锁或写锁(由于一个事务中可能多次访问同一元组);
- 事务的隔离等级不为
READ_UNCOMMITTED。
在使用完毕元组后,需要在以下条件下为该元组解锁:
- 事务拥有该元组的读锁(可能事务拥有的锁为写锁);
- 事务的隔离等级为
READ_COMMITTED时,需要在使用完读锁后立即释放,在其他等级下时,锁将在COMMIT或ABORT中被释放。
insert在插入的时候会维护一个表格,保存插入前的tuple和插入后的tuple,目的是在ABORT时回滚,返回初始值。
COMMIT操作中包含释放该事物占有的所有锁


















 7166
7166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









