






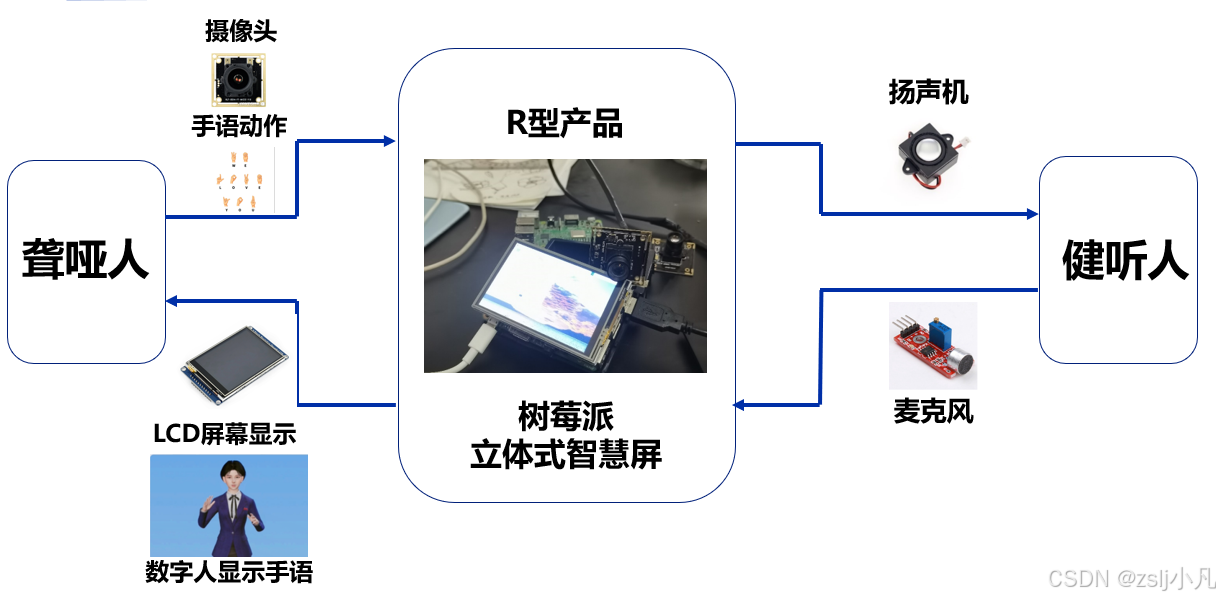
主要包括模型,数字人,前后端三大块。
双向交流过程如图。
手语主要分为静态手语和动态手语。刚开始项目的时候以为只有静态手语,决定用yolov7目标检测图片中的手语,因为要做数据集,拉框标注,但团队成员还不会做数据集,所以我决定改用mobilenetv3和resnet50模型做图像分类。
前后拉着拍了三次数据集,大部分都是我的图(所以大概14000+张图片了?真没想到这么多),所以这模型识别我的准确度奇高。
虽然没做,但是我们项目中还是要会吹的,比如,在未来我们也会使用数据增强(加噪点,旋转等等),在后端中提供个性化模型微调功能以提升识别准确度。
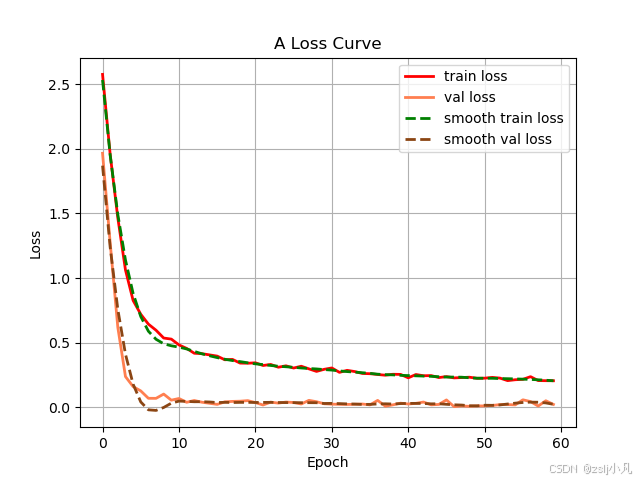
当然到这里还没完,现在只识别了单个词,聋哑人的语序和中文语序不一样,所以还需要nlp模型把词变成句子,最后通过文字转语音模型,才能使用麦克风进行播放。
至此从左往右的流程就结束了。
现在开始从右往左,麦克风录音健听人说的句子Whisper模型转文字,然后nlp模型进行分词,我们想自己实现一个数字人模型,这玩意一开始觉得没啥难度吧,真到实现的时候又卡住了,简单来说,我们需要自己建一个模型(maya),然后对模型进行绑定,绑定甚至还需要学人体,当然对于我们来说就需要重点了解嘴,胳膊,手的关节。绑定好之后,就是制作每个词对应的动作,呃.........就是需要一帧一帧自己来调模型,或者也可以用3d动捕来制作,当然买不起设备,就没有这种方法了。
这时候我们了解了手语不仅是手上的动作,有时嘴和整个胳膊都是信息,还好我们的模型可以提取到这些特征,只需对数据集进行改进。
是不是感觉模型非常的多,是的,我一开始使用tf2,然后又用了pytouch,最后呢又用了百度飞浆,一开始不愿意用感觉一更新代码就可能用不成,但是模型还是很全,都是现成的。
前端树莓派其实也好搞,只需要烧录镜像到sd卡,我烧的带图像化界面,通过vnc Viewer可以远程连接到树莓派,基本上其他硬件设备都是免驱使用的,支持python,所以前端使用了pyqt编写,注意使用多线程防止界面卡顿,使用http和后端进行通讯,所有的模型都上云部署,用了flask部署的,我那个时候GitHub还没有花里胡哨的模型部署方法。
看看ppt

同时还使用了vue3写后台管理系统,介绍产品和卖,后端就是ruoyi,因为我们项目叫基于多场景应用XXXXX,所以需要Saas多租户权限管理,我们也设计了两套产品,上面的基于计算机视觉,还有一个手套,基于多模态传感器,用stm32拿到数据之后也是传后端,让模型分析。
我们发现还有动态手语,所以识别手语一直做的不好。
而最近考研初试结束后,我又重看了项目,觉得可以先用mobilenet提取特征,然后用滑动窗口,把多帧特征送给transformer做分类,类似的手套也可以这么做,把多传感器的数据一起送给transformer做分类。但静态手语和动态手语混一起的时候,怎么分词是一个问题,大概我想,可以类似llm的token一样,其实一个token也并不一定是一个单词,数据集可以一句话,一个词这样去录视频。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









