







需要安装的包:flask_sqlalchemy,使用方法是需要绑定到一个app上,然后再创建一个sqlalchemy对象db(也就是ORM,用于对数据库进行操作的一个映射)。
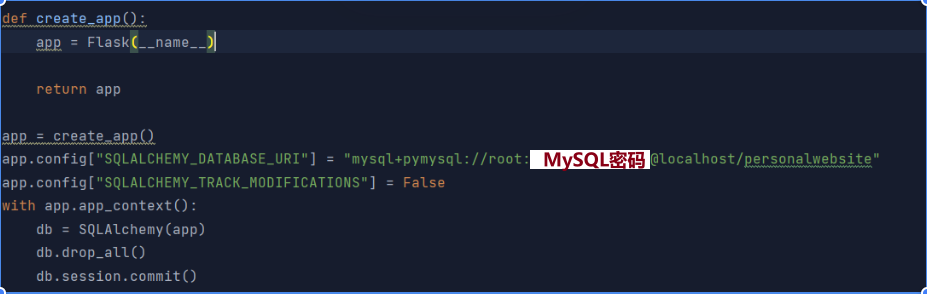
1. 利用这个可以首先连接数据库:
只需要在app的配置文件中指定数据库的url:"mysql+pymysql://root:20040616wldnrr@localhost/personalwebsite"
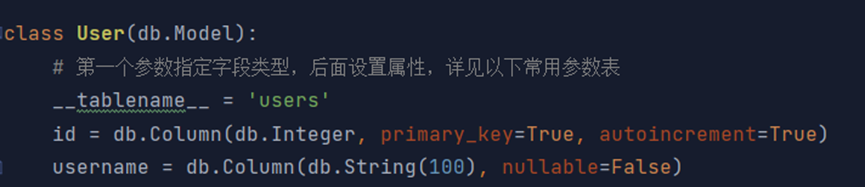
2. 其次还可创建表:
这里主要的就是每一个表都对应着一个类,一般所有的这种表的类都会放在models.py中。然后再类中指定 __tablename__ 用于改变表名,否则表名就是类名的小写
3. 通过这个我也进一步明白了之前困扰我的配置文件,模型文件。原来配置文件就是放置数据库db的一些配置键:
SQLALCHEMY_DATABASE_URI 用于连接数据的数据库。例如:mysql://username:password@server/db
SQLALCHEMY_BINDS 一个映射绑定 (bind) 键到 SQLAlchemy 连接 URIs 的字典。 更多的信息请参阅 绑定多个数据库。
SQLALCHEMY_ECHO 如果设置成 True,SQLAlchemy 将会记录所有发到标准输出(stderr)的语句,这对调试很有帮助。
SQLALCHEMY_RECORD_QUERIES 可以用于显示地禁用或者启用查询记录。查询记录在调试或者测试模式下自动启用。更多信息请参阅 get_debug_queries()。
SQLALCHEMY_NATIVE_UNICODE 可以用于显示地禁用支持原生的 unicode。这是某些数据库适配器必须的(像在 Ubuntu 某些版本上的PostgreSQL),当使用不合适的指定无编码的数据库 默认值时。
SQLALCHEMY_POOL_SIZE 数据库连接池的大小。默认是数据库引擎的默认值 (通常是 5)。
SQLALCHEMY_POOL_TIMEOUT 指定数据库连接池的超时时间。默认是 10。
SQLALCHEMY_POOL_RECYCLE 自动回收连接的秒数。这对 MySQL 是必须的,默认情况下 MySQL 会自动移除闲置 8 小时或者以上的连接。 需要注意地是如果使用 MySQL 的话, Flask-SQLAlchemy 会自动地设置这个值为 2 小时。
SQLALCHEMY_MAX_OVERFLOW 控制在连接池达到最大值后可以创建的连接数。当这些额外的 连接回收到连接池后将会被断开和抛弃。
SQLALCHEMY_TRACK_MODIFICATIONS 如果设置成 True (默认情况),Flask-SQLAlchemy 将会追踪对象的修改并且发送信号。这需要额外的内存,如果不必要的可以禁用它。
而模型文件则是存放每一个表的结构(所有的字段,字段的限制等等)
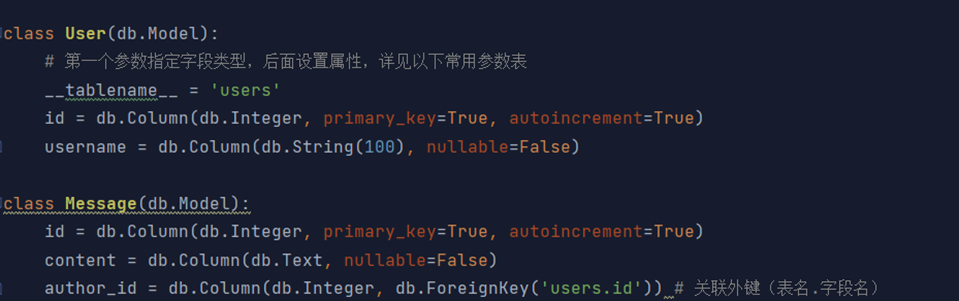
最后总结使用flask_sqlalchemy与直接用pymysql相比的好处就是不用接触直接的SQL语句,而是创建了一个ORM对象用于操纵数据库。
















 770
770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











