







实战网站:
Mindat是国际互联网上最大的矿物数据库平台和矿物参考资源网站,提供世界各地的矿物数据和矿物数据,许多地质人员更新最新的矿物信息、矿物来源、图片、存储等数据资源。
信息获取:
登录网址——
搜索目标矿石——
此处以 gold 为例:
进入目标矿石界面——
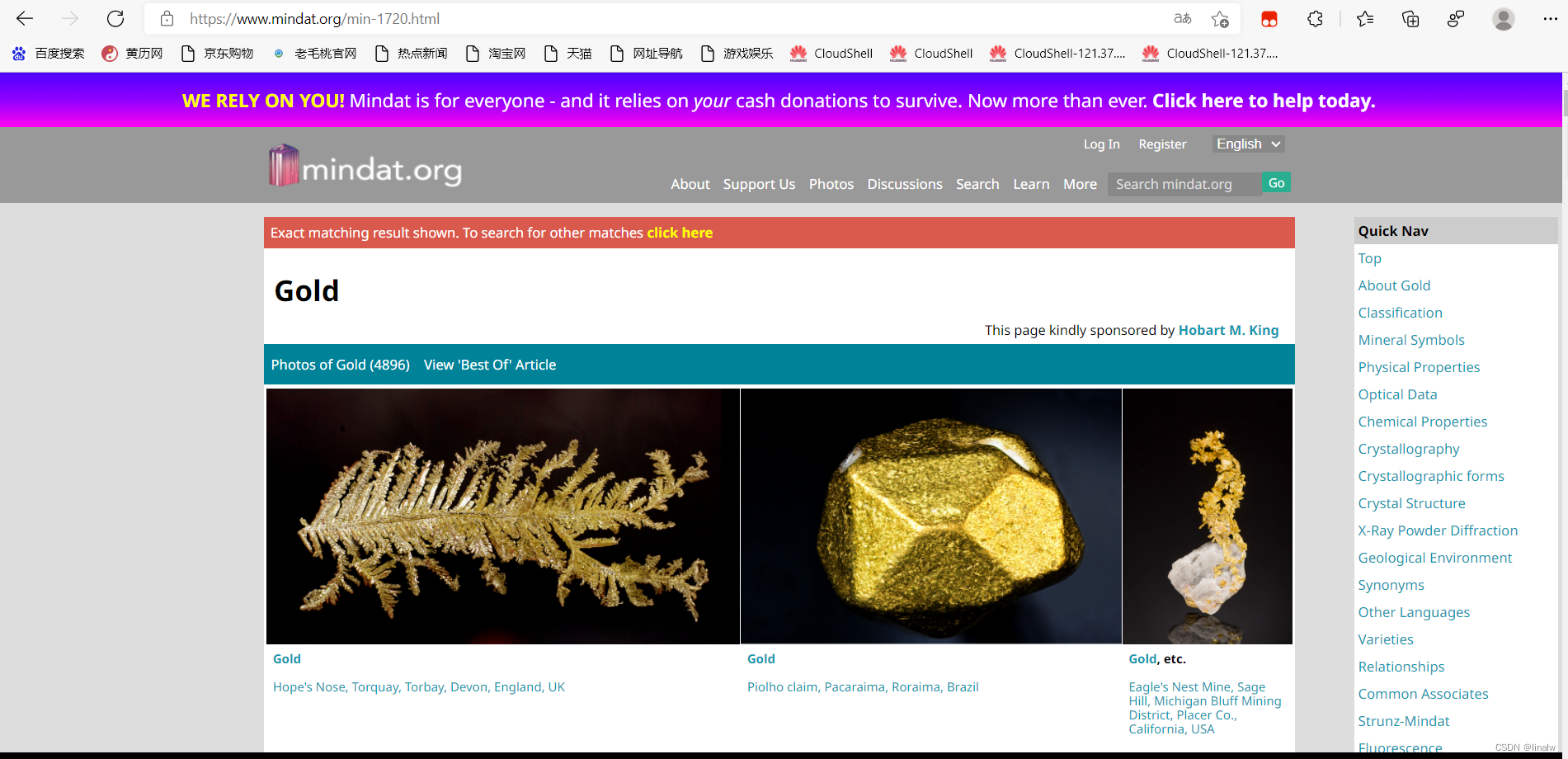
进入后点击 Photos of Gold ,进入下一个界面——
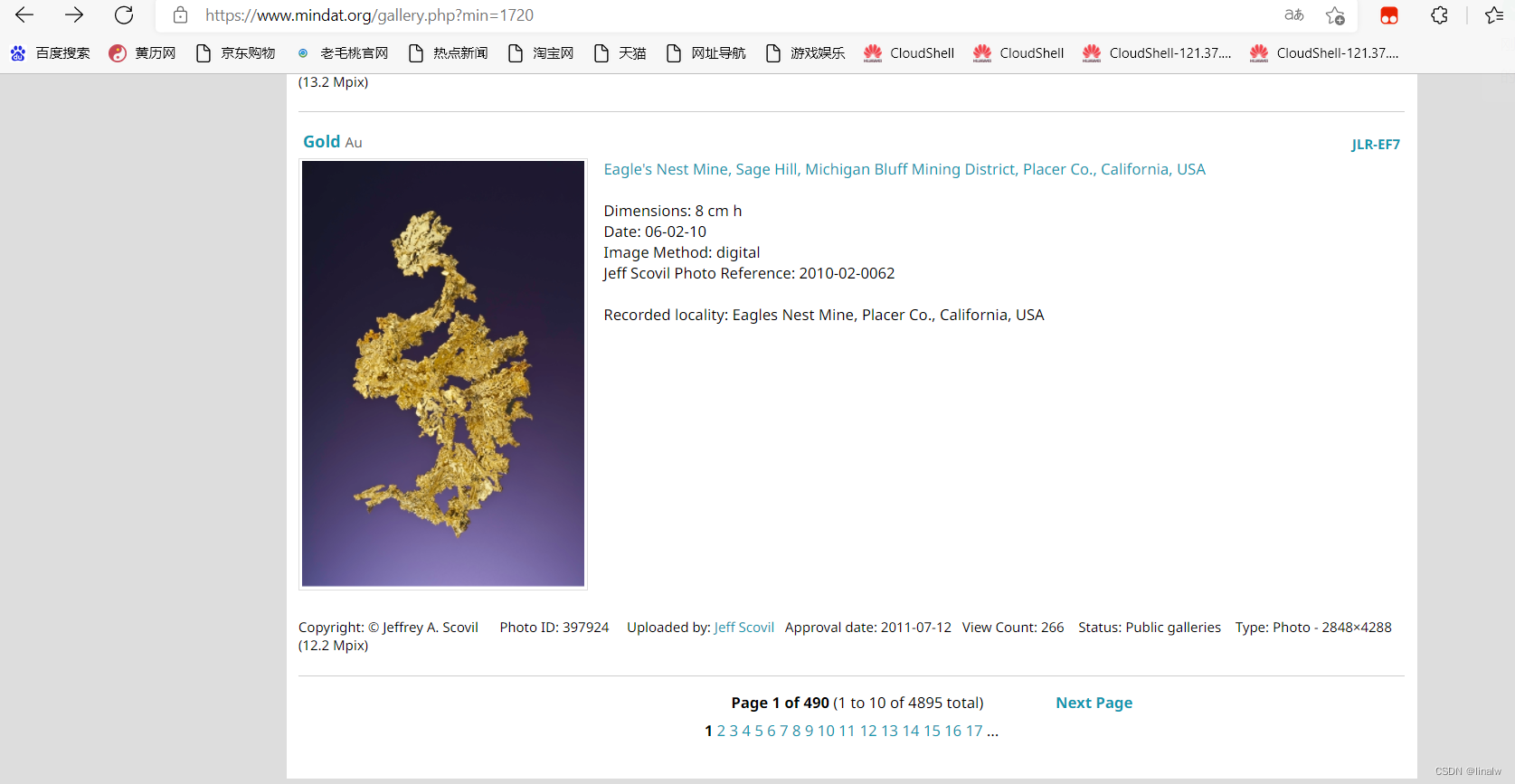
注意此时的 url:https://www.mindat.org/gallery.php?min=1720 尚不能满足爬取图片所需url的要求,因为爬取过程中需要刷新,进行翻页,这个url只能是程序爬取一页的图片
往下翻,底部出现页数标签,点击任一页数,此处点2,3作实列,进入以下界面
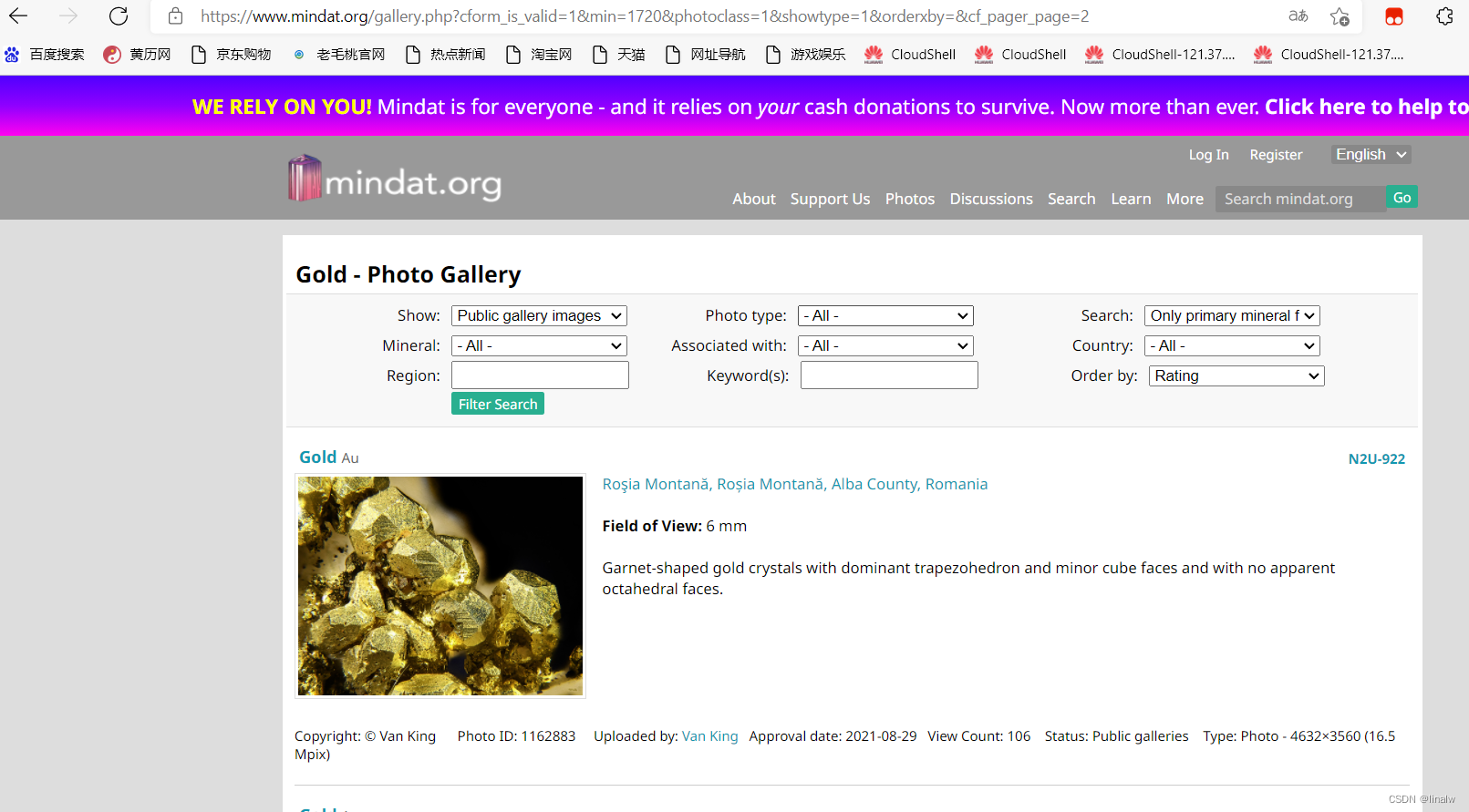
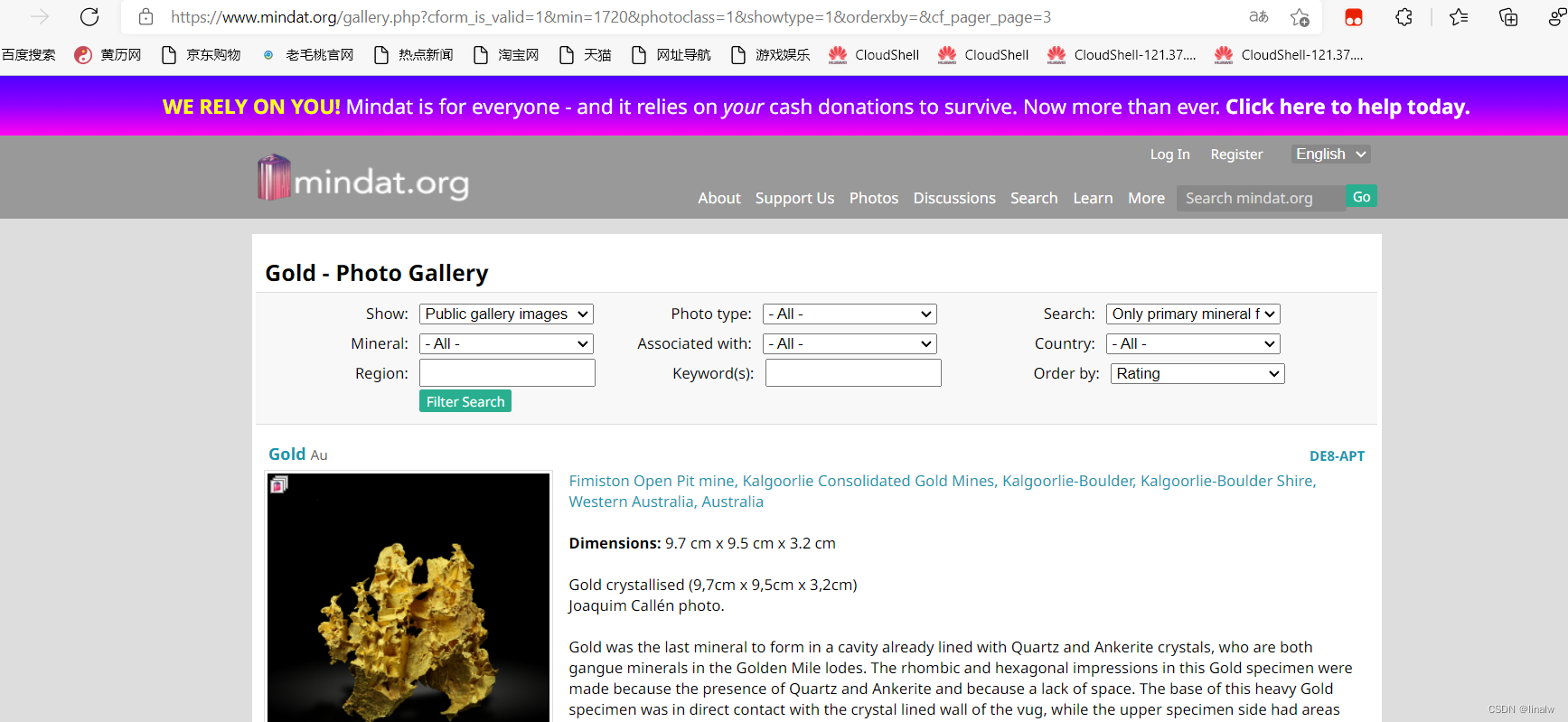
注意此时url发生变化,url:https://www.mindat.org/gallery.php?cform_is_valid=1&min=1720&photoclass=1&showtype=1&orderxby=&cf_pager_page=2
https://www.mindat.org/gallery.php?cform_is_valid=1&min=1720&photoclass=1&showtype=1&orderxby=&cf_pager_page=3此时url带这页数信息,观察两个url,发现两者不同之处只有页数, page=页数 ,也就是说,只要我们更改url中页数数字,就能利用它得到所有图片。
接下来获取总页数,滑倒底部,那里直接写明了,记下即可
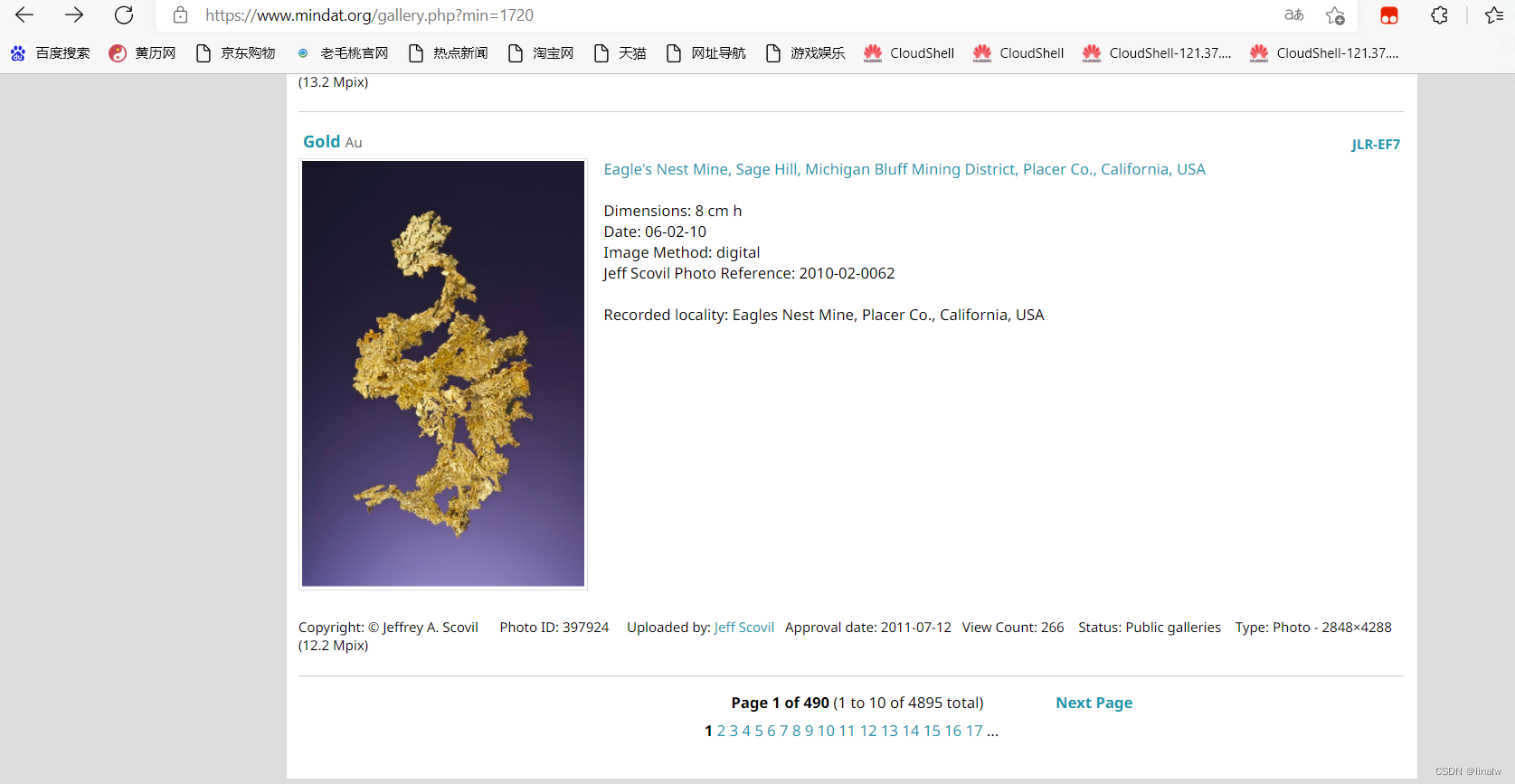
page 1 of 490 :所以矿石Gold图片有490页。
import json
import requests
import re
import os #为了存储爬取的图片,建立文件夹
if not os.path.exists('./gold'):#查找当前目录是否有目标文件夹(用于存储图片)
os.mkdir('./gold')#如没有,则在当前目录新建文件夹
url='https://www.mindat.org/gallery.php?cform_is_valid=1&min=1720&photoclass=1&showtype=1&orderxby=&cf_pager_page=' #去掉页数的url
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.12151 SLBChan/103'}
for pagen in range(1,491):#加上页数,遍历每一页,左闭右开区间,所以写491而不是490;
new_url=url+str(pagen)
page_text=requests.get(url=new_url,headers=headers).text
ex='/imagecache.*?jpg'
image_scr=re.findall(ex,page_text,re.S)
print(image_scr)
for src in image_scr:
src="https://www.mindat.org/" + src
image_data=requests.get(url=src,headers=headers).content
#生成图片名称
image_name=src.split('/')[-1]
#图片存储路径
image_path='./gold/'+image_name
with open(image_path,'wb') as fp:
fp.write(image_data)
print('over')
print("下载完成")更新(2022.11.28):
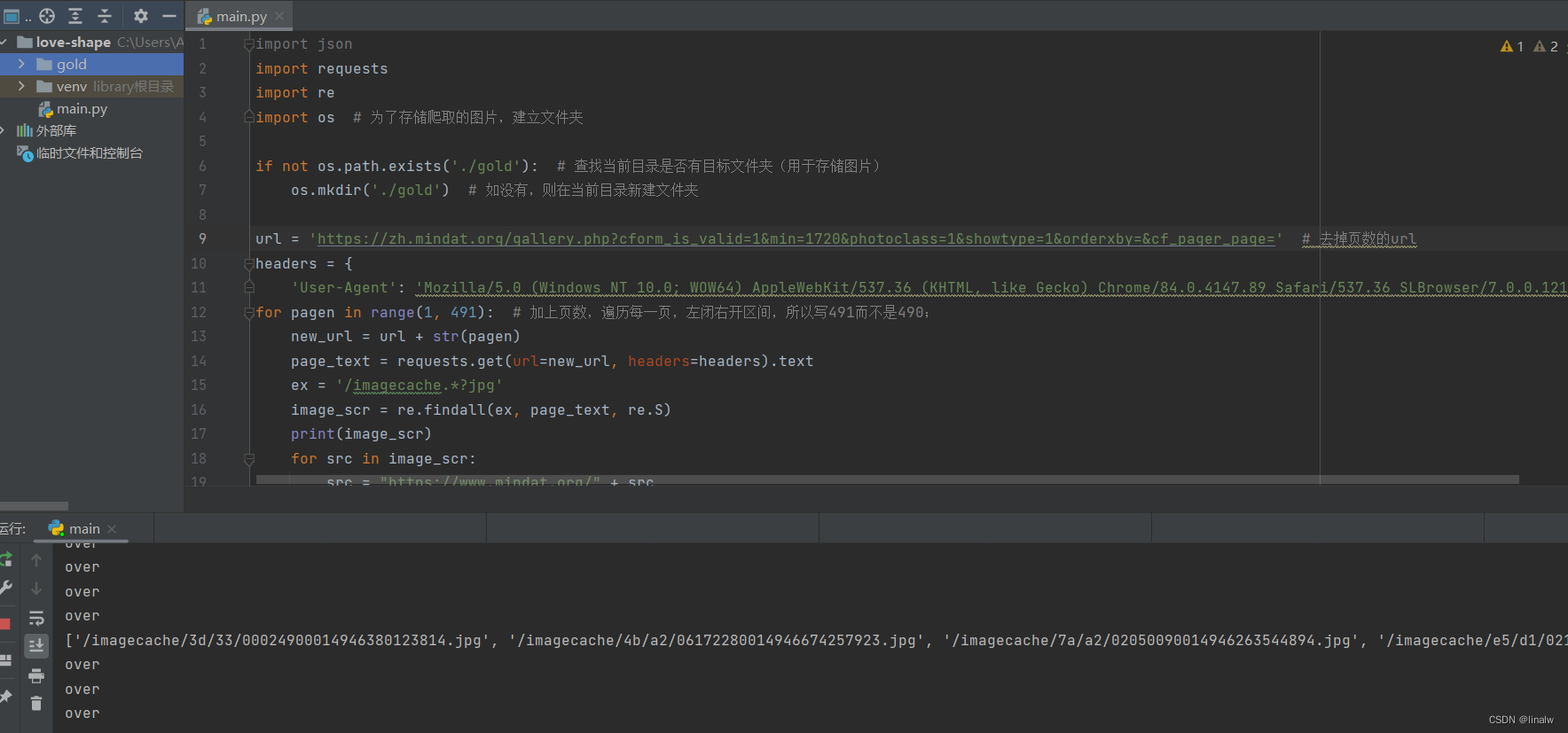
有朋友反映代码能跑,但是文件中没有图片,我试了一下,确实如此,并找到了原因:
原因是原网站上的url发生了变化——
url='https://www.mindat.org/gallery.php?cform_is_valid=1&min=1720&photoclass=1&showtype=1&orderxby=&cf_pager_page=
改为
url = 'https://zh.mindat.org/gallery.php?cform_is_valid=1&min=1720&photoclass=1&showtype=1&orderxby=&cf_pager_page=' 下面是正确运行的截图:
















 714
714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











