






大家好,今天给大家分享的是关于深度学习中最基础的部分,也就是神经网络的相关知识。
说到神经网路,大家都会觉得它非常的高级以及困难。但是其实它只是一个近几年来火起来的一种解决问题的方法,实现人工智能的方式有很多,包括各种各样的算法,神经网络也只是其中之一。
下面给大家讲解一下神经网络的基础组成。
一、浅层神经网络
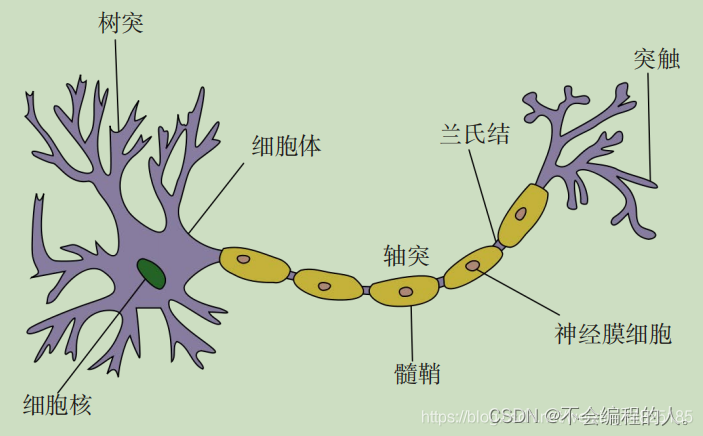
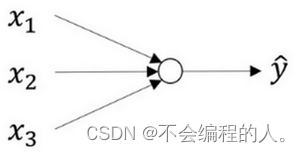
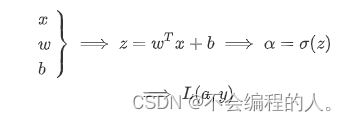
神经元的状态取决于从其它的神经细胞收到的输入信号量,及突触的强度(抑制或加强). 当信号量总和超过了某个阈值时,细胞体就会兴奋,产生电脉冲. 电脉冲沿着轴突并通过突触传递到其他神经元.
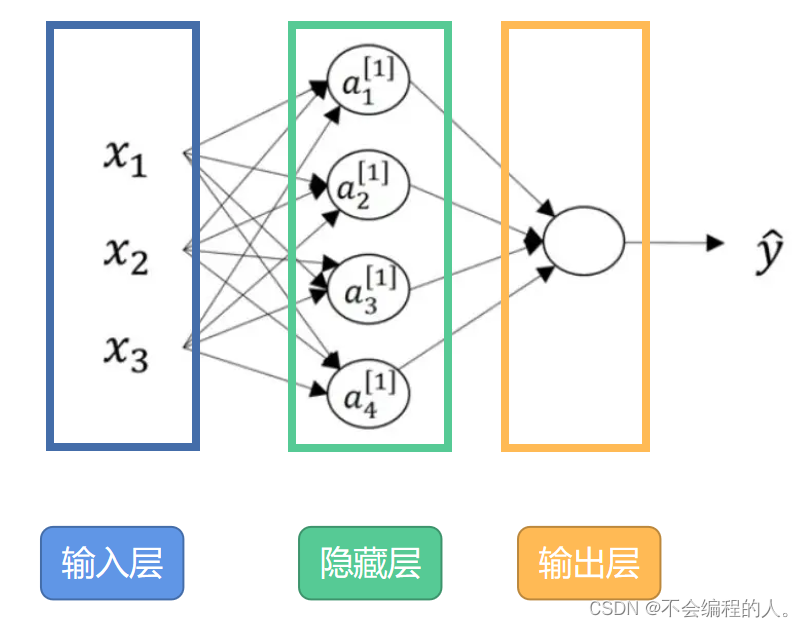
除了输入层和输出层,其他层在训练时,这些中间结点的准确值我们是不知道到的,所以称为隐藏层。
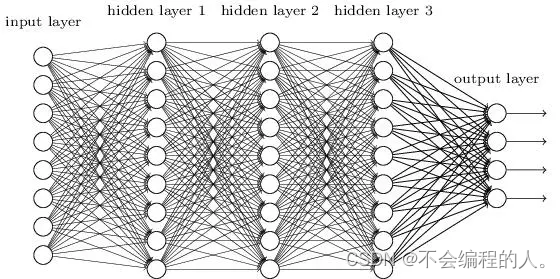
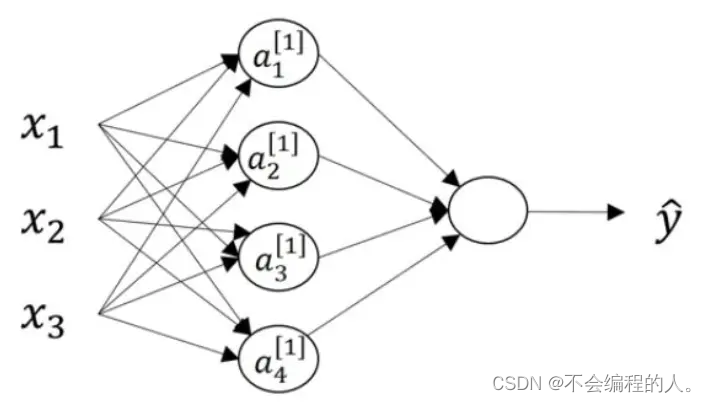
这些每个单元的计算和所有输入都相关的层,我们也称为全连接层
二、前向传播
通俗的说前向传播过程中的每一个神经元都可以看成在做一个操作,也就是y=wx+b操作,当神经元的个数或者层数增加时,这就需要并行计算减少成本,也就是线性代数中的矩阵运算。
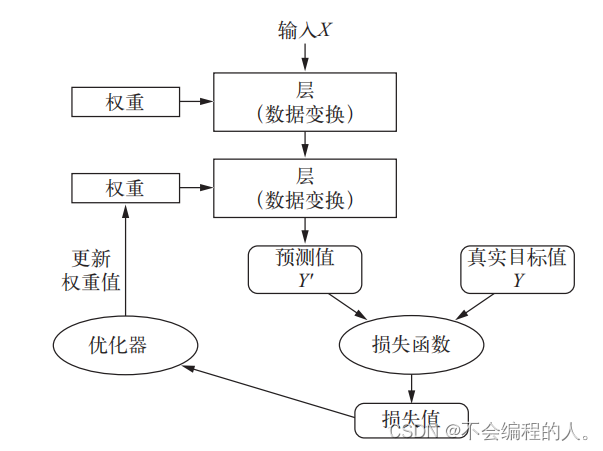
三、反向更新
反向更新也是非常的简单,最重要的就是大家需要掌握高等数学中的链式求导法则.
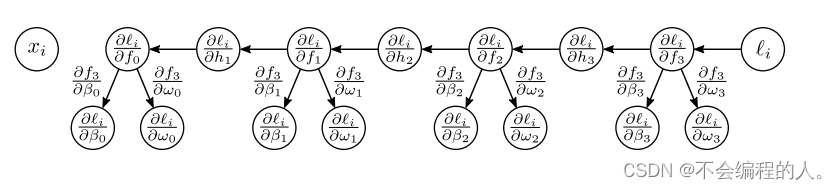
对于每一层的梯度:
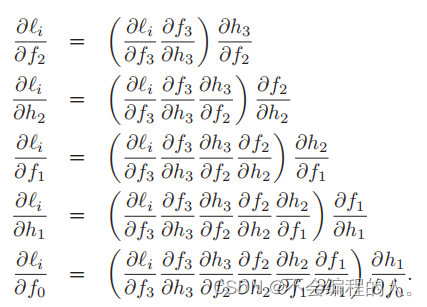
四、激活函数
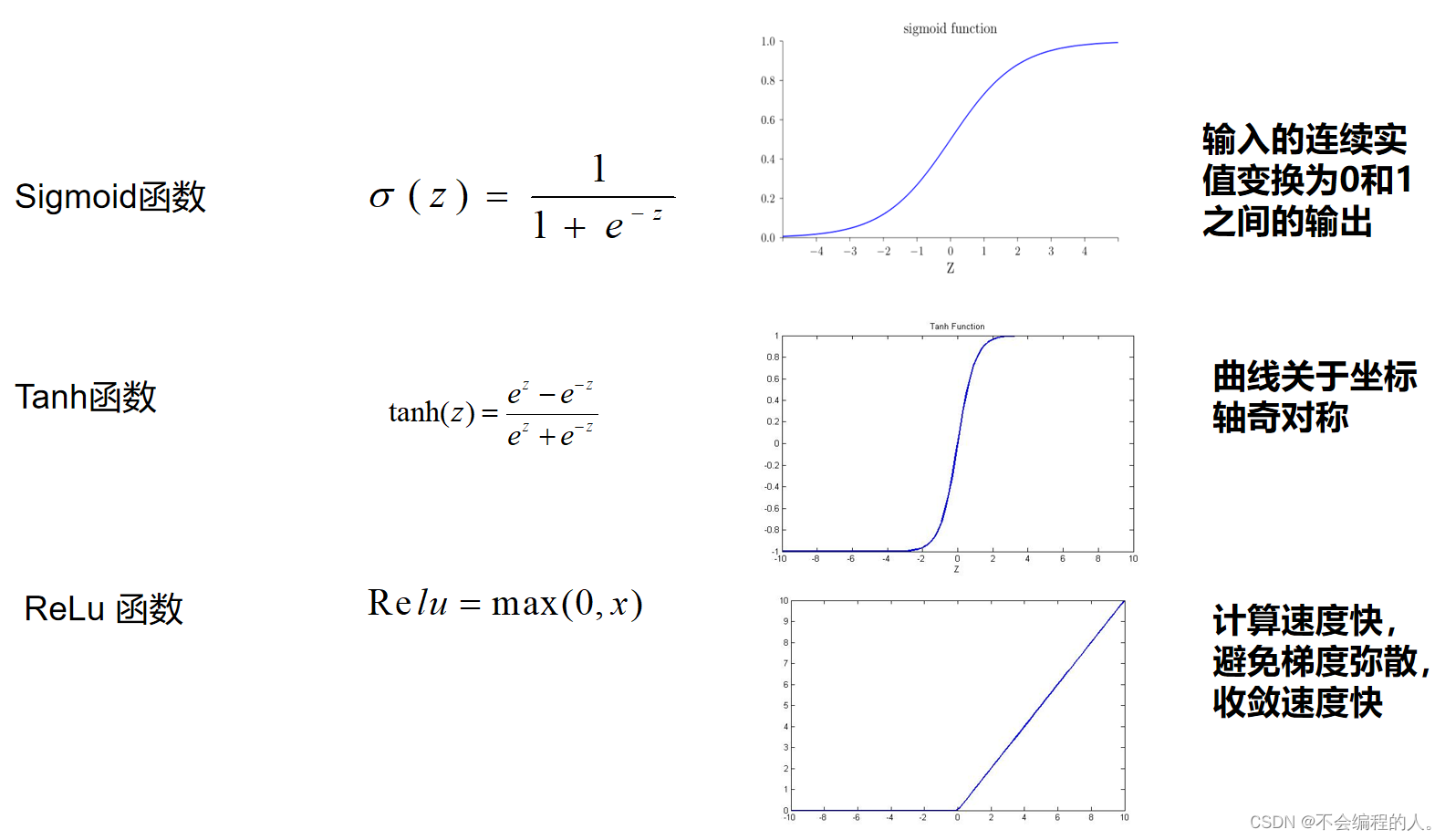
1.sigmoid 2.Tanh函数 3. ReLU
作用:其作用就是将我们通过前向传播得到的线性结果y增加非线性因素,通俗的说就是为了拟合更加复杂的数据,包括非线性的。
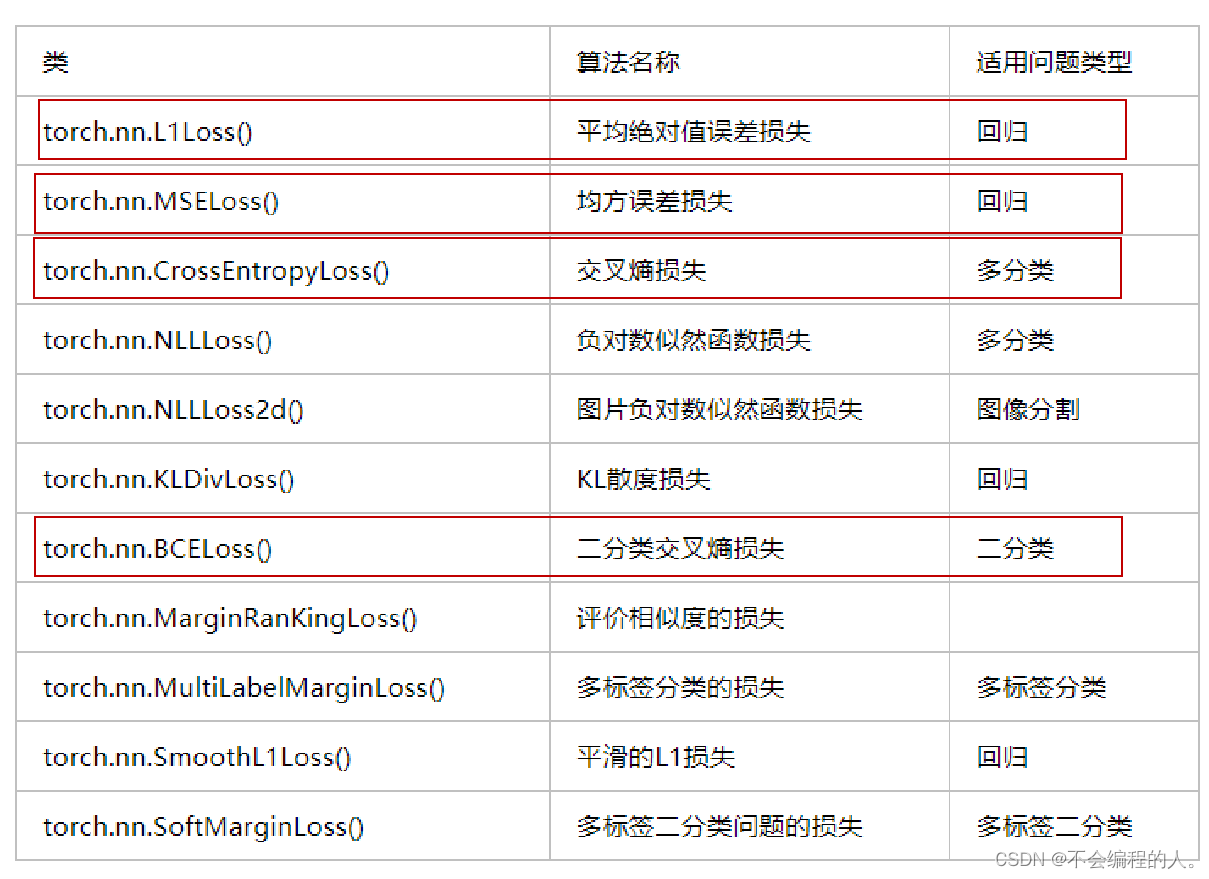
五、损失函数
目的:顾名思义,就是为了计算我们通过前向传播得到的结果y'的正确性,通常损失函数都是根据实际情况自己确定,当然也有一些通用的损失函数。
六、优化器
目的:优化器是为了更新我们神经网络中的参数,比如y=wx+b中的w和b,都是我们要更新的参数,使得模型拟合的效果更接近于真实结果。
常用的优化器:
SGD、Adam,这里就不详细展开了。
七、pytorch建立模型并训练
好,下面给大家列举一个简单的例子。
创建简单的模型:
class Net(torch.nn.Module): #继承nn.Module
def __init__(self, n_feature, n_output):
super(Net, self).__init__()
self.predict = torch.nn.Linear(n_feature, n_output)
def forward(self, x):
out = self.predict(x)
out = torch.relu(out)
return out
net = Net(13, 1)
常用优化器:
LR=0.01 #设置学习率
optimizer = torch.optim.SGD(net.parameters(), lr=LR)
损失函数设定:(回归任务)
criterion=torch.nn.MSELoss()开始训练:(在训练时,需要在每轮训练时梯度清理和梯度更新)
for epoch in range(15):
for step, (b_x, b_y) in enumerate(train_loader):
optimizer.zero_grad() # zero the gradient buffers
output = net(b_x)
loss = criterion(output, b_y)
loss.backward()
optimizer.step()
















 1404
1404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











