






Controllable Multi-Interest Framework for Recommendation
introduction&related work
推荐不仅只要精度,更要实现推荐多样化。
related work里介绍了如下主题,提到了很多经典模型(有兴趣可以看看原文):
-
Neural Recommender Systems
-
Sequential Recommendation
-
Recommendation Diversity.
-
Attention
-
Capsule Network
模型架构

方法METHODOLOGY
表一是符号(notation)
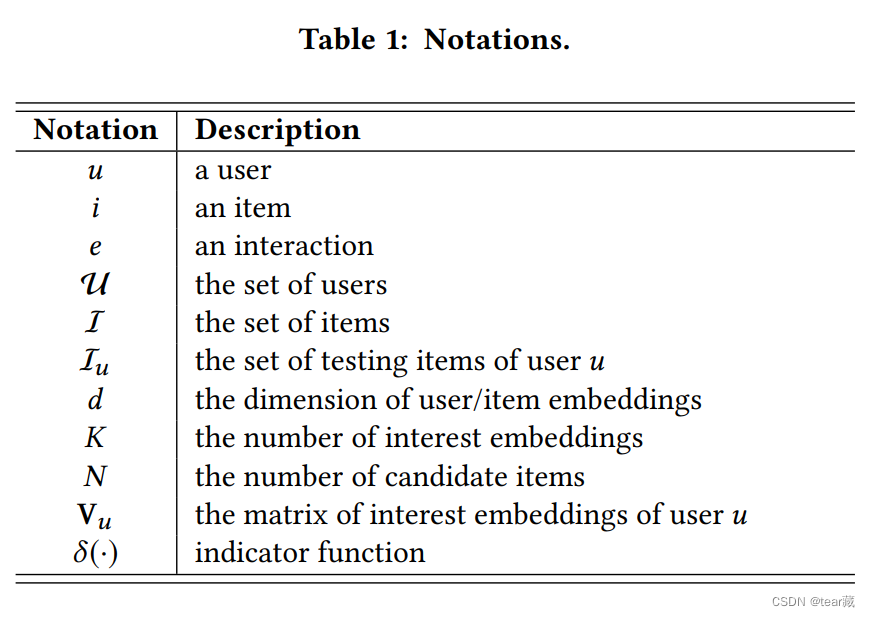
这部分重要的是用户多兴趣向量生成
Multi-Interest Framework
两种方法,一种使用动态路由的方法,一种使用self attention
Dynamic Routing:
我们要计算兴趣胶囊
v
j
v_j
vj,首先初始化
b
i
j
b_{ij}
bij以此来得到
c
i
j
c_{ij}
cij,这里使用0来初始化
b
i
j
b_{ij}
bij :
c
i
j
=
e
x
p
(
b
i
j
)
∑
K
e
x
p
(
b
i
k
)
(3)
c_{ij} = {exp(b_{ij}) \over \sum_K{exp(b_{ik})}} \tag3
cij=∑Kexp(bik)exp(bij)(3)
再计算根据用户项目交互
e
i
e_i
ei计算出high-level-vector “
e
^
j
∣
i
{\hat e_{j|i}}
e^j∣i”,以此来得到
s
i
j
s_{ij}
sij:
s
j
=
∑
i
c
i
j
e
^
j
∣
i
(2)
s_j = {\sum_i{c_{ij}{\hat e_{j|i}}}} \tag2
sj=i∑cije^j∣i(2)
e
^
j
∣
i
=
W
i
j
e
i
j
(1)
{\hat e_{j|i}} = W_{ij} e_{ij} \tag1
e^j∣i=Wijeij(1)
其中每个
W
i
j
W_{ij}
Wij对每个兴趣胶囊是不一样的,最终我们可以计算出用户兴趣胶囊
v
j
v_j
vj:
v
j
=
s
q
u
a
s
h
(
s
i
j
)
=
∣
∣
s
j
∣
∣
2
1
+
∣
∣
s
j
∣
∣
2
s
j
s
i
j
(4)
v_j = squash( s_{ij} ) = { { { {||s_j||}^2 }\over{1+||s_j||^2 } }}{s_j\over s_ij}\tag4
vj=squash(sij)=1+∣∣sj∣∣2∣∣sj∣∣2sijsj(4)
V
u
=
[
v
1
,
.
.
.
.
.
.
v
K
]
∈
R
d
∗
K
V_u=[v_1,......v_K]\in R^{d*K}
Vu=[v1,......vK]∈Rd∗K
使用动态路由更新
b
i
j
b_{ij}
bij

Self-attentive Method:
这里很自然引入self-attention计算用户兴趣胶囊:
a
=
s
o
f
t
m
a
x
(
w
2
⊤
t
a
n
h
(
w
1
H
)
)
(1)
a = softmax(w_2^{\top}tanh(w_1H))\tag1
a=softmax(w2⊤tanh(w1H))(1)
然后将
w
2
w_2
w2 into a
d
a
d_a
da-by-
K
K
K :
W
2
W_2
W2
A
=
s
o
f
t
m
a
x
(
W
2
⊤
t
a
n
h
(
w
1
H
)
)
(2)
A = softmax(W_2^{\top}tanh(w_1H))\tag2
A=softmax(W2⊤tanh(w1H))(2)
training时,求得用户对item的好感度
v
u
=
V
u
[
:
,
a
r
g
m
a
x
(
V
u
⊤
e
i
)
]
v_u = V_u [:, argmax(V^{\top}_ue_i)]
vu=Vu[:,argmax(Vu⊤ei)]

loss


Aggregation Module
But how to aggregate theseitems from different interests to obtain the overall top-N items?
A basic and straightforward way is to merge and filter the items basedon their inner production proximity with user interests, which canbe formalized as:
这里说如何针对不同的用户兴趣,最终选出top_K个item:
本来为了精确度:
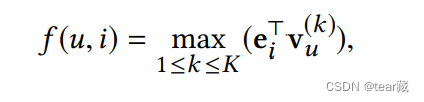
但是前面提到用户的体验更要是多样化的

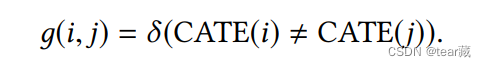
与现有模型的联系
- 不同于rank阶段的MIMN包含大量复杂计算的循环神经网络,本文模型更简单。
- 对于MIND,本文模型更能平衡用户体验(即多样性)
实验
指标有recall,HR,NCGD
对比如下
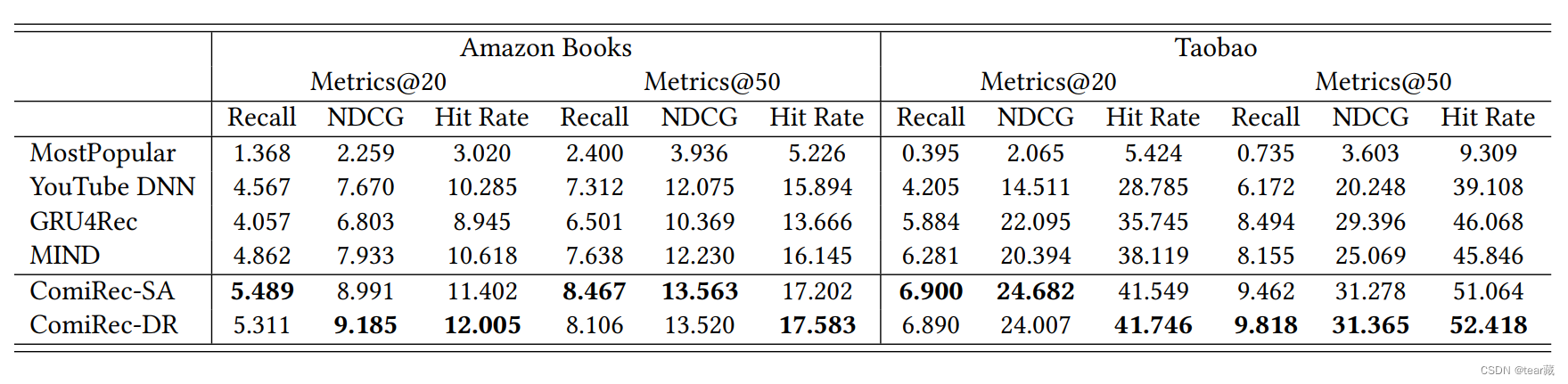


实验部分总结:
- attention方法在 K = ( 6 − 8 ) K=(6-8) K=(6−8)之间表现不错
- 胶囊方法方法在 K = 2 K=2 K=2和 K = 6 K=6 K=6时表现不错
- 对于后面提到的多兴趣超参数 λ \lambda λ,只能说是要推荐准确就不要多样性,反之一样。
总结
多样性有点牵强,attention效果挺好的















 1128
1128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









