







理解独热编码的原理,掌握词袋模型的实现方法,词频-逆文本频率的实现方法。
项目地址:zz-zik/NLP-Application-and-Practice: 本项目将《自然语言处理与应用实战》原书中代码进行了实现,并在此基础上进行了改进。原书作者:韩少云、裴广战、吴飞等。 (github.com) https://github.com/zz-zik/NLP-Application-and-Practice
https://github.com/zz-zik/NLP-Application-and-Practice
实现独热编码
onehot.py具体功能根据输入数据输出指定数字的独热编码,输入数据共3列,每一列表示不同的特征及取值范围,程序输出结果为数字0、1、3的独热编码。
"""
实现独热编码
具体功能根据输入数据输出指定数字的独热编码,输入数据共3列,每一列表示不同的特征及取值范围,程序输出结果为数字0、1、3的独热编码。
"""
from sklearn import preprocessing
"""调用独热编码,拟合训练数据"""
enc = preprocessing.OneHotEncoder() # 调用独热编码
enc.fit([
[0, 0, 3],
[1, 1, 0],
[0, 2, 1],
[1, 0, 2]
]) # 训练集
"""将结果转化为数组,并打印显示"""
res = enc.transform([[0,1,3]]).toarray() #将结果转化为数组
print(res)
从运行结果可以看出,前两个数字(1.0.)表示数字0的独热编码;中间3个数字(0.1.0)表示数字1的独热编码;后4个数字(0.0.0.1.)表示数字33的独热编码。.
实现词袋模型
bow.py具体功能是输出语料库中每个句子对应词袋模型的表示。
"""
实现词袋模型
具体功能是输出语料库中每个句子对应词袋模型的表示
"""
from sklearn.feature_extraction.text import CountVectorizer
"""加载语料库"""
texts = ['橘子 香蕉 苹果 葡萄',
'葡萄 苹果 苹果',
'葡萄',
'橘子 苹果'] # 语料库
"""文本向量化"""
cv = CountVectorizer() # 词袋模型对象
cv_fit = cv.fit_transform(texts) # 完成文本到向量的表示
"""打印结果"""
print(cv.vocabulary_) # 词汇表
print(cv_fit.toarray()) # 文本向量表示的数组格式
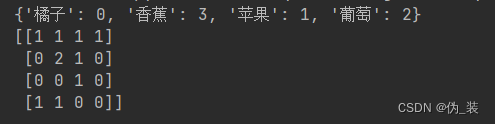
从运行结果可以看出,第一行打印信息表示语料库构建的词汇表,第二行打印信息表示每个句子对应的词袋模型表示。
实现TF-IDF模型
tfidf.py实现TF-IDF模型,具体功能是输出语料库中每个句子对应的TF-IDF的表示。
"""
实现TF-IDF模型,具体功能是输出语料库中每个句子对应的TF-IDF的表示。
"""
from sklearn.feature_extraction.text import TfidfVectorizer
""""加载语料库"""
texts = ['橘子 香蕉 苹果 葡萄',
'葡萄 苹果 苹果',
'葡萄',
'橘子 苹果'] # 语料库
"""文本向量化表示"""
cv = TfidfVectorizer() # TF-TDF
cv_fit = cv.fit_transform(texts) # 完成文本到向量的表示
"""打印结果"""
print(cv.vocabulary_) # 词汇表
print(cv_fit.toarray()) # 文本向量表示的数组格式
从运行结果可以看出,第一行打印信息表示语料库的词汇表,第二行打印信息表示每个句子对应的TF-IDF模型表示。
















 649
649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











